1.线性回归R方法
通过计算R方来看每个变量间的相关性
代码如下
X=[ones(length(X_pre),1),X_pre]; %注意:要计算具有常数项(截距)的模型的系数估计值,请在矩阵 X 中包含一个由 1 构成的列
[b,bint,r,rint,stats]=regress(Y,X);
R2=stats(1);2.Pearson相关系数
%默认类型为Pearson系数
[xiangguanxing,p_value]=corr(data,'Type','Pearson');数据如下所示

每一列为一个特征的数据集,第一列为因变量,需要计算其他自变量与它的相关性
相关性结果(xianguanxing):
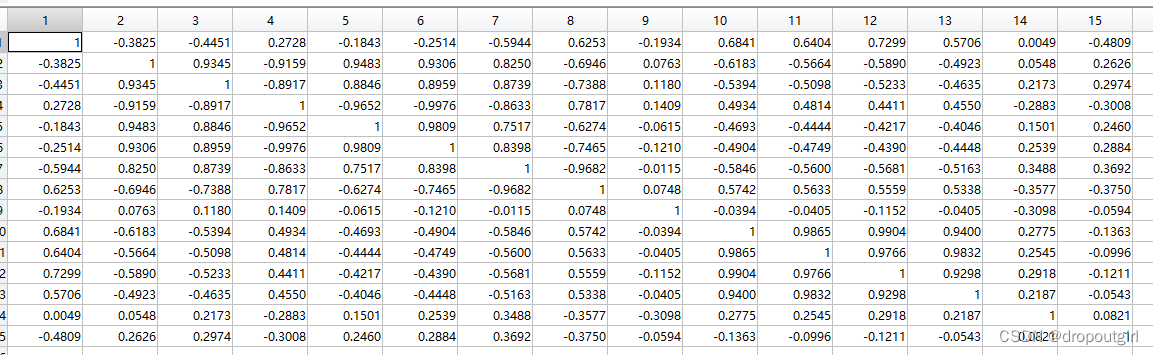
p值显著性检验结果(p_value):

显著性水平通常由研究者在进行统计分析之前事先设定,代表了对研究结果的显著性要求。常见的显著性水平是 0.05 或 0.01,分别对应着 5% 和 1% 的显著性水平。
当研究中进行假设检验并计算得到的 p 值小于设定的显著性水平时,可以认为结果是显著的。
一般低于0.01(双侧,即正负)为极显著相关,低于0.05(双侧)为显著相关。
如xianzhuxing(12,1)=0.7299,p_value(12,1)=0.0020,p值低于0.01,则为极显著相关。
3.其他相关系数
[xiangguanxing,p_value]=corr(data,'Type','Kendall'); %Kendall相关系数
[xiangguanxing,p_value]=corr(data,'Type','Spearman'); %Spearman相关系数