一种基于Spring-Kafka消费者动态启停方式的多环境切换的实现
1、背景
生产环境有3套,分别是正式生产环境(A)、备份生产环境(B)和预生产环境( P)。这三套环境的代码是完全相同的,但部署了3套进程(3“套”而不是3“个”是因为每个环境都可能部署多节点),但数据库和中间件却是共用的。所以这3套环境中共用了同一个Kafka集群。
开发每一个功能的生命周期会涉及到“上线”到生产环境,但生产环境也是有顺序的,并非同时部署到A、B和P这3个环境去,而是先部署到P环境,测试伙伴对P环境的代码做验证(此时主要验证新开发的功能搭配生产数据库的数据是否能够通过测试,然后产品经理也是在该环境对功能进行验收)。
问题是什么呢?有些业务需要在P环境验证Kafka消费后的逻辑,但Kafka对消费者的选择是有自己内定的规则,并不能做到A、B和P都同时消费,如何能够满足我们任意指定一个环境当作当前Kafka的消费者呢?本文将回答这个问题。
2、核心步骤1(Spring-Kafka的控制)
2.1 首先需要借助Spring的依赖注入功能获取到KafkaListenerEndpointRegistry的实例,该实例可以管理Kafka在Spring中的各种功能:
@Autowired
private KafkaListenerEndpointRegistry kafkaListenerEndpointRegistry;
2.2 从kafkaListenerEndpointRegistry获取所有的ListenerContainers:
Collection<MessageListenerContainer> listenerContainers =
kafkaListenerEndpointRegistry.getListenerContainers();
2.3 遍历所有的“监听器容器“,并调用“启动“或“停止“方法:
for (MessageListenerContainer listenerContainer : listenerContainers) {
listenerContainer.start();
listenerContainer.stop();
}
以上是最核心的控制Kafka的代码,有了控制Kafka的启动与停止逻辑后,就能够随时根据我们的需要实现动态的启停Kafka的消费者。
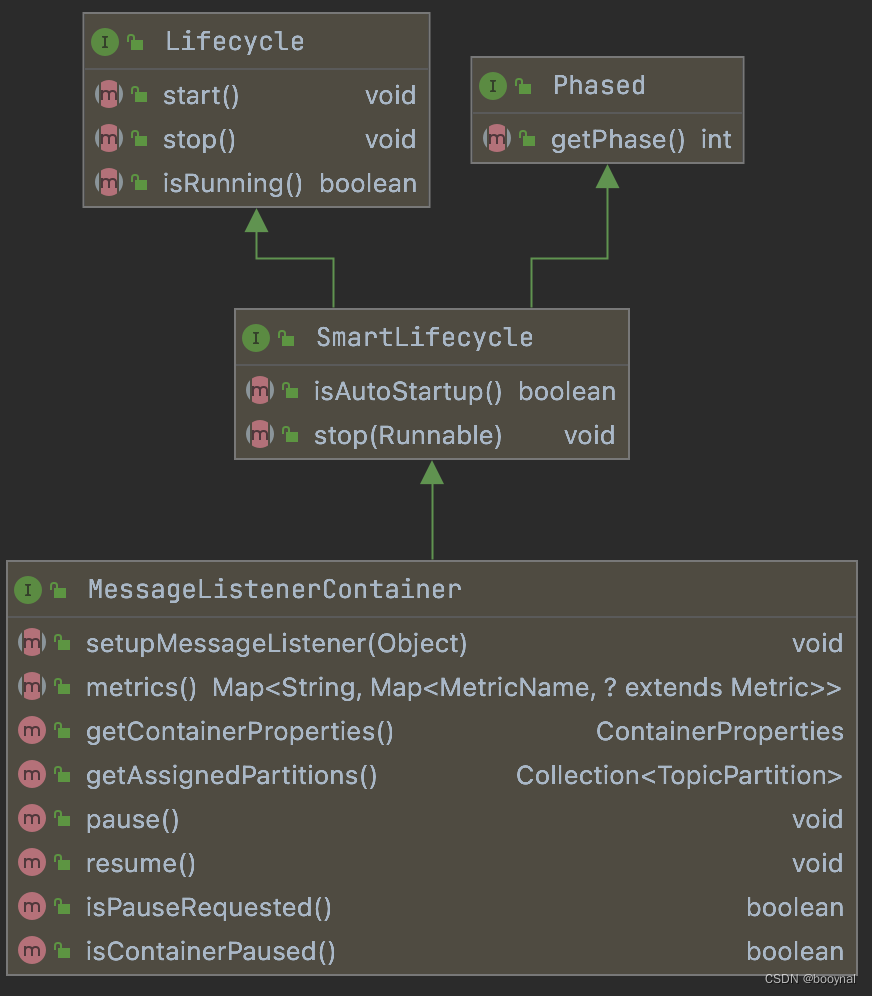
2.4 MessageListenerContainer的继承图
从MessageListenerContainer的继承图可以看出,该接口继承了SmartLifecyclie、Lifecycle和Phased。有几个与本主题相关的方法定义:
start():启动该“监听器容器”,与resume()不同,resume()表示从暂停中恢复,而start()表示向Kafka的broker建立连接,容器没有启动就不能暂停和恢复。stop():停止该“监听器容器”,该操作是spring-kafka从Kafka的broker中发送关闭命令,不再与Kafka的服务保持连接。getContainerProperties():可以获取到该“监听器容器”的配置,从而拿到监听的主题。
下面将介绍如何跟环境做绑定
3 核心步骤2(环境获取与判断)
针对A、B和P这三个环境,他们的代码相同,并不能从代码本身的内在逻辑获取是A、B还是P,只能从代码以外的地方获取,另一个值得考虑的是从JVM参数传递环境信息,但运维这边拒绝了,因为这样会导致服务启动的参数不标准、不统一。那还有什么不同呢?有很多!首先能想到的就是这三个环境的机器不同、IP地址不同,于是那就干吧。
3.1 获取机器名
由于获取机器名的代码可能需要在开发机、测试机和生产机器上执行,而测试和生产都是通用的Linux,但开发机器是个人的本地机器,有些人是Mac的OS系统,有些人是Windows系统,很少有人直接在Linux系统上做开发的。所以获取机器名需要兼容各种操作系统,这么说是因为我没有找到Java有通用的获取机器名称的方法,而是采用命令行执行本地命令的方式获取机器名。
Process process = Runtime.getRuntime().exec("hostname");
if (null != process) {
hostname = StreamUtil.fetchAllDataAsString(process.getInputStream());
System.out.println("hostname = " + hostname);
process.destroy();
}
获取到了本地的机器名,如果再能获取到当前希望消费的机器名,那就能够判断当前机器是否被允许启动消费者了,有多个方法去配置允许消费者启动的机器名单,如使用zookeeper,或者使用msyql等。
3.2 判断机器名
此处不对如何获取配置做介绍,而是对获取到配置之后的判断逻辑展示一下:
private boolean isNeedConsume(String fromSwitch) {
// 配置可能有多个,按照逗号分割
String[] split = fromSwitch.split("\\s*,\\s*");
// 先判断主机名,再判断IP
String hostname = SystemCommandUtil.getHostname();
if (SizeUtil.isNotEmpty(hostname) && Arrays.stream(split).filter(t -> Objects.equals(hostname, t)).findAny().isPresent()) {
return true;
} else {
List<String> localIpAddress = LocalIpUtil.getLocalIpAddress();
return SizeUtil.isNotEmpty(localIpAddress) && Arrays.stream(split).filter(t -> localIpAddress.contains(t)).findAny().isPresent();
}
}
4、定时器
由于程序需要响应管理人员任何时候的配置变更,所以需要定时获取管理员设定的配置信息,为了实现简单,此处使用定时器获取,代码如下:
public class KafkaConsumerStartStopConfiguration implements ApplicationRunner {
@Resource
private ScheduledThreadPoolExecutor scheduledThreadPoolExecutor;
@Override
public void run(ApplicationArguments args) throws Exception {
int periodInSec = 60;
log.info("定时检查是否需要本节点启动Kafka消费者: '{}'sec", periodInSec);
scheduledThreadPoolExecutor.scheduleAtFixedRate(this::check, 0, periodInSec, TimeUnit.SECONDS);
}
}
5、完整示例
以下给出主要代码逻辑的连续版本:
@Slf4j
@Configuration
public class KafkaConsumerStartStopConfiguration implements ApplicationRunner {
@Autowired
private KafkaListenerEndpointRegistry kafkaListenerEndpointRegistry;
@Resource
private ScheduledThreadPoolExecutor scheduledThreadPoolExecutor;
/** 缓存上一次允许消费的主机名 **/
private String lastKafkaConsumeHostname;
// 等到Spring容器启动完毕后再执行的方法
@Override
public void run(ApplicationArguments args) throws Exception {
int periodInSec = 60;
log.info("定时检查是否需要本节点启动Kafka消费者: '{}'sec", periodInSec);
scheduledThreadPoolExecutor.scheduleAtFixedRate(this::check, 0, periodInSec, TimeUnit.SECONDS);
}
public void check() {
// 检查配置是否有变化?
// 检查当前节点是否有消费权利?
// 如果没有,则调用消费者的stop()方法
// 如果有,则调用消费者的start()方法
String fromSwitch = ""; // FIXME 此处为获取配置,示例代码省略
if (SizeUtil.isEmpty(fromSwitch)) {
log.error("Kafka消费的主机名配置无效: '{}'", fromSwitch);
return;
}
if (Objects.equals(lastKafkaConsumeHostname, fromSwitch) == false) {
log.info("Kafka允许消费的主机名配置有变化: '{}' -> '{}'", lastKafkaConsumeHostname, fromSwitch);
if (isNeedConsume(fromSwitch)) {
start(null);
} else {
stop(null);
}
lastKafkaConsumeHostname = fromSwitch;
} else {
log.debug("Kafka允许消费的主机名配置无变化: ('{}', '{}')", lastKafkaConsumeHostname, fromSwitch);
}
}
private boolean isNeedConsume(String fromSwitch) {
// 配置可能有多个,按照逗号分割
String[] split = fromSwitch.split("\\s*,\\s*");
// 先判断主机名,再判断IP
String hostname = SystemCommandUtil.getHostname();
if (SizeUtil.isNotEmpty(hostname) && Arrays.stream(split).filter(t -> Objects.equals(hostname, t)).findAny().isPresent()) {
return true;
} else {
List<String> localIpAddress = LocalIpUtil.getLocalIpAddress();
return SizeUtil.isNotEmpty(localIpAddress) && Arrays.stream(split).filter(t -> localIpAddress.contains(t)).findAny().isPresent();
}
}
public void start(List<String> targetTopicList) {
startOrStop(targetTopicList, true);
}
public void stop(List<String> targetTopicList) {
startOrStop(targetTopicList, false);
}
/**
* 方法描述: 启动或停止消费者<br/>
*
* @param targetTopicList 目标的主题列表,如果为null,则表示全部(当前进程所持有)的主题
* @param start true表示是执行启动消费者的操作,false表示停止消费者的操作
*/
private void startOrStop(List<String> targetTopicList, boolean start) {
log.info("启动或停止Kafka消费者, start: '{}', targetTopicList: '{}'", start, targetTopicList);
Collection<MessageListenerContainer> listenerContainers = kafkaListenerEndpointRegistry.getListenerContainers();
if (SizeUtil.isNotEmpty(listenerContainers)) {
for (MessageListenerContainer listenerContainer : listenerContainers) {
// 是否执行:默认是全部执行
boolean doit = true;
if (SizeUtil.isNotEmpty(targetTopicList)) {
// 当有指定主题,就需要判断特定主题才执行
String[] registerTopics = listenerContainer.getContainerProperties().getTopics();
if (SizeUtil.isNotEmpty(registerTopics)) {
doit = CollectionUtils.containsAny(targetTopicList, Arrays.asList(registerTopics));
}
}
if (doit) {
if (start) {
listenerContainer.start();
log.info("启动Kafka的topic: '{}'", Arrays.toString(listenerContainer.getContainerProperties().getTopics()));
} else {
listenerContainer.stop();
log.info("停止Kafka的topic: '{}'", Arrays.toString(listenerContainer.getContainerProperties().getTopics()));
}
}
}
}
}
}
以上代码并非拷贝过去就能用,因为里面使用了很多的工具类,这些工具类可能需要你自己实现里面的逻辑。
另外,此份代码也体现了设计复杂,最终实现简陋的特点,从startOrStop(..)方法可以看出来,参数targetTopicList其实并没有被用上,这就是设计代码的时候希望用上,但由于客观原因不需要控制到主题这个粒度,而是将消费者整体关停。
有什么疑问欢迎讨论,如果文章有不合适的地方,也欢迎各位大佬斧正。