
论文链接:Improving Convolutional Networks With Self-Calibrated Convolutions
时间:2020 CVPR2020
作者团队:Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Changhu Wang, Jiashi Feng
分类:计算机视觉–人体关键点检测–2D topdown_heatmap
目录:
1.SCNet背景
2.SCNet姿态识别
3.SCNet网络架构图
4.引用
1.主要在于学习记录,如有侵权,私聊我修改
2.水平有限,不足之处感谢指出
1.SCNet背景
大多数卷积神经网络的改进主要关注于调整网络模型的架构,以产生丰富的有限元分析。
CNNs的进步主要集中于设计更复杂的结构,从而增强它们表示学习的能力。
该论文不关注架构,只通过改进基本的卷积模块来提升整个网络的性能,提出的自校准卷积SC可以更完整、更准确的定位目标物体。
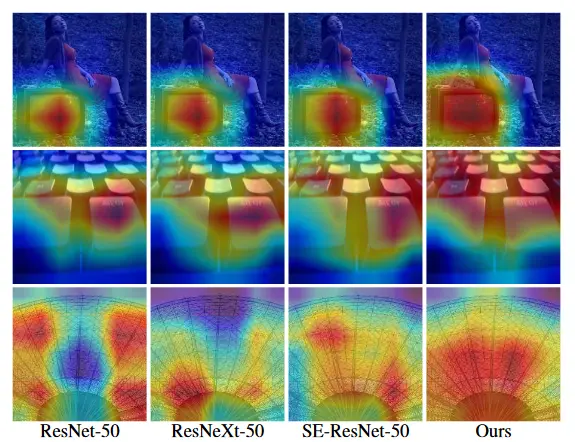
下图是可视化不同卷积方式的resnet产生的特征激活图,带自校准卷积的resnet可以更准确的定位目标物体。
2.SCNet姿态识别
该论文提出了一种由多个卷积注意力组合的自校准模块,用于替换基本的卷积结构,在不增加额外参数和计算量的情况下,该模块能够产生全局的感受野。相比于标准卷积,该模块产生的特征图更具有区分度。
该模块的优势所在:
1、传统卷积只能对小区域进行卷积操作,而自校准卷积模块使每个空间位置可以自适应的编码来自长范围区域的相关信息。
2、自校准卷积是普遍适用的,能够轻易地应用到标准的卷积层中,而不需要引入任何参数和复杂的头部或改变超参数。
-
网络结构部分
传统卷积:
存在输入x,卷积核k,输出z,则传统卷积操作的公式:
y i = k i ∗ X = ∑ j = 1 k i j ∗ x j , \begin{aligned} \\ \text{y}_i=\text{k}_i*\textbf{X} =\sum\limits_{j=1}\mathbf{k}_i^j*\mathbf{x}_j, \end{aligned} yi=ki∗X=j=1∑kij∗xj,
存在的问题;提取到的特征图没有很强的区分性
1. 每个输出的特征图都是通过所有通道求和来计算的,所有的特征图都是通过重复同一公式得到。
2. 每个空间位置的感受野主要由预定义的卷积核大小控制。
SC自校准卷积:
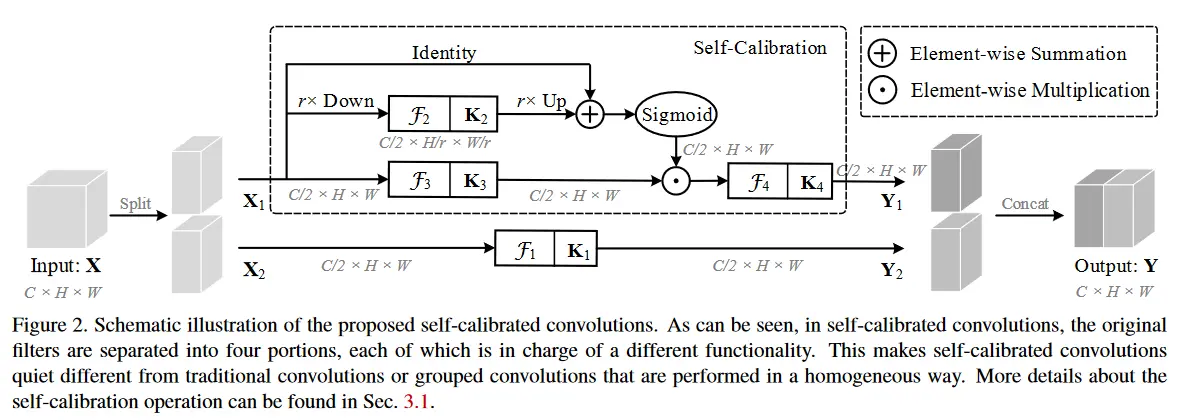
以上为SC模块的架构图,X为输入特征图,Y为输出特征图,F为不同kernel size的卷积层,K为对应的kernel的大小。
为了有效获取每个空间位置的、有用的全局信息,论文提出在两个不同的空间进行卷积特征变换:
一个是初始尺度空间,特征图与输入数据相同的分辨率;一个是下采样后的小的隐空间。小隐空间转换后因为具有较大的感受野,可以用来做参考信息,指导初始特征空间的特征变换过程。
1. 将输入特征图X分为两部分X1和X2。
2. X1经过自校准操作得到Y1,X2经过简单的卷积操作获得Y2,最后Y1和Y2拼接得到输出特征图Y。
具体操作
对于Y1的过程:给定输入X,使用滤波器尺寸为rxr ,步长为r进行平均池化,公式如下︰
T 1 = A v g P o o l r ( X 1 ) . \mathbf{T}_1=\mathrm{AvgPool}_r(\mathbf{X}_1). T1=AvgPoolr(X1).
对T使用卷积核组 K 2 {K}_2 K2进行特征变换︰ X 1 ′ = Up ( F 2 ( T 1 ) ) = Up ( T 1 ∗ K 2 ) \mathbf{X}_{1}^{\prime}=\operatorname{Up}({\mathcal{F}}_{2}(\mathbf{T}_{1}))=\operatorname{Up}(\mathbf{T}_{1}*\mathbf{K}_{2}) X1′=Up(F2(T1))=Up(T1∗K2)
其中 Up ( ⋅ ) \text{Up}(\cdot) Up(⋅)表示线性插值操作,得到中间参考量从小尺度空间到原始特征空间的映射,则自校准操作可以表示为: Y 1 ′ = F 3 ( X 1 ) ⋅ σ ( X 1 + X 1 ′ ) \mathbf{Y}_1'=\mathcal{F}_3(\mathbf{X}_1)\cdot\sigma(\mathbf{X}_1+\mathbf{X}_1') Y1′=F3(X1)⋅σ(X1+X1′)
其中 F 3 ( X 1 ) = X 1 ∗ K 3 \operatorname{F}_3(\mathrm X_1)=\mathrm X_1\ast\mathrm K_3 F3(X1)=X1∗K3, σ \sigma σ表示sigmoid函数,符号“.”表示逐元素乘运算,X’被用作残差项,建立权重,用于自校准。自校准后的最终输出可以写作: Y 1 = F 4 ( Y 1 ′ ) = Y 1 ′ ∗ K 4 \mathbf{Y}_1=\mathcal{F}_4(\mathbf{Y}_1')=\mathbf{Y}_1'*\mathbf{K}_4 Y1=F4(Y1′)=Y1′∗K4 -
总结
与传统的卷积相比,通过采用校准操作,允许每个空间位置不仅将其周围的信息环境自适应地视为来自潜在空间的embedding,以作为来自原始比例空间的响应中的标量,还对通道间依赖性进行建模。 可以有效地扩大具有自校准的卷积层的视场。 如图所示,具有自校准功能的卷积层编码更大但更准确的辨识性区域。

自校准操作不收集全局上下文,仅考虑每个空间位置周围的上下文,在某种程度上避免来自无关区域的某些污染信息。 从图中可以看出,在可视化最终分数层时,具有自校准功能的卷积可以准确地定位目标物体。

-
结果评估
SC和普通卷积的对比
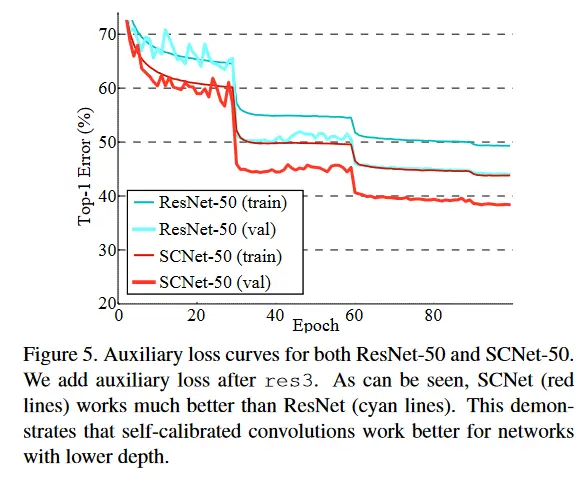
训练过程中加了SC模块后loss下降更快,错误率更低。
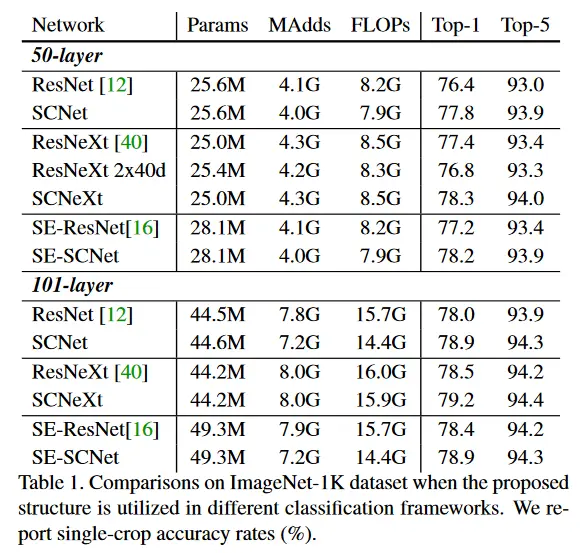
ImageNet-1K数据集评估结果
SCNet设计的消融实验
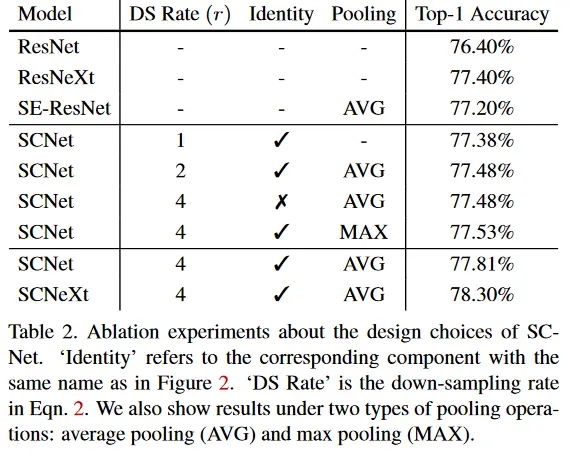
ImageNet上使用注意力机制方法的比较
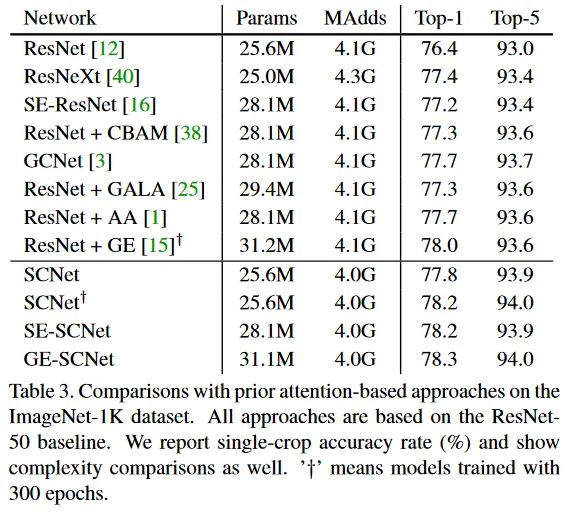
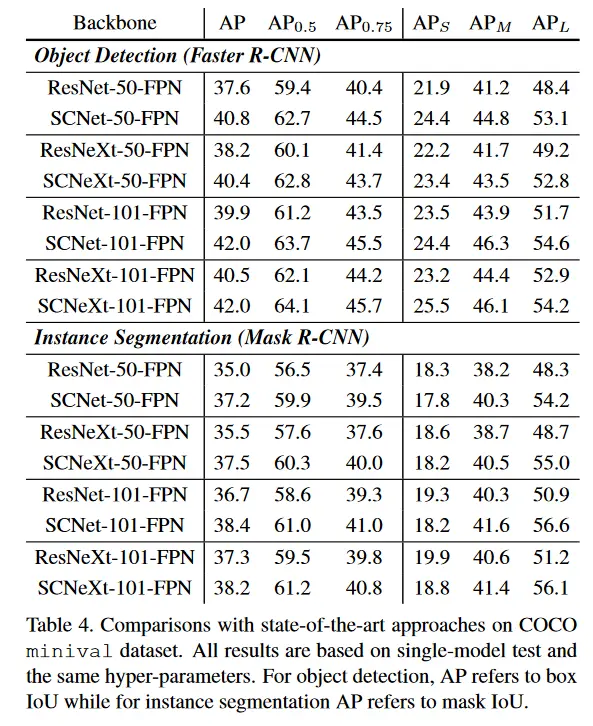
coco minival数据集使用最优方法在目标检测上的比较
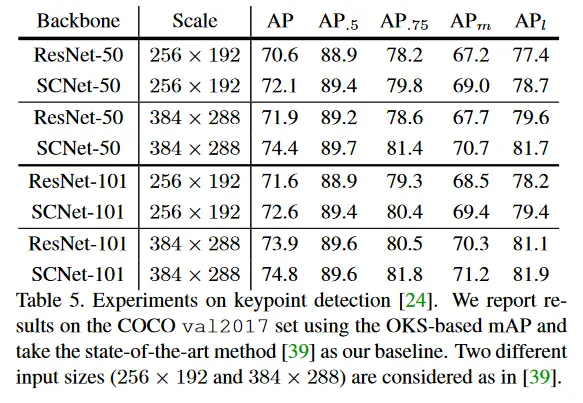
COCO val2017数据集上的关键点检测比较
3.SCNet网络架构图
