1. 迁移学习的背景
在有监督的机器学习和尤其是深度学习的场景应用中,需要大量的标注数据。标注数据是一项枯燥无味且花费巨大的任务,关键是现实场景中,往往无法标注足够的数据。而且模型的训练是极其耗时的。因此迁移学习营运而生。
传统机器学习(主要指监督学习)
- 基于同分布假设
- 需要大量标注数据
然而实际使用过程中不同数据集可能存在一些问题,比如 - 数据分布差异
- 标注数据过期
训练数据过期,也就是好不容易标定的数据要被丢弃,有些应用中数据是分布随着时间推移会有变化,将以往数据尽可能的利用起来,是迁移学习的思想。

2. 迁移学习
迁移学习中有两个重要概念:
- 域(domain):可以理解为某个时刻的某个特定领域,比如 动物图片数据 和 电影海报数据 可以认为是两个域,不同域中的数据特征往往存在比较大的差异。
- 任务(task):可以理解为 业务场景的目标。例如:情感识别和自动问答 就是两个不同的task,不同的task的数据可以来自同一个域。
迁移学习,并不是某一类特定的算法,而是一种处理问题的思想。
具体迁移学习往往分为两个步骤:
1.根据超大规模数据,对模型进行训练;
2.根据具体场景任务 进行微调(可以微调权重,还可以调整终端的结构)
根据特征空间和迁移方法,可以将迁移学习分为不同的种类。根据特征空间和标签空间是否相同,可将迁移学习分为 异构迁移学习 和 同构迁移学习。

根据迁移学习的方法,大体可以将迁移学习分为:
- 基于实例(样本)的迁移学习;
- 基于特征的迁移学习;
- 基于参数(模型)的迁移学习;
- 基于关系的迁移学习。
3.基于实例(样本)的迁移学习
传统机器学习中假设训练数据和测试数据来自同一个领域(Domain),即处于同一个特征空间,服从同样的数据分布。然而实际应用中测试数据跟训练数据可能来自不同的域(Domain)。
其中基于实例(样本)的方法对应的假设如下:源域和目标域 有很多交叠的特征,源域和目标域具有相同或相近的支持集。(支撑:理解为 对任务目标有用的信息)
比如:利用评论分析客户情感的任务中,电子设备的评论和DVD的评论,两种评论属于不同领域,虽然两种数据属于不同的域,但是可能存在一些电子设备的评论适用于DVD的评论的情感分类任务。

我们的目标就是从源域的训练数据中找出那些适合目标域的实例,并将这些实例迁移到训练数据的学习中去。
典型的算法是Tradaboosting,算法的关键想法是,利用boosting的技术来过滤掉源域数据中那些与目标域训练数据最不像的数据。其中,boosting的作用是建立一种自动调整权重的机制,于是重要的源域练数据的权重将会增加,不重要的源域训练数据的权重将会减小。调整权重之后,这些带权重的源域训练数据将会作为额外的训练数据,与目标域训练数据一起从来提高分类模型的精度和可靠度。
4. 基于特征的迁移学习
基于特征的迁移学习算法,通过将源域和目标域特征变换到相同的空间(或者将其中之一映射到另一个空间中),并最小化源域和目标域的距离来完成知识迁移。
基于特征映射的迁移学习算法,关注的是,如何将源域和目标域的数据从原始特征空间映射到新的特征空间中。在新的特征空间中,源域和目标域的数据分布相同,从而可以在新的空间中,更好的利用源域已有的标记数据样本进行分类训练,最终对目标域的数据进行分类测试。
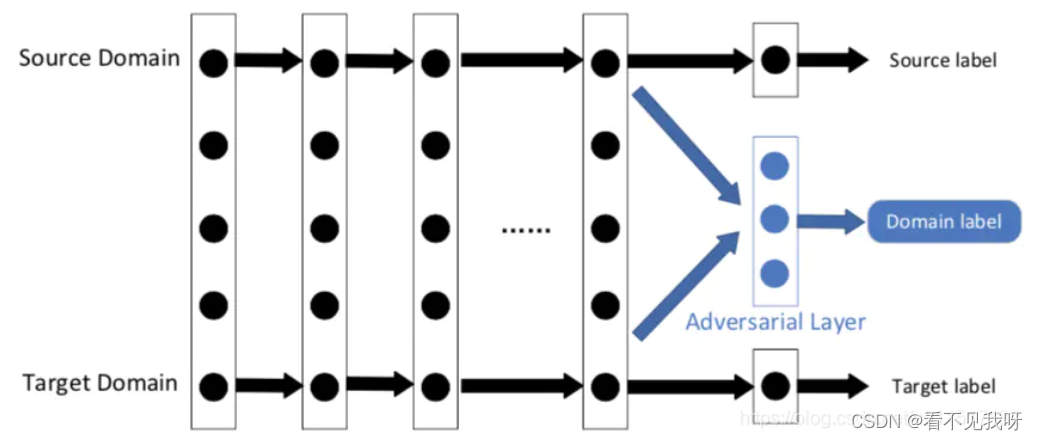
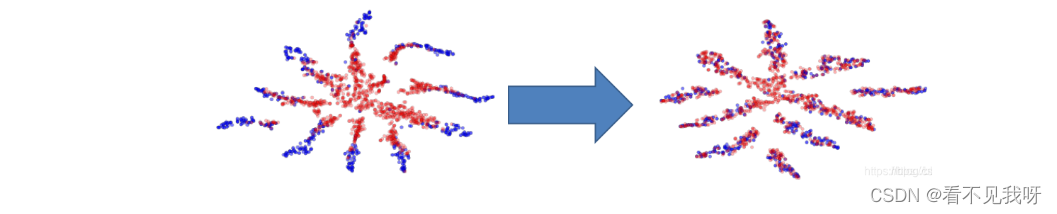
针对源域的大量数据进行训练的过程中,网络的前几层可以看作是特征提取器。该特征抽取器收取两个域的特征,然后输入对抗网络;对抗网络尝试对特征进行区分。
如果对抗网络对特征较难区分,则意味着两个域的特征区分性小,具有很好的迁移性。反之亦然。
最近几年,由于其良好的性能和实用性,基于对抗学习的深度迁移学习,被广泛的研究。
5.基于参数(模型)的迁移学习
基于参数/模型的迁移学习,主要假设 源域和目标域的学习任务中 相关模型会共享一些相同的参数或者先验分布,使得源域和目标域的任务之间 可以 共享部分模型结构,和 与之对应的模型结构。
比如源域中有大量未标记的的猫和狗的图片,目标域中有少量的标记猫和狗的图片。可以利用DNN对源域中的猫狗图片进行无监督学习。之后将训练好的DNN模型的前几层layer和参数直接带入新的DNN,使前几层layer和参数复用在目标域猫狗分类任务中去。此时源域的DNN模型的前几层layer的输出可以看做对图片特征的提取器,这些特征能有效的代表图片的信息。
6.基于关系的迁移学习
通过将源域和目标域映射到一个新的数据空间。在这个新的数据空间中,来自两个域的实例相似 且 适用于联合深度神经网络。
该方法基于假设:尽管源域和目标域不同,但是在精心设计的新数据空间中,他们可以更相似。
就目前来说,基于关系的迁移学习方法的相关研究工作很少。

通常的迁移学习可以分为两步完成:“预训练”和“微调”
预训练(pre-train):预训练的本质是无监督学习,栈式自编码器和多层神经网络都能得到有效的参数,使用大量数据将其训练之后的参数作为神经网络的参数初始值即预训练。预训练由于是无监督学习,无需对样本进行标记标签,省去大量人工时间,并且预训练后的参数直接带入其他任务模型中,可以使模型更快的收敛。
微调(fine-tuning):任务模型一部分会复用预训练的部分模型结构和参数,根据具体任务,对模型参数进行微调。由于模型绝大部分参数是已经训练好的,因此无需大量数据进行微调,并且由于参数已经是经过训练的,模型收敛很快