原文来源:arxiv
作者:Devendra Singh Chaplot、Ruslan Salakhutdinov
「雷克世界」编译:嗯~阿童木呀、KABUDA
相信大家都知道,在自然语言处理中存在这样一个尚待解决的问题:词义消歧(Word Sense Disambiguation),尤其在无监督环境中具有很大的挑战性和有用性。其中,对于任何给定文本中的所有单词都需要在不使用任何标记数据的情况下对其进行歧义的消除。通常,WSD系统将目标单词周围的句子或小窗口作为消除歧义的上下文,因为它们的计算复杂度随着上下文的大小呈指数级增长。

在本文中,我们利用主题模型的形式设计了一个WSD系统,该系统以一种与上下文中的词数成线性关系的方式进行扩展。因此,我们的系统能够利用整个文档作为一个单词的上下文,从而进行消除歧义。我们在本文中所提出的方法是主题模型Latent Dirichlet Allocation(LDA)的一个变体,其中,文档的主题比例被同义词集比例(synset proportions)所代替。进一步地,通过在词汇上为同义词集分布分配一个非均匀先验,以及在同义词集上为文档分布分配一个逻辑正太先验(logistic-normal prior)。我们在Senseval-2、Senseval-3、SemEval-2007、SemEval-2013和SemEval-2015英文全文WSD数据集上评估了我们所提出的方法,评估结果表明该,在很大程度上,我们提出的方法要优于当前最先进的无监督基于知识型的WSD系统。
可以这样说,词义消歧(WSD)是指将给定上下文中的一个歧义词映射到其正确含义的任务。 在自然语言处理(NLP)中,WSD在是一个很重要的问题,一方面,它本身就是一个具有意义的系统。另一方面,对于诸如机器翻译(Chan、Ng和Chiang 于2007年提出)、信息提取与检索(Zhong和Ng 于2012年提出 )、以及问题回答(Ramakrishnan等人于2003年提出)等任务的发展来说,WSD系统起到了很大的推波助澜作用。
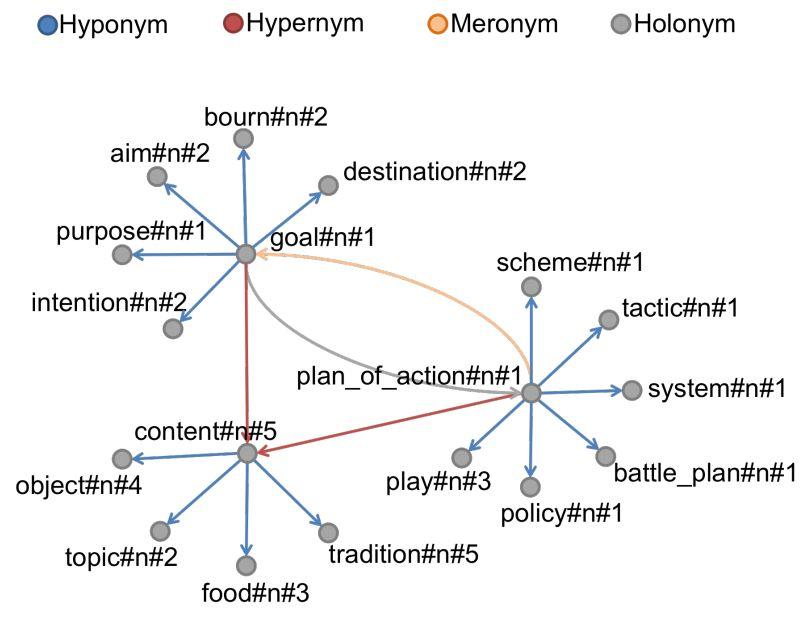
WordNet样本显示了几个同义词集以及它们之间的关系
WSD,是一个完全基于人工智能技术的产物(Navigli于2009年提出),经过二十多年的研究,现如今仍然是一个有待完善和提高的问题。继Navigli之后,我们可以大致地区分监督式和基于知识型(无监督的)的方法。监督方法需要有意义的训练数据,一般来说适用于词汇样本WSD任务,其中,在这些任务中系统需要对目标词的一组限制集进行消歧处理。然而,在全词词义消歧任务中监督系统的性能是有局限性的,因为完整词典中的标记数据是稀疏且难以获得的。由于全词词义消歧任务更加具有挑战性,且具有更多的实际应用,因此开发无监督的基于知识的系统是非常有意义的。这些系统只需要一个外部知识源(如WordNet),而不需要已标记的训练数据。
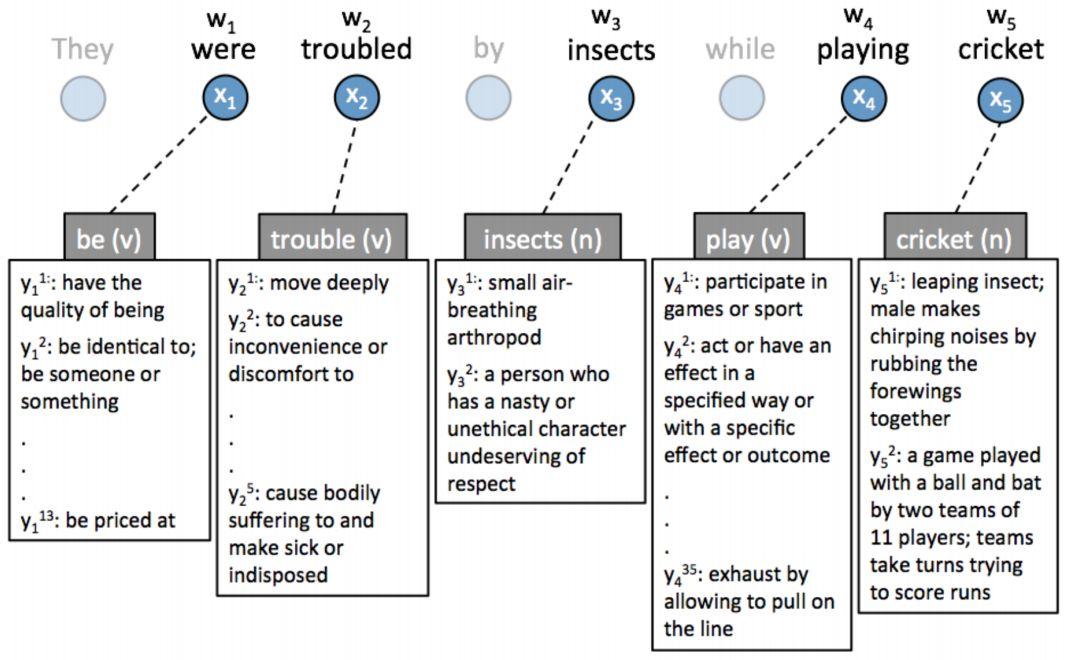
全词词义消歧任务的一个例子
本文提出了一种用于全词WSD任务的全新的基于知识型WSD算法,该算法将整个文档作为单词的上下文,而非是像大多数WSD系统那样将当前语句作为上下文。为了对WSD的整体文档进行建模,我们采用了主题模型的形式,特别是Latent Dirichlet Allocation(LDA)。我们的方法是LDA的一种变体,其中文档的主题比例被文档的同义词比例所取代。我们使用一个分布在单词上的同义词分布的非均匀先验来为一个同义词集合中单词的频率进行建模。此外,我们通过利用逻辑正太先验(logistics normal prior)绘制出文档中同义词的比例,从而对同义词之间的关系进行建模。这使得我们的模型类似于相关的主题模型,不同之处在于我们的先验知识是固定的而非学习来的。需要特别指出的是,这些先验的值是通过WodNet中的知识决定的。我们使用Senseval-2、Senseval-3、SemEval-2007、SemEval-2013和SenEval-2015五个基准数据集对我们的系统进行评估,并证明我们提出的模型优于最先进的基于知识型的WSD系统。

在一个使用该提出模型进行学习的文档中,一个以同义词和同义词比例分布方式分布的单词分布的玩具示例。在文档中,高亮标出的单词的颜色表示它们从这些单词中采样得到的相应的同义词
该模型还克服了基于LDA及其变体的主题模型的一些局限性。首先,LDA需要将主题的数量指定为一个超参数,其中,这个超参数很难进行微调。所提出的模型不需要指定同义词集的总数,因为同义词集的总数等于意义储存库中固定的同义词集的数目。其次,使用LDA所学习的主题常常没有意义,因为某些主题内的单词是不相关的。然而,同义词集总是有意义的,因为它们只包含同义词。在提出的方法中,通过在同义词中使用用于单词分布的非均匀先验来保证这一点。
尤其是在本文中,我们提出了一个新的基于知识型的WSD系统,该系统基于一个逻辑正太主题模型(logistic normal topic model),其中包含作为其先验的同义词语义信息。该模型与上下文中的单词数量呈线性关系,这使我们的系统能够将整个文档作为上下文来消除歧义,并且,评估结果表明,我们的方法在一组基准数据集上的性能标新要优于最先进的基于知识型的WSD系统。
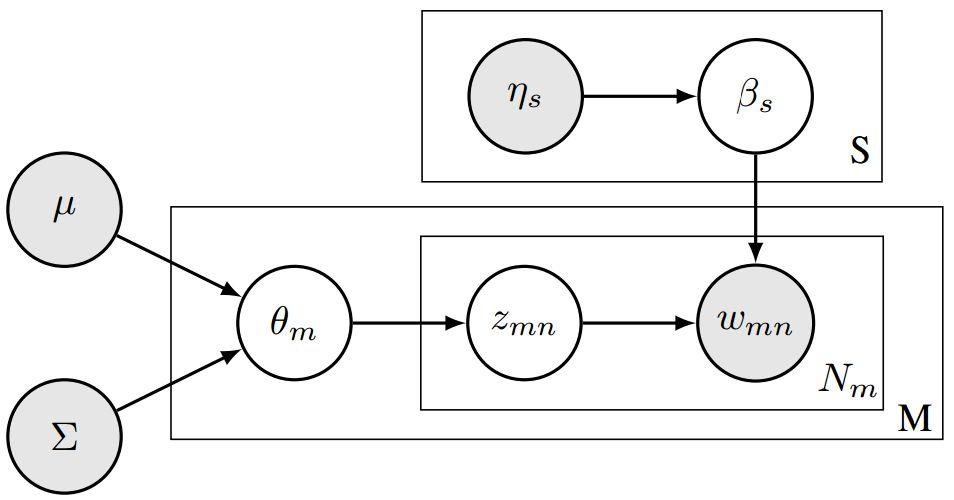
本文所提出的方法的图形模型表示
在未来,我们的一个研究方向是将这一模型用到监督式WSD系统中。这可以通过使用来自SemCor语料库的感应标签,将其作为监督主题模型中的训练数据来完成,这和Mcauliffe和 Blei在2008年提出的一个模型相类似。另一种可能是将另一个级别添加到文档生成过程的层次结构中。这将使我们能够回归主题概念,然后定义特定主题的意义分布。同样的模型也可以扩展至其他问题,如:命名实体消歧(named-entity disambiguation)。
原文链接:https://arxiv.org/pdf/1801.01900.pdf
转载于https://www.sohu.com/a/215818150_390227