目录
一、什么是DropBlock?
DropBlock 是一种正则化技术,用于深度神经网络的训练。它是对传统的 Dropout 方法的一种改进,旨在更好地处理卷积神经网络(CNN)中的特征图。
二、DropBlock与传统的DorpOut的区别
传统的 Dropout 在训练时会随机地将某些神经元的输出置零,以防止过拟合。而 DropBlock 引入了更加结构化的随机失活机制,它不是随机地丢弃单个神经元,而是随机地屏蔽一块区域的神经元。
三、DropBlock的处理方法
相比于传统的 Dropout 技术, DropBlock 不是随机屏蔽掉一部分特征(注意是对特征图进行屏蔽),而是随机屏蔽掉多个部分连续的区域。这种方法有助于减少神经网络中的冗余连接,从而提高模型的泛化能力
DropBlock 的处理方法主要包括以下几个步骤:
-
选择块: 在每个训练迭代中,随机选择一些块(blocks)。
-
屏蔽块: 对于选择的块,将整个块的输出设为零。这个过程模拟了在特定区域进行失活的效果。
-
正常训练: 使用屏蔽了一些块的特征图进行正常的反向传播和权重更新。
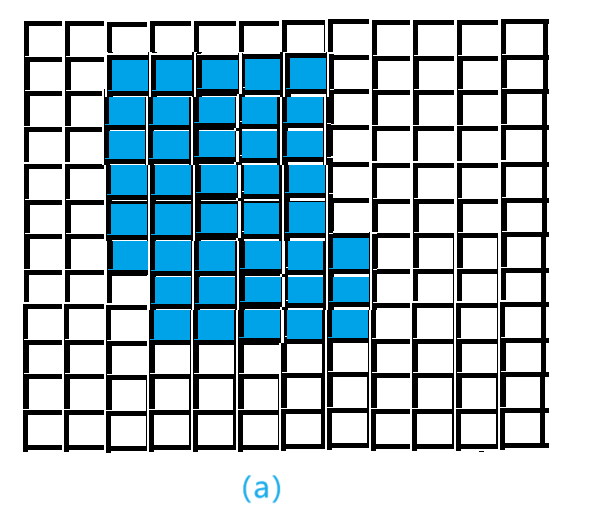
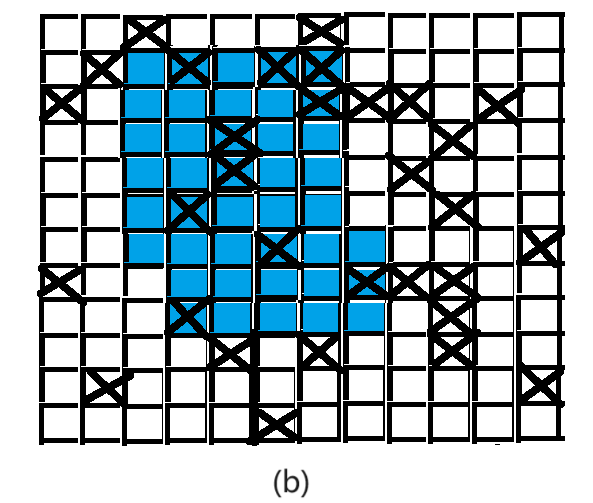
原模块 DropOut后的模块
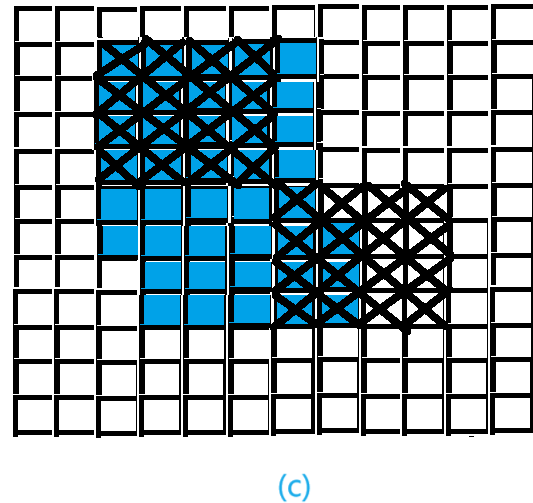

DropBlock后的模块 原图(修狗)
四、具体的算法
具体的 DropBlock 算法包括两个超参数:块大小(block size)和丢弃概率(drop probability)。块大小定义了在特征图上选择块的大小,而丢弃概率定义了在每个迭代中丢弃块的概率。
五、引入DropBlock的目的
DropBlock 的引入有助于减少过拟合,特别是在数据集相对较小的情况下。通过在网络中引入结构化的失活,DropBlock 可以防止过于依赖某些局部特征的情况,从而提高模型的泛化能力。这对于训练深度神经网络,特别是在图像分类等任务中,是一种有效的正则化手段。