一、问题描述
hbase的/hbase/.oldlogs存储空间占用过多,触发hbase-slave存储空间占用告警。在hbase-slave容器下查看.oldlog存储空间占用:
su hadoop
hdfs dfs -du -h /hbase
二、问题原因
2.1 涉及知识
HBase的Write-Ahead Log(WAL)主要用于解决因系统故障导致的数据丢失问题。当操作到达Region时,HBase会将数据首先写入WAL,并将其保存在HDFS的/hbase/.logs目录下。WAL采用环状滚动日志结构,数据被写入WAL后会被写入HDFS的/hbase/.logs目录下,而超过检查时间并且数据已经持久化后,则会移动到/hbase/.oldlogs目录下,这个过程称为滚动。如果数据超过TTL时间或不再需要作为恢复数据的备份,则数据将从/hbase/.oldlogs中删除,从而完成一份数据在WAL中的生命周期。
影响WAL文件从/hbase/.oldlogs完全删除的条件有:
- TTL进程:该进程保证WAL文件一致存货到hbase.master.logcleaner.ttl定义的超时时间
- replication被份机制:如果开启HBase备份机制,要保证备份集群已经不需要该WAL了。
2.2 问题原因
/hbase/.oldlogs的数据已经持久化到存储了,一般是用来作为灾难恢复的。正常情况下不需要保留太久的oldlogs,因此可以通过配置TTL时间让master自动清理oldlogs。
三、解决方案
3.1 确认master状态
登录http://${master}:${port}/master-status
3.2 登录hbase参数配置页面
使用浏览器打开$master_ip:$port/cm.jsp,默认账号密码是 hbase/hbase

3.3 修改参数
调整master的log保留时间,对应参数为 hbase.master.logcleaner.ttl。该值默认为259200000,代表3天,将该修改为86400000(1天):
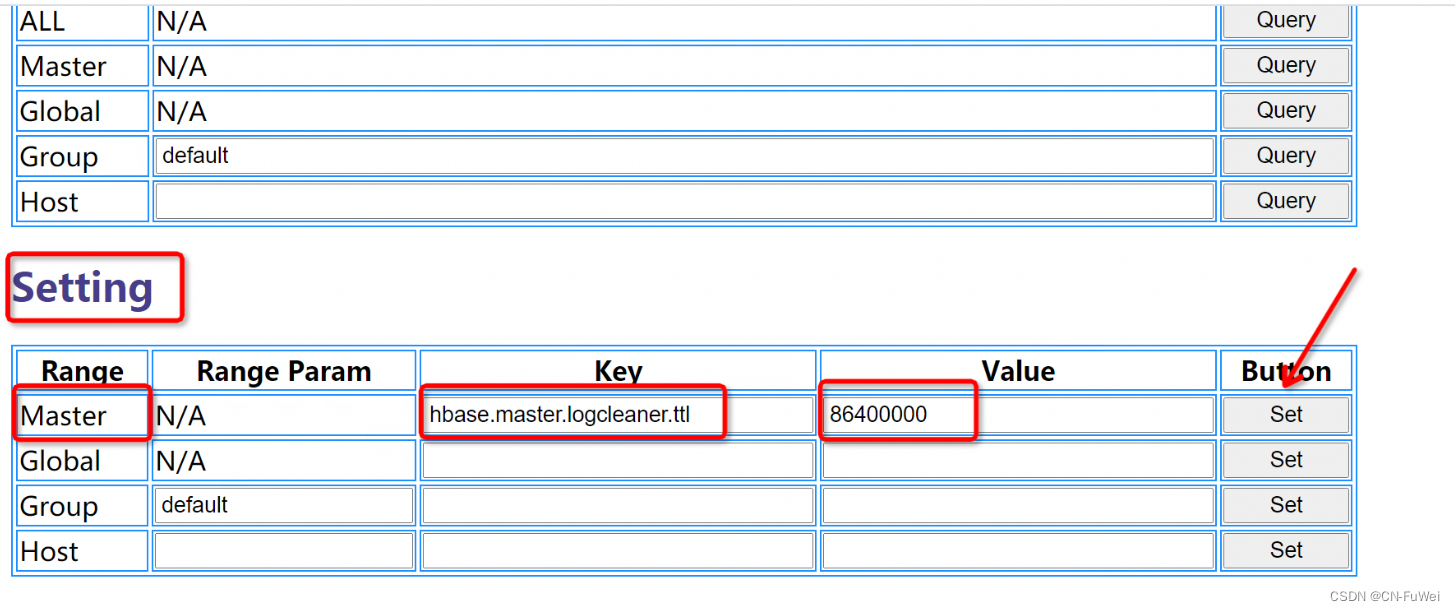
填写好对应的key和value,点击set,底部会出现success,表示配置成功。
3.4 重启Master
一般情况下部署了三台master,其中两台运行了master进程,可以通过如下命令确认运行master的服务器
ps aux|grep master
su hadoop
~/hbase-current/bin/hbase-daemon.sh stop master
~/hbase-current/bin/hbase-daemon.sh start master四、验证
查看oldlogs空间占用是否在逐渐减少:
su hadoop
hdfs dfs -du -h /hbase