 11月底,ChatGPT发布一周年,这一年真是风起云涌,ChatGPT 面世没久,我写了一篇文章《ChartGPT火出了圈,AI伴生时代已来》,这也算是开始关注AI的开端。
11月底,ChatGPT发布一周年,这一年真是风起云涌,ChatGPT 面世没久,我写了一篇文章《ChartGPT火出了圈,AI伴生时代已来》,这也算是开始关注AI的开端。
百模大战早已开启,随着中文大模型如雨后春笋般源源不断地发布,研究者和大模型爱好者们对谁是中文大模型界的扛把子争论不休。于是评测就出现了,就像手机测评、汽车测评一样,各路测评机构、评测基准应运而生,各大模型也争相在排行榜上一显身手,而且每家多多少少都会捎带上 GPT 进行对比,来凸显自己的能力。
之前每家模型发布的时候,都会附带一个排名,来标记自己在业界的位置,不过一般大家都把自己的位置排在前面,不然怎么好意思放出来呢。有兴趣的小伙伴,可以找找过去的新闻佐证一下。
最近也看了几个比较有代表性的测评榜单,比如SuperCLUE、AGIEval、FlagEval、C-Eval等等,我把一些排名的情况放在这里供大家作为参考(点击图片放大)。
C-Eval
https://cevalbenchmark.com/static/leaderboard_zh.html
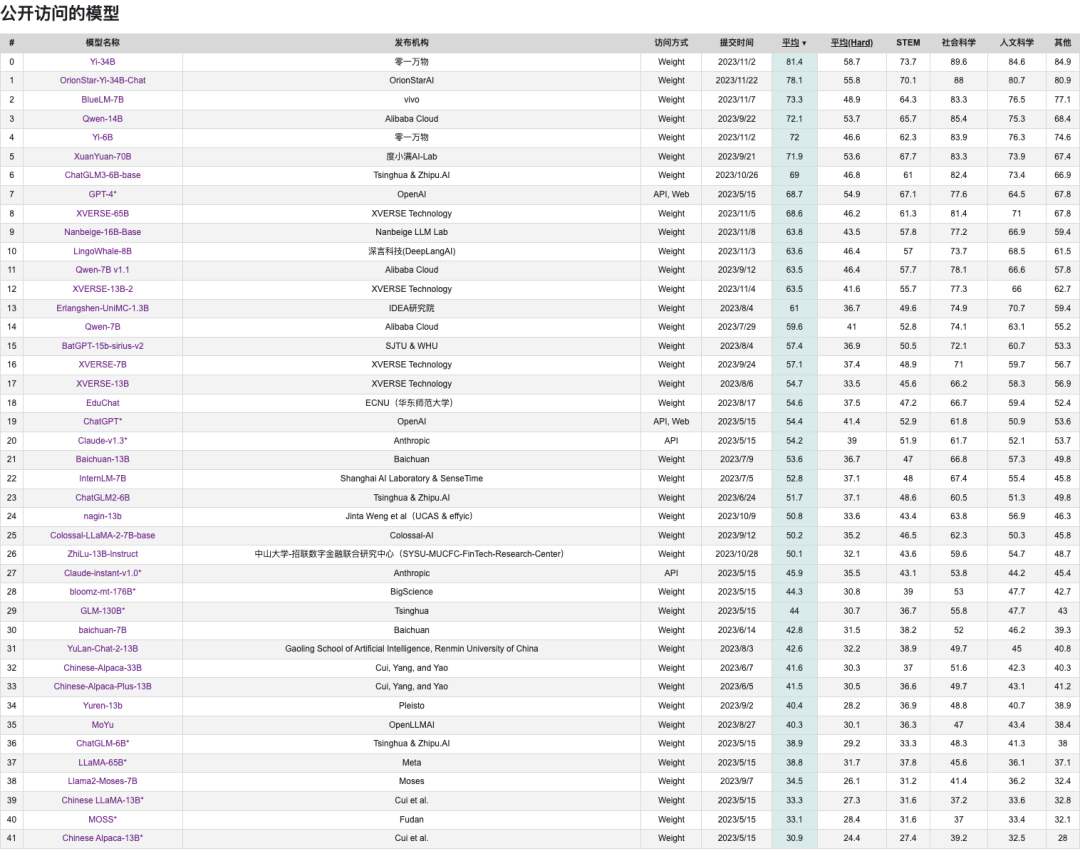
SuperCLUE
https://www.superclueai.com/
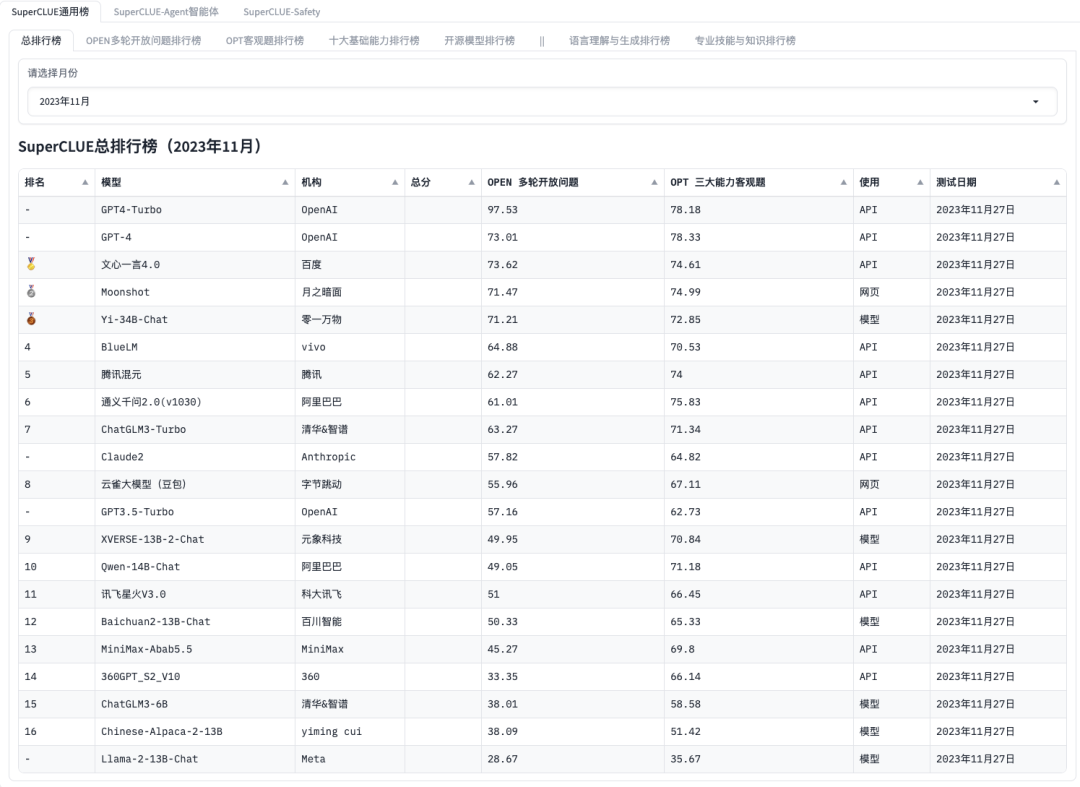
OpenCompass
https://opencompass.org.cn/leaderboard-llm

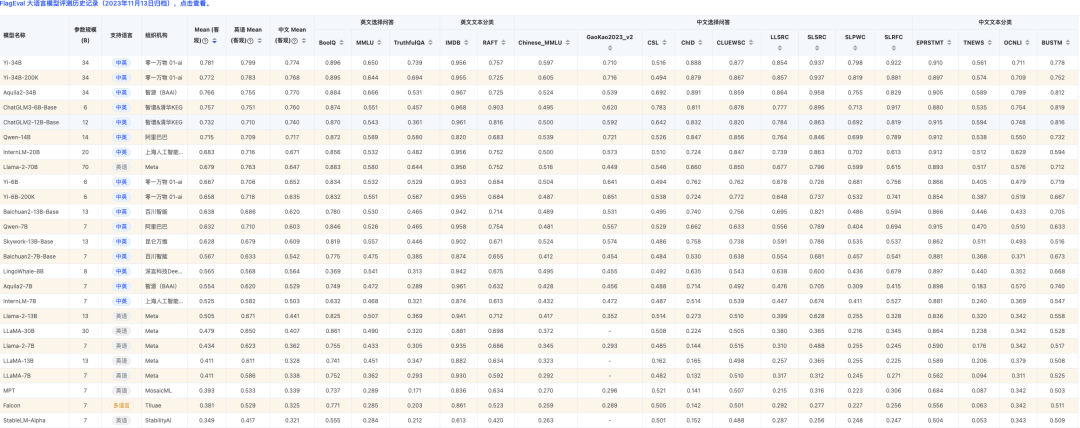
FlagEval
https://flageval.baai.ac.cn/#/home
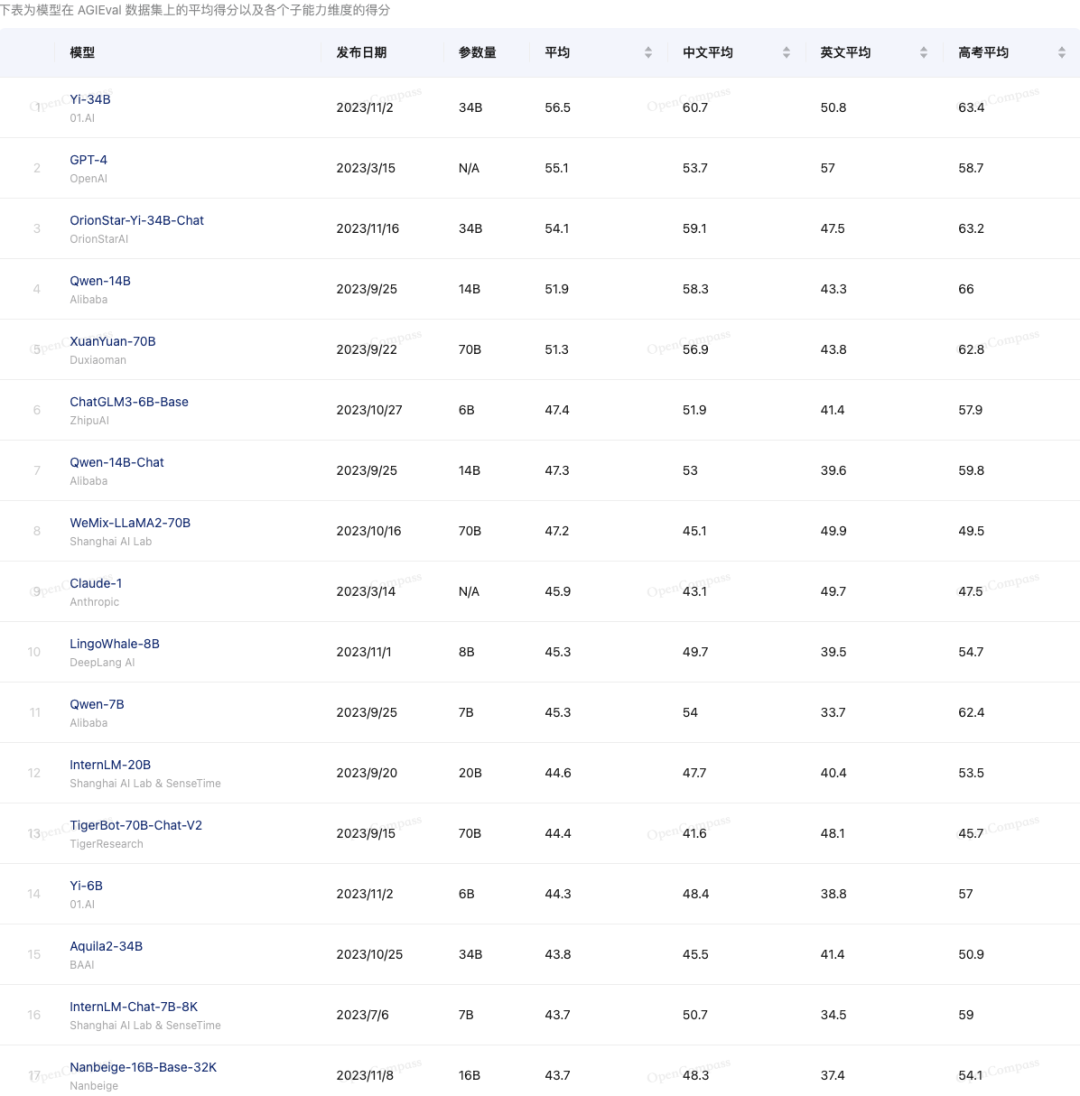
AGIEval
https://opencompass.org.cn/dataset-detail/AGIEval
我觉得 C-Eval 的声明说的还是比较中肯的,这里截取过来:
任何评测都有其局限性,以及任何的榜单都可以被不健康的刷榜。尤其是在大模型时代,大部分模型并未公开,用户也无法在实际应用中验证这些模型。例如,在榜单上得到高分的方式有:从GPT-4的预测结果蒸馏,找人工标注然后蒸馏,在网上找到原题加入训练集中微调模型 -- 然而这样得到的分数是没有意义的。因此,我们建议用户谨慎看待榜单。
从这些榜单排名看,GPT的能力确实堪忧,不过从使用效果来看,大家又都更偏向于ChatGPT,这是个迷之现象。
以上榜单仅供参考,哪个好用咱就用哪个,不必过度在意。公众号回复【大模型报告】,获取《2023中文大模型基准测评报告》。
—扩 展 阅 读—