
import requests
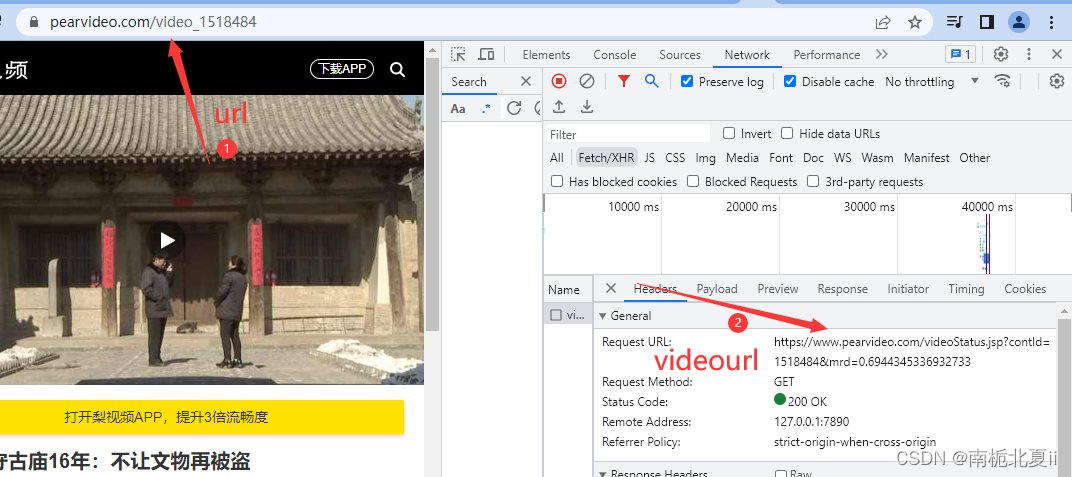
url = "https://www.pearvideo.com/video_1518484"
contId = url.split("_")[1]
videourl = "https://www.pearvideo.com/videoStatus.jsp?contId=1518484&mrd=0.6944345336932733"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
# 防盗链:溯源
"Referer":url
}
resp = requests.get(videourl,headers=headers)
# print(resp.text)
dict = resp.json()
srcurl = dict["videoInfo"]["videos"]["srcUrl"]
systemTime = dict["systemTime"]
srcurl_1 = srcurl.replace(systemTime,f"cont-{contId}")
print(srcurl_1)
# 下载视频:
try:
with open("a.mp4",mode="wb") as f:
f.write(requests.get(srcurl_1).content)
except IOError as e:
print("文件操作错误",e)