在PatchTST等一系列后续Transformer相关的工作中,使用patch进行时间序列数据处理+Transformer模型结构的方式逐渐成为时间序列预测的主流模型。然而,之前的很多工作,都使用一个固定的时间窗口进行patch处理,降低了模型对于不同scale规律性的捕捉。这也衍生出一个研究点:如何设计多粒度的patch方法,增强patch+Transformer的建模能力。
今天这篇文章,给大家汇总了近期的2篇多粒度patch+Transformer的代表工作,分别来自香港科技大学和华为。
1
Patch建模背景
基于Patch的时间序列建模方法,最早在PatchTST这篇文章中提出。通过将时间序列进行分段,每段分别用MLP映射成向量,输入到Transformer模型中,实现时间序列编码。
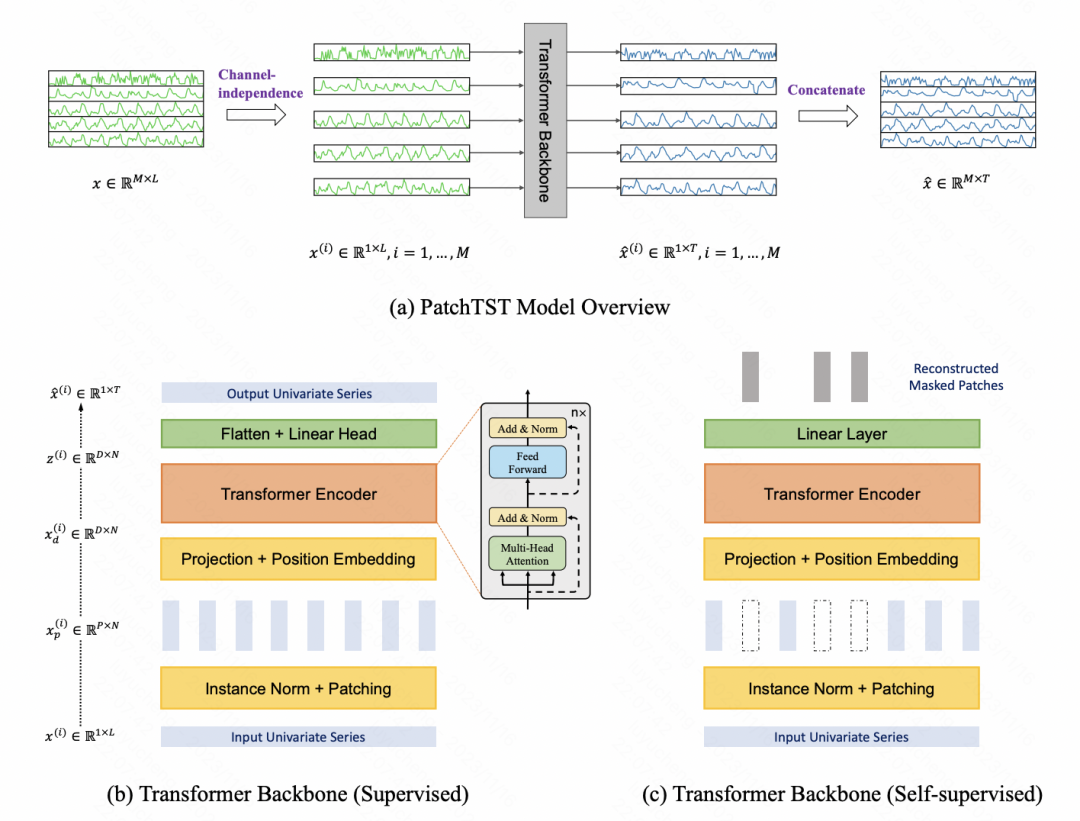
其中,Patch的生成方式,也成为后续的研究焦点。Patch的生成结果,主要由窗口大小和滑动间隔组成,不同的patch处理方式,对于后续的建模结果又比较大的影响。因此,一些工作也开始将视角转向多粒度的patch时间序列建模。
2
多尺寸MLP-Mixer

论文标题:A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
下载地址:https://arxiv.org/pdf/2310.11959v1.pdf
机构:香港科技大学
这篇文章提出了一种多粒度的patch划分时间序列模型,能够在网络的不同层,根据不同的patch尺寸自适应的进行patch划分,实现不同维度的建模。
整体的建模思路和Nbeats比较像,每一层拟合上一层的残差。在一层的MSD-Mixer网络中,首先将时间序列进行patch处理,使用一个Patch Encoder编码,生成当前层时间序列的表示向量。这个表示向量会再经过一个Decoder+Unpatching的反向处理,生成当前层的约结果,然后使用当前层的输入减去这个预测结果得到残差,作为下一层的输入和预测目标。最终使用各个层的预测结果加到一起,得到最终的预测结果。
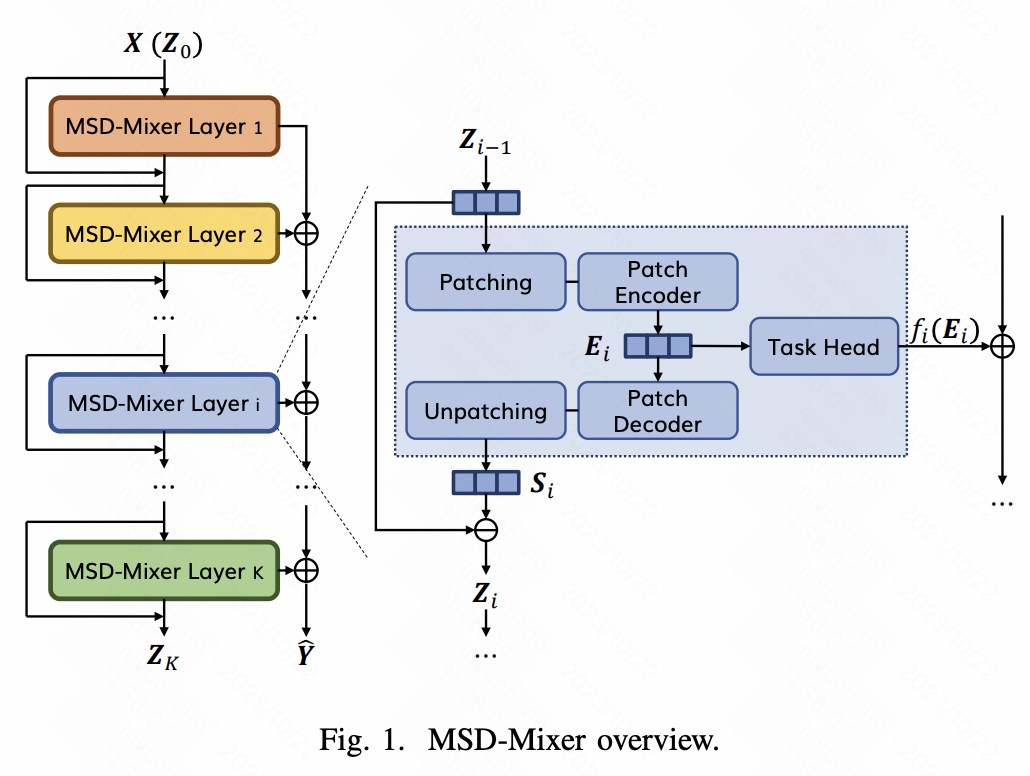
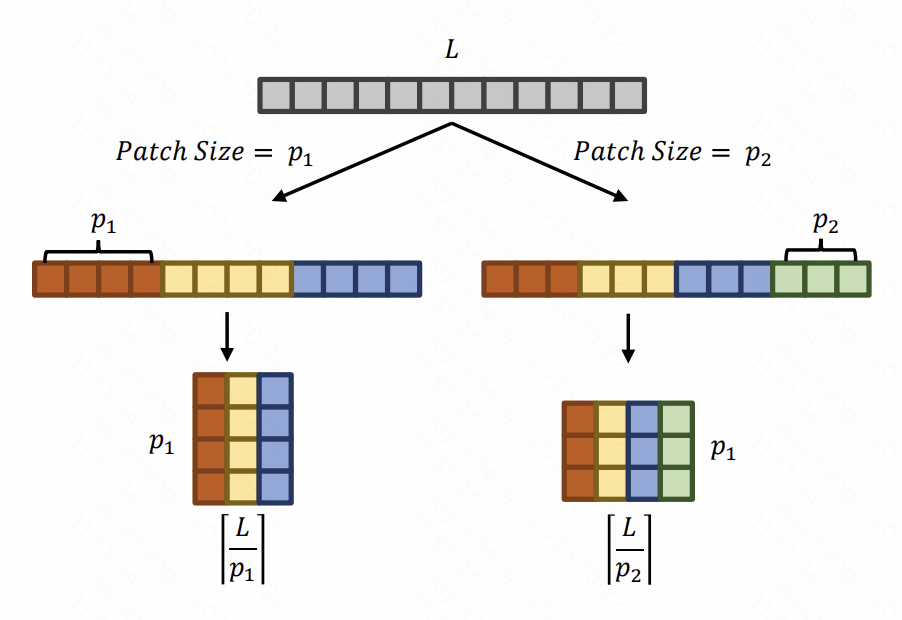
在每一层的patch中,有一个单独的patch size,生成不同scale的子序列,让不同层专注于不同scale的信息提取,每层的patch size是一个超参数。
Encoder-Decoder采用的是纯MLP结构,类似于Mixer,使用channel-wise、intra-wise、inter-wise三种类型的MLP进行embedding维度、patch内部、patch间的信息提取。
3
多尺寸Patch-Transformer

论文标题:Multi-resolution Time-Series Transformer for Long-term Forecasting
下载地址:https://arxiv.org/pdf/2311.04147v1.pdf
机构:华为
本文提出了一种多分辨率的Patch-Transformer模型本文提出了一种多尺寸patch transformer建模方法。整体模型如下图所示,对于每一层网络,会有多个分支,每个分支输入不同patch处理的时间序列。每种patch处理方式由窗口长度和步长组成。每个分支独立的使用Transformer对该patch进行编码,将各个branch的结果拼接到一起,经过线性层映射后输入到下一层。
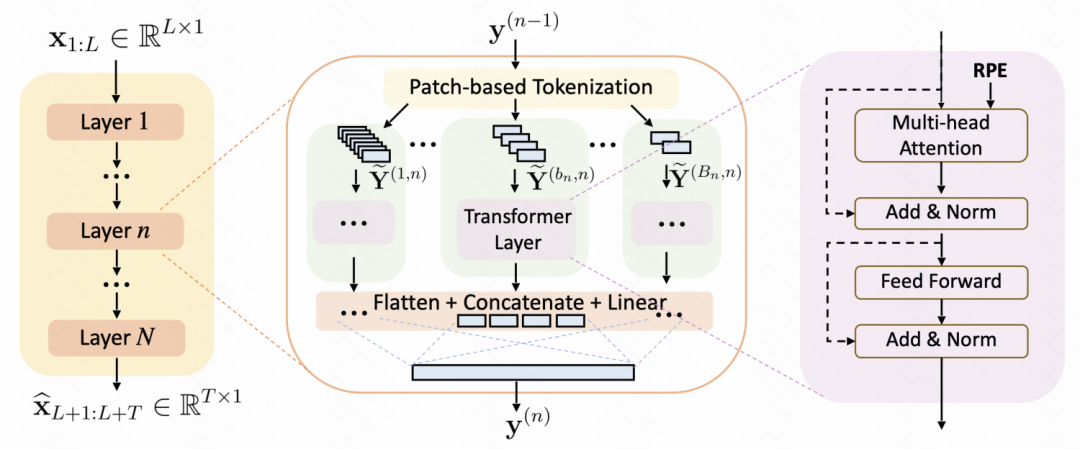
除了这种多尺寸建模方法外,文中还在Transformer中引入了相对位置编码,相对位置编码在NLP的很多大模型中都有所应用,例如ChatGLM,直接将两个位置的相对距离作为编码,文中采用三角函数生成位置编码。
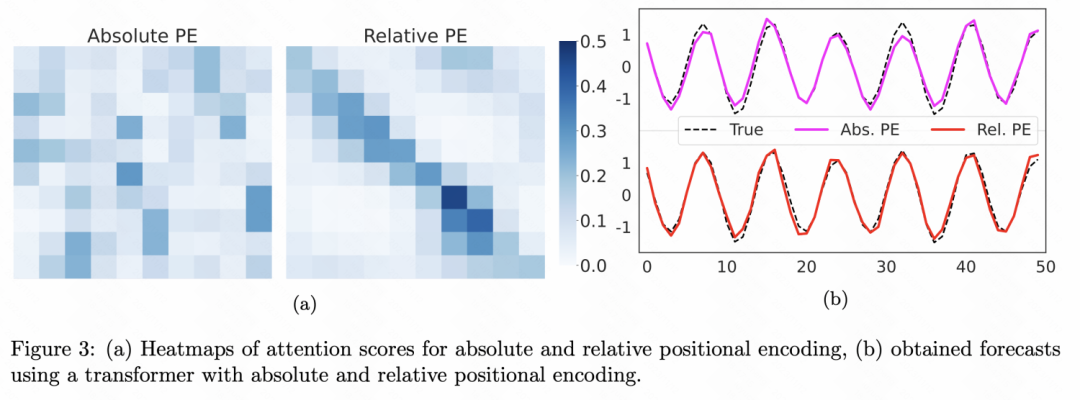
4
总结
多尺寸patch建模可以看做一个patch transformer的优化方向,目前属于研究的起步阶段,未来可能会有更多的相关工作。这种建模方式,在patch建模中引入了更多的灵活性,也越来越像CNN的底层建模方法。
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书