| 67.文献阅读笔记 |
||
| 简介 |
题目 |
Conditional Image Generation with PixelCNN Decoders |
| 作者 |
Aäron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu |
|
| 原文链接 |
||
| 关键词 |
PixelCNN |
|
| 研究问题 |
调整改进pixel cnn; 通过噪声或者不完整数据条件下生成的图像 对图像去噪、去模糊、修复、超分辨率和彩色化等图像处理任务的进步有着重大影响。 也可用于神经艺术品和内容生成。 Pixel cnn通过自回归连接对像素进行逐像素建模,每个像素都取决于其上方和左侧的所有像素,而不取决于任何其他像素。所以联合图像分布被分解为了条件句的连乘。 Pixel rnn:利用二维lstm建模;(生成性能更好) Pixel cnn:利用cnn进行建模;(更快,因为cnn本质上更加易于并行计算) |
|
| 研究方法 |
通过引入PixelCNN的门控变体( Gated PixelCNN )来结合pixelcnn 和pixelrnn,该模型在CIFAR和ImageNet上都匹配PixelRNN的对数似然,同时需要不到一半的训练时间。  在 PixelCNN 中,每个条件分布都由一个卷积神经网络建模。为确保卷积神经网络只能使用当前像素上方和左侧的像素信息,卷积的滤波器被屏蔽,如图 1(中)所示。 对于每个像素,三个颜色通道(R、G、B)都是连续建模的,B 以(R、G)为条件,G 以 R 为条件。 然后使用软最大值对每个颜色通道的 256 个可能值进行建模。PixelCNN 通常由一叠掩码卷积层组成,将 N x N x 3 图像作为输入,并将 N x N x 3 x 256 预测结果作为输出。 使用卷积层可以在训练期间并行预测所有像素(等式 1 中的所有条件分布)。在采样过程中,预测是按顺序进行的:每预测完一个像素,就会将其反馈到网络中,以预测下一个像素。这种顺序性对于生成高质量图像至关重要,因为它允许每个像素以高度非线性和多模态的方式依赖于前一个像素。 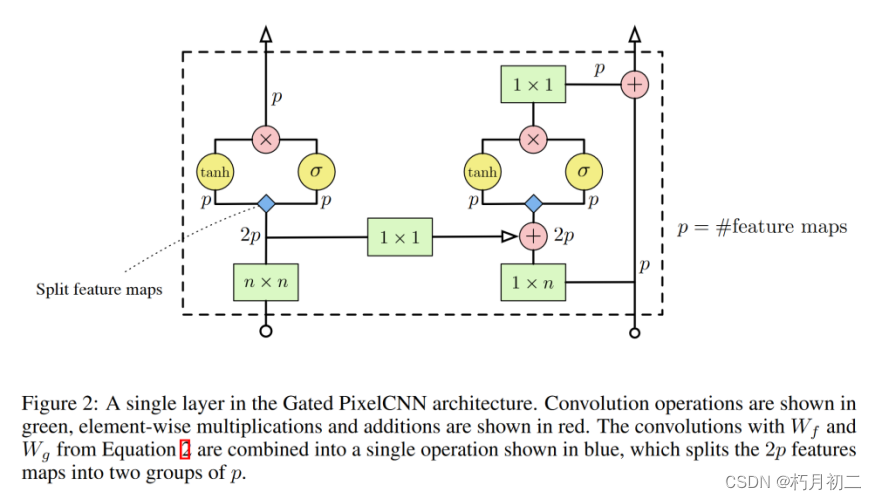 在我们的新架构中,我们使用了两组 CNN 来处理感受野中的 "盲点",这限制了原始的 PixelCNN。此外,我们还使用了门控机制,从而提高了性能和收敛速度。 |
|
| 研究结论 |
研究表明,只需对类别进行单次编码(one-hot encoding),一个条件像素网络模型就能生成狗、割草机和珊瑚礁等不同类别的图像。同样,我们也可以利用捕捉图像高层信息的嵌入来生成具有相似特征的大量图像。这样,我们就能深入了解嵌入编码中的不变量--例如,我们可以根据单张图像生成同一个人的不同姿势。同样的框架也可用于分析和解释深度神经网络中的不同层和激活。 |
|
| 创新不足 |
||
| 额外知识 |
||
| 68.文献阅读笔记 |
||
| 简介 |
题目 |
Learning to Generate Chairs with Convolutional Neural Networks |
| 作者 |
Alexey Dosovitskiy, Jost Tobias Springenberg, Thomas Brox |
|
| 原文链接 |
||
| 关键词 |
Convolutional networks, generative models, image generation, up-convolutional networks |
|
| 研究问题 |
基于随机噪声进行创意和发明新的椅子风格(根据分布向量生成图像的生成器) 根据高级描述生成准确的物体图像:样式、相对于摄像机的方向以及颜色、亮度等附加参数。 使用这些预测的分割掩码将黑色背景替换为白色背景。 |
|
| 研究方法 |
训练了生成式"上卷积"神经网络,该网络能够生成给定物体风格、视角和颜色的物体图像。 在渲染的椅子、桌子和汽车的3D模型上训练网络。 标准CNN分类倒置。 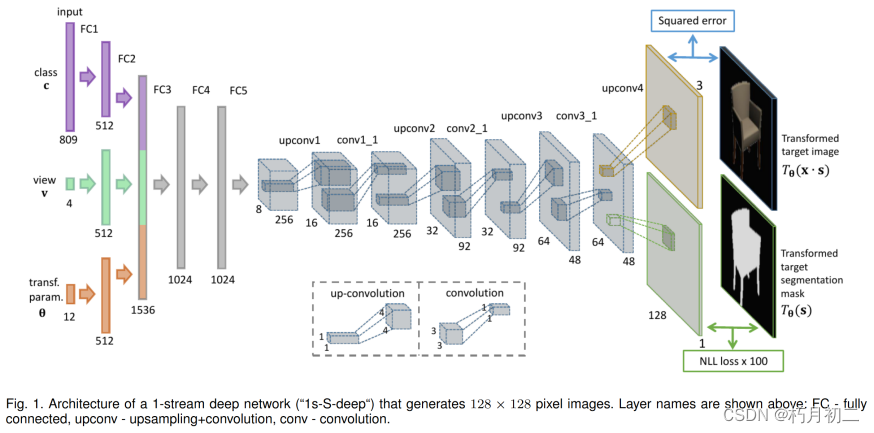 在这些层中,三个输入向量首先通过两个完全连接的层独立输入,每个层有 512 个神经元,然后将这三个流的输出串联起来。在独立处理之后,再经过两个各有 1024 个神经元的全连接层,得到第四个全连接层(FC4)的响应。网络的扩展部分 u 由 FC5 层和 upconv1 至 upconv4 层组成。它生成图像 1。我们这样做是为了处理角度的周期性。如果我们仅仅使用度数,网络将无法理解 0 度和 359 度实际上非常接近。 如图 1 所示,在其中一个层中,图像和分割掩码根据共享的特征表示生成。全连接层 FC5 输出一个 16384 维的向量,该向量被重塑为 8 × 8 的多通道图像,并通过 3 个具有 4 × 4 滤波器和 2 × 2 上采样的 "上采样+卷积 "层,每个 "上采样+卷积 "层后都有一个具有 3 × 3 滤波器的卷积层。我们发现,在每次上变频后增加一个卷积层,能显著提高生成图像的质量。最后一个上卷积层(upconv4)同时预测 RGB 图像和分割掩码。在另一种双流架构中,网络在 FC4 层之后立即分成两个流(预测 RGB 图像和分割掩码)。 生成不同视角的2d图像。
(即用一个 s × s 块替换特征图的每个条目,条目值位于左上角,其他地方为零)来实现解池。这样,特征图的宽度和高度都增加了 s 倍。我们在网络中使用的是 s = 2。 在卷积层之前进行这种上采样操作时,我们可以将上采样+卷积("upconvolution")看作是标准 CNN 中执行的卷积+池化步骤的反面,参见右图 2。该图还说明了在实际操作中,上采样和卷积步骤不必顺序执行,而是可以合并为一个操作。在我们的所有网络中,除输出层外,每一层后面都有一个整流线性(ReLU)非线性。 我们生成了 128 × 128 像素的图像,但也对 64 × 64 和 256 × 256 像素的图像进行了实验。在这些情况下,结构上的唯一区别就是分别少了或多了一次上变频。  |
|
| 研究结论 |
实验表明,网络不仅仅是通过牢记学习所有的图像,而是找到3D模型的有意义的表示,允许它们评估不同模型的相似性,在给定的视图之间进行插值以生成缺失的视图,外推视图,并通过重新组合训练实例,甚至两个不同的对象类来发明训练集中不存在的新对象。 证明了这样的生成网络可以用于从数据集中找到不同对象之间的对应关系,性能优于现有的方法 |
|
| 创新不足 |
||
| 额外知识 |
自然图像的生成建模:自然分为两个部分:学习生成图像的分布,以及学习根据分布向量生成图像的生成器。 |
|

| 69.文献阅读笔记 |
||
| 简介 |
题目 |
DRAW: A Recurrent Neural Network For Image Generation |
| 作者 |
Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, Daan Wierstra(ICML, 2015) |
|
| 原文链接 |
https://arxiv.org/pdf/1502.04623.pdf |
|
| 关键词 |
||
| 研究问题 |
(DRAW)架构代表了一种向更自然的图像构建形式的转变,在这种架构中,场景的各个部分都是独立于其他部分创建的,近似草图会被不断完善。 |
|
| 研究方法 |
Deep Recurrent Attentive Writer (DRAW) neural network architecture 编码器网络确定的是捕捉输入数据显著信息的潜在代码分布;解码器网络从代码分布中接收样本,并利用这些样本调整自己的图像分布。然而,两者之间有三个主要区别。首先,在 DRAW 中,编码器和解码器都是递归网络,因此它们之间会交换一连串代码样本;此外,编码器还能获知解码器之前的输出,从而根据解码器迄今为止的行为调整自己发送的代码。其次,解码器的输出会陆续添加到最终生成数据的分布中,而不是一步到位。第三,采用动态更新的关注机制来限制编码器观察到的输入区域和解码器修改的输出区域。简单地说,网络在每个时间步决定 "在哪里读"、"在哪里写 "以及 "写什么"。 DRAW 中的注意力模型是完全可微分的,因此可以使用标准的反向传播进行训练。 Lstm(遗忘门)在处理真实序列数据中的长程依赖性方面有着良好的记录
|
|
| 研究结论 |
本文介绍了深度循环注意力机制( Deep Recurrent Attentive Writer,DRAW )神经网络架构,并证明了其能够生成高真实感的自然图像,如房屋编号照片,以及对二值化MNIST生成的最佳已知结果的改进。我们还证明了嵌入在DRAW中的二维可微注意力机制不仅有利于图像生成,而且有利于图像分类。 |
|
| 创新不足 |
||
| 额外知识 |
||
