文章目录
背景
作为使用java技术栈的金融类公司,确保Java程序在生产环境中的稳定性和性能至关重要。由于生产环境访问受限,远程监控成为了主要的监控方式。本文将介绍如何使用一些工具来监控以太坊的Java应用程序,并深入探讨技术细节。
工具
在本文中,我们将主要使用两个工具:jconsole 和 jvisualvm。
jconsole和jvisualvm
jconsole和jvisualvm都是Java虚拟机(JVM)自带的监控工具,无需额外安装。它们提供了丰富的功能来监控和分析Java进程的性能和健康状态。虽然它们都能胜任监控任务,但它们各自具有不同的特点。
jconsole:这个工具提供了图形用户界面,用于监控Java进程。您可以通过特殊参数在被监控的远程Java进程启动时打开监控端口,并在监控机器上打开jconsole,输入相应的地址和端口以连接到远程进程。需要注意的是,在某些情况下,您可能需要在 /etc/hosts 中配置IP和名称的映射以解决连接问题。
jvisualvm:与jconsole类似,jvisualvm也提供了图形界面,但它在线程查看方面更为方便,线程以不同颜色进行标识,使您更容易识别。如果您只关注单个Java进程的内存堆详细信息,jconsole可能更适合。不过,jvisualvm在某些方面更强大,例如提供了Pending队列数量的直观显示。
注意:jvisualvm比jconsole更强大,特别是在线程查看方面。它还提供了更多的性能监控功能,因此在大多数情况下,jvisualvm可能是更好的选择。
压测实战
以太坊Java程序监控
在我们的案例中,我们使用以太坊的Java程序作为示例,该程序是一个大型Java应用程序。我们的机器资源有限(4核8GB内存),如何有效地监控这个高并发、高吞吐量的Java进程呢?
首先,让我们看一下如何使用jconsole和jvisualvm来监控这个Java进程。
1.使用jconsole监控
要使用jconsole监控远程Java进程,首先需要在远程Java进程启动时加上特殊参数,以打开监控端口。以下是一个示例命令:
java -server -XX:NewSize=3g -XX:MaxNewSize=3g -XX:InitialHeapSize=6g -XX:MaxHeapSize=6g -XX:SurvivorRatio=4 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=7979 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar ethereumj-core-1.5.0-SNAPSHOT-all.jar
接下来,在本地运行jconsole命令,并输入远程Java进程的IP和端口(例如,192.168.213.49:7979)。如果出现连接问题,请确保您的 /etc/hosts 文件中已配置IP和名称的映射。
jvisualvm比jconsole好的地方是线程查看很方便,有不同颜色标出;如果只看单个进程还是jconsole的内存堆详细
如下是监控系统的拓扑图(概略)
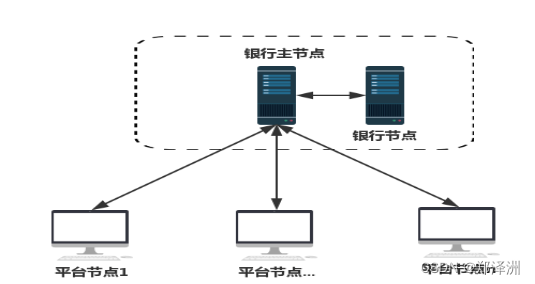
一个形象的说法是,此类命令讲究**“里应外合”**,里应就是被监控的远程java 进程启动时带上特殊参数,打开那个监控端口,外合就是我监控的机器(一般是我笔记本电脑)开始jconsole图形解密并输入对应的地址和刚才那个端口*
2.使用jvisualvm监控
jvisualvm的使用方式与jconsole类似,也分为两步。首先,您需要添加服务器的IP地址,然后使用“添加JMX连接”来输入端口信息。
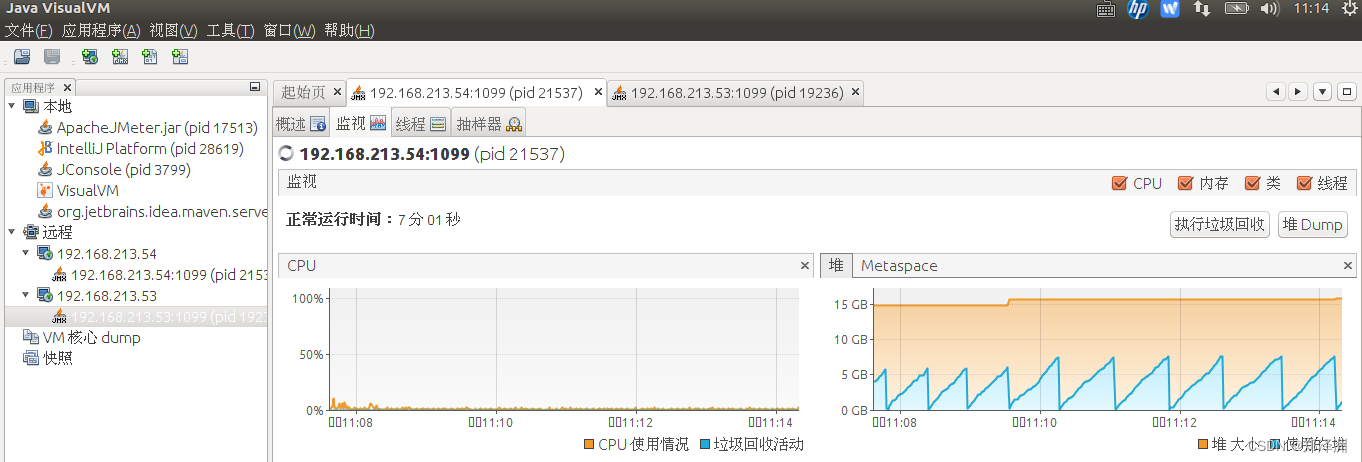
jconsole和jvisualvm可以同时连接同一台服务器的同一个端口
不仅如此,jvisualvm还具有一些优势,例如提供了Pending队列数量的直观显示,使您更容易分析性能数据。
总结一下,jvisualvm通常更加强大,并且适用于大多数监控任务。它允许您同时连接到同一台服务器的同一个端口,使监控更加灵活。
问题分析
在实际监控过程中,我们可能会遇到各种性能问题。让我们来分析一些可能的问题和解决方法。
堆内存使用异常
之前的pending队列是异步的模式下,堆内存使用一直居高不下
恢复同步模式后,经过运行,内存使用量下降了,cpu也恢复正常
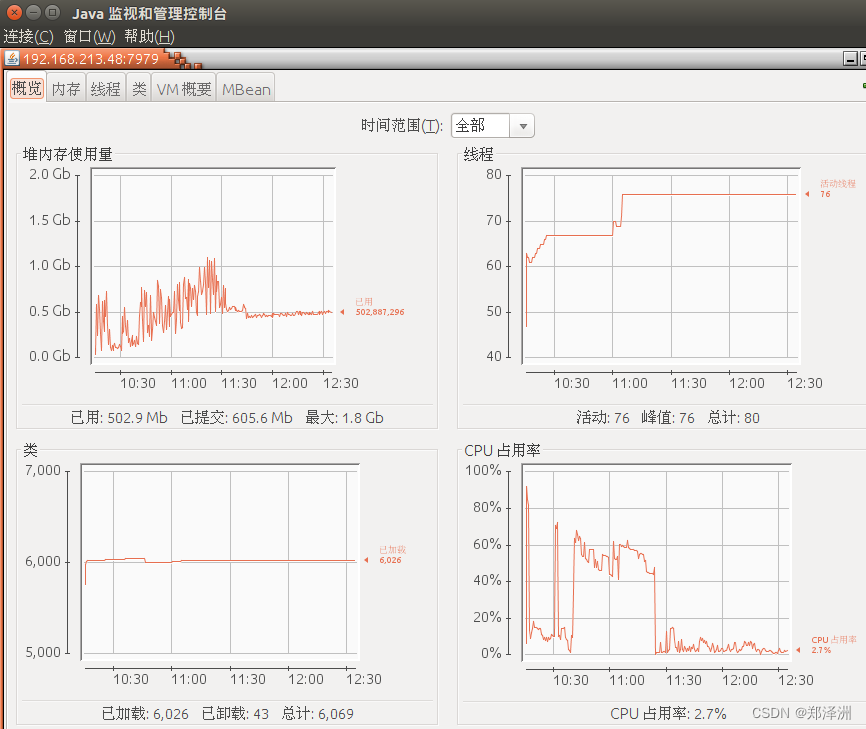
通过调整内存策略来应对:
-
Eden大 survivor和old小; 不能8:1
-
因为这里的交易,都是大量瞬时产生,异步发出后,或者记入区块后就没有用了,应该消亡了
-
以太坊的内存图谱和我的基金资金结算交易系统的很像,都是大量临时对象起来,ephemeral,后续不用了,老年代比较小
-
-
永久代的内容还是会慢慢增加,加上ethereumj本身可能的问题,还是需要每日重启节点
- 这里的重启是指银行的业务节点,可以是loadbalance下的双活,重启在晚间业务低谷,先重启另外一台,这台负责全部流量;再重启这台
交易虚增问题
春峰在压测时,发现JMeter联不上,后来就也用JConsole了
比起2个多月之前的测试,cpu进步很大,稳定在40%,线程数量也保持稳定,目前看内存泄露的风险不大,注意测试持续了12个小时,这个是首次这么长时间;而且tps有1285,系统也没崩掉
但是监控到一个问题
原来一直是200多的交易每区块,但是突然变成5156最大了,原来到每个区块是,因为Pending队列还是List的,清理的时候并发错误,但是一直在挖那个区块?
原因:
区块是有效了,各节点都认可,但是trytoConnect的时候,清理出错,结果Pending队列没有清理,写入leveldb也有问题,导致这个本来应该是事务的操作没有完成,结果就反复出同样的块了
code:

另外一段记录在区块链研究的性能测试报告那块了