MapReduce是Hadoop核心框架之一,是一种并行计算的编程模型。当我们利用Hadoop进行大数据处理时,很大一部分工作就是基于MapReduce编写数据处理程序,所以对于掌握MapReduce执行框架的组件和执行流程非常重要。本文借助WordCount程序来讲述MapReduce执行框架的组件和执行流程。
WordCount程序的作用是统计文本中出现的每个单词的次数。下面先给出WorkCount程序代码。
package MapReduceDemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
//statistics the number of words
public class WordCountMain {
public static void main(String[] args)throws Exception {
//create job = map + reduce
Configuration conf = new Configuration();
//create Job
Job job = Job.getInstance(conf);
//the entry of job
job.setJarByClass(WordCountMain.class);
//the mapper of job
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//the reducer of job
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//input and output
TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
//submit job
job.waitForCompletion(true);
}
}
package MapReduceDemo;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {
//split string
String data = value.toString();
String[] words = data.split(" ");
for(String word : words){
context.write(new Text(word),new LongWritable(1));
}
}
}
package MapReduceDemo;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text arg0, Iterable<LongWritable> arg1,Context arg2)throws IOException,InterruptedException {
long sum = 0;
for(LongWritable a : arg1){
sum += a.get();
}
arg2.write(arg0, new LongWritable(sum));
}
}
下面我们就以WordCount程序的执行流程来阐述MapReduce执行的几个阶段和所需的组件。
第一阶段:以指定格式从HDFS上读取数据。
要进行数据处理的第一步当然是读取数据,并且为了方便进行数据处理,数据必须以特定的某种格式进行读取。在MapReduce中InputFormat类就是读取数据的组件。我们知道MapReduce的核心思想是“分而治之”,所以一份大数据就必须要分成多份小数据来处理,而InputFormat类也担当将大数据分块的任务。下面是InputFormat类的职责。
(1)以某种格式读取数据。
(2)将读取的一份大数据分成逻辑意义上完整的多个块,其中每一个块是一个Mapper的输入。
(3)提供一个RecordReader类,用于将Mapper的输入(即第二中的块)转化为若干条输入记录。
Hadoop提供了一些常用的InputFormat类,每一个InputFormat类都采用特定的格式读取数据并分块。下面给出三个常用的InputFormat类。
| InputFormat类 | 描述 | 键 | 值 |
| TextInputFormat | 对文本文件一行一行的读取 | 当前行的偏移量 | 当前行内容 |
| KeyValueInputFormat | 将行解析为键值对 | 行内首个制表符前的内容 | 行内其余内容 |
| SequenceFileInputFormat | 专用于Hadoop的高性能的二进制格式 | 用户定义 | 用户定义 |
在WordCount中,我使用的是TextInputFomat类。HDFS上的源数据如下。
I Love Beijing I Love China Beijng is the capital of China
经过TextInputFomat类的读取和分块(我们假设有两个分块),以下是输入到每个Mapper中的键值对。
第一个Mapper的输入: 0:I love Beijing 第二个Mapper的输入: 0:I love China 14:Beijing is the capital of China
第二阶段:在Mapper中处理每一个键值对
怎么处理键值对完全是由用户定义的,由于WordCount程序的任务是求每个单词的个数,所以我们就对值进行分词处理了。下面是每一个Mapper的输出。
第一个Mapper的输出: I:1,Love:1,Beijing:1 第二个Mapper的输出: I:1,Love:1,China:1,Beijing:1,is:1,the:1,capital:1,of:1,China:1
第三阶段:对Mapper的输出进行合并、分区和排序处理之后作为Reducer的输入。
每一个Mapper的输出要传输到Reducer中进行处理,在第二个Mapper的输出中,我们发现有两个 China:1要进行传输,我们能不能把本来要单独进行两次传输的键值对改进成一次传输,这样做的目的就是减少网络带宽。在Hadoop中有一个Combiner类就是做这种改进的,它把具有相同主键的键值对合并在一起成为一个新的键值对,新键值对的主键还是原来的主键,值变为一个列表,列表中的元素为原来每一个键值对的值。如上述的两个 China :1 可以合并成 China:[1,1]。
一个键值对放在哪个Reducer节点上进行处理是有关系的,为了避免不同Reducer节点的数据相关性,我们要将具有相同主键的键值对放在同一个Reducer节点上进行处理。比如第一个Mapper输出的 I:1 和第二个Mapper输出的 I:1就要放在同一个Reducer节点上处理。Hadoop提供的Partitioner类就是起这个作用的。下图是每一个键值对的分区结果。
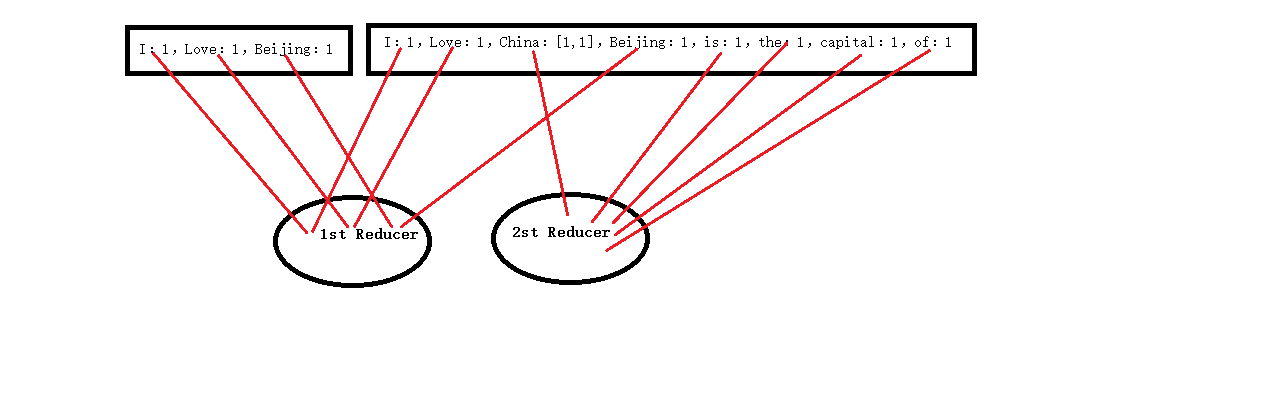
键值对进入Reducer节点之后,在每一个Reducer节点内部,会对所有键值对进行一个排序。排序默认是以主键进行升序的,当然用户可以自己定义排序操作,这需要重载Hadoop中的Sort类接口函数。在WordCount程序中我们使用默认排序。
第四阶段:在Reducer中处理并以指定格式输出最后结果。
Reducer主要是做一些整理和进一步的处理,其中的逻辑主要由用户决定,用户需要重载其reduce()方法。最后结果的输出和源数据的输入一样都有格式要求,Hadoop中的OutputFormat类就提供以指定格式进行输出的功能。下面介绍几个常用的OutputFormat类。
| OutputFormat | 描述 |
| TextOutputFormat | 一行一行输出 |
| SequenceFileOutputFormat | 二进制文件 |
| NullOutputFormat | 忽略其输入值 |
Beijing 2 China 2 I 2 capital 1 is 1 love 2 of 1 the 1
到此,本文的内容介绍完了,本文对MapReduce执行框架的组件和执行流程的见解有偏颇之处,请不吝赐教。
获取更多干货请关注微信公众号:追梦程序员。
