python使用os模块划分图片数据集、文件,切割复制文件
目录结构,这里是二分类问题,多分类可以以此类推

这里也不过多废话直接上代码
import numpy as np
import os
import shutil
# 定义划分数据集方法
def copy_img(train_dir, val_dir):
# 遍历合格、不合格目录
for i in range(0, 2):
image_data = os.listdir(f'./image/{
i}') # 获取目录中的所有图片名列表
for img in image_data: # 遍历所有图片
# 划分数据集路径,将80%的数据划分到train下,并分合格与不合格
out_img_file = os.path.join(train_dir if np.random.ranf() < 0.95 else val_dir, str(i))
# 判断划分好的输出图片路径是否存在,不存在则创建
if not os.path.exists(out_img_file):
os.makedirs(out_img_file)
# 图片原始路径
img_file = os.path.join(f'./image/{
i}', img)
# 拷贝图片,参数是图片原始路径和输出路径
shutil.copy(img_file, out_img_file)
return '拷贝完毕'
if __name__ == '__main__':
# 训练集、验证集输出路径
train_dir = os.path.join('./img', 'train')
val_dir = os.path.join('./img', 'val')
# 调用方法
s = copy_img(train_dir, val_dir)
print(s)
一、方法API
1、通过路径判断文件是否存在
-
方法:
os.path.exists(path) -
返回值:布尔类型,存在则返回true,否则则返回false。
2、新建文件夹
- 方法:
os.makedirs(path)
3、路径拼接
-
方法:
os.path.join(path1,path2) -
列:
path1 = "D:\data" path2 = "img1" imgs_path = os.path.join(path1,path2) print(imgs_path) # 打印出来:"D:\data\img1"
4、返回指定文件夹中的目录、文件名
- 方法:
os.listdir(path)
5、目录遍历器
-
方法:
os.walk() -
代码:
plant_path="D:data" # 是样本文件夹的绝对路径 for root, dirs, files in os.walk(plant_path): -
返回值:三元组,
- root :所指的是当前正在遍历的这个文件夹的本身的地址
- dirs :是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files :同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
6、拷贝文件
-
方法:
shutil.copy(path1,path2) -
解:path1是源文件路径,path2是目标文件夹路径
7、遍历列表,返回索引和值
-
方法:
enumerate(list) -
代码:
for id, list_name in enumerate(list): # 遍历list集合,得到二元组。id为集合每个值的索引、list_name为集合的值
二、案例
1、题目
①合并样本划分
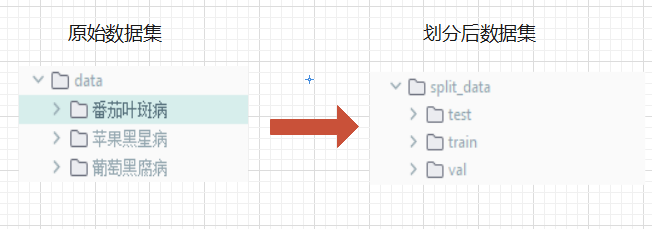
- 将数据集划分为如图所示:
其中data下每个样本文件夹(如苹果黑星病),下面都是一张一张图片。划分后数据集每个文件夹中是不同样本的图片
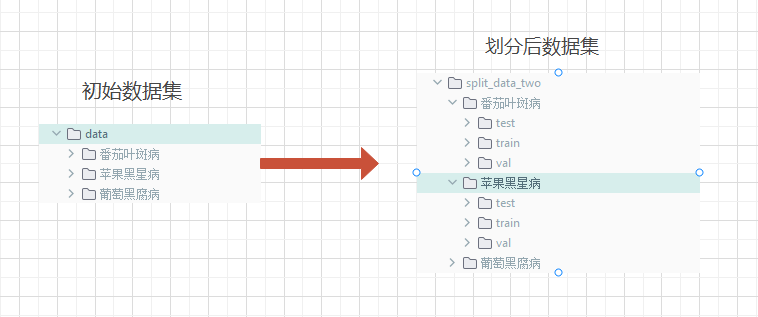
②分别样本划分
- 将数据集中每个样本都划分test、train、val:
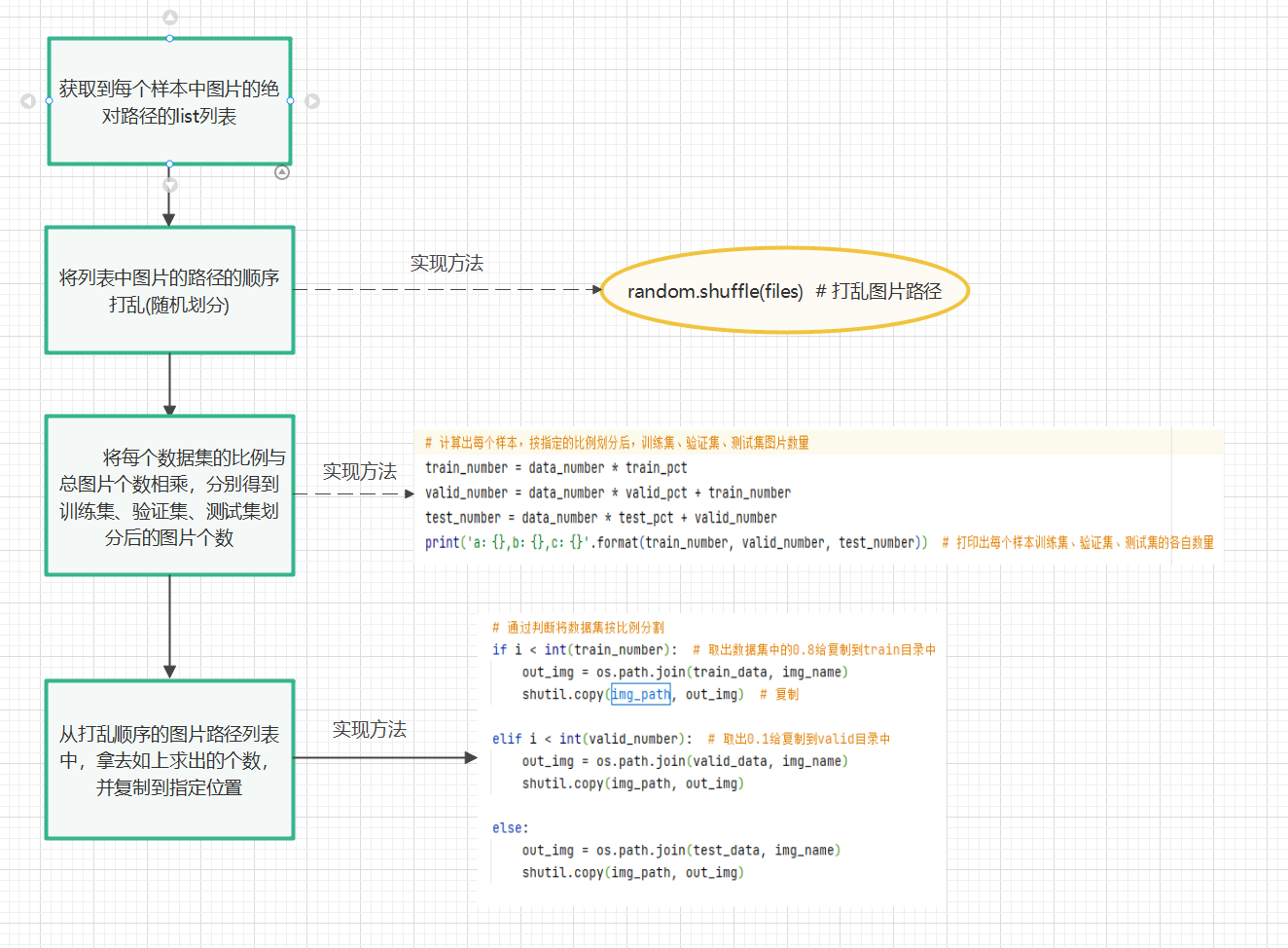
2、主体思想
3、代码
①合并样本划分
import os
import random
import shutil
"""
将样本合并并划分数据集
"""
path_data = "D:\javaBC\PyChamDm\算法\demo4\data" # 数据集存放路径(一级目录)
split_data_path = "D:\javaBC\PyChamDm\算法\demo4\split_data" # 划分后的数据集路径(一级目录)
"""超参数的设置,设置训练集、验证集、测试集的比例"""
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
train_data = os.path.join(split_data_path, "train") # 训练集文件夹路径
valid_data = os.path.join(split_data_path, "val") # 验证集文件夹路径
test_data = os.path.join(split_data_path, "test") # 测试集文件夹路径
"""
使用路径划分数据集
"""
def split_path():
for plant_name in os.listdir(path_data): # 获取到每个样本的文件夹名
plant_path = os.path.join(path_data, plant_name) # 将每个样本的文件夹名和路径拼接
for root, dirs, files in os.walk(plant_path): # files是每个图片名列表
random.shuffle(files) # 打乱图片路径
data_number = len(files) # 得到每个样本路径数量,核验数据是否缺失
print(f"{
plant_name} 样本数量:{
data_number}") # 将每个样本数打印出来
# 计算出每个样本,按指定的比例划分后,训练集、验证集、测试集图片数量
train_number = data_number * train_pct
valid_number = data_number * valid_pct + train_number
test_number = data_number * test_pct + valid_number
print('a:{},b:{},c:{}'.format(train_number, valid_number, test_number)) # 打印出每个样本训练集、验证集、测试集的各自数量
for i, img_name in enumerate(files): # 遍历列表得到列表的索引i,值img_name
img_path = os.path.join(plant_path, img_name) # 将图片名和样本路径拼接,得到每个图片的绝对路径
# 通过判断将数据集按比例分割
if i < int(train_number): # 取出数据集中的0.8给复制到train目录中
out_img = os.path.join(train_data, img_name)
shutil.copy(img_path, out_img) # 复制
elif i < int(valid_number): # 取出0.1给复制到valid目录中
out_img = os.path.join(valid_data, img_name)
shutil.copy(img_path, out_img)
else:
out_img = os.path.join(test_data, img_name)
shutil.copy(img_path, out_img)
# 主函数
if __name__ == '__main__':
# 创建划分数据集后的文件夹
if os.path.exists(split_data_path): # 判断文件夹是否存在
shutil.rmtree(split_data_path) # 删除文件夹
else:
# 创建训练集文件夹
os.makedirs(split_data_path)
os.makedirs(train_data)
os.makedirs(valid_data)
os.makedirs(test_data)
# 调用方法划分数据集
split_path()
②分别样本划分
import os
import random
import shutil
"""
将样本合并并划分数据集,合并样本划分
"""
path_data = "D:\javaBC\PyChamDm\算法\demo4\data" # 数据集存放路径(一级目录)
split_data_path = "D:\javaBC\PyChamDm\算法\demo4\split_data_two" # 划分后的数据集路径(一级目录)
"""超参数的设置,设置训练集、验证集、测试集的比例"""
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
"""
使用路径划分数据集
"""
def split_path():
"""遍历数据集(一级目录)"""
for plant_name in os.listdir(path_data): # 获取到每个样本的文件夹名
"""创建划分后的数据集文件夹,得到不同样本不同文件夹"""
train_data = os.path.join(split_data_path, plant_name, "train") # 训练集文件夹路径
valid_data = os.path.join(split_data_path, plant_name, "val") # 验证集文件夹路径
test_data = os.path.join(split_data_path, plant_name, "test") # 测试集文件夹路径
os_set(train_data, valid_data, test_data)
plant_path = os.path.join(path_data, plant_name) # 将每个样本的文件夹名和路径拼接
"""遍历每个样本(二级目录)"""
for root, dirs, files in os.walk(plant_path): # files是每个图片名列表
random.shuffle(files) # 打乱图片路径
data_number = len(files) # 得到每个样本路径数量,核验数据是否缺失
print(f"{
plant_name} 样本数量:{
data_number}") # 将每个样本数打印出来
# 计算出每个样本,按指定的比例划分后,训练集、验证集、测试集图片数量
train_number = data_number * train_pct
valid_number = data_number * valid_pct + train_number
test_number = data_number * test_pct + valid_number
print('a:{},b:{},c:{}'.format(train_number, valid_number, test_number)) # 打印出每个样本训练集、验证集、测试集的各自数量
for i, img_name in enumerate(files): # 遍历列表得到列表的索引i,值img_name
img_path = os.path.join(plant_path, img_name) # 将图片名和样本路径拼接,得到每个图片的绝对路径
# 通过判断将数据集按比例分割
if i < int(train_number): # 取出数据集中的0.8给复制到train目录中
out_img = os.path.join(train_data, img_name)
shutil.copy(img_path, out_img) # 复制
elif i < int(valid_number): # 取出0.1给复制到valid目录中
out_img = os.path.join(valid_data, img_name)
shutil.copy(img_path, out_img)
else:
out_img = os.path.join(test_data, img_name)
shutil.copy(img_path, out_img)
def os_set(train_data, valid_data, test_data):
# 创建训练集文件夹
os.makedirs(train_data)
os.makedirs(valid_data)
os.makedirs(test_data)
# 主函数
if __name__ == '__main__':
# 创建划分数据集后的文件夹
if os.path.exists(split_data_path): # 判断文件夹是否存在
shutil.rmtree(split_data_path) # 删除文件夹
else:
os.makedirs(split_data_path)
# 调用方法划分数据集
split_path(