目录
一 什么是线性模型
1.1 定义

1.2 回归和分类的转换

1.3 几何解释

二 线性回归
2.1 定义

2.2 参数学习方法


三 Logistic回归
3.1 定义
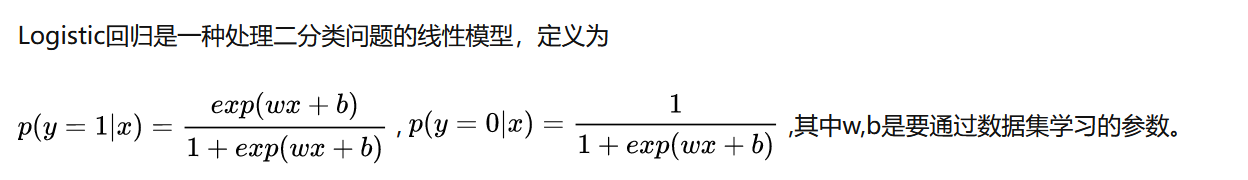
3.2 参数学习方法

四 SoftMax回归
4.1 定义

4.2 参数学习方法
同样采用交叉熵损失函数进行参数学习
五 感知机
5.1 定义

5.2 参数学习方法
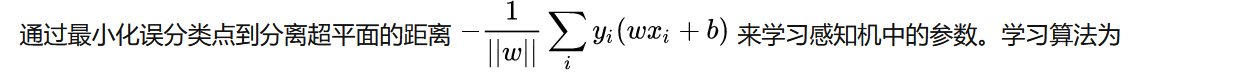
输入:训练集D,最大迭代次数T
初始化:w_0 <- 0,k <- 0,t <- 0
repeat
对训练集D进行随机打乱
for n=1...N do
选取一个样本(x_n,y_n)
if y_n*w_k*x_n <=0 then
w_k+1 <- w_k+y_n*x_n
k <- k+1
end
t <- t+1
if t=T then
break
end
until t=T
输出:w_k六 支持向量机
6.1 定义
当训练数据线性可分时,通过硬间隔最大化,可以学习一个线性的分类器,称为线性可分支持向量机或硬间隔支持向量机。
当训练数据近似线性可分时,通过软间隔最大化,也可以学习一个线性的分类器,称为线性支持向量机或软间隔支持向量机。
当训练数据非线性可分时,通过使用核技巧及软间隔最大化,可以学习一个非线性支持向量机。
6.2 核函数和核方法
当输入空间为欧式空间或离散集合,特征空间为希尔伯特空间时,核函数表示将输入从输入空间映射到特征空间得到的特征向量之间的内积,通过核函数可以学习非线性支持向量机,其等价于隐式的在高维的特征空间中学习非线性支持向量机。这种方法称为核技巧、核方法。

6.3 参数学习方法

七 Numpy实现代码
7.1 Logistic回归
import numpy as np
# Logistic回归
class LogisticRegression:
def __init__(self, n_iter=200, eta=1e-3, tol=None):
# 训练迭代的次数
self.n_iter = n_iter
# 学习率
self.eta = eta
# 损失函数变化阈值
self.tol = tol
# 模型参数w(训练时初始化)
self.w = None
def _z(self, X, w):
'''g(x)函数: 计算x与w的内积.'''
return np.dot(X, w)
def _sigmoid(self, z):
'''Logistic函数'''
return 1. / (1. + np.exp(-z))
def _predict_proba(self, X, w):
'''h(x)函数: 预测y为1的概率.'''
z = self._z(X, w)
return self._sigmoid(z)
def _loss(self, y, y_proba):
'''计算损失'''
# y_proba是预测值
m = y.size
# 求对数似然函数(也是交叉熵分类损失)
p = y_proba * (2 * y - 1) + (1 - y)
result = -np.sum(np.log(p)) / m
return result
def _gradient(self, X, y, y_proba):
'''计算梯度'''
# 对上面的对数似然函数关于参数w求导
return np.matmul(y_proba - y, X) / y.size
def _gradient_descent(self, w, X, y):
'''梯度下降算法'''
# 若用户指定tol, 则使用早期停止法.
if self.tol is not None:
loss_old = np.inf
self.loss_list = []
# 使用梯度下降法迭代n_iter次, 更新模型的参数w.
for step_i in range(self.n_iter):
# 预测所有点的概率
y_proba = self._predict_proba(X, w)
# 计算损失
loss = self._loss(y, y_proba)
self.loss_list.append(loss)
# print('%4i Loss: %s' % (step_i, loss))
# 早期停止法
if self.tol is not None:
# 如果损失下降不足阈值, 则终止迭代.
if loss_old - loss < self.tol:
break
loss_old = loss
# 计算梯度
grad = self._gradient(X, y, y_proba)
# 梯度下降,更新参数w
w -= self.eta * grad
def _preprocess_data_X(self, X):
'''数据预处理'''
# 扩展X, 添加x0列并置1.
m, n = X.shape
X_ = np.empty((m, n + 1))
X_[:, 0] = 1
X_[:, 1:] = X
return X_
def train(self, X_train, y_train):
'''训练'''
# 预处理X_train(添加x0=1)
X_train = self._preprocess_data_X(X_train)
# 初始化参数向量w
_, n = X_train.shape
self.w = np.random.random(n) * 0.05
# 执行梯度下降训练w
self._gradient_descent(self.w, X_train, y_train)
def predict(self, X):
'''预测'''
# 使用训练完毕的模型进行训练
# 预处理X_test(添加x0=1)
X = self._preprocess_data_X(X)
# 预测概率值
y_pred = self._predict_proba(X, self.w)
# 根据概率预测类别
return np.where(y_pred >= 0.5, 1, 0)7.2 SoftMax回归
import numpy as np
# SoftMax回归
class SoftmaxRegression:
def __init__(self, n_iter=200, eta=1e-3, tol=None):
# 训练的迭代次数
self.n_iter = n_iter
# 学习率
self.eta = eta
# 损失函数变化阈值
self.tol = tol
# 模型参数W(训练时初始化)
self.W = None
def _z(self, X, W):
'''g(x)函数: 计算x与w的内积.'''
if X.ndim == 1:
return np.dot(W, X)
return np.matmul(X, W.T)
def _softmax(self, Z):
'''softmax函数'''
E = np.exp(Z)
if Z.ndim == 1:
return E / np.sum(E)
return E / np.sum(E, axis=1, keepdims=True)
def _predict_proba(self, X, W):
'''h(x)函数: 预测y为各个类别的概率.'''
Z = self._z(X, W)
return self._softmax(Z)
def _loss(self, y, y_proba):
'''计算损失'''
m = y.size
# 对数似然函数(交叉熵损失)
p = y_proba[range(m), y]
return -np.sum(np.log(p)) / m
def _gradient(self, xi, yi, yi_proba):
'''计算梯度'''
# 构造一个真实标签
K = yi_proba.size
y_bin = np.zeros(K)
y_bin[yi] = 1
# 返回梯度
return (yi_proba - y_bin)[:, None] * xi
def _stochastic_gradient_descent(self, W, X, y):
'''随机梯度下降算法'''
# 若用户指定tol, 则使用早期停止法.
if self.tol is not None:
loss_old = np.inf
end_count = 0
# 使用随机梯度下降至多迭代n_iter次, 更新w.
m = y.size
idx = np.arange(m)
for step_i in range(self.n_iter):
# 计算损失
y_proba = self._predict_proba(X, W)
loss = self._loss(y, y_proba)
print('%4i Loss: %s' % (step_i, loss))
# 早期停止法
if self.tol is not None:
# 随机梯度下降的loss曲线不像批量梯度下降那么平滑(上下起伏),
# 因此连续多次(而非一次)下降不足阈值, 才终止迭代.
if loss_old - loss < self.tol:
end_count += 1
if end_count == 5:
break
else:
end_count = 0
loss_old = loss
# 每一轮迭代之前, 随机打乱训练集.
np.random.shuffle(idx)
for i in idx:
# 预测xi为各类别概率
yi_proba = self._predict_proba(X[i], W)
# 计算梯度
grad = self._gradient(X[i], y[i], yi_proba)
# 更新参数w
W -= self.eta * grad
def _preprocess_data_X(self, X):
'''数据预处理'''
# 扩展X, 添加x0列并置1.
m, n = X.shape
X_ = np.empty((m, n + 1))
X_[:, 0] = 1
X_[:, 1:] = X
return X_
def train(self, X_train, y_train):
'''训练'''
# 预处理X_train(添加x0=1)
X_train = self._preprocess_data_X(X_train)
# 初始化参数向量W
k = np.unique(y_train).size
_, n = X_train.shape
self.W = np.random.random((k, n)) * 0.05
# 执行随机梯度下降训练W
self._stochastic_gradient_descent(self.W, X_train, y_train)
def predict(self, X):
'''预测'''
# 预处理X_test(添加x0=1)
X = self._preprocess_data_X(X)
# 对每个实例计算向量z.
Z = self._z(X, self.W)
# 向量z中最大分量的索引即为预测的类别.
return np.argmax(Z, axis=1)7.3 支持向量机
import numpy as np
# 采用SMO优化方法的支持向量机模型
class SMO:
def __init__(self, C, tol, kernel='rbf', gamma=None):
# 惩罚系数
self.C = C
# 优化过程中alpha步进阈值
self.tol = tol
# 核函数
if kernel == 'rbf':
#高斯核函数
self.K = self._gaussian_kernel
self.gamma = gamma
else:
#线性核函数
self.K = self._linear_kernel
def _gaussian_kernel(self, U, v):
'''高斯核函数'''
if U.ndim == 1:
p = np.dot(U - v, U - v)
else:
p = np.sum((U - v) * (U - v), axis=1)
return np.exp(-self.gamma * p)
def _linear_kernel(self, U, v):
'''线性核函数'''
return np.dot(U, v)
def _g(self, x):
'''函数g(x)'''
alpha, b, X, y, E = self.args
idx = np.nonzero(alpha > 0)[0]
if idx.size > 0:
return np.sum(y[idx] * alpha[idx] * self.K(X[idx], x)) + b[0]
return b[0]
def _optimize_alpha_i_j(self, i, j):
'''优化alpha_i, alpha_j'''
alpha, b, X, y, E = self.args
C, tol, K = self.C, self.tol, self.K
# 优化需有两个不同alpha
if i == j:
return 0
# 计算alpha[j]的边界
if y[i] != y[j]:
L = max(0, alpha[j] - alpha[i])
H = min(C, C + alpha[j] - alpha[i])
else:
L = max(0, alpha[j] + alpha[i] - C)
H = min(C, alpha[j] + alpha[i])
# L == H 时已无优化空间(一个点).
if L == H:
return 0
# 计算eta
eta = K(X[i], X[i]) + K(X[j], X[j]) - 2 * K(X[i], X[j])
if eta <= 0:
return 0
# 对于alpha非边界, 使用E缓存. 边界alpha, 动态计算E.
if 0 < alpha[i] < C:
E_i = E[i]
else:
E_i = self._g(X[i]) - y[i]
if 0 < alpha[j] < C:
E_j = E[j]
else:
E_j = self._g(X[j]) - y[j]
# 计算alpha_j_new
alpha_j_new = alpha[j] + y[j] * (E_i - E_j) / eta
# 对alpha_j_new进行剪辑
if alpha_j_new > H:
alpha_j_new = H
elif alpha_j_new < L:
alpha_j_new = L
alpha_j_new = np.round(alpha_j_new, 7)
# 判断步进是否足够大
if np.abs(alpha_j_new - alpha[j]) < tol * (alpha_j_new + alpha[j] + tol):
return 0
# 计算alpha_i_new
alpha_i_new = alpha[i] + y[i] * y[j] * (alpha[j] - alpha_j_new)
alpha_i_new = np.round(alpha_i_new, 7)
# 计算b_new
b1 = b[0] - E_i \
- y[i] * (alpha_i_new - alpha[i]) * K(X[i], X[i]) \
- y[j] * (alpha_j_new - alpha[j]) * K(X[i], X[j])
b2 = b[0] - E_j \
- y[i] * (alpha_i_new - alpha[i]) * K(X[i], X[j]) \
- y[j] * (alpha_j_new - alpha[j]) * K(X[j], X[j])
if 0 < alpha_i_new < C:
b_new = b1
elif 0 < alpha_j_new < C:
b_new = b2
else:
b_new = (b1 + b2) / 2
# 更新E缓存
# 更新E[i],E[j]. 若优化后alpha若不在边界, 缓存有效且值为0.
E[i] = E[j] = 0
# 更新其他非边界alpha对应的E[k]
mask = (alpha != 0) & (alpha != C)
mask[i] = mask[j] = False
non_bound_idx = np.nonzero(mask)[0]
for k in non_bound_idx:
E[k] += b_new - b[0] + y[i] * K(X[i], X[k]) * (alpha_i_new - alpha[i]) \
+ y[j] * K(X[j], X[k]) * (alpha_j_new - alpha[j])
# 更新alpha_i, alpha_i
alpha[i] = alpha_i_new
alpha[j] = alpha_j_new
# 更新b
b[0] = b_new
return 1
def _optimize_alpha_i(self, i):
'''优化alpha_i, 内部寻找alpha_j.'''
alpha, b, X, y, E = self.args
# 对于alpha非边界, 使用E缓存. 边界alpha, 动态计算E.
if 0 < alpha[i] < self.C:
E_i = E[i]
else:
E_i = self._g(X[i]) - y[i]
# alpha_i仅在违反KKT条件时进行优化.
if (E_i * y[i] < -self.tol and alpha[i] < self.C) or \
(E_i * y[i] > self.tol and alpha[i] > 0):
# 按优先级次序选择alpha_j.
# 分别获取非边界alpha和边界alpha的索引
mask = (alpha != 0) & (alpha != self.C)
non_bound_idx = np.nonzero(mask)[0]
bound_idx = np.nonzero(~mask)[0]
# 优先级(-1)
# 若非边界alpha个数大于1, 寻找使得|E_i - E_j|最大化的alpha_j.
if len(non_bound_idx) > 1:
if E[i] > 0:
j = np.argmin(E[non_bound_idx])
else:
j = np.argmax(E[non_bound_idx])
if self._optimize_alpha_i_j(i, j):
return 1
# 优先级(-2)
# 随机迭代非边界alpha
np.random.shuffle(non_bound_idx)
for j in non_bound_idx:
if self._optimize_alpha_i_j(i, j):
return 1
# 优先级(-3)
# 随机迭代边界alpha
np.random.shuffle(bound_idx)
for j in bound_idx:
if self._optimize_alpha_i_j(i, j):
return 1
return 0
def train(self, X_train, y_train):
'''训练'''
m, _ = X_train.shape
# 初始化向量alpha和标量b
alpha = np.zeros(m)
b = np.zeros(1)
# 创建E缓存
E = np.zeros(m)
# 将各方法频繁使用的参数收集到列表, 供调用时传递.
self.args = [alpha, b, X_train, y_train, E]
n_changed = 0
examine_all = True
while n_changed > 0 or examine_all:
n_changed = 0
# 迭代alpha_i
for i in range(m):
if examine_all or 0 < alpha[i] < self.C:
n_changed += self._optimize_alpha_i(i)
print('n_changed: %s' % n_changed)
print('sv num: %s' % np.count_nonzero((alpha > 0) & (alpha < self.C)))
# 若当前迭代非边界alpha, 且没有alpha改变, 下次迭代所有alpha.
# 否则, 下次迭代非边界间alpha.
examine_all = (not examine_all) and (n_changed == 0)
# 训练完成后保存模型参数:
idx = np.nonzero(alpha > 0)[0]
# 1.非零alpha
self.sv_alpha = alpha[idx]
# 2.支持向量,
self.sv_X = X_train[idx]
self.sv_y = y_train[idx]
# 3.b.
self.sv_b = b[0]
def _predict_one(self, x):
'''对单个输入进行预测'''
k = self.K(self.sv_X, x)
return np.sum(self.sv_y * self.sv_alpha * k) + self.sv_b
def predict(self, X_test):
'''预测'''
y_pred = np.apply_along_axis(self._predict_one, 1, X_test)
return np.squeeze(np.where(y_pred > 0, 1., -1.))
八 Scikit-learn实现代码
8.1 Logistic回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from scipy.special import expit
# 自定义一个数据集
xmin, xmax = -5, 5
n_samples = 100
np.random.seed(0)
X = np.random.normal(size=n_samples)
y = (X > 0).astype(float)
X[X > 0] *= 4
X += .3 * np.random.normal(size=n_samples)
X = X[:, np.newaxis]
# 使用Logistic回归模型
clf = linear_model.LogisticRegression(C=1e5)
clf.fit(X, y)
# 画出结果
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.scatter(X.ravel(), y, color='black', zorder=20)
X_test = np.linspace(-5, 10, 300)
loss = expit(X_test * clf.coef_ + clf.intercept_).ravel()
plt.plot(X_test, loss, color='red', linewidth=3)8.2 支持向量机
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
# 画网格
def make_meshgrid(x, y, h=.02):
x_min, x_max = x.min() - 1, x.max() + 1
y_min, y_max = y.min() - 1, y.max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
# 画分割超平面
def plot_contours(ax, clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
# 使用Iris数据集
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
# 支持向量机正则化超参数
C = 1.0
# svm.SVC()是支持向量机分类模型
models = (svm.SVC(kernel='linear', C=C),
svm.LinearSVC(C=C, max_iter=10000),
svm.SVC(kernel='rbf', gamma=0.7, C=C),
svm.SVC(kernel='poly', degree=3, gamma='auto', C=C))
models = (clf.fit(X, y) for clf in models)
# 标题
titles = ('SVC with linear kernel',
'LinearSVC (linear kernel)',
'SVC with RBF kernel',
'SVC with polynomial (degree 3) kernel')
# 画图
fig, sub = plt.subplots(2, 2)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
X0, X1 = X[:, 0], X[:, 1]
xx, yy = make_meshgrid(X0, X1)
for clf, title, ax in zip(models, titles, sub.flatten()):
plot_contours(ax, clf, xx, yy,
cmap=plt.cm.coolwarm, alpha=0.8)
ax.scatter(X0, X1, c=y, cmap=plt.cm.coolwarm, s=20, edgecolors='k')
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel('Sepal length')
ax.set_ylabel('Sepal width')
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
plt.show()