通过本文,您将通过实际操作学到为什么图像到图像搜索是一个强大的工具,可以帮助您在向量数据库中找到相似的图像。
目录
图像到图像搜索
CLIP和Pinecone:简要介绍
构建图像到图像搜索工具
测试时间:魔戒
等等,如果我有100万张图片怎么办?
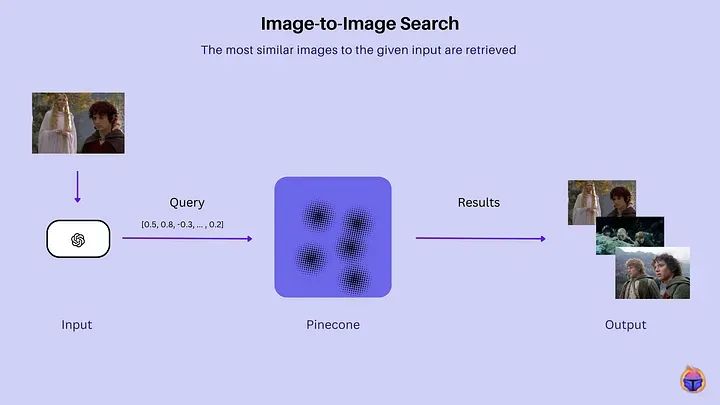
1. 图像到图像搜索
图像到图像搜索是什么意思?
在传统的图像搜索引擎中,通常您使用文本查询来查找图像,搜索引擎根据与这些图像相关的关键词返回结果。另一方面,在图像到图像搜索中,您以图像作为查询的起点,系统检索与查询图像在视觉上相似的图像。
想象一下,您有一幅画,比如一幅美丽的日落图片。现在,您想找到其他看起来完全相同的画,但您不能用文字描述它。相反,您向计算机展示您的绘画,它会浏览它所知道的所有绘画,并找到那些非常相似的绘画,即使它们有不同的名称或描述。图像到图像搜索,简而言之。
我可以用这个搜索工具做什么?
图像到图像搜索引擎开启了一系列令人兴奋的可能性:
查找特定数据 - 搜索包含您想要训练模型识别的特定对象的图像。
错误分析 - 当模型错误分类一个对象时,搜索视觉上相似的图像,它也失败了。
模型调试 - 显示包含导致不希望的模型行为的属性或缺陷的其他图像。
2. CLIP和Pinecone:简要介绍
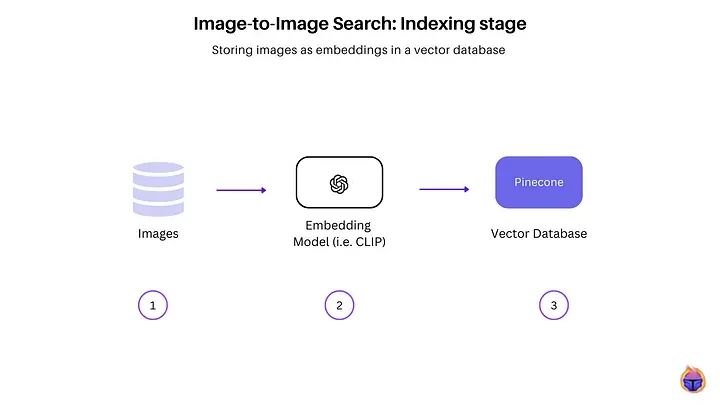 图像到图像搜索中的索引阶段
图像到图像搜索中的索引阶段
上图显示了在向量数据库中索引图像数据集的步骤。
步骤1:收集图像数据集(可以是原始/未标记的图像)。
步骤2:使用CLIP [1],一个嵌入模型,提取图像的高维向量表示,捕捉其语义和感知特征。
步骤3:将这些图像编码到一个嵌入空间中,在这个空间中,图像的嵌入被索引在像Pinecone这样的向量数据库中。
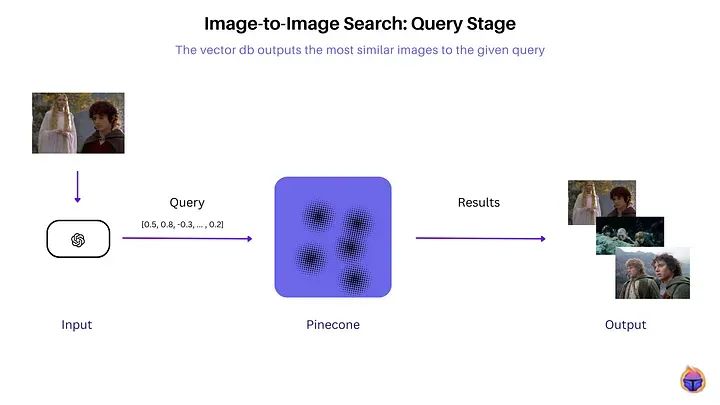
查询阶段:检索给定查询的最相似图像
在查询时,通过相同的CLIP编码器传递一个样本图像以获取其嵌入。执行向量相似性搜索以高效地找到前k个最近的数据库图像向量。与查询嵌入的余弦相似性分数最高的图像被返回为最相似的搜索结果。
3. 构建图像到图像搜索引擎
3.1 数据集 - 魔戒
我们使用Google搜索查询与关键词“魔戒电影场景”相关的图像。在此代码的基础上,我们创建一个函数根据给定查询检索100个URL。
import requests, lxml, re, json, urllib.request
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36"
}
params = {
"q": "the lord of the rings film scenes", # search query
"tbm": "isch", # image results
"hl": "en", # language of the search
"gl": "us", # country where search comes from
"ijn": "0" # page number
}
html = requests.get("https://www.google.com/search", params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, "lxml")
def get_images():
"""
https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes
if you try to json.loads() without json.dumps() it will throw an error:
"Expecting property name enclosed in double quotes"
"""
google_images = []
all_script_tags = soup.select("script")
# # https://regex101.com/r/48UZhY/4
matched_images_data = "".join(re.findall(r"AF_initDataCallback\(([^<]+)\);", str(all_script_tags)))
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# https://regex101.com/r/VPz7f2/1
matched_google_image_data = re.findall(r'\"b-GRID_STATE0\"(.*)sideChannel:\s?{}}', matched_images_data_json)
# https://regex101.com/r/NnRg27/1
matched_google_images_thumbnails = ", ".join(
re.findall(r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]',
str(matched_google_image_data))).split(", ")
thumbnails = [
bytes(bytes(thumbnail, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for thumbnail in matched_google_images_thumbnails
]
# removing previously matched thumbnails for easier full resolution image matches.
removed_matched_google_images_thumbnails = re.sub(
r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]', "", str(matched_google_image_data))
# https://regex101.com/r/fXjfb1/4
# https://stackoverflow.com/a/19821774/15164646
matched_google_full_resolution_images = re.findall(r"(?:'|,),\[\"(https:|http.*?)\",\d+,\d+\]", removed_matched_google_images_thumbnails)
full_res_images = [
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in matched_google_full_resolution_images
]
return full_res_images3.2 使用CLIP获取嵌入向量
提取我们图像集的所有嵌入。
def get_all_image_embeddings_from_urls(dataset, processor, model, device, num_images=100):
embeddings = []
# Limit the number of images to process
dataset = dataset[:num_images]
working_urls = []
#for image_url in dataset['image_url']:
for image_url in dataset:
if check_valid_URL(image_url):
try:
# Download the image
response = requests.get(image_url)
image = Image.open(BytesIO(response.content)).convert("RGB")
# Get the embedding for the image
embedding = get_single_image_embedding(image, processor, model, device)
#embedding = get_single_image_embedding(image)
embeddings.append(embedding)
working_urls.append(image_url)
except Exception as e:
print(f"Error processing image from {image_url}: {e}")
else:
print(f"Invalid or inaccessible image URL: {image_url}")
return embeddings, working_urlsLOR_embeddings, valid_urls = get_all_image_embeddings_from_urls(list_image_urls, processor, model, device, num_images=100)
Invalid or inaccessible image URL: https://blog.frame.io/wp-content/uploads/2021/12/lotr-forced-perspective-cart-bilbo-gandalf.jpg
Invalid or inaccessible image URL: https://www.cineworld.co.uk/static/dam/jcr:9389da12-c1ea-4ef6-9861-d55723e4270e/Screenshot%202020-08-07%20at%2008.48.49.png
Invalid or inaccessible image URL: https://upload.wikimedia.org/wikipedia/en/3/30/Ringwraithpic.JPG100个URL中有97个包含有效图像。
3.3 将我们的嵌入存储在Pinecone中
要在Pinecone [2]中存储我们的嵌入,首先需要创建i一个Pinecone账户。之后,创建一个名称为“image-to-image”的索引。
pinecone.init(
api_key = "YOUR-API-KEY",
environment="gcp-starter" # find next to API key in console
)
my_index_name = "image-to-image"
vector_dim = LOR_embeddings[0].shape[1]
if my_index_name not in pinecone.list_indexes():
print("Index not present")
# Connect to the index
my_index = pinecone.Index(index_name = my_index_name)创建一个函数将数据存储在Pinecone索引中。
def create_data_to_upsert_from_urls(dataset, embeddings, num_images):
metadata = []
image_IDs = []
for index in range(len(dataset)):
metadata.append({
'ID': index,
'image': dataset[index]
})
image_IDs.append(str(index))
image_embeddings = [arr.tolist() for arr in embeddings]
data_to_upsert = list(zip(image_IDs, image_embeddings, metadata))
return data_to_upsert运行上述函数以获得:
LOR_data_to_upsert = create_data_to_upsert_from_urls(valid_urls,
LOR_embeddings, len(valid_urls))
my_index.upsert(vectors = LOR_data_to_upsert)
# {'upserted_count': 97}
my_index.describe_index_stats()
# {'dimension': 512,
# 'index_fullness': 0.00097,
# 'namespaces': {'': {'vector_count': 97}},
# 'total_vector_count': 97}3.4 测试我们的图像到图像搜索工具
# For a random image
n = random.randint(0,len(valid_urls)-1)
print(f"Sample image with index {n} in {valid_urls[n]}")Sample image with index 47 in
https://www.intofilm.org/intofilm-production/scaledcropped/870x489https%3A/s3-eu-west-1.amazonaws.com/images.cdn.filmclub.org/film__3930-the-lord-of-the-rings-the-fellowship-of-the-ring--hi_res-a207bd11.jpg/film__3930-the-lord-of-the-rings-the-fellowship-of-the-ring--hi_res-a207bd11.jpg
示例图像用于查询(可以在上述URL中找到)
# 1. Get the image from url
LOR_image_query = get_image(valid_urls[n])
# 2. Obtain embeddings (via CLIP) for the given image
LOR_query_embedding = get_single_image_embedding(LOR_image_query, processor, model, device).tolist()
# 3. Search on Vector DB index for similar images to "LOR_query_embedding"
LOR_results = my_index.query(LOR_query_embedding, top_k=3, include_metadata=True)
# 4. See the results
plot_top_matches_seaborn(LOR_results)
显示每个匹配的相似性分数的结果
如图所示,我们的图像到图像搜索工具找到了与给定样本图像相似的图像,如预期中的ID 47具有最高的相似分数。
5. 等等,如果有100万张图片怎么办?
正如您可能已经意识到的,通过从Google搜索查询一些图像来构建图像到图像搜索工具是有趣的。但是,如果您实际上有一个包含100万张以上图像的数据集呢?
在这种情况下,您可能更倾向于构建一个系统而不是一个工具。建立一个可扩展的系统并非易事。而且,涉及到一些成本(例如存储成本、维护、编写实际代码)。对于这些情况,在Tenyks,我们构建了一个最佳的图像到图像搜索引擎,即使您有100万张或更多图像,也能在几秒钟内执行多模态查询!
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除