目录
5、PRIMARY KEY:主键约束(主键只能定义一个,NOT NULL 和 UNIQUE 的结合)
一、数据库的约束
1、约束类型
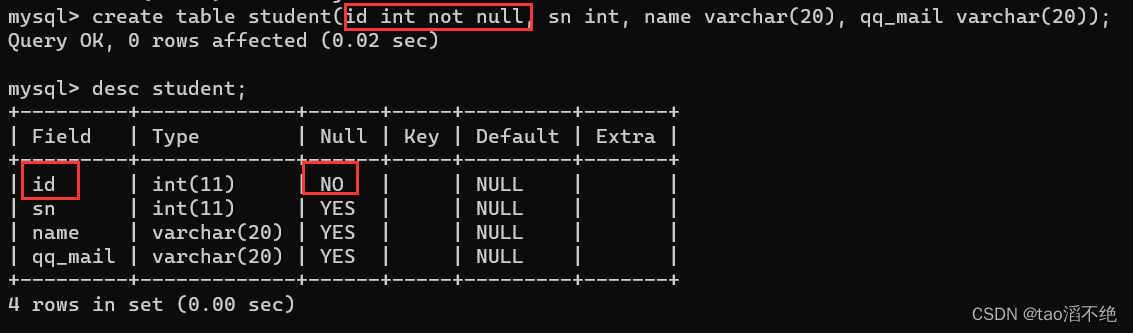
NOT NULL - 指示某列不能存储 NULL 值。
UNIQUE - 保证某列的每行必须有唯一的值。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。(用来作为一个记录的身份标识,一个表里面只能有一个主键,设置为主键的那一列不能为null)
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
2、NULL约束
创建表时,可以指定某列不为空:
代码展示:
create table student(id int not null, sn int, name varchar(20), qq_mail varchar(20));
3、UNIQUE:唯一约束
指定sn列为唯一的、不重复的:
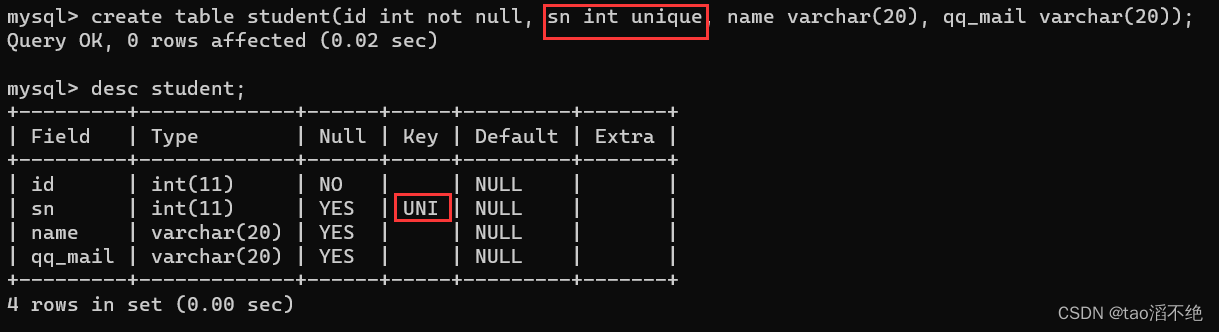
代码展示:
create table student(id int not null, sn int unique, name varchar(20), qq_mail varchar(20));
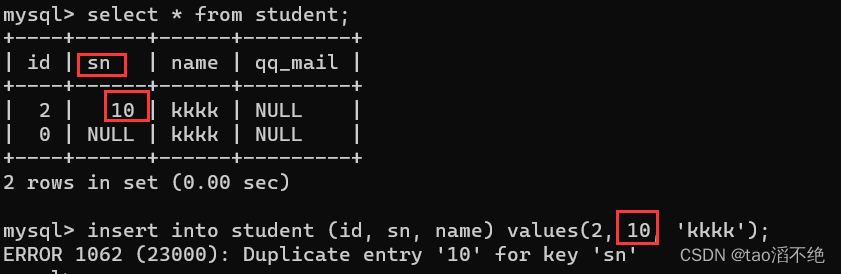
有了unique约束后,sn列里面的数据就不能重复
如果sn插入相同的数据就会失败
4、DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
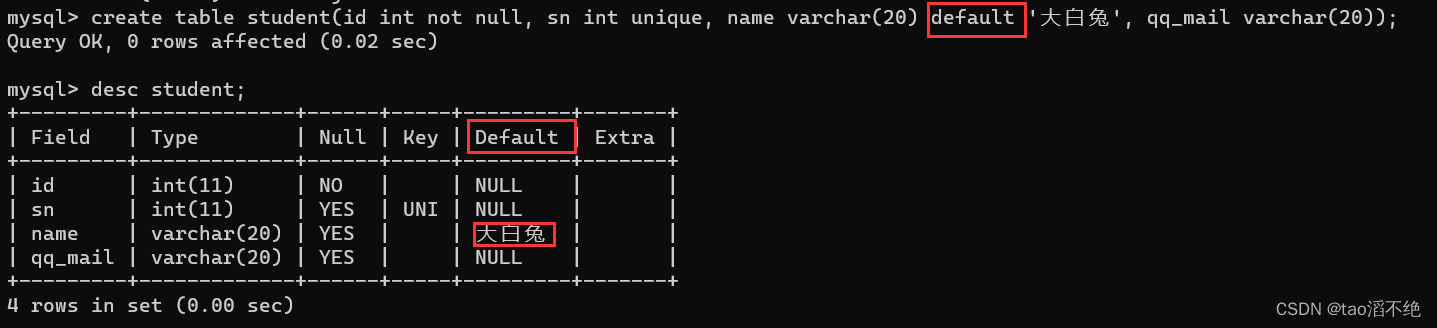
代码展示:
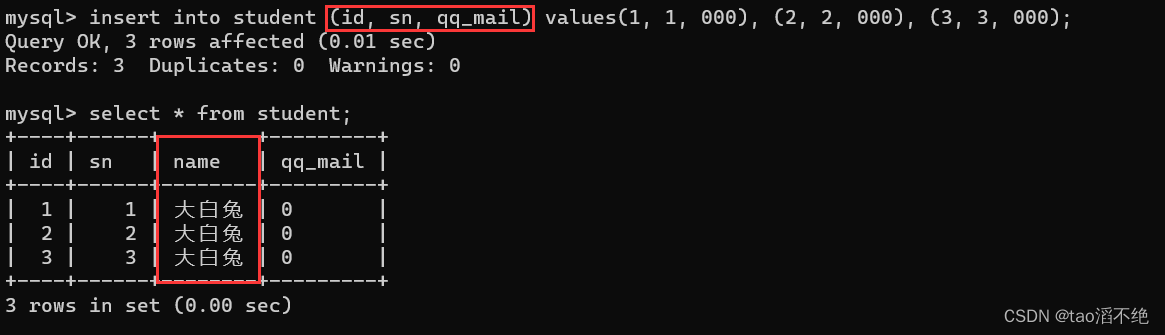
create table student(id int not null, sn int unique, name varchar(20) default '大白兔', qq_mail varchar(20));
我们插入一些数据
可以看到name列的数据都为“大白兔”,我们并没有初始化name这个列的数据,但是因为我们使用了default约束,默认了name列的数据为“大白兔”。
5、PRIMARY KEY:主键约束(主键只能定义一个,NOT NULL 和 UNIQUE 的结合)
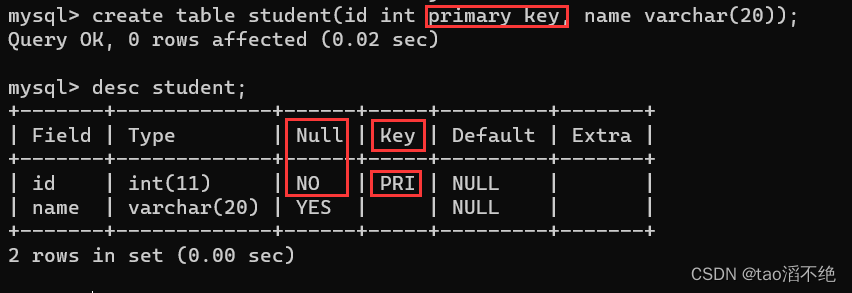
指定id列为主键:
代码展示:
create table student(id int primary key, sn int unique, name varchar(20) default '大白兔', qq_mail varchar(20));结果如下:
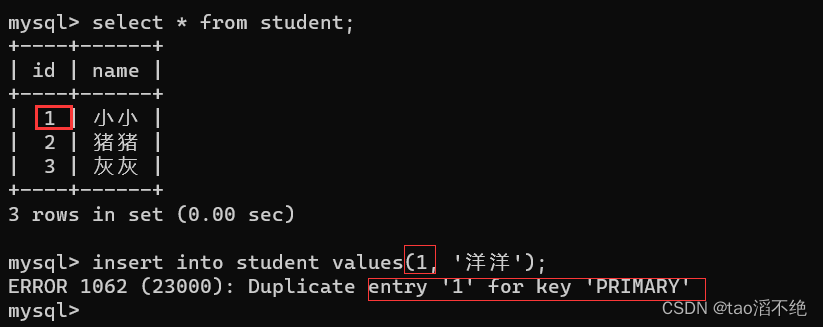
如果定义两个主键则会报错,如下图:
如图,如果我们再插入id为1的数据,就会报错
因为我们把id设置了为主键,那么id这个列它不允许有null值,也不允许有重复的数据,因为主键约束的列数据是唯一的
主键不允许重复,那么我们怎么它不重复呢?
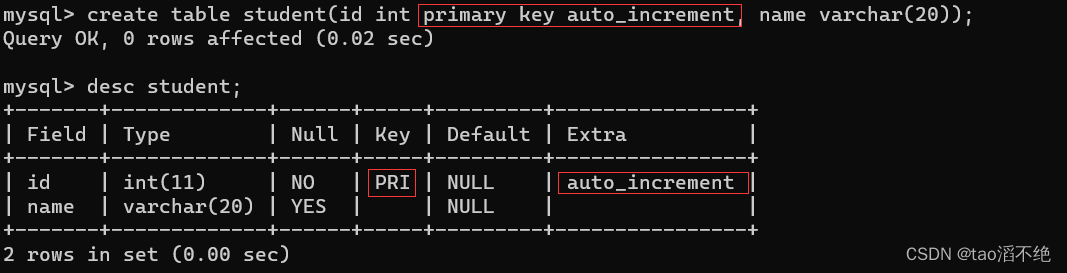
MySQL自身给我们提供了一种机制:“自增主键”(primary key auto_increment)
如图:
那么如果我们插入数据的时候,就不用指定id了,MySQL会自动帮我们加1,保证id列上的数据不重复
如图展示:
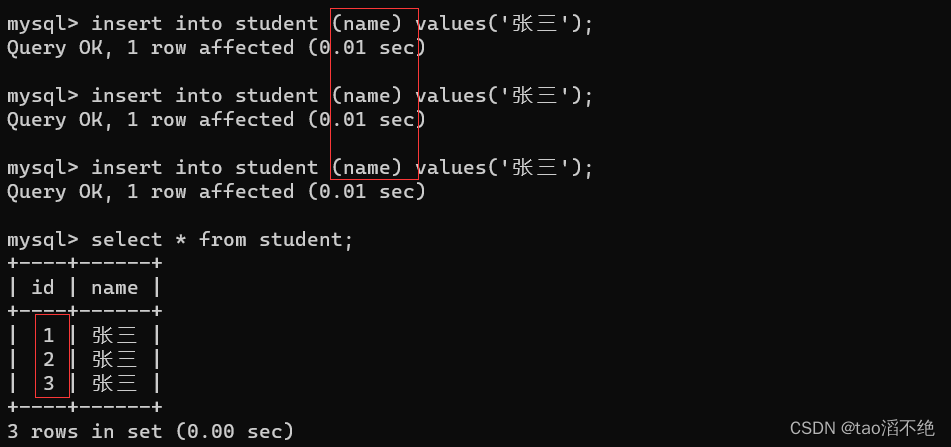
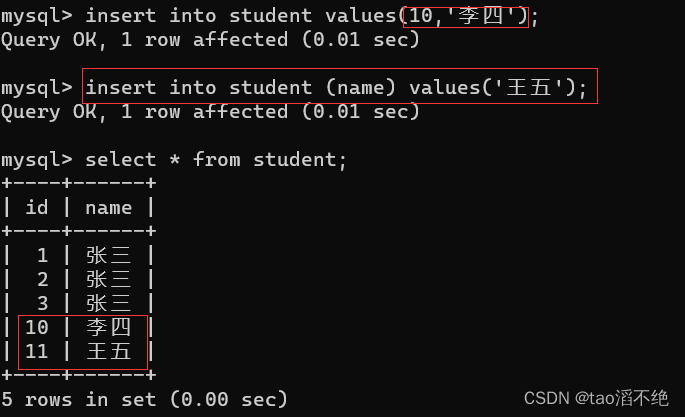
如果我们手动加一个id为10的数据,再次添加只有name列的数据,id让MySQL自动添加,它自动添加的值是多少呢?如图
可以看到,id是3到9的数据会跳过,从10开始自增。
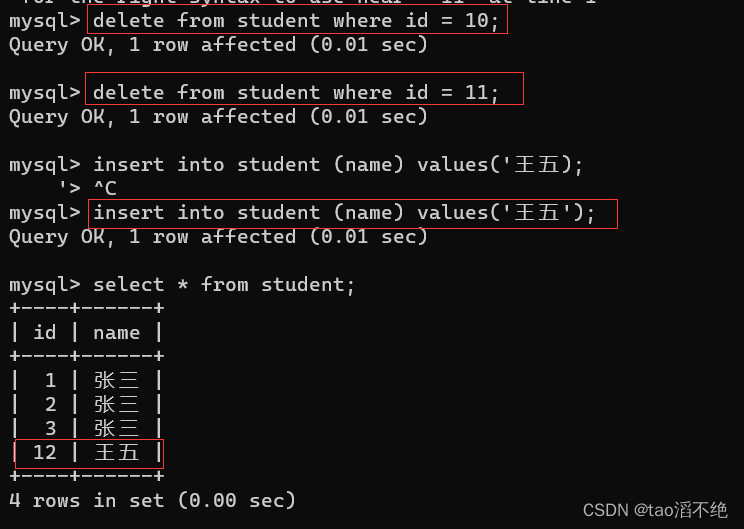
那如果我们把id = 10和id = 11的数据删除呢?
可以看到,id是从之前已经存过的数据,但是删除了的开始自增,并不会从3开始自增。
所以,每次没有指定id或者指定为null时插入主键自增的时候。都是数据库会根据当前列的最大值进行自增,并且这里的自增是不会重复利用之前的值的

看到这,你会不会觉得这样太浪费空间了?
其实这么做确实会浪费一点空间,但是MySQL的数据是存储到硬盘上的,硬盘本身也比较便宜,而且这么做也能省去一些麻烦事,用MySQL进行编程也会更简单,减轻我们在实际开发中的工作量,浪费这么点空间就浪费了,硬盘空间有不值钱。
6、FOREIGN KEY:外键约束
外键约束是指有两张表,一个表作为父表,一个表作为子表,父表约束着子表,在子表插入数据的时候,被外键约束的那一列插入的数据在父表也必须有,没有的话就不能插入;
同时,子表对父表也有一定的约束,例如,子表被约束的那列数据是和父表约束子表的那一列数据是一样的,父表可能会有多,但子表有的父表一定有,这时,我们就不能随便更改或删除父表约束列的那一数据了,因为改了子表和父表的约束数据就不一样了,这也就是子表对父表有一定约束的原因。
语法:foreign key (字段名) references 主表(列)
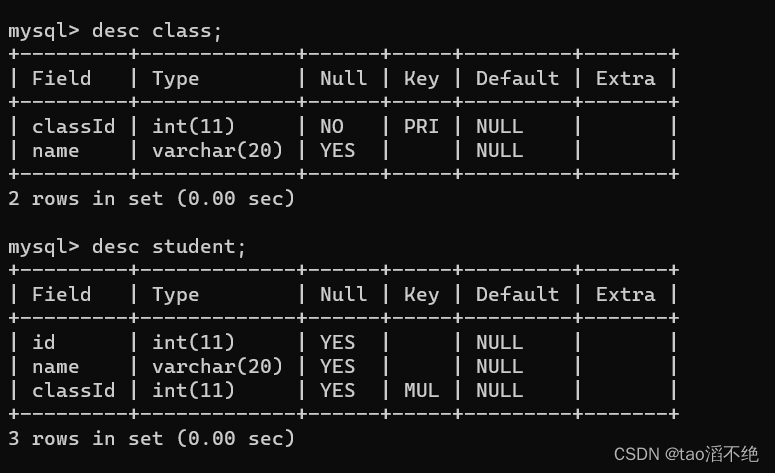
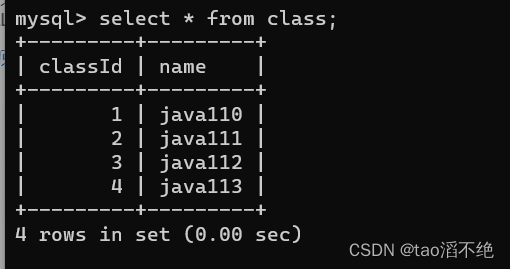
创建class表,创建时id是用了主键约束。
代码展示:
create table class(classId int primary key, name varchar(20));创建student表,创建时是用了外键约束。
代码展示:
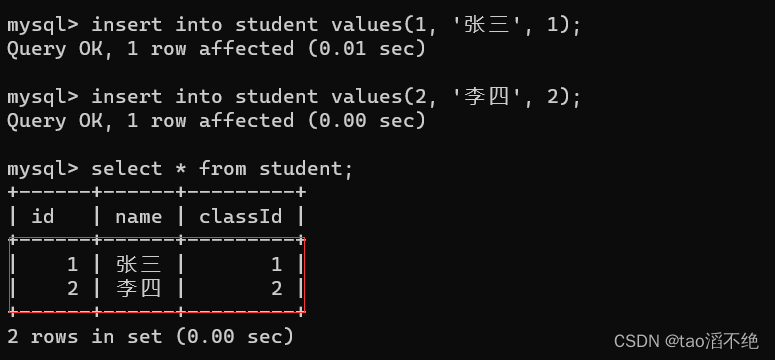
create table student(id int, name varchar(20), classId int primary key, foreign key (classId) references class(classId));创建的两张表如图:
class表的内容:
我们试着对student插入数据试试,如图
当我们插入外键约束中父表没有的数据,如图:
插入失败了,同时,我们试着删除或者更改父表外键约束的数据,如图:
也是删除或者修改失败了


7、CHECK约束(了解)
保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。对于MySQL没啥用,了解即可。
二、表的设计
表的设计就是根据需求,把把你需要的表创建出来,做法:
1) 根据需求找实体
2) 梳理清楚实体之间的关系
一对一
如图:

例子:教务系统,需要表示一个概念,学生(实体),需要一个学生表示这个实体,还有一个概念,账户(实体),需要一个账户表示这个实体
实体:学生,账户
关系:一个学生只有一个账户,一个账户只能给一个学生使用
设计方案
方案一:把学生和账户都放进一个表里进行管理(这两个表都很简单,列很少,可以考虑合并)
方案二:分两个表,一个是学生表,一个是账户表,通过id引用将两个表联系起来(一对一)如图

一对多
如图:
例子:教务系统,有一个实体,学生,还有一个实体,班级
实体:学生,班级
关系:一个班级可以包含多个学生,一个学生只能从属一个班级
设计方案:
如图

多对多
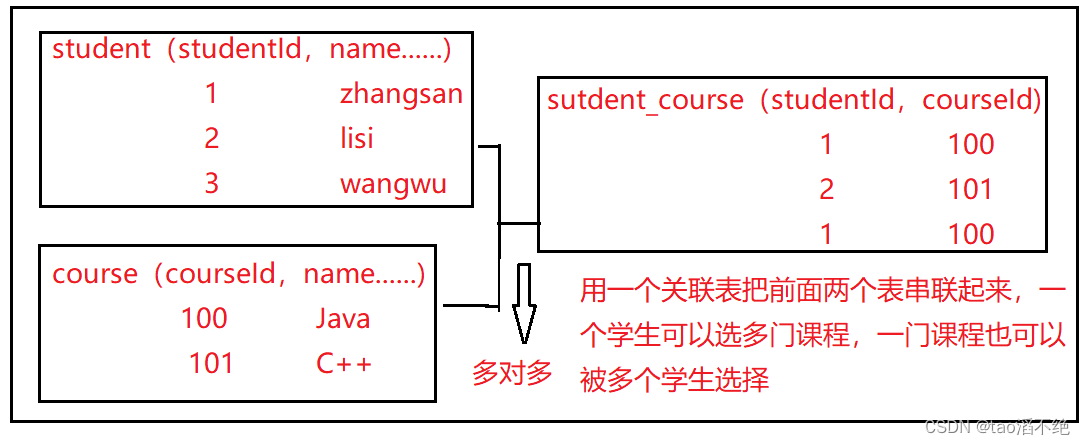
如图:

例子:教务系统,学生是一个实体,课程也是一个实体
实体:学生,课程
关系:一个学生可以选多门课程,一个课程也可以被多个学生选择
设计方案:如图
没关系(两个实体毫不相干)
直接各自创建各自的表,比较简单,没有关联
总结:
表的设计要确定实体的关系,造句,往里套,能套上哪个就用那种方式创建数据表
三、新增
插入查询结果
语法: insert into 表名 values select 要查询的表...
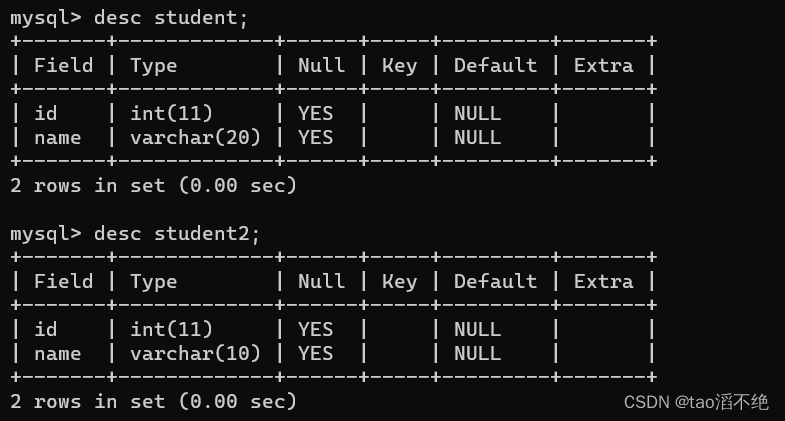
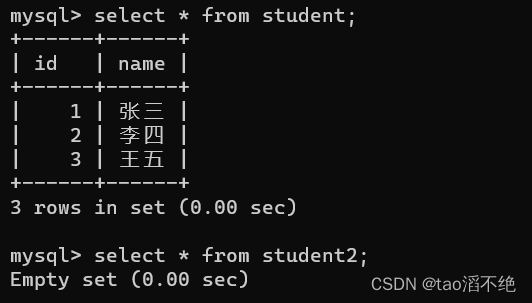
例子:把student表的所有数据都插入到student2表中
我们现有两张表,列的结构是一样的,如图
现在,把student的表数据全部插入到student2中
代码:
insert into student2 select * from student;如图
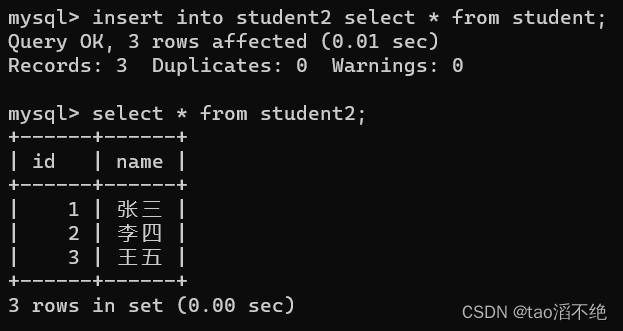
注意:要插入查询的结果,那么要插入的数据列结构和被插入的数据列结果要相同,可以指定列插入,也可以插入多个查询结果
四、查询
1、聚合函数
(1)聚合函数
常见的聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
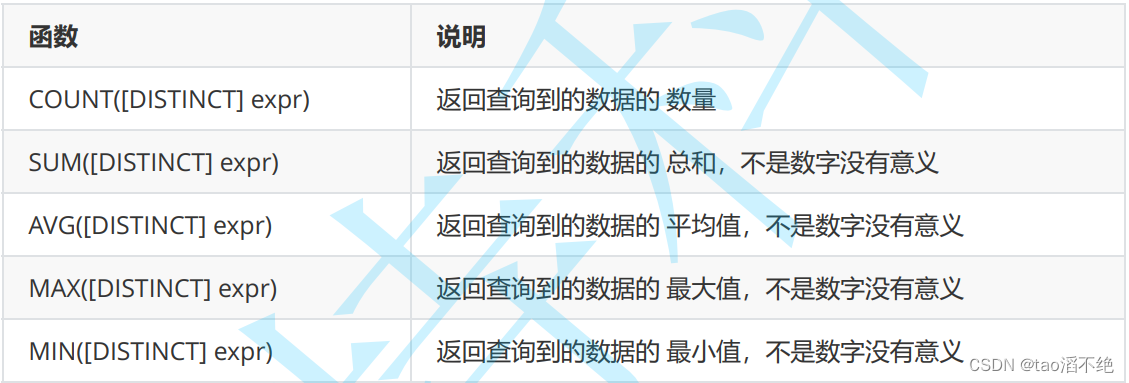
案例
COUNT:
查看查询数据的行数:
如图:
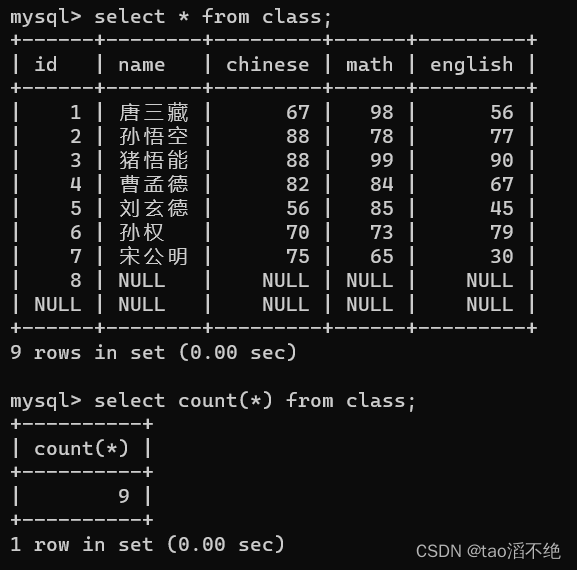
注意:
count(*)不管列里面的数据有没有null值,查询出来的行数都是总行数,
但如果是某一列,则有null值的那一行数据就不会被算进去
如图:
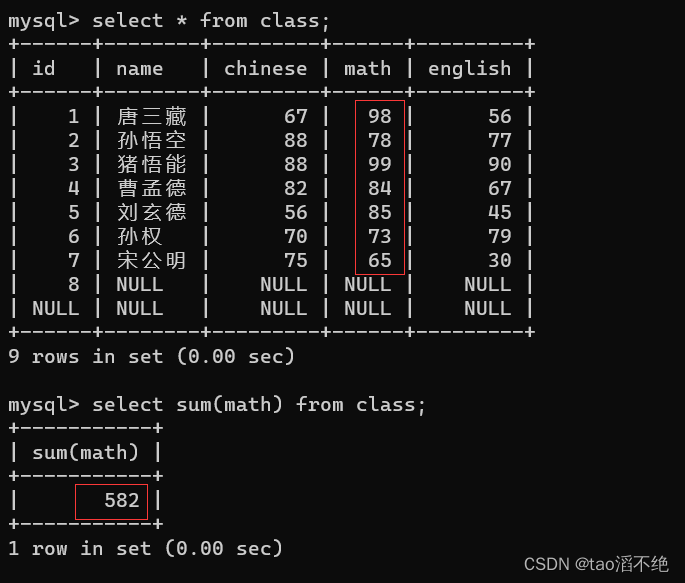
SUM:
计算math列的总成绩
注意:(1)这里的null不会被计算,在sql中,与null的任何计算都为0,如null + 10,null * 20...等等,所以sum函数在计算中遇到null就会跳过不计算。
(2)字符或字符串是不能相加的,如果使用了sum函数对字符或字符串相加,结果会为0,并且会有警告,但是有一特例:字符数字,字符数字则会转换为字符继续执行sum函数计算
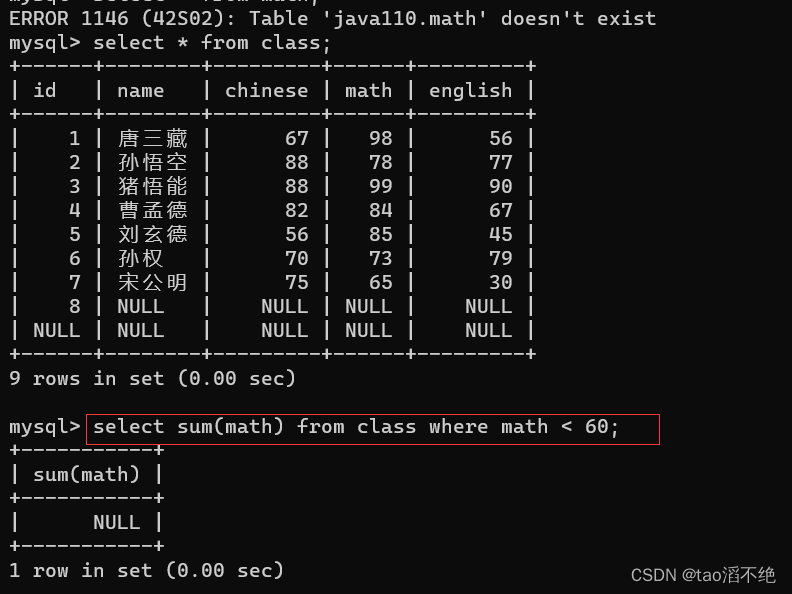
计算math不及格(< 60)的总分,没有结果,返回 NULL
如图:
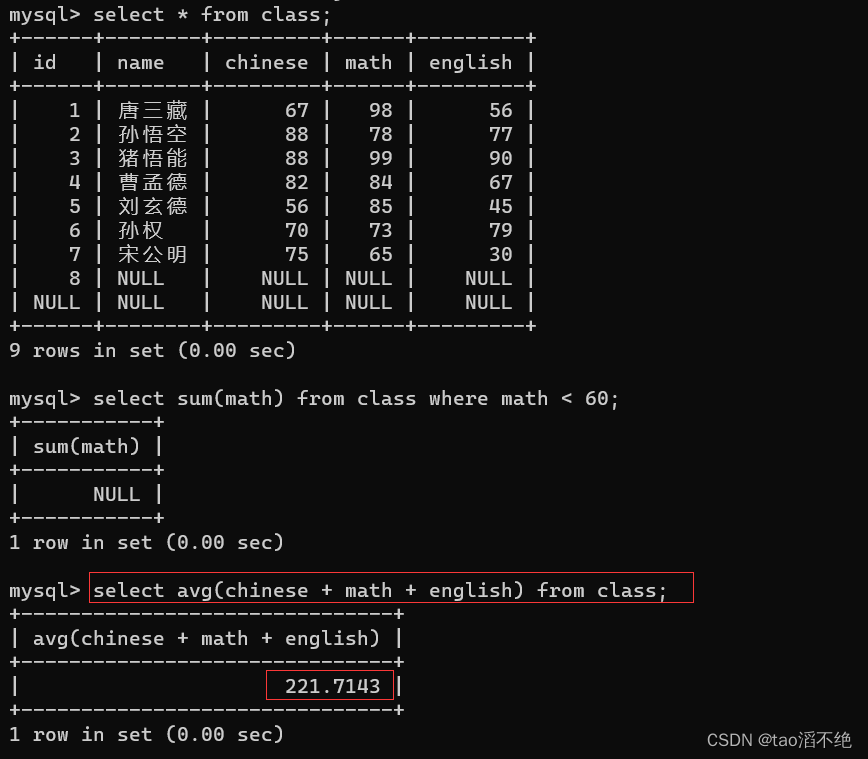
AVG:
统计平均总分
MAX:
返回英语最高分
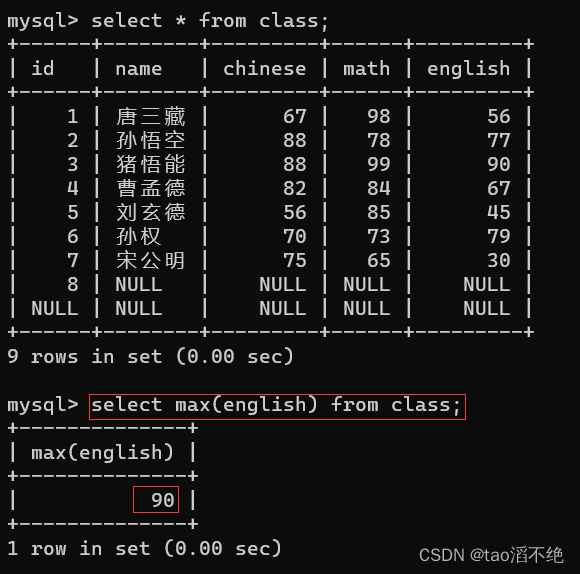
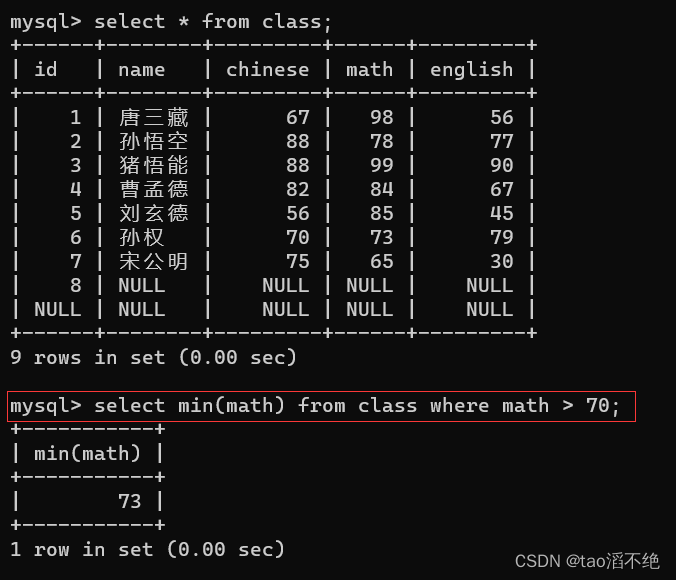
MIN:
返回 math > 70 分以上的数学最低分
(2)group by子句
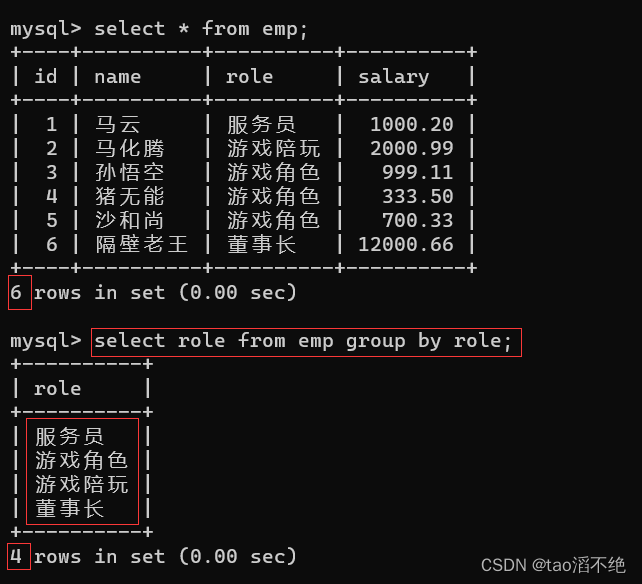
select中使用group by可以对指定列进行分组查询,指定的列会把列里面相同的数据进行合并,不会出现相同的数据,select查询的必须是“分组查询的字段”,如果其他字段想要出现在select中,则必须对其使用聚合函数
查询role的列使用group by子句,对role列进行分组查询
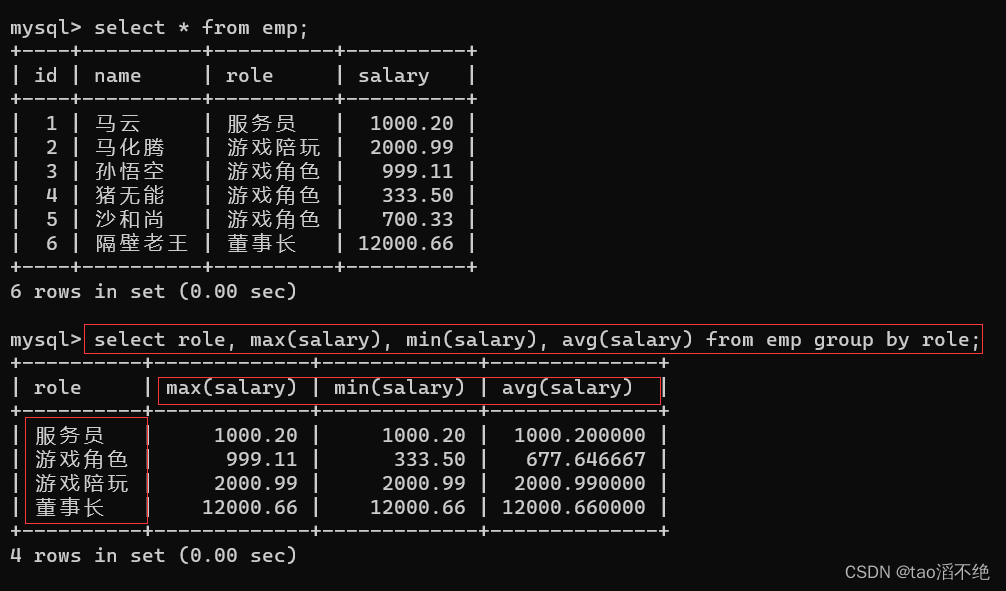
查询每个角色的最高工资,最低工资和平均工资
(3)having
having和where用法一样,但是执行优先级不一样,区别:where在执行分组查询group by前先执行,having在执行分组查询group by后执行。
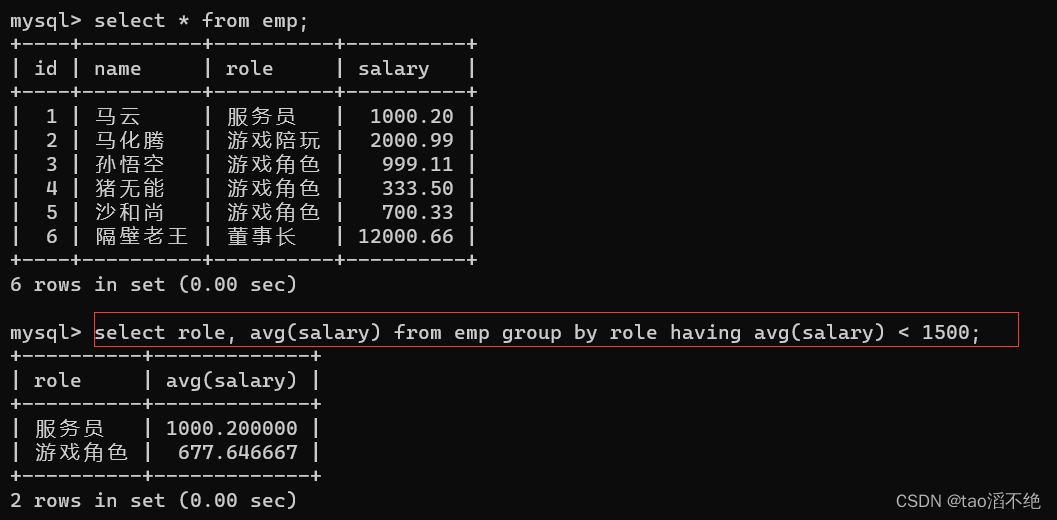
显示平均工资低于1500的角色和它的平均工资
2、联合查询
基本流程:
1、对两个或者多个表进行笛卡尔积
2、连接条件(因为笛卡尔积后有很多行数据是错误的,我们需要使用连接条件把正确的数据筛选出来)
3、根据需求指定条件
4、针对列对其精简或者使用聚合函数
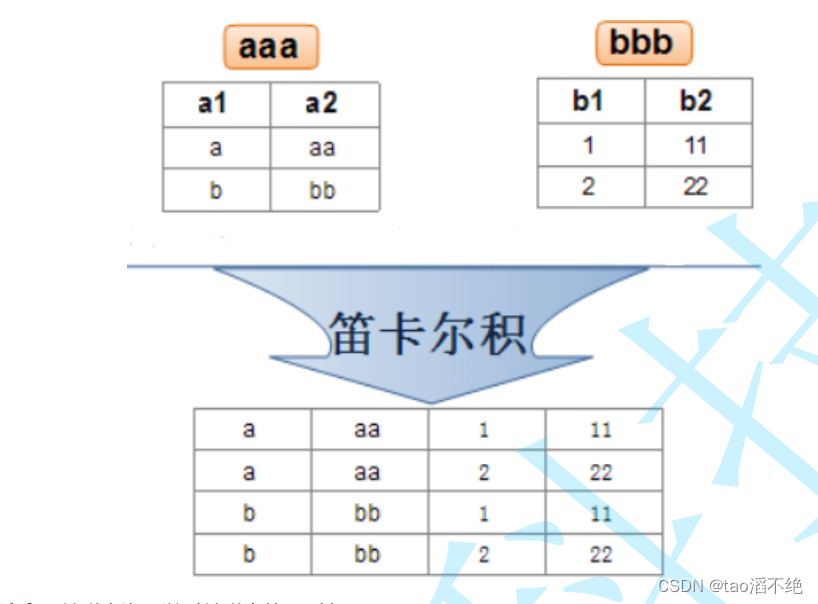
笛卡尔积
大致做法:如图
注意:关联查询可以对关联表使用别名。
1、内连接
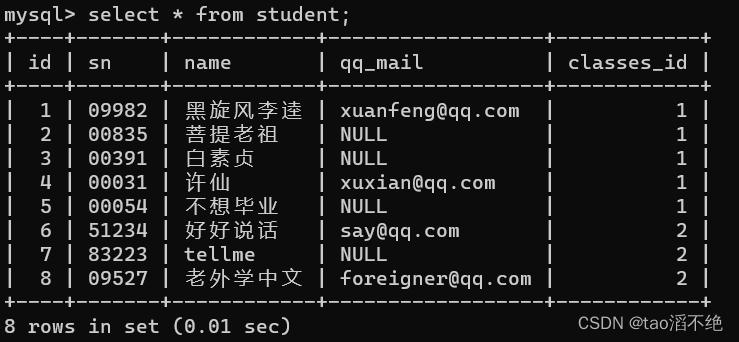
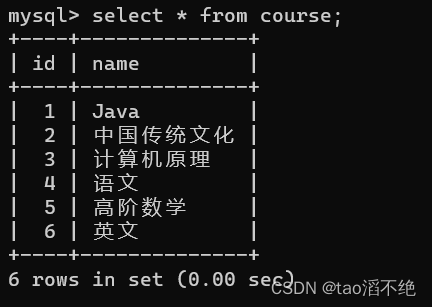
现有4张表classes,student,course,score,如图:

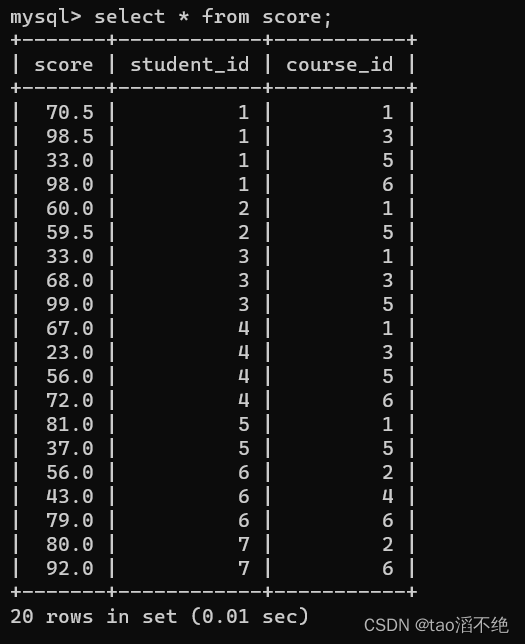
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;(inner可以省略)
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
例子:
查询“许仙”同学的 成绩
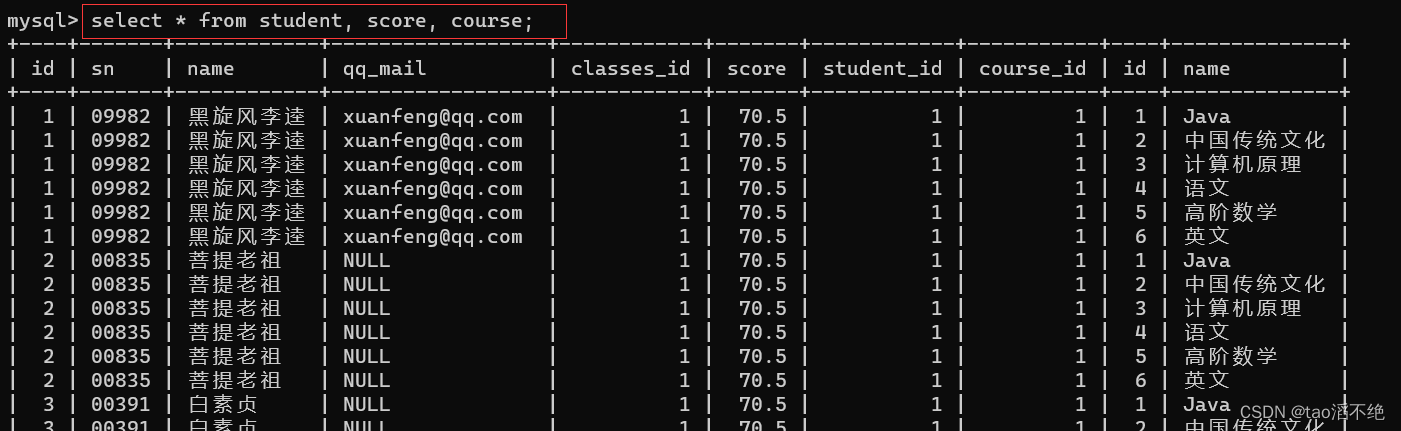
步骤1:笛卡尔积
代码:
select * from student, score, course;结果如下:
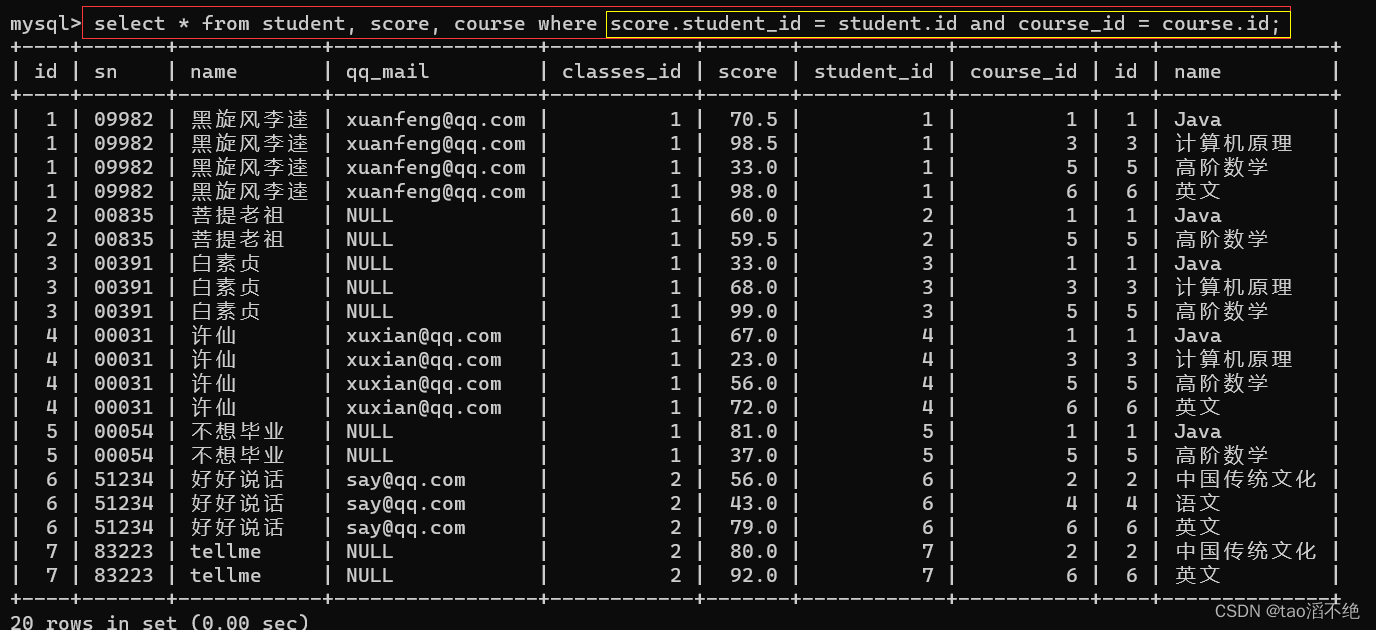
步骤2:连接条件
代码:
select * from student, score, course where score.student_id = student.id and course_id = course.id;结果如下:
步骤3:根据需求给出条件
代码:
select * from student, score, course where score.student_id = student.id and course_id = course.id and student.name = '许仙';结果如下:

步骤4:针对列进行精简或者使用聚合函数
代码:
select student.name, score from student, score, course where score.student_id = student.id and course_id = course.id and student.name = '许仙';结果如下:

join on的操作方法:
步骤和上面一样
代码:
select student.name, score from score join student on score.student_id = student.id join course on course.id = score.course_id and student.name = '许仙';结果如下:

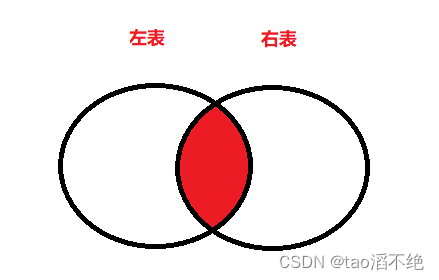
2、外连接
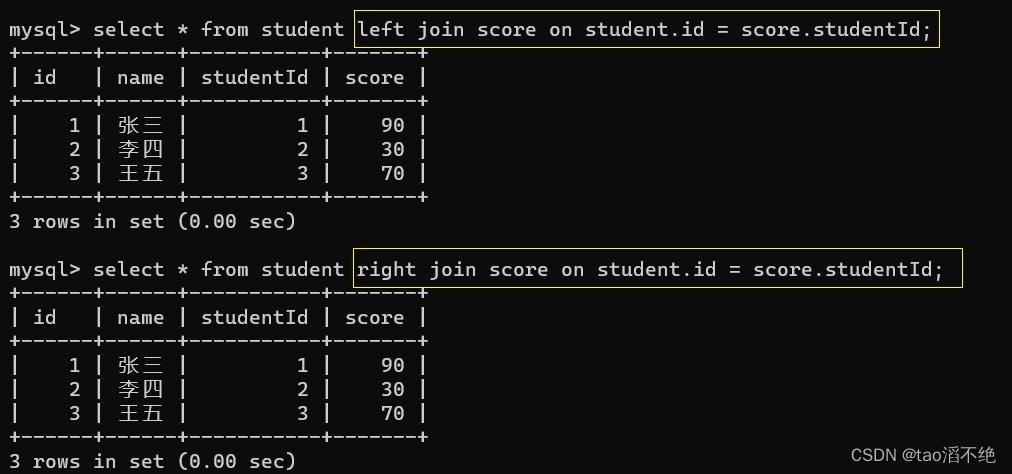
外连接分为左外连接(保留左边表的完整数据)和右外连接(保留右边表的完整数据)
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
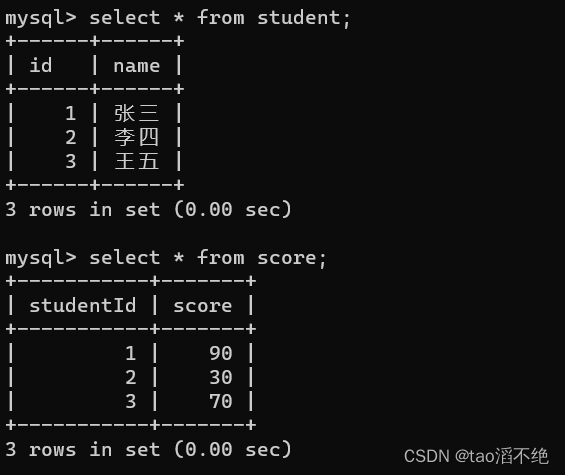
例子:
现有两张表如下:
内连接和外连接其实差不多,不过有一些特殊的地方会有不同
外连接:
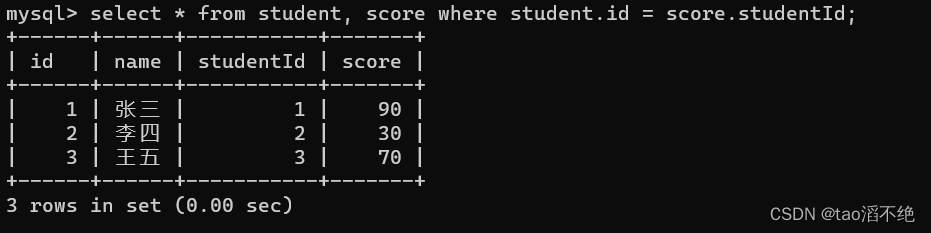
内连接:
上面这种情况进行联合查询是一样的,但是下面我们将score的数据studentId为3变成id为4,这时两者就不同,如图:
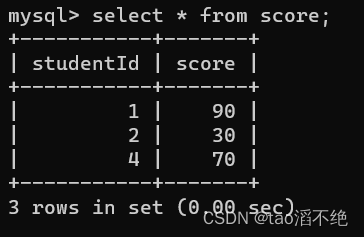
这时我们使用内外查询看看有啥区别
外查询:
关系如下图:
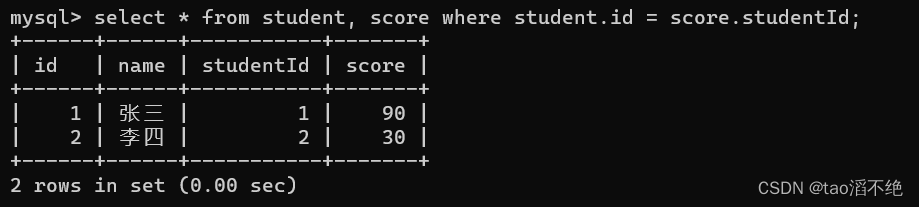
内查询
关系如下图:
关系如下图:
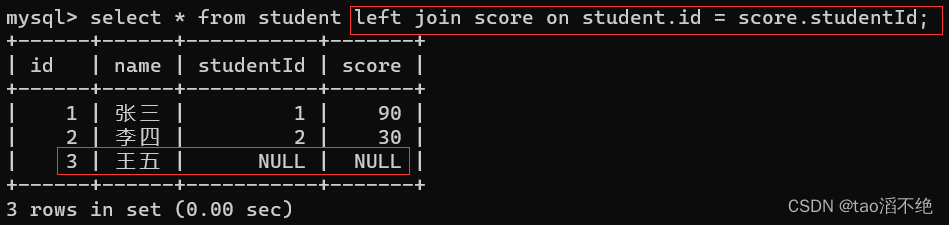
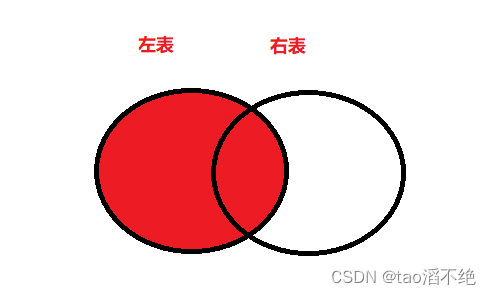
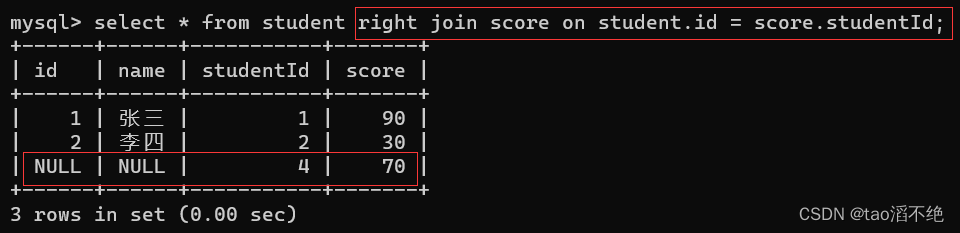
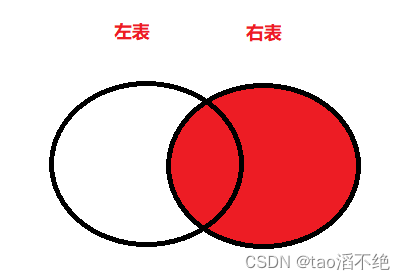
可以看到,左外查询会保持左表有值,如果右表没有连接匹配的数据,则会自动填充null值。
3、自连接
自连接表示在同一张表,自己和自己连接进行查询;进行条件查询时,指定条件一定是列和列之间的关系,不能指定行和行之间的关系,而自连接就可以把指定列和列之间的关系转换为行和行之间的关系。
例子:
显示所有“计算机原理”(id为3)成绩比“Java”(id为1)成绩高的成绩信息
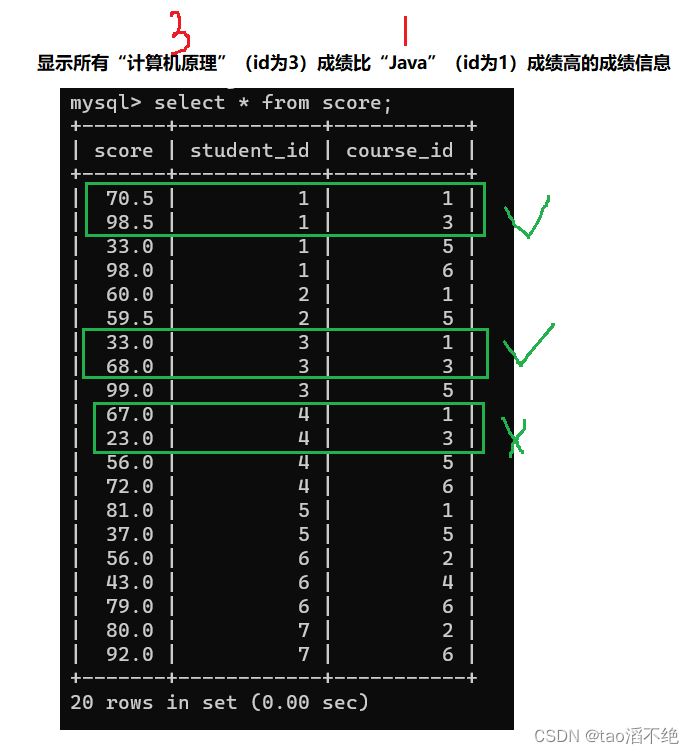
步骤一:笛卡尔积(自连接这里要起别名)
代码:
select * from score as s1, score as s2;结果如下:
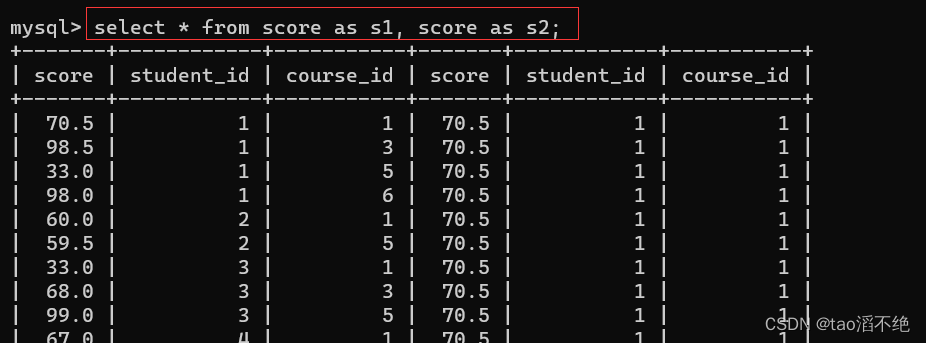
步骤二:连接条件
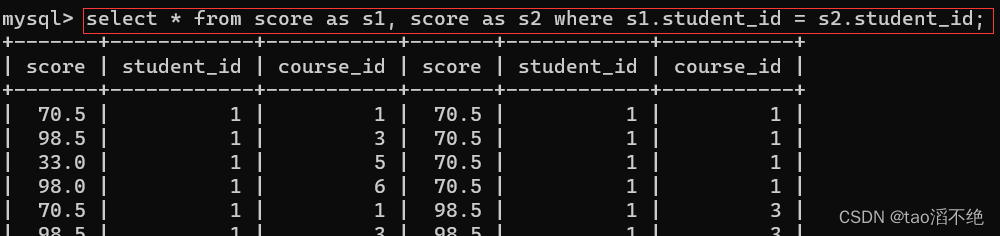
代码:
select * from score as s1, score as s2 where s1.student_id = s2.student_id;结果如下:
步骤三:根据需求给出条件
代码:
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1;结果如下:

代码:
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;结果如下:

代码:
select * from score as s1, score as s2, student where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score and student.id = s1.student_id;结果如下:

步骤四:针对列进行精简
代码:
select student.name, s1.score, s2.score from score as s1, score as s2, student where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score and student.id = s1.student_id;结果如下:

4、子查询
子查询是指嵌入在其他sql语句的select语句,也叫嵌套查询,套娃,把多个简单的sql语句合并成一个复杂的sql语句(实际开发中不推荐使用)
例子:
查询与“不想毕业” 同学的同班同学
正常查询分两步,如图:
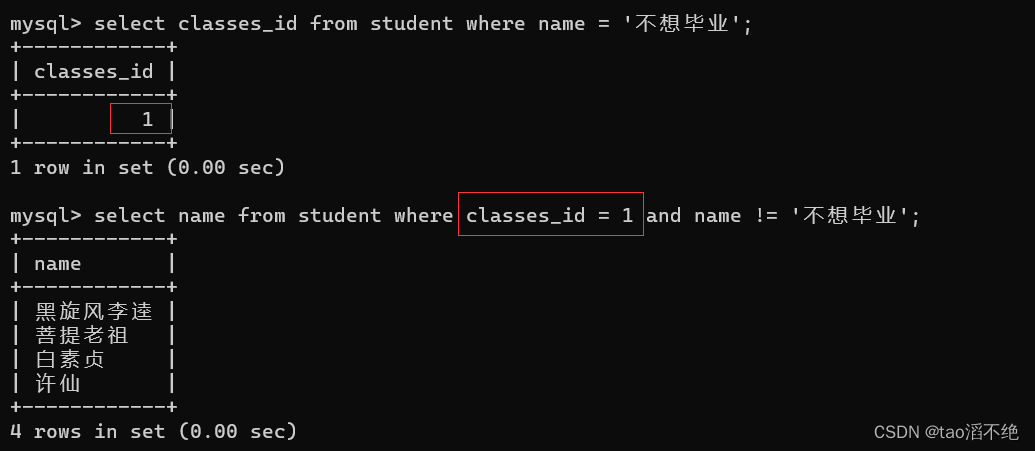
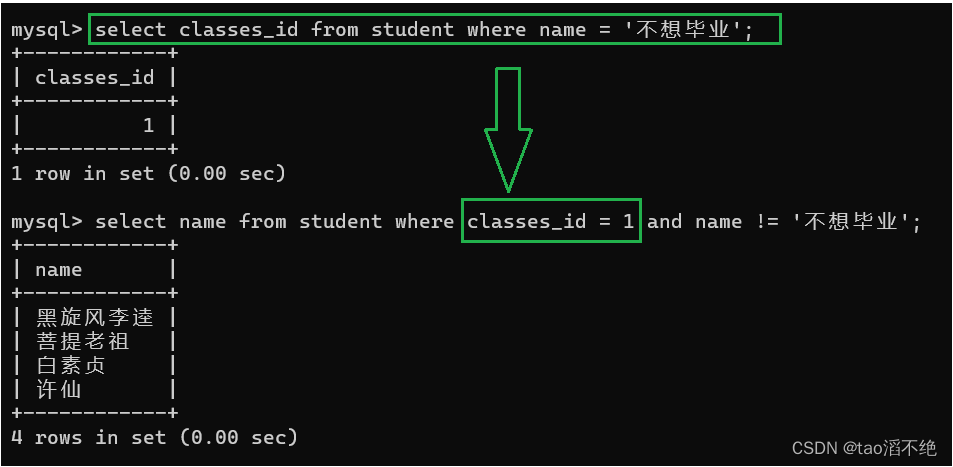
子查询的方法,是把上一个sql语句嵌套到下一个sql中,如图:
代码:
select name from student where classes_id = (select classes_id from student where name = '不想毕业') and name != '不想毕业';结果如下:
注意:嵌套的sql语句要加括号“()”

5、合并查询
合并查询使用union,可以把两个查询结果的集合,合并成一个集合;在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union(自动去重),union all(不去重)。
合并两个不同表前提条件:使用UNION和UNION ALL时,两个select查询的结果集,列数和类型要匹配,但列名不影响。
例子:
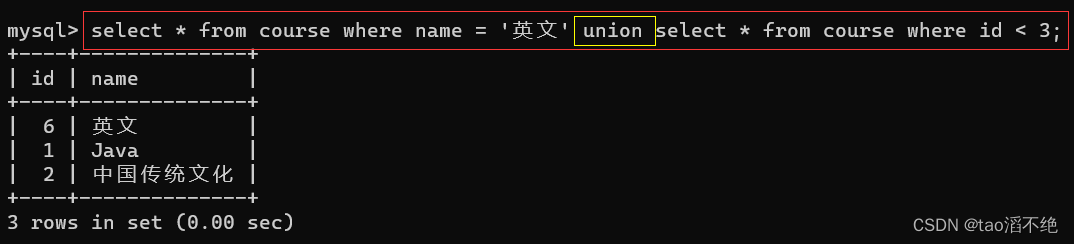
查询id小于3,或者名字为“英文”的课程。
代码:
select * from course where name = '英文' union select * from course where id < 3;结果如下:
这个场景我们也可以直接使用or,如图:
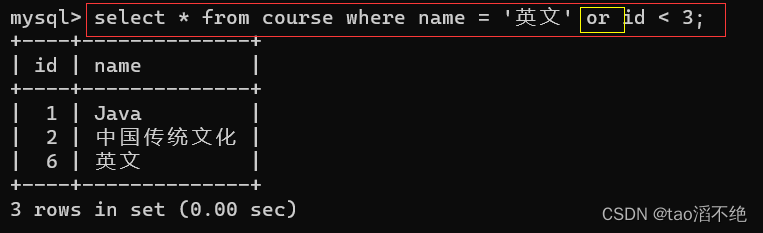
这里是不是觉得用union多此一举了呢,但是别忘了,union是可以合并两个不同表的查询,但是or不可以,注意:合并两不同表时,两个select查询的结果集,字段要匹配(列数和类型要匹配)