短视频评论的抓取及分析
一.设计背景
目前,短视频已经成为大多数人娱乐消遣的主要方式。用户在观看视频内容的同时,也同样关注视频评论,并且很多时候评论带给人们的乐趣远远超过视频本身。但是各短视频平台都没有提供用户评论数据的可视化分析,基于该现状,本项目给出了解决方案。
在本项目中,我们对视频评论的文本进行分析,提取出现频率较高的一部分词汇形成词云,这样可以过滤掉大量文本,使用户一眼扫过就可以获取主要信息,并感知最突出且具有代表性的评论词汇;同时我们对每一条评论进行情感分析,统计各种情感倾向评论的数量,以可视化的方式展现给用户,以便用户掌握评论的舆情走向。除此之外,我们还对所有评论的IP进行分析,最终以地图的方式向用户展示全国各地的评论人数,使用户对该视频的地域性有所了解。
二.设计思想
1.评论数据抓取
首先分析视频页面源码以及服务器返回的各种数据,接下来定位评论数据,最后使用Fiddler抓包工具抓取服务器返回的JSON格式的评论数据并保存。
2.评论文本分析
(1)文本内容提取
分析JSON数据的层次,找到评论文本并提取。
(2)文本分析及可视化
(a)绘制词云
首先使用jieba库对全部评论分词并提取出现频率较高的词汇,然后利用wordcloud进行词云绘制。
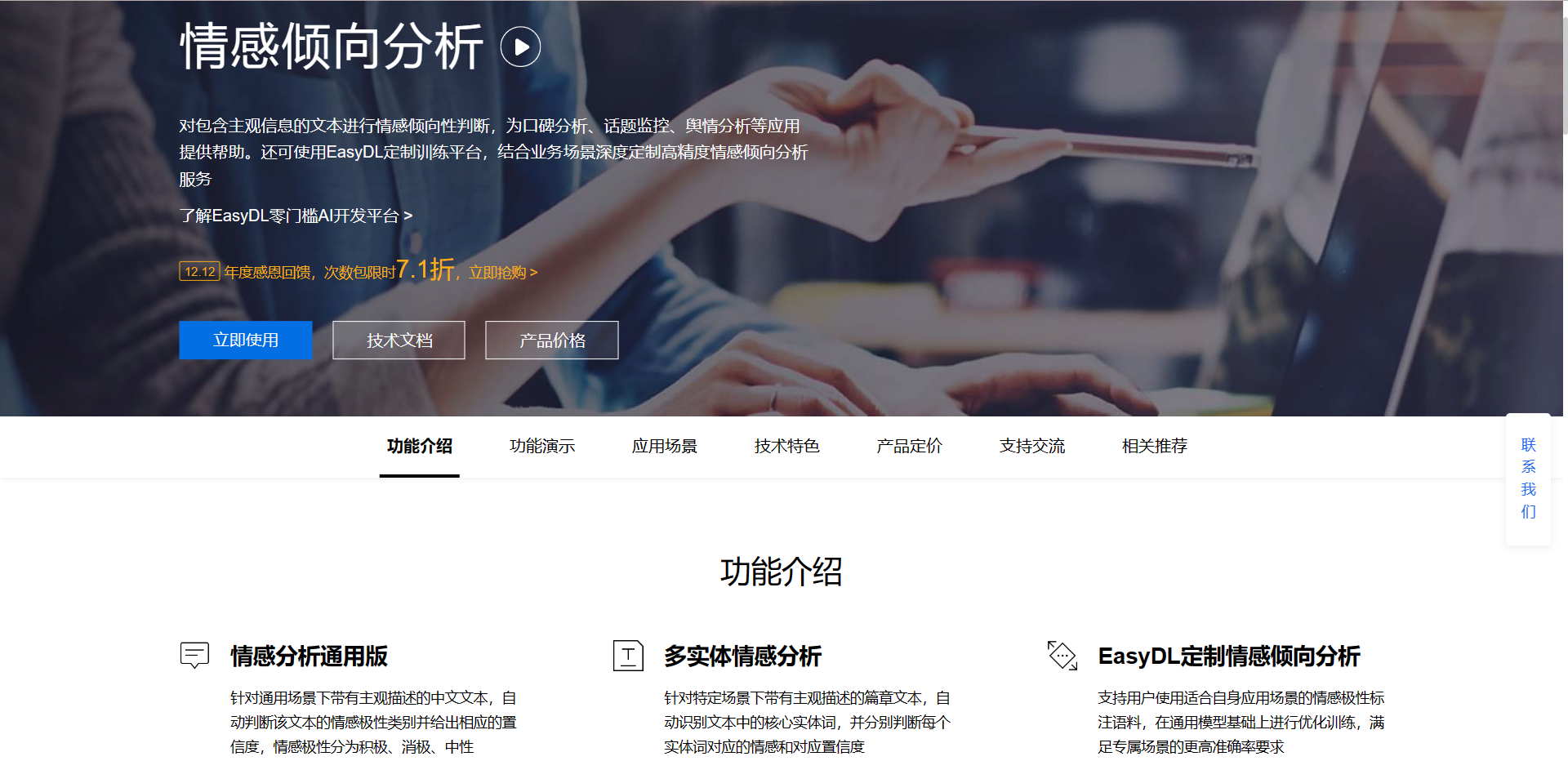
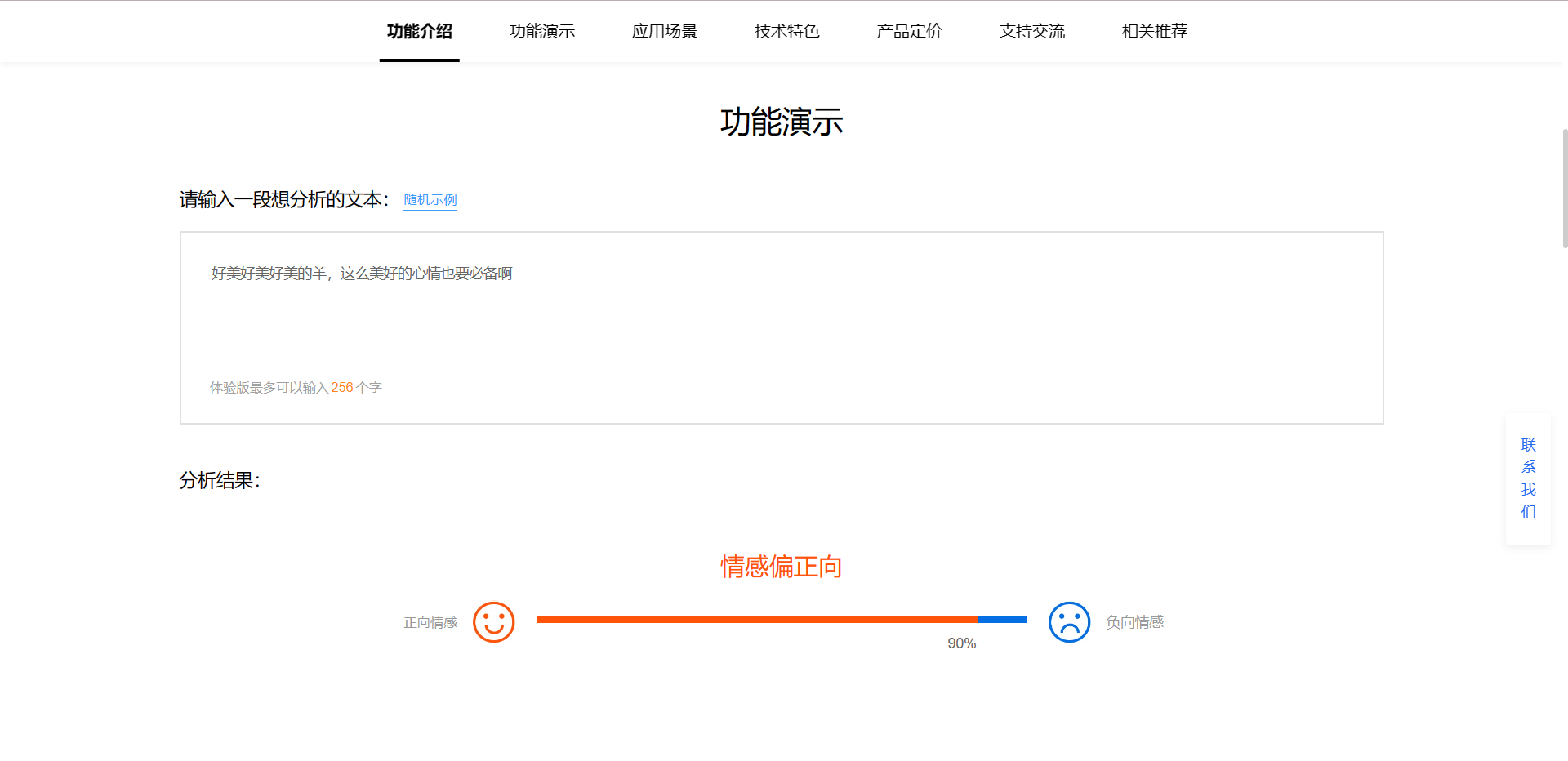
(b)情感分析
首先调用百度智能云自然语言处理功能中的情感倾向分析,接下来对获取到的每一条评论进行情感分析,最后统计各种情感倾向的占比,并使用matplotlib绘制饼图,可视化展示分析结果。
3.评论IP分析
(1)IP信息提取
分析JSON数据层次,找到IP信息并提取。
(2)IP分析及可视化
使用collections库中的Counter方法对提取到的IP进行数量统计,得到每个省份评论人数的数据,然后使用pyecharts模块绘制体现各省份评论人数的中国地图。
三.数据获取流程
1.定位评论数据
通过分析页面源码发现,只有一小部分评论数据包含在页面源码中,显然直接爬取短视频页面的源码的做法并不可行。进一步分析发现,抖音评论数据为异步数据,即评论数据包随着用户下翻视频页面逐一从服务器发送给用户,每个数据包都为包含20条评论的JSON文件,并且具有唯一的URL。
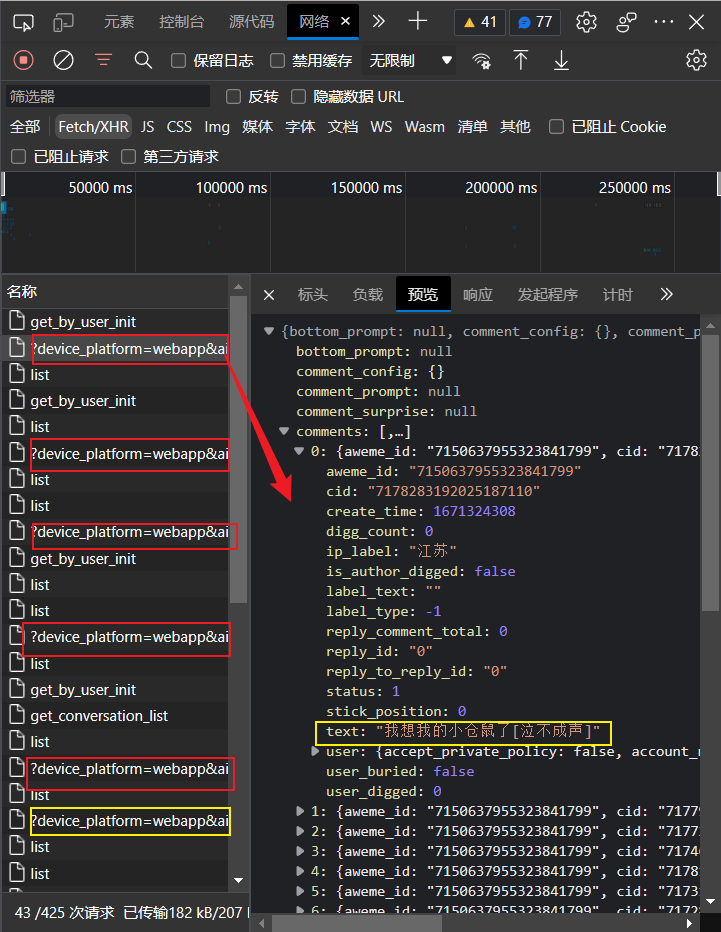
2.数据抓取
首先尝试使用requests带着cookie直接请求该数据包的URL,但是发现返回的数据为空,经过多次尝试,最终认为直接爬取该数据包的难度较大。所以另辟蹊径,使用Fiddler抓包工具抓取在下翻评论过程中服务器返回的所有数据包,然后利用评论数据包URL的特征进行筛选,得到返回的所有评论数据,最后将这些数据保存以备接下来从中提取所需数据。
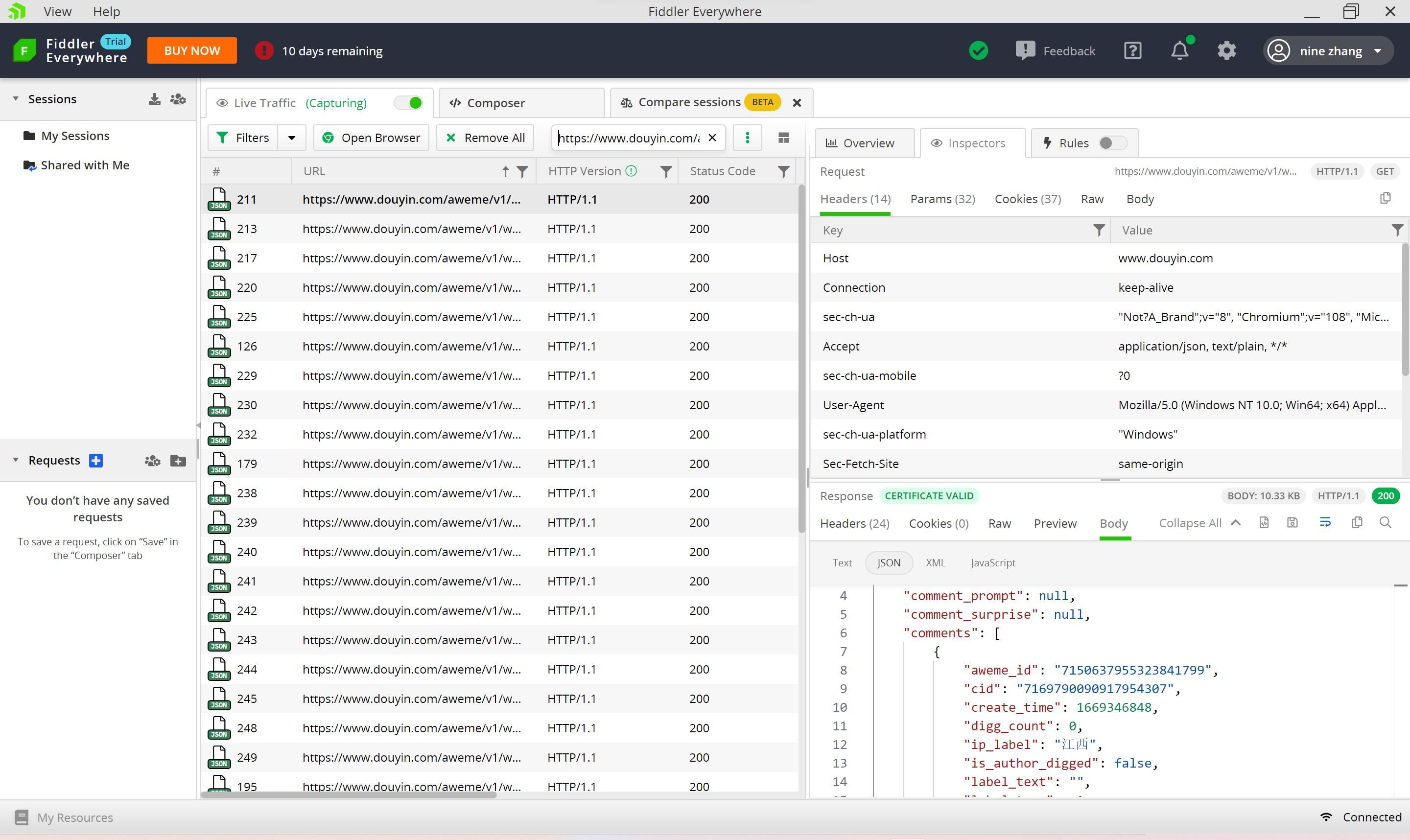
3.提取有用数据
将JSON文件内容复制粘贴到JSON解析网站,以便通过JSON视图更清晰的把握JSON数据的层次。

不难发现,评论文本信息和IP信息都在comments下以序号为标签的字典中,ip_label对应IP信息,text对应文本信息。由此可以编写Python代码提取每个JSON数据中的文本和IP信息。
四.代码结构
代码主要有两部分,comments_analysis:评论文本分析及可视化,形成词云和反应情感倾向占比的饼图;IP_analysis:对IP信息进行统计并绘制反应各省份评论人数的中国地图。代码结构图如下:

具体代码如下:
getComments.py
import json
import os
import re
import jieba.analyse
import wordcloud
from imageio import imread
from aip import AipNlp
import matplotlib.pyplot as plt
mk = imread('词云背景图.png')
def get_filepath(data_base_dir):
"""拿到json文件的路径及文件名,保存到'file_name.txt中'"""
file_name = open('file_name.txt', 'w', encoding='utf-8')
filelist = []
for filePath in os.listdir(data_base_dir):
filePath = data_base_dir + '\\' + filePath
filelist.append(filePath)
for i in filelist:
file_name.write(i + '\n')
file_name.close()
def get_1comments(js_path):
"""拿到一个json文件中的评论内容,保存到列表comment_1中并返回"""
js = open(js_path, 'r', encoding='utf-8').read()
data = json.loads(js)
comment_1 = []
for comment in data['comments']:
comment_1.append(comment['text'])
return comment_1
def get_allcomments(data_base_dir):
"""拿到所有json文件中的评论内容,保存到列表comments中并返回"""
comments = []
get_filepath(data_base_dir)
file_name = open('file_name.txt', 'r', encoding='utf-8')
for line in file_name:
comments.extend(get_1comments(line.strip()))
print('评论提取完毕!')
return comments
def form_wordcloud(comments):
"""解析评论内容并形成词云"""
word = ''.join(comments)
# 使用jieba分词并提取出现频率前200的名词、动词、形容词等有代表性的词汇
topWord_lis = jieba.analyse.extract_tags(word, topK=200, allowPOS='n''v''a''vn''an')
topWord = ' '.join(topWord_lis)
# 词云参数配置
w = wordcloud.WordCloud(
background_color='white',
# font_path='C:\Windows\Fonts\HGY2_CNKI.TTF', # 字体
width=2000,
height=1500,
max_words=1000,
max_font_size=80,
min_font_size=10,
mode='RGBA',
mask=mk, # 背景图
)
w.generate(topWord)
w.to_file('评论词云.png')
print('词云形成!')
def get_emotion(comment):
"""对一条评论进行情感分析,返回该评论的情感属性(emotion_label可能为0,1,2,分别对应消极的、中肯的、积极的)"""
# 百度API认证
APP_ID = '********'
API_KEY = '********'
SECRET_KEY = '********'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
comment = ''.join(re.findall('[\u4e00-\u9fa5]', comment)) # 去除评论文本中的特殊字符
# 调用情感倾向分析
dic = client.sentimentClassify(comment)
# 可能存在没有文本的空评论,异常处理保证程序执行的连续性
try:
emotion_label = dic['items'][0]['sentiment']
except KeyError:
return 1 # 若无内容,则为中性评论
return emotion_label
def emotion_analysis(comments):
"""对所有评论进行情感分析并绘制饼图"""
pos_comment = 0 # 积极
rel_comment = 0 # 中肯
neg_comment = 0 # 消极
for comment in comments:
if get_emotion(comment) == 0:
neg_comment += 1
elif get_emotion(comment) == 1:
rel_comment += 1
else:
pos_comment += 1
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文支持
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.style.use('fivethirtyeight') # 图表样式
attitude = ['消极的', '积极的', '中肯的'] # 标签
popularity = [neg_comment, pos_comment, rel_comment] # 数据
# 绘制饼图
plt.pie(popularity, labels=attitude, autopct='%1.1f%%',
counterclock=False, startangle=90, explode=[0, 0.1, 0])
plt.title('评论情感分析')
plt.tight_layout()
plt.savefig('情感分析结果.png')
plt.show()
print('情感分析完毕!')
def main():
data_base_dir = r'C:\Users\T-Rex\Desktop\PythonProject\douyin\data' # 数据文件的路径
comments = get_allcomments(data_base_dir)
form_wordcloud(comments)
emotion_analysis(comments)
if __name__ == "__main__":
main()
print('OK!')
get_ip.py
import json
import os
from collections import Counter
from pyecharts.charts import Map
from pyecharts.options import *
def get_filepath(data_base_dir):
"""拿到json文件的路径及文件名,保存到'file_name中'"""
file_name = open('file_name', 'w', encoding='utf-8')
filelist = []
for filePath in os.listdir(data_base_dir):
filePath = data_base_dir + '\\' + filePath
filelist.append(filePath)
for i in filelist:
file_name.write(i + '\n')
file_name.close()
def get_1data(js_path):
"""拿到一个json文件中每条评论的IP,保存到列表ip中并返回"""
js = open(js_path, 'r', encoding='utf-8').read()
js_dic = json.loads(js)
ip = []
for comment in js_dic['comments']:
ip.append(comment['ip_label'])
return ip
def get_data(data_base_dir):
"""提取所有json文件中评论的IP,保存到列表ip中并返回"""
ip = []
get_filepath(data_base_dir)
file_name = open('file_name', 'r', encoding='utf-8')
for line in file_name:
ip.extend(get_1data(line.strip()))
print('ip提取完毕!')
return ip
def count(ip):
"""统计所有IP出现的次数"""
ip_count = Counter(ip)
ipCount_list = []
ip_place = list(ip_count.keys())
ip_people = list(ip_count.values())
# 将IP数据封装成('省份',人数)的元组形式,保存到列表ipCount_list中
for i in range(len(ip_place)):
ipCount_list.append((ip_place[i], ip_people[i]))
print('统计完毕!')
return ipCount_list
def form_map(ipCount_list):
"""绘制IP分布地图"""
MAP = Map()
# 导入数据
MAP.add("各省份评论人数", ipCount_list, "china")
# 参数配置
MAP.set_global_opts(
title_opts=TitleOpts(title="IP分布地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{
"min": 1, "max": 20, "lable": "1~19人", "color": "#CCFFFF"},
{
"min": 20, "max": 40, "lable": "20~39人", "color": "#FFFF99"},
{
"min": 40, "max": 60, "lable": "40~59人", "color": "#FF9966"},
{
"min": 60, "max": 80, "lable": "60~79人", "color": "#FF6666"},
{
"min": 80, "max": 100, "lable": "80~99人", "color": "#CC3333"},
{
"min": 100, "lable": "100+", "color": "#990033"},
]
)
)
# 绘图
MAP.render("IP分布地图.html")
print('绘图完毕!')
def main():
data_base_dir = r'C:\Users\T-Rex\Desktop\PythonProject\douyin\data' # 数据文件的路径
ip = get_data(data_base_dir)
ipCount_list = count(ip)
form_map(ipCount_list)
if __name__ == "__main__":
main()
print('OK!')
五.可视化展示及分析
1.评论词云

该词云展示出了全部评论中出现频率最高的词汇,如“医学”、“小白鼠”、“可爱”、“可怜”、“解剖”、“学医”等。通过词云用户可以对全部评论的主要信息一目了然,同时也可以看到评论中出现的“热词”。
2.情感倾向分布饼图
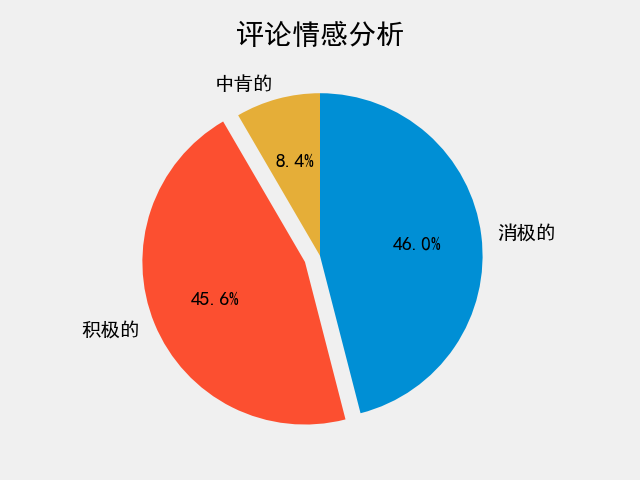
可见,持积极态度和消极态度的评论者数量均衡,只有一小部分评论者持中肯的态度。由此可知,此视频引发了较大的争议,评论者在评论区各执己见,互相抨击。
3.IP分布地图

从这张图可以看出,大部分评论者的IP为甘肃省。因为抖音会将用户创作的视频推给附近的人,所以可以推测,视频作者大概率身处甘肃。同时也可以看出,中东部地区以及新疆、广东评论者居多。
六.改进与完善
1.数据获取过程自动化程度降低,未来应进一步学习爬虫技术,找到可以直接通过URL一次性爬取全部评论数据的可行方法,同时提高代码的复用率。
2.词云中包含大量无用信息,如“不了”、“不用”、“觉得”、“感觉”、“看到”、“不想”、“时候”等。接下来应该编写一个包含常用中性词的字典,加入词云参数中用来过滤掉这些中性词。
3.情感倾向分析可能存在一定偏差。未来将进一步学习自然语言处理,利用针对短视频的评论情感倾向集来训练snownlp的情感分析模型,然后用该模型来进行情感分析以提高准确度。
4.继续学习pyecharts模块以及前端知识,使绘制的地图更美观。同时,地图图例中的数量分段应跟随评论总人数而变化,以期达到自适应的结果。
5.解决上述问题后,将设计一个可以嵌入浏览器的脚本,使用户在刷短视频的同时可以看到上述可视化成果。