模型量化
背景
AI计算的数据格式
计算机采用0/1来标识信息,每个0或每个1代表一个比特/二进制位(bit),信息一般以三种形式表示:
字符串,最小单元是char,占8个比特(bit, 简写b)内存,等于1个字节(Byte, 简写B)。1字节=8bit=8b。
整数INT(Integer),INT后面数值表示该整数类型占用内存的比特位数,常用INT8、INT16、INT32、INT64
浮点数PF(Floating points),PF后面数值也代表该浮点类型占用内存的比特位数,常用FP16(半精度)、FP32(单精度)和FP64(双精度)。
量化技术
常用两种量化方法,训练后量化PTQ(Post training quantization)和量化感知训练QAT(Quantize-aware training)。PTQ是在模型经过训练后进行的,但一般PTQ精度达不到要求,就会考虑使用QAT。在量化过程中会产生数据溢出和精度不足舍入错误,会混合使用单精度和半精度数据格式,优势是压缩模型大小,但因为模型结构和参数没有发生变化,再加上不同精度需要进行对齐运算,反而会导致计算速度降低,针对这种场景,英伟达GPU有专门的计算单元(Tensor Core等),完成单指令混合精度运算,提升计算速度。
量化工具
随着量化技术发展和成熟,已经有很成熟的软件工具,其中包括了英伟达的TensorRT。TensorRT是英伟达开发的深度学习推理引擎(GPU Inference Engine),是一套从模型获得,到模型优化与编译,再到部署的完整工具。模型获得支持Tensorflow、Pytorch、Caffe等主流训练框架,在模型优化与编译过程中,已经支持混合精度、PTQ和QAT量化训练,最终将训练好的模型部署于嵌入端、云端、以及汽车上的硬件平台上运行。

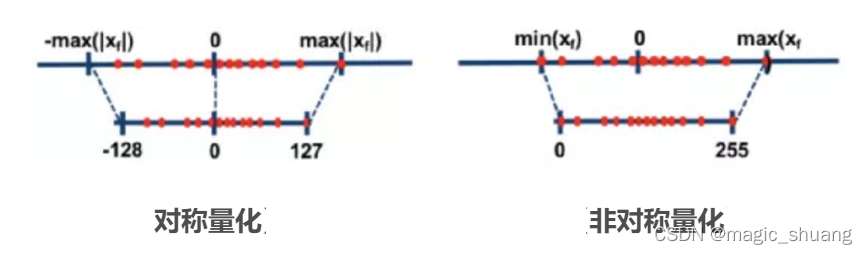
线性量化
常用的线性量化过程可以使用以下数学表达式表示:
$$
Q = clamp(Round(R/S+Z))=Q_{max},R \in float 且R>T_{max} \
Q = clamp(Round(R/S+Z))=Round(R/S+Z).R\in float且T_{min}<R<T_{max} \
Q = clamp(Round(R/S+Z))=Q_{min},R\in float且R<T_{min} \
\
R=(Q-Z)*S
$$
其中,Q表示量化后的定点数,R表示量化前的浮点数,Z就是zero_point,即浮点数映射到定点之后,浮点0所对应的定点值。S就是scale,即缩放尺度。Round()函数就是四舍五入。clamp()函数的作用是把一个值限制在一个上限和下限之间。Tmax表示浮点数的最大阈值,Tmin表示浮点数的最小阈值。Qmax表示定数的最大值,Qmin表示定点数的最小值。
通过换算可以得到阈值和线性映射参数 S 和 Z 的数学关系,在确定了阈值后,也就确定了线性映射的参数。
$$
S=(T_{max}-T_{min})/(Q_{max}-Q_{min})\
Z=Q_{max}-T_{max}/S
$$
数据类型 |
取值范围 |
float32 |
-2^31 ~ 2^31-1 |
int8 |
-2^7 ~ 2^7-1 (-128 ~ 127) |
uint8 |
0 ~ 2^8-1 (0~255) |
从上述的映射关系中,如果知道了阈值,那么其对应的线性映射参数也就知道了,整个量化过程也就明确了.
那么该如何确定阈值呢?
一般来说,对于权重的量化,由于权重的数据分布是静态的,一般直接找出 MIN 和 MAX 线性映射即可;而对于推理激活值来说,其数据分布是动态的,为了得到激活值的数据分布,往往需要一个所谓校准集的东西来进行抽样分布,有了抽样分布后再通过一些量化算法进行量化阈值的选取(饱和量化)。
举例:
模型训练后权重或激活值往往在一个有限的范围内分布,如权重值范围为[-2.0, 6.0],即Tmax = 6.0,Tmin = -2.0(非饱和量化)。然后我们用int8进行模型量化,则定点量化值范围为[-128, 127],即Qmax = 127,Qmin = -127,那么S和Z的求值过程如下:
$$
S = 6.0 - (-2.0) / (127 - (-128)) = 8.0 / 255 ≈ 0.03137255\
Z = 127 - 6.0 / 0.03137255 ≈ 127 - 191.25 ≈ -64.25 ≈ -64
$$
可以得到如下对应关系:
浮点数 |
定点数 |
6.0 |
-128 |
0 |
-64 |
-2.0 |
127 |
得到量化参数S和Z后,我们就可以求任意一个浮点数对应的定点数,比如说有一个权重等于0.28,即R=0.28
$$
Q = 0.28 / 0.03137255 + (-64) ≈ -55
$$