文章目录
论文翻译
0. Abstract
不平衡学习(IL),即从类不平衡数据中学习无偏模型,是一个具有挑战性的问题。包括重采样和重新加权在内的典型IL方法是基于一些启发式假设而设计的。在他们的假设不成立的复杂任务中,他们经常遭受不稳定的性能、差的适用性和高的计算成本。本文介绍了一种新的集成IL框架MESA。它在迭代中自适应地重采样训练集,得到多个分类器,形成级联集成模型。MESA直接从数据中学习采样策略,以优化最终指标,而不是采用随机试探法。此外,与流行的基于元学习的IL解决方案不同,我们通过在任务不可知的元数据上独立地训练元采样器,来分离MESA中的模型训练和元训练。这使得MESA普遍适用于大多数现有的学习模型,元采样器可以有效地应用于新的任务。在合成和真实任务上的大量实验证明了MESA的有效性、健壮性和可移植性。
1. Introduction
由于自然偏斜的类分布,类不平衡在许多真实世界的应用中被广泛观察到,例如点击预测、欺诈检测和医疗诊断[13,15,21]。在解决类别不平衡问题时,规范分类算法通常会导致偏差,即在全局准确性方面表现良好,但在少数类别上表现不佳。然而,从学习和实践的角度来看,通常对少数类产生更高的兴趣[18, 19]。典型的不平衡学习(IL)算法试图通过数据重采样[6,16,17,26,35]或重新加权[30,33,40]在学习过程中来消除偏差。最近,集成学习被结合以减少由重采样或重加权引入的方差,并且已经取得了令人满意的性能[23]。 然而,在实践中,已经观察到所有这些方法都受到三个主要限制:(I)由于对异常值的敏感性,性能不稳定。(II)由于领域专家手工制作成本矩阵的先决条件,适用性差。(III)计算实例之间距离的高成本。
不考虑计算问题,我们将传统 IL方法的不令人满意的性能归因于对训练数据做出的启发式假设的有效性。例如,一些方法[7,12,32,39]假设具有较高训练误差的实例对于学习来说更有信息量。然而,错误分类可能是由异常值引起的,在这种情况下,在上述假设下会出现错误强化。另一个广泛使用的假设是围绕少数实例生成合成样本有助于学习[7,8,46]。这种假设仅在少数数据被很好地聚集并且具有足够的辨别力时才成立。如果训练数据非常不平衡或者具有许多损坏的标签,则少数类将很难被代表并且缺乏清晰的结构。在这种情况下,在这种假设下工作会严重影响性能。
因此,更希望开发一个自适应的IL框架,它能够在没有直觉假设的情况下处理复杂的现实世界任务。受到元学习最新发展的启发[25],我们提出在集成不平衡学习(EIL)框架下实现元学习机制。事实上,一些初步的努力[37,38,41]研究了将元学习应用于信息素养问题的潜力。然而,由于依赖于模型的优化过程,这些工作具有有限的概括能力。它们的元学习器被限制为与单个DNN共同优化,这极大地限制了它们在其他学习模型(例如,基于树的模型)中的应用以及在更强大的EIL框架中的部署。
在本文中,我们提出了一个通用的 EIL框架MESA,它从数据中自动学习其策略,即元采样器,以优化不平衡分类。主要思想是建模一个元采样器,作为嵌入在迭代集成训练过程中的自适应欠采样解决方案。在每次迭代中,它将集成训练的当前状态(即,训练集和验证集上的分类误差分布)作为其输入。在此基础上,元采样器选择一个子集来训练一个新的基分类器,然后将其添加到集成中,从而获得一个新的状态。我们期望元采样器通过从这样的交互中学习来最大化最终的泛化性能。为此,我们使用强化学习(RL)来解决元采样器的不可微优化问题。综上所述,本文做出了以下贡献。(I)我们提出了 MESA,这是一个通用的EIL框架,它通过从数据中自动学习自适应欠采样策略来展示优越的性能。(II)对EIL系统中跨任务元信息的提取和使用进行了初步探索。这种元信息的使用赋予了元采样器跨任务的可移植性。经过预训练的元采样器可以直接应用于新的任务,从而大大降低元训练带来的计算成本。(III)与元学习者被设计为在训练期间与特定学习模型(即DNN)协同优化的流行方法不同,我们在 MESA中将模型训练和元训练过程解耦。这使得我们的框架通常适用于大多数统计和非统计学习模型(例如,决策树、朴素贝叶斯、k-最近邻分类器)。
2. Related Work
费尔南德斯等人[1],郭等[15],以及何等[18,19]提供了不平衡学习的算法和应用的系统评论。本文主要研究二元不平衡分类问题,这是研究最广泛的问题之一 15,23]在不平衡的学习中。这种问题广泛存在于实际应用中,例如欺诈检测(欺诈对正常)、医疗诊断(患病对健康)和网络安全(入侵对用户连接)。我们主要回顾了关于这个问题的现有工作如下。
重采样。重采样方法集中于修改训练集以平衡类分布(即,过采样/欠采样[6,16,17,35,42])或过滤噪声(即清理重采样[26,45]).随机重采样通常会导致严重的信息丢失或过度捕捞,因此许多先进的方法探索距离信息来指导其采样过程[15]。然而,在大规模数据集上,计算实例之间的距离在计算上是昂贵的,并且当数据不符合它们的假设时,这样的策略甚至可能失败。
重加权。重加权方法将不同的权重分配给不同的实例,以减轻分类器对多数类的偏见(例如[5,12,31,33])。许多最近的重新加权方法,如无焦点加权法[30]和GHM [28]是专门为DNN损失函数工程设计的。类级别的重新加权,如成本敏感学习[33]更加通用,但是需要领域专家事先给出一个成本矩阵,这在实践中通常是不可行的。
集成方法。已知集成不平衡学习(EIL)通过组合多个分类器的输出来有效地改善典型的 IL 解决方案(例如7,32,34,39,46])。事实证明,这些EIL方法极具竞争力[23]因此在IL中越来越受欢迎15]。然而,它们中的大多数是重采样/重新加权解决方案和集成学习框架的直接组合,例如SMOTE [6]+ADABOOST [12]= smote boot[7].因此,尽管EIL技术有效地降低了由重采样/重加权引入的方差,但是这些方法仍然由于其基于启发式的设计而遭受不令人满意的性能。
元学习方法。受最近元学习发展的启发[11,25],有一些研究将元学习用于解决信息素养问题。典型的方法包括学习动态损失函数的Learning to Teach [48]、学习小批量课程的MentorNet [22]和学习隐式/显式数据加权函数的L2 RW [38]/Meta-Weight-Net [41]。尽管如此,所有这些方法都局限于通过梯度下降与 DNN 共同优化。由于深度学习的成功依赖于大量的训练数据,主要来自像计算机视觉和自然语言处理这样的结构良好的数据领域,这些方法在传统分类任务(例如,小/非结构化/表格数据)中应用于其他学习模型(例如,基于树的模型及其集成变体,如梯度提升机器)受到很大限制。
我们在表1中给出了二元不平衡分类问题的现有IL解决方案与我们的MESA的全面比较。与其他方法相比,MESA的目标是直接从数据中学习重采样策略。由于在重采样过程中不涉及距离计算、领域知识或相关启发式算法,因此能够执行快速和自适应的重采样。
表1:梅萨与现有不平衡学习方法的比较,注意|N| 》 |P|。
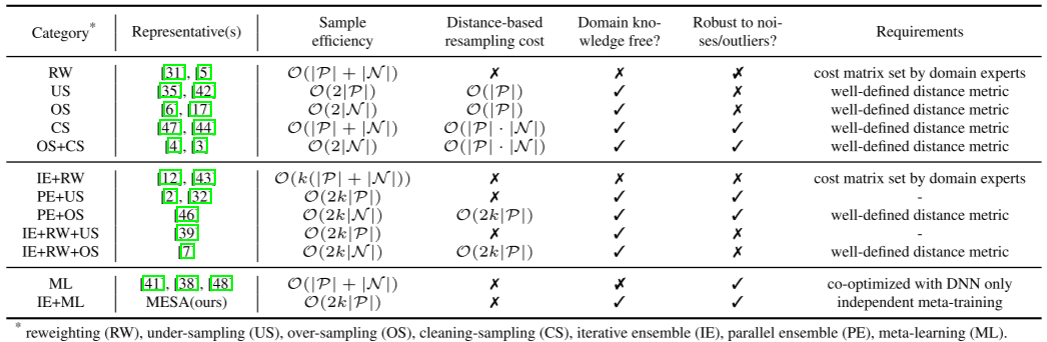
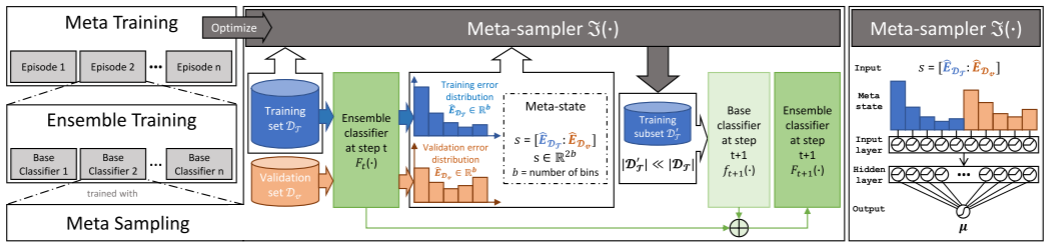
图1:MESA框架概览
3. The Proposed MESA framework
为了利用集成学习和元学习的优势,我们提出了一个新的 EIL框架MESA,它与元采样器一起工作。如图1 所示。MESA由三部分组成:元采样和集成训练以构建集成分类器,元训练以优化元采样器。我们将在本节中分别描述它们。
具体地,MESA被设计成:(I)基于元信息执行重采样,以进一步提高集成分类器的性能;(II)解耦模型训练和元训练,以实现对不同分类器的普遍适用性;(III)在任务不可知的元数据上训练元采样器,以获得跨任务的可转移性,并降低新任务的元训练成本。
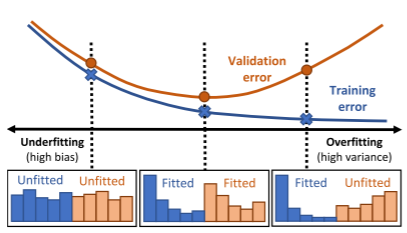
图2:不同元状态的一些示例(s = [EDτ:EDv ])及其对应的集成训练状态。元状态反映了当前分类器与训练集的匹配程度,以及它泛化到未知验证数据的程度。注意这种表示独立于特定任务的属性(例如,数据集大小、特征空间)因此可用于支持元采样器跨不同任务执行自适应重采样。
符号。令 X : R d \mathcal X:\mathbb R^d X:Rd为输入特征空间, Y : { 0 , 1 } \mathcal Y:\{0,1\} Y:{ 0,1}为标签空间。一个实例用 ( x , y ) (x,y) (x,y)表示,其中 x ∈ X , y ∈ Y x ∈ \mathcal X,y ∈ \mathcal Y x∈X,y∈Y。不失一般性,我们总是假定少数类是积极的。给定不平衡数据集 D : { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x n , y n ) } D:\{(x_1,y_1),(x_2,y_2),···,(x_n,y_n)\} D:{(x1,y1),(x2,y2),⋅⋅⋅,(xn,yn)},则少数类集合为 P : { ( x , y ) ∣ y = 1 , ( x , y ) ∈ D } \mathcal P:\{(x,y)|y = 1,(x,y)∈ D\} P:{(x,y)∣y=1,(x,y)∈D}并且多数类集合是 N : { ( x , y ) ∣ y = 0 , ( x , y ) ∈ D } \mathcal N:\{(x,y)|y = 0,(x,y)∈ D\} N:{(x,y)∣y=0,(x,y)∈D}.对于高度不平衡的数据,我们有 ∣ N ∣ ≫ ∣ P ∣ |\mathcal N| \gg|\mathcal P| ∣N∣≫∣P∣。我们使用 f : x → [ 0 , 1 ] f:x → [0,1] f:x→[0,1]表示单个分类器,而 F k : x → [ 0 , 1 ] F_k:x → [0,1] Fk:x→[0,1]表示由 k k k个基分类器组成的集成分类器。我们使用 D τ D_τ Dτ和 D v D_v Dv分别表示训练集和验证集。
元状态。如前所述,我们期望找到一种任务不可知的表示,它可以为元采样器提供集成训练过程的信息。受“梯度/硬度分布”概念的启发 [28,34],我们引入训练和验证误差的直方图分布作为集成训练系统的元状态。
形式上,给定一个数据实例 ( x , y ) (x,y) (x,y)和一个集成分类器 F t ( ⋅ ) F_t(\cdot) Ft(⋅),分类误差 e e e被定义为 x x x为正的预测概率和真实标签 y y y,即 ∣ F t ( x ) − y ∣ |F_t(x)-y | ∣Ft(x)−y∣之间的绝对差。假设数据集 D D D上的误差分布为 E D E_D ED,则直方图近似的误差分布由向量 E ^ D ∈ R b \hat E_D ∈ \mathbb R^b E^D∈Rb给出,其中 b b b是直方图中的条柱数。具体来说,矢量 E ^ D \hat E_D E^D的第 i i i个分量可以计算如下:
E ^ D i = ∣ { ( x , y ) ∣ i − 1 b ≤ a b s ( F t ( x ) − y ) < i b , ( x , y ) ∈ D } ∣ ∣ D ∣ , 1 ≤ i ≤ b (1) \hat E_D^i = \frac{|\{(x,y)|\frac{i-1}b\le abs(F_t(x)-y)<\frac ib,(x,y)\in D\}|}{|D|},1\le i\le b\tag1 E^Di=∣D∣∣{(x,y)∣bi−1≤abs(Ft(x)−y)<bi,(x,y)∈D}∣,1≤i≤b(1)
将训练集和验证集上的误差分布向量级联之后,我们具有元状态:
s = [ E ^ D t : E ^ D v ] ∈ R 2 b (2) s=[\hat E_{D_t}:\hat E_{D_v}]\in \mathbb R^{2b}\tag2 s=[E^Dt:E^Dv]∈R2b(2)
直观地,直方图误差分布 E ^ D \hat E_D E^D显示给定分类器拟合数据 D D D的程度。当 b = 2 b = 2 b=2时,其在 E ^ D 1 \hat E_D^1 E^D1中报告准确度评分,在 E ^ D 2 \hat E_D^2 E^D2中报告误分类率(分类阈值为0.5)。当 b > 2 b>2 b>2时,它以更细的粒度显示了“易”样本(误差接近0)和“难”样本(误差接近1)的分布,从而包含了更多的信息来指导重采样过程。此外,由于我们考虑了训练集和验证集两者,所以元状态还向元采样器提供关于当前集成模型的偏差/方差的信息,从而支持其决策。我们在图2中给出了一些示例。
元采样。通过使用复杂的元采样器(例如,设置大的输出层或使用递归神经网络)来做出实例级决策是非常耗时的,因为单独更新 C u C_u Cu的复杂度是 O ( ∣ D ∣ ) \mathcal O(|D|) O(∣D∣)。此外,复杂的模型架构也带来了额外的内存开销和优化困难。为了使MESA更加简洁有效,我们使用了高斯函数简化元采样过程和采样器本身的技巧,把 C u C_u Cu从 O ( ∣ D ∣ ) \mathcal O(|D|) O(∣D∣)减小为 O ( ∣ 1 ∣ ) \mathcal O(|1|) O(∣1∣)。
具体来说,让 ð \eth ð表示元采样器,它基于输入元状态 s s s输出标量 [ 0 , 1 ] [0,1] [0,1],即 μ ∼ ð ( μ ∣ s ) \mu \sim \eth (\mu |s) μ∼ð(μ∣s)。然后,我们对每个实例的分类误差应用高斯函数 g μ , σ ( x ) g_{\mu ,σ}(x) gμ,σ(x),以确定其(非标准化)采样权重,其中 g μ , σ ( x ) g_{\mu ,σ}(x) gμ,σ(x)定义为:
g μ , σ ( x ) = 1 σ 2 π e − 1 2 ( x − μ σ ) 2 (3) g_{\mu ,σ}(x) = \frac1{\sigma\sqrt{2\pi}}e^{-\frac12(\frac{x-\mu}\sigma)^2}\tag3 gμ,σ(x)=σ2π1e−21(σx−μ)2(3)
注意,在公式3中, e e e是欧拉数, µ ∈ [ 0 , 1 ] µ ∈ [0,1] µ∈[0,1]由元采样器给出, σ σ σ是超参数。有关我们的超参数设置的讨论和指南,请参见第C.2节。上述元采样程序样本 ( ⋅ ; F ,µ, σ ) (·;F,µ,σ) (⋅;F,µ,σ)总结于算法1中。
算法1 采样 ( D τ ; F , μ , σ ) (D_τ;F,\mu,\sigma) (Dτ;F,μ,σ)
要求: D t , F , μ , σ D_t,F,\mu,\sigma Dt,F,μ,σ
1:初始化:从 D τ \mathcal D_τ Dτ导出多数集 P τ \mathcal P_τ Pτ和少数集 N τ \mathcal N_τ Nτ
2:为 N τ \mathcal N_τ Nτ中的每个 ( x i , y i ) (x_i,y_i) (xi,yi)分配权重:
w i = g ( µ , σ ) ( ∣ F ( x i ) − y i ∣ ) ∑ ( x j , y j ) ∈ N τ g ( µ , σ ) ( ∣ F ( x i ) − y i ∣ ) w_i =\frac{g_{(µ,σ)}(|F(x_i)− y_i|)}{\sum _{(x_j,y_j)∈\mathcal N_τ} g_{(µ,σ)}(|F(x_i)− y_i|)} wi=∑(xj,yj)∈Nτg(µ,σ)(∣F(xi)−yi∣)g(µ,σ)(∣F(xi)−yi∣)
3:从 N τ \mathcal N_τ Nτ中采样多数类子集 N τ ′ \mathcal N_τ' Nτ′,即,采样权重 w w w,其中 ∣ N τ ′ ∣ = ∣ P τ ∣ |\mathcal N_τ'|=|\mathcal P_τ| ∣Nτ′∣=∣Pτ∣
4:返回平衡子集 D τ ′ = N τ ′ ∪ P τ \mathcal D_τ' = \mathcal N_τ'\cup\mathcal P_τ Dτ′=Nτ′∪Pτ
集成训练.给定一个元采样器: ð : R 2 b → [ 0 , 1 ] \eth:\mathbb R^{2b} → [0,1] ð:R2b→[0,1]和元采样策略,我们可以利用采样器采样的数据集迭代训练新的基分类器。在第 t t t次迭代时,具有当前集成 F t ( ⋅ ) F_t(·) Ft(⋅),我们可以通过应用公式1和2获得 E ^ D τ 、 E ^ D v \hat E_{\mathcal D_τ}、\hat E_{\mathcal D_v} E^Dτ、E^Dv和元状态 s t s_t st。然后用子集 D t + 1 , τ ′ = \mathcal D_{t+1,τ}'= Dt+1,τ′=采样 ( D τ ; F t , μ t , σ ) (D_τ;F_t,\mu_t,\sigma) (Dτ;Ft,μt,σ)训练获得新的基分类器 f t + 1 ( x ) f_{t+1}(x) ft+1(x),其中 μ t ∼ ð ( μ t ∣ s t ) \mu_t∼\eth(\mu_t |s_t) μt∼ð(μt∣st), D τ D_τ Dτ是原始训练集。注意, F 1 ( ⋅ ) F_1(·) F1(⋅)是在随机平衡子集上训练的,因为在第一次迭代中没有训练过的分类器。更多详情见算法2。
算法2 MESA集成训练
要求: D t , D v , ð , σ , f , b , k \mathcal D_t,\mathcal D_v,\eth ,\sigma,f,b,k Dt,Dv,ð,σ,f,b,k
1:使用随机的平衡子集训练 f 1 ( x ) f_1(x) f1(x)
2:从 t = 1 t=1 t=1到 t = k − 1 t=k-1 t=k−1循环:
3: F t ( x ) = 1 t ∑ i = 1 t f i ( x ) F_t(x)=\frac1 t\sum^t_{i=1}f_i(x) Ft(x)=t1∑i=1tfi(x)
4: 通过公式1计算 E ^ D τ \hat E_{\mathcal D_τ} E^Dτ和 E ^ D v \hat E_{\mathcal D_v} E^Dv。
5: s t = [ E ^ D τ : E ^ D v ] s_t=[\hat E_{\mathcal D_τ}:\hat E_{\mathcal D_v}] st=[E^Dτ:E^Dv]
6: μ t ∼ ð ( μ t ∣ s t ) \mu_t∼\eth(\mu_t |s_t) μt∼ð(μt∣st)
7: D t + 1 , τ ′ = 采样 ( D τ ; F t , μ t , σ ) \mathcal D_{t+1,τ}'=采样(D_τ;F_t,\mu_t,\sigma) Dt+1,τ′=采样(Dτ;Ft,μt,σ)
8: 用 D t + 1 , τ ′ \mathcal D_{t+1,τ}' Dt+1,τ′训练新的分类器 f t + 1 ( x ) f_{t+1}(x) ft+1(x)
9:返回 F k ( x ) = 1 k ∑ i = 1 k f i ( x ) F_k(x)= \frac1 k \sum^k_{i=1} f_i(x) Fk(x)=k1∑i=1kfi(x)
元训练.如上所述,我们的元采样器 ð \eth ð被训练为通过迭代地选择其训练数据来优化集成分类器的广义性能。它以训练系统的当前状态 s s s作为输入,然后输出高斯函数的参数 µ µ µ来决定每个实例的采样概率。元采样器期望从这种状态( s s s)-动作( µ µ µ)-状态(新的 s s s)相互作用中学习和调整其策略。因此,训练的不可微优化问题可以自然地通过强化学习(RL)来处理。
算法3 MESA元训练
1:初始化:容量为 N N N的重放存储器 M \mathcal M M,网络参数 ψ 、 ψ ˉ 、 θ 和 φ ψ、\bar ψ、θ和\varphi ψ、ψˉ、θ和φ
2:从场景1到M循环:
3: 对于所有情况步长t执行:
4: 从ENV观察 s t s_t st 在算法2的3-5行中
5: 执行 μ t ∼ ð φ ( μ t ∣ s t ) \mu_t∼\eth_\varphi(\mu_t |s_t) μt∼ðφ(μt∣st) 在算法2的6-8行中
6: 观察奖励 r t = P ( F t + 1 , D v ) − P ( F t , D v ) r_t=P(F_{t+1},D_v)-P(F_{t},D_v) rt=P(Ft+1,Dv)−P(Ft,Dv)和 s t + 1 s_{t+1} st+1
7: 更新存储 M = M ∪ { ( s t , µ t , r t , s t + 1 ) } \mathcal M=\mathcal M ∪ \{(s_t,µ_t,r_t,s_{t+1})\} M=M∪{(st,µt,rt,st+1)}
8: 对于每个梯度步长执行:
9: 根据[14]更新 ψ 、 ψ ˉ 、 θ 和 φ ψ、\bar ψ、θ和\varphi ψ、ψˉ、θ和φ
10:返回带有参数 φ \varphi φ的元采样器 ð \eth ð
我们把集成训练系统作为作为RL中的环境(ENV)设置。相应的马尔可夫决策过程(MDP)由元组 ( S , A , p , r ) (\mathcal S,\mathcal A, p, r) (S,A,p,r)定义,其中状态空间 S : R 2 b \mathcal S:\mathbb R^{2b} S:R2b和行动空间 A : [ 0 , 1 ] \mathcal A:[0,1] A:[0,1]是连续的,未知的状态转移概率 p : S × S × A → [ 0 , ∞ ) p: \mathcal S×\mathcal S×\mathcal A→[0,∞) p:S×S×A→[0,∞)代表了考虑当前状态 s t ∈ S s_{t}∈\mathcal S st∈S和行动 a t ∈ A a_{t}∈\mathcal A at∈A后的下一个状态的概率密度 s t + 1 ∈ S s_{t+1}∈\mathcal S st+1∈S。更具体地说,在每一个场景,我们反复训练 k k k个基分类器 f ( ⋅ ) f(·) f(⋅)并且形成一个级联集成分类器 F k ( ⋅ ) F_k(·) Fk(⋅)。在每个环境时间步, ENV提供元状态 s t = [ E ^ D τ : E ^ D v ] s_t=[\hat E_{\mathcal D_τ}:\hat E_{\mathcal D_v}] st=[E^Dτ:E^Dv], 然后通过 a t ∼ ð ( μ t ∣ s t ) a_t∼\eth(\mu_t |s_t) at∼ð(μt∣st)选择行动 a t a_t at。即 a t ⇔ µ t a_t⇔µ_t at⇔µt。一个新的基分类器 f t + 1 ( ⋅ ) f_{t+1}(·) ft+1(⋅)使用子集 D t + 1 , τ ′ = 采样 ( D τ ; F t , μ t , σ ) \mathcal D_{t+1,τ}'=采样(D_τ;F_t,\mu_t,\sigma) Dt+1,τ′=采样(Dτ;Ft,μt,σ)训练。在添加 f t + 1 ( ⋅ ) f_{t+1}(·) ft+1(⋅)到集成分类器后,新的状态 s t + 1 s_{t+1} st+1被采样,即 s t + 1 ∼ p ( s t + 1 ; s t ; a t ) s_{t+1}∼p(s_{t+1};s_t;a_t) st+1∼p(st+1;st;at) 。给定的性能指标函数 P ( F , D ) → R P (F, D)→\mathbb R P(F,D)→R,奖励 r r r被设置为 F F F在更新之前和之后的泛化性能差(使用遮挡验证为无偏估计),即 r t = P ( F t + 1 , D v ) − P ( F t , D v ) r_t = P(F_{t+1},Dv)−P(F_t,Dv) rt=P(Ft+1,Dv)−P(Ft,Dv)。元采样器的优化目标(即,累积回报)因此是集成分类器的泛化性能。
我们利用基于最大熵RL框架的非策略行动者-评论者,深度RL算法软行动者-评论者[14](SAC)来优化我们的元采样器。在我们的例子中,我们考虑了一个参数化的状态值函数 V ψ ( s t ) V_ψ(s_t) Vψ(st)和它对应的目标网络 V ψ ( s t ) V_ψ(s_t) Vψ(st),一个软Q函数 Q θ ( s t , a t ) Q_θ(s_t,a_t) Qθ(st,at),以及一个易处理的策略(元采样器) ð φ ( a t ∣ s t ) \eth_\varphi(a_t |s_t) ðφ(at∣st)。这些网络的参数是 ψ 、 ψ ˉ 、 θ 和 φ ψ、\bar ψ、θ和\varphi ψ、ψˉ、θ和φ。SAC论文[14]中给出了更新这些参数的规则。在算法3中总结了 ð φ \eth_\varphi ðφ的元训练过程。
复杂性分析,MESA的复杂度分析详见C.1节,相关验证实验见图7。
4. Experiments
为了全面评估MESA的有效性,进行了两个系列的实验:一个在受控的合成简单数据集上进行可视化,另一个在真实世界的不平衡数据集上验证MESA在实际应用中的性能。我们还在真实数据集上进行了扩展实验,以验证MESA的鲁棒性和跨任务迁移性。
4.1 Experiment on Synthetic Datasets
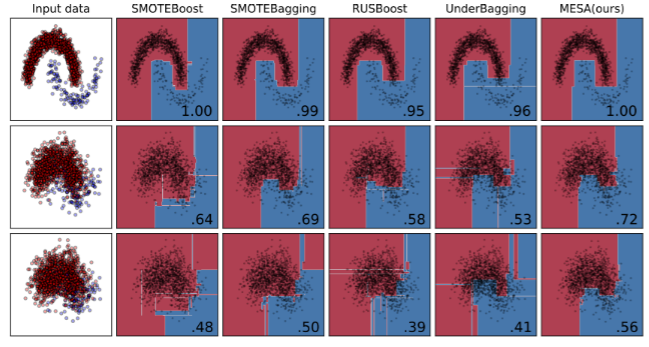
图3:MESA与4种代表性传统EIL方法(SMOTEBOOST [7]、SMOTEBAGGING [46]、RUSBOOST [39]和UNDERBAGGING [2])在3个简单数据集上的比较,这些简单数据集具有不同水平的基础类别分布重叠(第1/2/3行中重叠较少/中等/高度)。每个子图右下角的数字代表相应分类器的AUCPRC评分。
设置详细信息。我们构建了一系列不平衡的简单数据集,这些数据集对应于不同级别的底层类分布重叠,如图3所示。所有数据集具有相同的不平衡比率 2 ^2 2( ∣ N ∣ / ∣ P ∣ = 2000 / 200 = 10 |\mathcal N|/|\mathcal P|= 2000/200 = 10 ∣N∣/∣P∣=2000/200=10)。本实验将MESA与EIL的4个主要分支(并行/迭代集成+欠采样/过采样)的4种代表性算法进行了比较,即:SMOTEBOOST[7]、SMOTEBAGGING[46]、RUSBOOST[39]和UNDERBAGGING[2]。所有的EIL方法都使用决策树作为基分类器,集成大小为5。
可视化和分析。我们绘制了不同EIL算法学习的输入数据集和决策边界图,图中显示了MESA在不同情况下取得的最佳性能。我们可以观察到:所有测试的方法在较少重叠的数据集(第一行)上表现良好。注意,随机欠采样会丢弃一些重要的多数样本(例如,在"∩"形分布右端的数据点),并导致信息丢失。这使得RUSBOOST和UNDERBAGGING的表现略弱于其竞争对手。随着重叠的加强(第2行),在基于增强的方法的训练过程期间,增加的噪声量获得高样本权重,即SMOTEBOOST和RUSBOOST,从而导致较差的分类性能。基于BAGGING的方法,即SMOTEBAGGING和UNDERBAGGING受噪声影响较小,但仍低于MESA。即使在重叠程度极高的数据集(第3行)上,MESA仍然给出了符合潜在分布的稳定合理的决策边界。这是因为元采样器可以朝着良好的预测性能自适应地选择有信息的训练子集,同时对噪声/异常值是鲁棒的。实验结果表明,MESA在处理分布重叠、噪声和少数类代表性差等问题上优于其他传统EIL基线。
4.2 Experiment on Real-world Datasets
设置详细信息。为了验证MESA在实际应用中的有效性,我们将实验扩展到来自UCI知识库[10]和KDD CUP 2004的真实世界不平衡分类任务。为确保全面评估,这些数据集的属性差异很大,不平衡比(IR)范围为9.1:1至111:1,数据集大小范围为531至145751,特征数量范围为6至617(详细信息请参见B节中的表7)。对于每个数据集,我们排除20%的验证集,并报告4重分层交叉验证的结果(即,60%/20%/20%训练/验证/测试拆分)。使用精确度-召回率曲线下面积(AUCPRC)评价性能,与F-score、ROC和准确度等其他指标相比,AUCPRC是一种无偏倚且更全面的类别不平衡任务指标[9]。
表2:MESA与其他代表性重采样方法的比较。
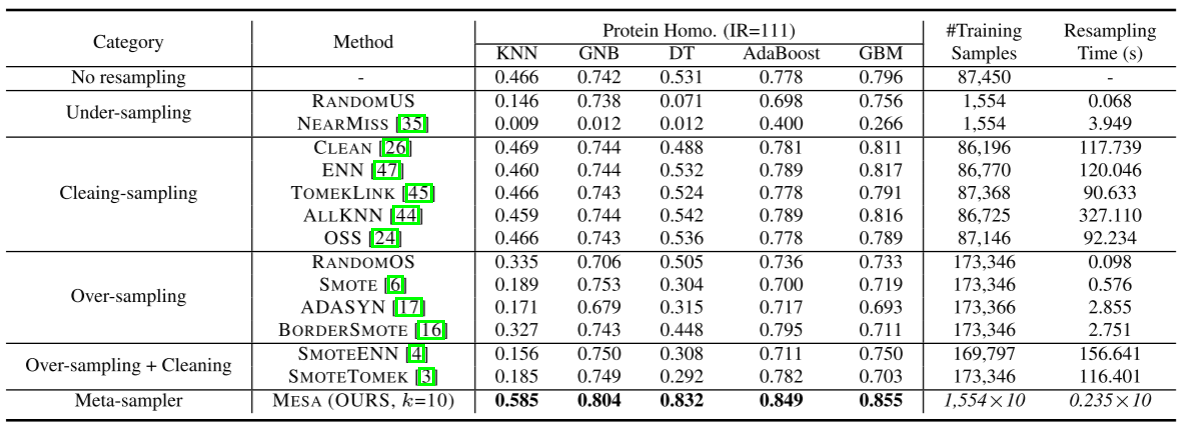
与重采样不平衡学习(IL)方法的比较。我们首先将MESA与重采样技术进行比较,重采样技术在实践中广泛用于预处理不平衡数据[15]。我们从基于重采样的IL的4个主要分支,即欠采样/过采样/清洁采样和过采样+清洁采样后处理中选取了12种有代表性的方法。我们在具有挑战性的高度不平衡(IR=111)人蛋白上测试了所有方法。检查其效率和效力任务。五种不同的分类器,即K近邻(KNN)、高斯朴素贝叶斯(GNB)、决策树(DT)、自适应提升(AdaBoost)和梯度提升机(GBM)被用于与不同的重采样方法协作。我们还记录了用于模型训练的样本数和用于执行重采样的时间。
表2详细列出了实验结果。通过学习自适应重采样策略,MESA在只使用少量训练样本的情况下大大优于其他传统的数据重采样方法。在这样一个高度不平衡的数据集中,少数类代表性差,缺乏清晰的结构。因此,依赖于少数对象之间的关系的过采样方法(如SMOTE)可能会恶化分类性能,即使它们生成并使用大量合成样本进行训练。另一方面,欠采样方法根据其规则丢弃大部分样本,导致显著的信息丢失和较差的性能。清理-采样方法旨在从数据集中去除噪声,但是重采样时间相当高并且改进微不足道。
表3:MESA与其他代表性的基于欠采样的EIL方法的比较。


图4:MESA与其他代表性过采样EIL方法的比较。
与集成不平衡学习方法的比较。我们进一步比较了MESA和7种代表性的EIL方法在4个真实世界不平衡分类任务上的性能。基线包括4种基于欠采样的EIL方法,即:RUSBOOST [39]、UNDERBAGGING[2]、SPE [34]、CASCADE[32]和3种基于过采样的EIL方法,即:SMOTEBOOST[7]、SMOTEBAGGING[46]和RAMMOBOOST[8]。我们使用决策树作为所有EIL方法的基础学习器,遵循大多数先前工作[15]的设置。
我们在表3中报告了具有不同集合大小(k=5、10、20)的各种USB-EIL方法的AUCPRC评分。实验结果表明,MESA算法在各种实际任务中均取得了较好的性能。对于基线方法,我们可以观察到RUSBOOST和UNDERBAGGING由于随机欠采样可能丢弃具有重要信息的样本而遭受信息损失,这种影响在高度不平衡的任务中更加明显。相比之下,改进的SPE和CASCADE采样策略使其性能相对较好,但仍逊于MESA。此外,由于MESA提供了一个自适应重采样器,使集成训练收敛得更快更好,当在高度不平衡的任务中使用小集成时,其优势尤其明显。在乳腺X射线摄影数据集(IR=42)上,与第二最佳评分相比,当k=5/10/20时,MESA分别实现了24.70%/12.00%/5.22%的性能增益。
我们进一步比较了MESA和3种OSB-EIL方法。如表1所示,OSB-EIL方法通常使用比基于欠采样的竞争对手(包括MESA)多得多(1-2×IR时间)的数据来训练每个基本学习器。因此,直接比较MESA和相同规模的过采样基线是不公平的。因此,我们绘制了关于集合训练中使用的实例数量的性能曲线,如图4所示。
可以观察到,我们的方法MESA始终优于基于过采样的方法,特别是在高度不平衡/高维任务(例如,具有617个特征的ISOLET,乳房摄影术。IR=42)。MESA具有较高的采样效率和较快的收敛速度。与基线相比,该方法只需少量的训练样本就能收敛到一个强集成分类器。MESA也有一个更稳定的训练过程。OSB-EIL方法通过分析和增强少数类数据的结构来执行重采样。当数据集很小或高度不平衡时,少数类通常代表不足,缺乏明确的结构。因此,在这种情况下,这些OSB-EIL方法的性能变得不稳定。
表4:元采样器的跨任务可转移性。

元采样器的跨任务可移植性。MESA的一个重要特点是跨任务可迁移性。由于元采样器是在任务不可知的元数据上训练的,因此它不受任务限制,并且可以直接应用于新任务。这为MESA提供了更好的可扩展性,因为可以在新任务中直接使用预训练的元采样器,从而大大降低了元训练成本。为了验证这一点,我们使用了乳腺X线摄影和人蛋白。作为两个较大且高度不平衡的元测试任务,然后考虑五个元训练任务,包括原始任务(基线)、原始训练集的50%/10%的两个子任务以及两个小任务光学数字和光谱仪。
表4报告了详细结果。可以看出,迁移后的元采样器在元测试任务上具有良好的泛化能力。按比例缩小元训练实例的数目对所获得的元采样器具有较小的影响,尤其是当原始任务具有足够数目的训练样本时(例如,对于人蛋白,当k=10/20时,将元训练集减少到10%子集仅导致-0.10%/-0.34% ∆)。此外,在小任务上训练的元采样器在新的、更大的甚至异构的任务上也表现出了令人满意的性能(上级其他基线),这验证了所提出的MESA框架的通用性。综合性跨任务/子任务可转移性测试和其他附加实验结果请参见A节。
5. Conclusion
我们提出了一种新的不平衡学习框架 MESA。它包含一个元采样器,自适应地选择训练数据,从不平衡数据中学习有效的级联集成分类器。MESA没有遵循随机试探法,而是直接优化其采样策略以获得更好的泛化性能。与流行的元学习 IL解决方案相比,MESA是一个通用的框架,能够与各种学习模型一起工作。我们的元采样器是在任务不可知的元数据上训练的,因此可以转移到新的任务,这大大降低了元训练成本。实验结果表明,MESA 在多种任务上取得了较好的性能,并具有较高的采样效率。在未来的工作中,我们计划探索元知识驱动的集成学习在长尾多分类问题中的潜力。
6. Statement of the Potential Broader Impact
本文研究了不平衡学习问题,这是机器学习和数据挖掘中的一个常见问题。这种问题广泛存在于许多现实世界的应用领域,如金融、安全、生物医学工程、工业制造和信息技术[15].IL方法,包括本文中提出的MESA框架,旨在修复由偏斜训练类分布引入的学习模型的偏差。我们相信正确使用这些技术将会把我们引向一个更美好的社会。例如,更好的IL技术可以检测钓鱼网站/欺诈交易以保护人们的财产,并帮助医生诊断罕见疾病/开发新药以挽救人们的生命。也就是说,我们也意识到不恰当地使用这些技术会导致负面影响,因为错误分类在大多数学习系统中是不可避免的。特别是,我们注意到在医疗相关领域部署IL系统时,错误分类(例如,未能识别患者)可能会导致医疗事故。在这样的领域中,这些技术应该作为辅助系统使用,例如,在执行诊断时,我们可以调整分类阈值以实现更高的召回率,并使用预测的概率作为医生诊断的参考。尽管IL研究存在一些风险,但正如我们上面提到的,我们相信通过正确的使用和监控,错误分类的负面影响可以被最小化,IL技
术可以帮助人们过上更好的生活。
A. Additional Result ## B. Implementation Details ## C. Discussion ## D. Visualization
论文总结
总结
本文提出了一个通用的 EIL框架MESA,它从数据中自动学习其策略,即元采样器,以优化不平衡分类。主要思想是建模一个元采样器,作为嵌入在迭代集成训练过程中的自适应欠采样解决方案。在每次迭代中,它将集成训练的当前状态(即,训练集和验证集上的分类误差分布)作为其输入。在此基础上,元采样器选择一个子集来训练一个新的基分类器,然后将其添加到集成中,从而获得一个新的状态。我们期望元采样器通过从这样的交互中学习来最大化最终的泛化性能。为此,我们使用强化学习(RL)来解决元采样器的不可微优化问题。
本文做出了以下贡献。(I)我们提出了 MESA,这是一个通用的EIL框架,它通过从数据中自动学习自适应欠采样策略来展示优越的性能。(II)对EIL系统中跨任务元信息的提取和使用进行了初步探索。这种元信息的使用赋予了元采样器跨任务的可移植性。经过预训练的元采样器可以直接应用于新的任务,从而大大降低元训练带来的计算成本。(III)与元学习者被设计为在训练期间与特定学习模型(即DNN)协同优化的流行方法不同,我们在 MESA中将模型训练和元训练过程解耦。这使得我们的框架通常适用于大多数统计和非统计学习模型(例如,决策树、朴素贝叶斯、k-最近邻分类器)。
启发
问题
强化学习
在强化学习里有两个基本的概念,Environment和Agent。
Environment指的是外部环境,在游戏中就是游戏的环境。
Agent指的是智能体,指的就是你写的算法,在游戏中就是玩家。
智能体通过一套策略输出一个行为(Action)作用到环境,环境则反馈状态值,也就是Observation,和奖励值Reward到智能体,同时环境会转移到下一个状态。如此不断循环,最终找到一个最优的策略,使得智能体可以尽可能多的获得来自环境的奖励。整个过程如下图所示:
