论文链接:
对于分词、命名实体识别等序列标注任务,现在已有的较好效果模型为bi-Lstm + CRF,但由于网络的递归特性导致在GPU并行性能上有一些问题(后一输入的特征学习依赖于前一输入)。本文使用CNN对序列标注问题提出一个在同样精度下,性能高于RNN的解决方案。(同一精度下14-20倍速,8倍速下精度高于RNN场景),这种替换方案在更大size的问题如音频生成模型上也有着相应的应用。
CNN与RNN在速度上的分别受制于网络深度及输入大小。在对于大的语料进行特征提取时要相应考虑增大网络深度的问题,而由此可能带来的调参问题在常用的CNN中一般是通过pooling来减少深度的,但这种方法难以适用于序列标注问题(在sentence方向进行消去语料单项位置信息或顺序信息的pooling是不合适的)。
本文提出的方法是Dilated Convolution

半径的一小段为有theta-1个“空洞”的Dilated Convolution,当theta > 1时相同参数设定下,后者比前者计算的range更大(这是指相对范围的,绝对范围是一样的)。卷积所能“覆盖”的range也称为“感受野”。对于单个卷积运算造成的空洞,通过平移运算,总会算入(所以在感觉上比poolling更少信息损失)。
相应叙述也可以参考链接:
https://blog.csdn.net/jiachen0212/article/details/78548667
故垛堞相似层数的DilatedConvolution,会较CNN有更强的“概括能力”,这种较强的概括性可能带来overfitting的风险。所以本文的做法为递归运用小的堆叠Dilated Convolution
模型结构:

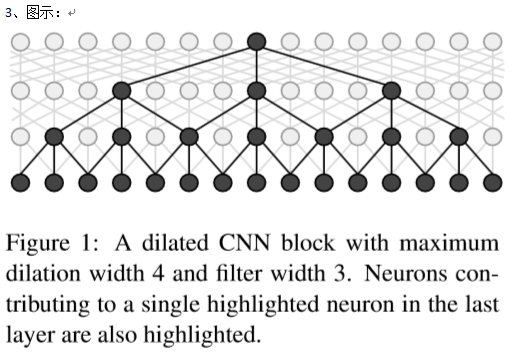
4、实现例子:
摘自:
https://github.com/crownpku/Information-Extraction-Chinese/tree/master/NER_IDCNN_CRF
def IDCNN_layer(self, model_inputs,
name=None):
"""
:param idcnn_inputs: [batch_size, num_steps, emb_size]
:return: [batch_size, num_steps, cnn_output_width]
"""
model_inputs = tf.expand_dims(model_inputs, 1)
reuse = False
if self.dropout == 1.0:
reuse = True
with tf.variable_scope("idcnn" if not name else name):
shape=[1, self.filter_width, self.embedding_dim,
self.num_filter]
print(shape)
filter_weights = tf.get_variable(
"idcnn_filter",
shape=[1, self.filter_width, self.embedding_dim,
self.num_filter],
initializer=self.initializer)
"""
shape of input = [batch, in_height, in_width, in_channels]
shape of filter = [filter_height, filter_width, in_channels, out_channels]
"""
layerInput = tf.nn.conv2d(model_inputs,
filter_weights,
strides=[1, 1, 1, 1],
padding="SAME",
name="init_layer")
finalOutFromLayers = []
totalWidthForLastDim = 0
for j in range(self.repeat_times):
for i in range(len(self.layers)):
dilation = self.layers[i]['dilation']
isLast = True if i == (len(self.layers) - 1) else False
with tf.variable_scope("atrous-conv-layer-%d" % i,
reuse=True
if (reuse or j > 0) else False):
w = tf.get_variable(
"filterW",
shape=[1, self.filter_width, self.num_filter,
self.num_filter],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable("filterB", shape=[self.num_filter])
conv = tf.nn.atrous_conv2d(layerInput,
w,
rate=dilation,
padding="SAME")
conv = tf.nn.bias_add(conv, b)
conv = tf.nn.relu(conv)
if isLast:
finalOutFromLayers.append(conv)
totalWidthForLastDim += self.num_filter
layerInput = conv
finalOut = tf.concat(axis=3, values=finalOutFromLayers)
keepProb = 1.0 if reuse else 0.5
finalOut = tf.nn.dropout(finalOut, keepProb)
finalOut = tf.squeeze(finalOut, [1])
finalOut = tf.reshape(finalOut, [-1, totalWidthForLastDim])
self.cnn_output_width = totalWidthForLastDim
return finalOut
tf.nn.atrous_conv2d中rate参数对应theta执行空洞size设定。,代码作者的dilation参数并不与论文中设定一致。