1 ,sort和Deepsort算法
在目标检测领域,sort(Simple Online and Realtime Tracking)算法和 DeepSORT(Deep Learning for Multi-Object Tracking)算法是两种常用的目标追踪算法,它们通常与目标检测器结合使用,用于在视频中跟踪和识别目标。
-
SORT算法: SORT 算法是一种简单高效的多目标跟踪算法,其主要思想是通过关联检测框和已知轨迹来进行目标追踪。SORT 算法首先利用目标检测器检测出目标,并根据检测框的位置、大小等信息建立轨迹和检测框之间的关联。接着,利用匈牙利算法对每帧的检测结果进行关联,然后根据关联结果更新轨迹信息。SORT 算法简单易懂,并且能够实现实时目标跟踪,但在处理遮挡、长时间不可见等复杂场景时表现可能较差。
-
DeepSORT算法: DeepSORT 算法是在 SORT 算法基础上加入深度学习模型进行目标特征提取和关联的改进版本。DeepSORT 使用卷积神经网络(CNN)从目标检测框中提取特征,然后利用这些特征信息进行目标的关联和轨迹更新。相较于 SORT,DeepSORT 在处理外观变化大、遮挡严重等复杂场景下具有更好的性能。
SORT 算法是一种简单而高效的多目标跟踪算法,适用于一般的目标跟踪任务
DeepSORT 算法则通过引入深度学习模型,能够更好地处理复杂场景下的目标追踪问题,提高了目标识别和跟踪的准确性和鲁棒性。
2,Deep sort算法的基本思想
如下图所示,设T1和T2是视频中连续的两帧图像, 如要在T2帧中跟踪T1中的红色框中的车辆,首先,在T2中进行车辆检测,检测到了三辆车,如黄色框所示;然后需要解决的问题是,要在T1中红色框和T2中黄色框之间建立关联,根据关联关系,确定T2中检测到的车哪辆是T1中的跟踪结果,并用该检测结果作为更新跟踪目标,进行后续T3时刻的跟踪。
在这类检测方法中,将视频理解成连续的图片,我们会发现,在视频中,车辆的位置是在连续变化的,如下图,如果我们持续将图中左侧汽车的检测框画出来,会发现红色框中的车辆一直在变化位置。

假设上图中的某一帧,因为光线影响或者图片质量为题造成红色小车在第315帧无法检测到,那么这一帧将会缺失检测框信息,但是会在320帧的时候重新被检测出来。
2.1,跟踪框与检测框
跟踪框:其实就相当与警察抓犯人,警察是跟踪框,犯人是检测框,警察去预测判断犯人的位置,从而去实现跟踪。
基本跟踪过程如下:
我们可以每帧知道检测框的位置
跟踪框会通过检测框当前帧的位置和运动状态,预测下一帧这辆车的位置
如果检测框与预测的跟踪框位置不同,要修正跟踪框的位置从而更好的对后面的跟踪框进行预测
然而我们要在这里理解的目标跟踪,并不完全等同于警匪片里的跟踪逃犯的概念,区别是:我们的警察追上了逃犯,他的任务就已经完成了;而跟踪框要尽量保证跟检测框位置的重合,从而更好的进行下一帧位置的预测。
检测框可以理解为是一个静态的概念,它主要针对单张图片找出明确车辆在其中的位置;跟踪框是一个动态的概念,关注的是连续视频流中图片之间汽车位置的关联
2.2 ,卡尔曼滤波算法—预测
卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
首先我们给出卡尔曼滤波解决问题的场景和目标:卡尔曼滤波可以应用于有多个不同的观测数据,每个数据有一定的可靠程度时,我们希望能够得出尽量贴近真实情况的数据。卡尔曼滤波的一个典型实例是从一组有限的,包含噪声的,对物体位置的观察序列(可能有偏差)预测出物体的位置的坐标及速度。
以车辆举例,我们的车辆前方有一个障碍物,为了使距离测定更准确,我们有一个距离传感器获得车辆到前方障碍物的距离。
1) 在T1时刻,距离传感器告诉我们车辆距离前面障碍物的距离是10m。同时我们可以知道车辆速度是4m/s。为了简化问题,我们假设这两个数值是绝对准确的。
2) 在T2时刻(T1之后1秒),距离传稿器告诉我们当前距离障碍物的距离是7m。同时,在T2时刻,如果考虑到T1时刻我们的速度是4m/s,经过1s后我们应该从距离障碍物10m变成6m(10-4)。
于是,我们在T2时刻得到了两个数据:距离传感器告诉我们的结果7m,和我们通过计算的结果6m。
理想状况下,这个问题并不复杂:我们直接用距离传感器的数值不是就最准确了吗?但是现实是,距离传感器随着距离远近的不同,它的精确度是可能发生变化的;如果只是相信速度传感器,我们在1秒内的速度又不是绝对一致的。所以单独采用两者的任何一个都不够准确。因此如果我们希望T2时刻的结果更准确,我们最好将距离传感器的数值跟速度计算的数值做一下加权平均(予以不同的权重以算均值)。
例如,我们认为距离传感器的数值更加准确一些,认为它在T2时刻的准确度应该是90%,速度估算的值不够准确,因此给予80%的可信度。那么最终估计的距离结果就是:
这就是卡尔曼算法的主要思路:它将两个都不是那么可靠的方式做了融合,从而可以有效抵抗噪点等外部影响,得到相对准确的预测值。以T1时刻的最优的估计X_T1 为准,预测T2时刻的状态变量X_T2. 同时又对该状态进行观测得到观测变量Z_T2 ,再在预测和观测之间进行分析,或者说是以观测量对预测量进行修正,从而得到T2时刻的最优状态估计。
卡尔曼滤波算法目前已经应用于NASA(美国航空航天局)的阿波罗计划等计划中,用于进行飞行器的轨道预测等作用。它还有更多更广泛的使用场景。也许你会在你未来的某些应用场景中想到它并进行应用
简单来说,卡尔曼滤波算法就是根据你检测框的位置去预测目标在下一帧的位置,他是线性的
2.3 匈牙利算法----匹配
通过不断寻找增广路径的办法,寻找最大匹配数量。这就是匈牙利算法的主要思路
其实跟贪心算法差不多
我们有三样在售的食品,分别是面包、三明治、方便面。现在同时来了三个不同的客人A、B、C。其中A喜欢面包和三明治,B只喜欢面包,C只喜欢三明治:
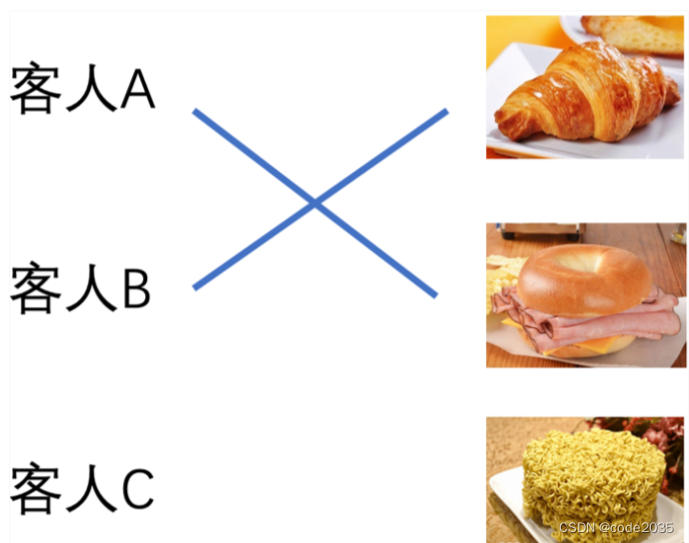
对于车辆跟踪来说,就是将检测框与跟踪框(卡尔曼滤波预测出来的跟踪框)他们匹配起来,找到最优(最佳)的匹配,从而实现跟踪。
3,工作流程
那么如何对多目标进行跟踪呢?
常见的跟踪策略就是track+detection
为什么选择与detection进行结合呢?
这是因为目标检测算法大多是基于多目标的
为什么不可以直接用detection进行多目标跟踪呢?
这是因为检测算法有时会出现漏检的情况. 在跟踪算法中一旦跟踪丢了目标就很难再继续跟踪下去了。 如果遇到漏检的情况,将失去身份ID。所以仅仅使用detection进行跟踪结果也并不理想。
检测算法主要关注在当前帧中准确地标识和定位目标,通常是静态图像或者视频的第一帧。
跟踪算法则会考虑上下文信息,通过对前一帧或多帧的目标位置和状态进行分析,以实现对目标的持续跟踪。
在跟踪算法中,利用了时间序列数据的连续性,以便更好地理解目标在不同帧之间的运动和变化。这种联系上下文信息的能力使得跟踪算法能够应对目标遮挡、姿态变化、光照变化等情况,从而实现对目标的鲁棒跟踪。
也就是说检测算法是针对当前帧的,而跟踪算法会联系上下两帧
3.1 重识别(ReID)问题
对于跟踪,算法并不知道自己跟踪的目标内容是什么,它只负责跟踪,具体是什么并不需要知道,那么就会出现重识别(ReID)的问题

紫色框表示上一帧的目标track,黑框表示当前帧检测到的四个目标,上一帧的目标(紫)跟检测出来的四个目标(黑)中哪一个是同一个目标呢?
这也是多目标跟踪要做的数据关联:上一时刻的目标,和当前时刻的目标,怎么匹配关联起来。实现策略有很多,思路就是训练一个网络使它最小化类内误差,最大化类间误差
3.2 身份变换(IDswitch)问题

白色框表示track,蓝色框表示detection;
图1中有四个ID:37,41,45,38。随着目标移动,ID41把ID38挡住(图4),detection检测不到ID38,而ID37如果刚好走到ID38原来的位置附近(从图片可以看出来,37走向和38走向是相对的,38被从右侧走到了左侧途中经过了遮挡,37从左侧走到了右侧可能也发生了遮挡),检测器可能会把37识别成38,把后继帧出现的38识别成37,从而导致身份变换。也就是说如何在目标交叉的过程中保证身份不会发生变化呢?
3.3 由上述两个问题引出我们的Deepsort算法
在DeepSORT提出之前是SORT算法(SORT论文链接),但是它对身份变换的问题,仅仅采取框和框之间距离的匹配方式,没有考虑框内的内容,所以容易发生身份变换,不过这个问题已经在2017年的论文中进行了解决,即DeepSORT。
首先来看一下DeepSORT的核心流程:
预测(track)——>观测(detection+数据关联)——>更新
预测:预测下一帧的目标的bbox,即后文中的tracks
观测:对当前帧进行目标检测,仅仅检测出目标并不能与上一帧的目标对应起来,所以还要进行数据关联
更新:预测Bbox和检测Bbox都会有误差,所以进行更新,更新后的跟踪结果通常比单纯预测或者单纯检测的误差小很多。

如图所示:
在T1时刻track预测到一个行人的轨迹(图1紫框)后;
T2时刻detection对图中物体进行检测,检测出了四个目标(图2黑框),通过数据关联,将代表ID1的物体跟踪的BBOX(图2紫框,其实就对应图1track的紫框)与对应的检测BBOX(图2黑框)关联;
同样还是T2时刻,确定关联关系后,更新track预测的结果,用物体检测的Bbox来代表T2时刻物体追踪的Bbox。(这里不太清楚是detection直接代替track的Bbox,还是融合了track与detection的结果)
3.4 DeepSORT流程
下面来看一下Deep SORT的大体流程:
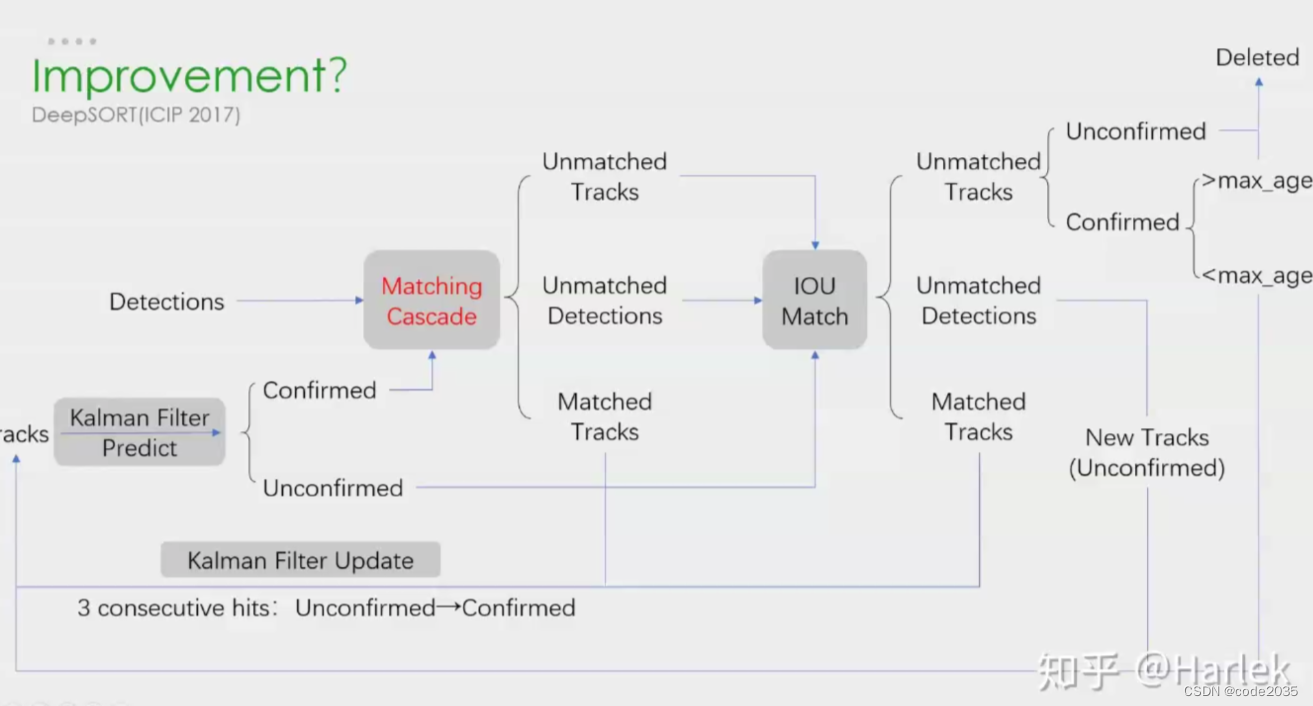
下面来逐步看一下DeepSORT到底是如何工作的吧。
1.首先是核心流程:绿框部分。
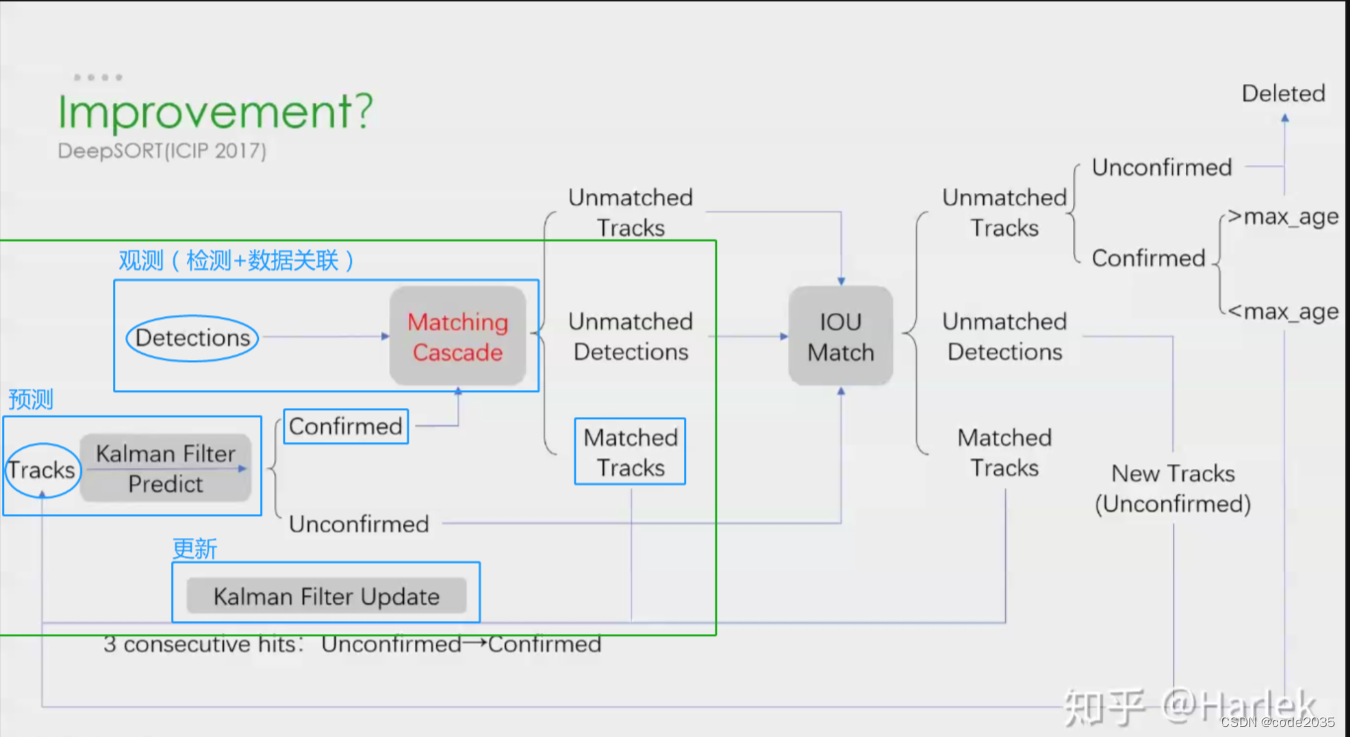
1)从预测(Tracks)开始,由于每一时刻的track Bbox组在一起就相当于构成一组轨迹,所以写的是复数tracks,并且后文都会称跟踪的Bbox为轨迹;
2)经过kalman滤波预测后,会对当前帧预测一个轨迹Bbox,先不看unconfirmed,假如预测出的是confirmed(对于confirmed和unconfirmed,是用来区别跟踪的目标是不是一个东西,比如一个杂七杂八的背景那就是unconfirmed,真真切切的人或者车就是confirmed);
3)对当前帧进行detection,然后将detection Bboxs结果和预测的confirmed track Bbox进行数据关联(matched tracks);
4)匹配完成后,更新跟踪的bbox(卡尔曼滤波预测的Bbox)。这里要注意,更新和匹配不是在时刻上顺延的(不是T2时刻匹配,T3时刻更新的关系),而是在下一帧时刻需要完成的两项流程(T2时刻匹配,继续在T2时刻更新)。
5)更新后,对当前帧预测,下一帧观测,并更新;再预测,下一帧观测,更新…………
上面只讨论了跟踪目标是真实存在的物体且匹配成功的情况下的流程,显然匹配过程中不可能所有都实现一对一的匹配,肯定有的track是匹配不上detection的,也有detection匹配不到track的,那么如何处理呢?
2.匹配失败的第一种情况,那就是对于匹配不上的tracks和detection再次进行匹配,会出现两种情况,一个是匹配成功了,一个是依然还有部分匹配不到,先来看再次匹配能匹配成功的情况,流程如下: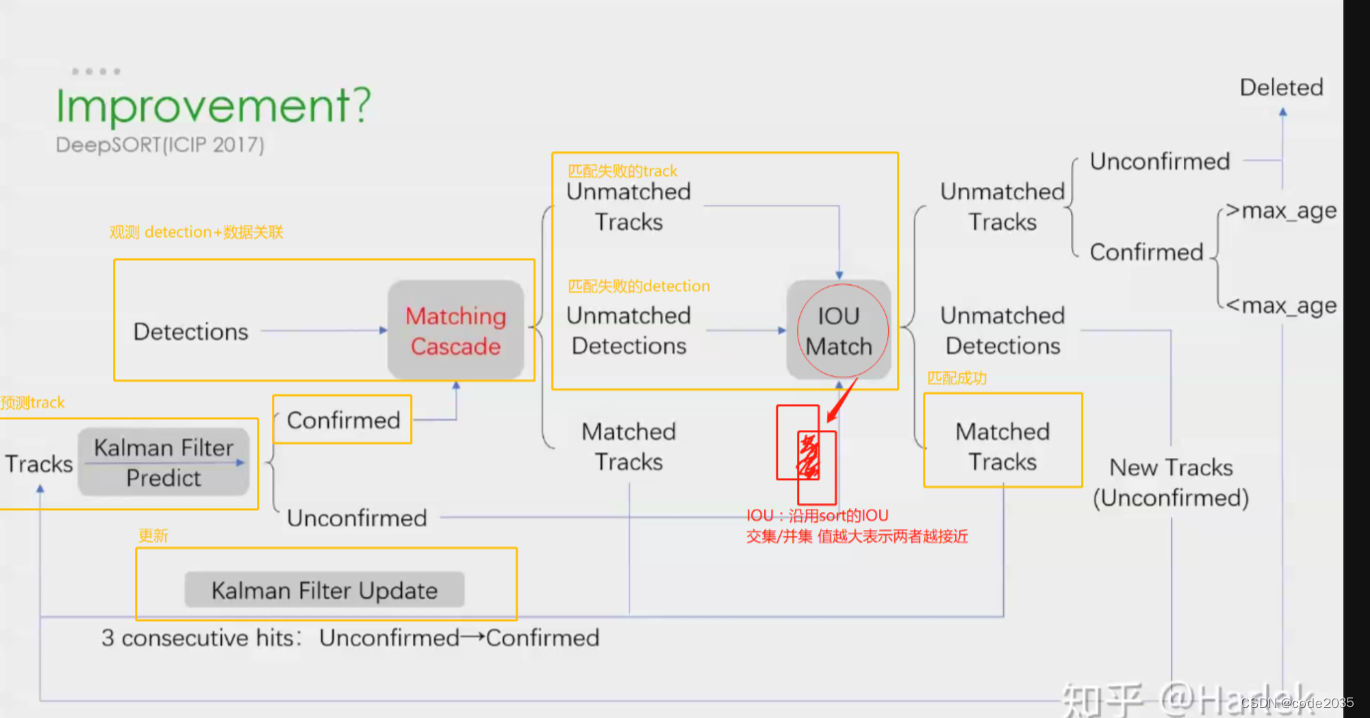
依然从预测的tracks开始,经过卡尔曼滤波预测,与detection匹配
1)发现此时的tracks匹配失败,为什么会有tracks匹配失败的情况呢?
检测可能发生了漏检,某时刻,预测的轨迹tracks还在,但是检测器没有检测到与之对应的目标。
2)为什么会有detection匹配失败的情况呢?
可能某一时刻有一个物体是新进入的镜头(比如,之前一直只有三个物体,某时刻突然镜头中出现了第四个新物体),就会发生detection匹配不到tracks的情况,因为这个物体是新来的,在这之前并没有它的轨迹用于预测;还有一种情况就是物体长时间被遮挡,导致检测到的物体没有可以与之匹配的轨迹。
针对上述匹配失败问题,处理方法就是对匹配失败的tracks和匹配失败的detection进行IOU匹配。如果能匹配成功,则再进行更新,然后继续进行预测–观测–更新的追踪流程。
3.再次匹配也匹配不成功的怎么办呢?如下图: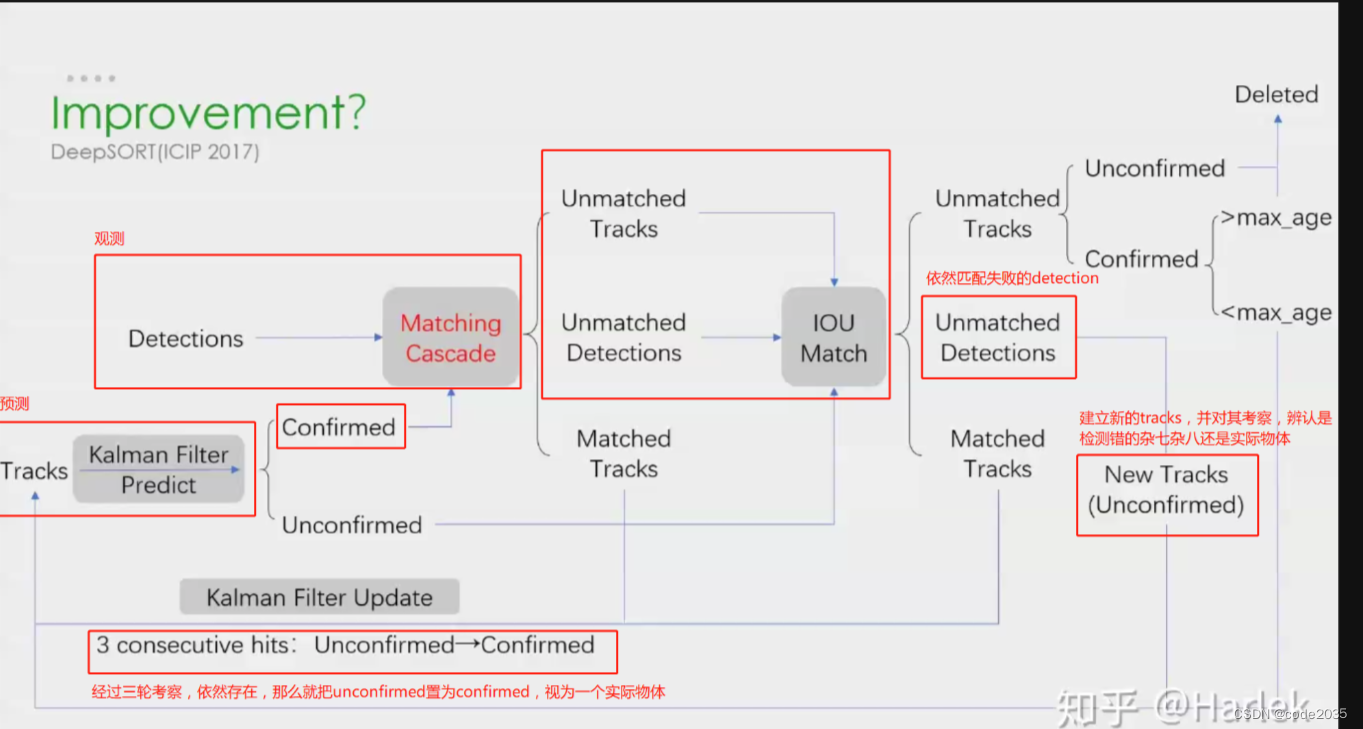
对于再次匹配依然失败的detections,前面讨论过detections匹配失败的原因可能是新出现的目标在之前没有它的轨迹tracks,或者长时遮挡的也没有轨迹tracks,所以对其建立一个new tracks,前面也提到,tracks都会设置confirmed/unconfirmed,对于新建立的tracks,尚未确定是否就是真切存在的,万一是检测错的杂七杂八呢,所以将其设置为unconfirmed,并对其进行三次考察,如果是实际目标修改为confirmed,再进行 预测-观测-更新
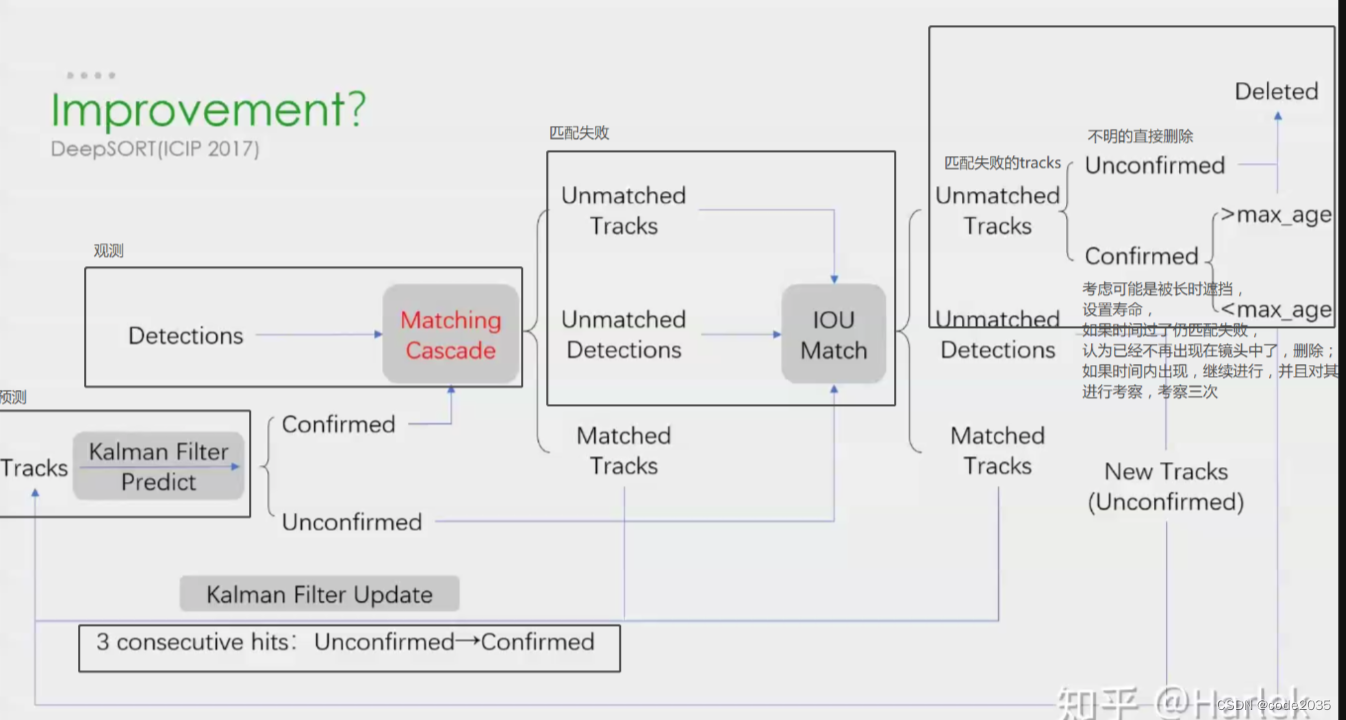
对于再次匹配依然失败的tracks,前面讨论过可能是检测器漏检了目标,此时看其是否是confirmed,如果是unconfirmed,将其删除;反之,为其设置寿命,在寿命时间之内都没发生变化(>max_age)则将其delete,认为其已移出镜头;如果寿命之内(<max_age),同样对其进行三次考察,是否是跟踪的杂七杂八,再进行 预测-观测-更新
参考文献:
1,DeepSORT(工作流程):https://blog.csdn.net/weixin_41761357/article/details/107360483