主页:元存_CSDN博客
个人辛苦整理,禁止转载。
本文基于 AI 解读。
论文原文:
Do, Jaeyoung et al. "Improving CPU I/O Performance via SSD Controller FTL Support for Batched Writes", Data Management on New Hardware (2019): 2:1-2:8.
内容摘要
本文描述了一种新的开放通道硬盘驱动系统,该系统支持多页I/O,而无需依赖于host的标记结构化存储。这大大简化了服务器系统,并提高了性能。我们提出了一个带有多个单词对齐的硬盘驱动系统,其中每个单词只改变当前堆栈的一小部分。
INTRODUCTION
1.Data Management
1. 随着主内存尺寸的增加和成本的下降,越来越多数据被保留在主内存中,减少了访问数据所需的 I/O 次数。
2. 虽然主内存中保留了所有数据,但是当需要再次访问数据时,I/O 操作仍然需要进行,因为二级存储的成本远低于主存储。
3. 减少存储成本的代价是当需要再次进行I/O操作时,执行成本会增加。这个I/O操作可能会对性能产生重大影响,从而影响到执行成本。
4. 在数据库领域,主内存系统通过将所有数据留在主内存中来避免数据访问 I/O,从而产生出色的性能。
5. 然而,那些暂时将数据缓存在主内存中并选择性地将数据从主存储器移动到二级存储器的系统具有较低的成本。
6. 技术挑战是提供良好的性能和低成本。
7. 使用日志结构化的方法直接提高I/O性能,例如在Deuteronomy中所做,这会减少将大量页面批量写入单个I/O的数量。
8. 然而,这需要实现日志结构化重映射、垃圾收集和恢复,这不是一项简单的任务。
9. 此外,执行开销,尤其是垃圾收集和恢复,会负面影响性能,从而降低日志结构化的优势。
10. 在这种情况下,SSD 闪存驱动程序已经在它们的控制器中支持了日志结构化,因此重复了 CPU 功能。
11. 遗憾的是,SSD 支持按块传输的接口,而主机无法从批量写入的块中受益。
12. 开放通道 SSD(OCSSDs)期望提供 FTL 功能。因此,我们可以将它们控制器的功能定制为提供所需的 FTL 界面和功能。
13. 存储器系统的本质是固定大小的逻辑页面(LPAGEs),可以通过逻辑页面标识符(LPIDs)进行识别。
14. 需要写入的 LPAGEs 放入大型缓冲区(大小为 256 到 512 个块)。
15. 发出整个缓冲区的I/O指令,包括一个描述符DESC,该描述符标识了包含在其中的LPAGEs。
16. 新的接口如图 1 所示,消除了基于 host 的日志结构化需求。
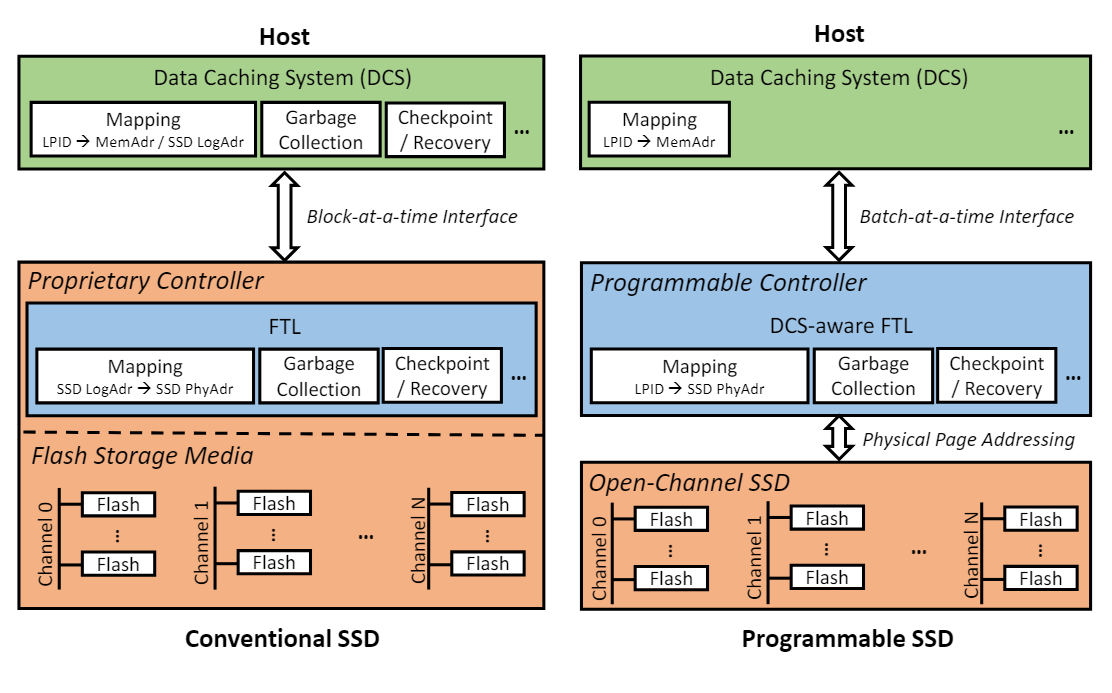
图1:左:使用传统SSD构建的基于主机的日志结构。
右:主机批量I/O接口到日志结构内置于开放通道SSD中。
17. I/O 接口与通常的存储接口相同,除了将可能无关的“LPAGE”批量写入一个 I/O 的序列。
18. 当前的 SSD(例如 HDD)仅处理一个块。
19. 有了这种新接口,主机就不需要在大内存中维护完整的映射表,正如在 LLAMA 中所做。
20. 只有缓存的 LPAGE 需要映射到它们的主内存位置,这是通常的要求。
21. LPAGE 不在主内存中时,无需主机映射。
22. 批量消除了I/O路径执行的成本,简化了并大多取代了Deuteronomy的LLAMA I/O接口,同时提高了性能。
23. 重要的是,主机无需实现日志结构化的存储。这是由 Open Channel SSD 控制器中的 FTL 完成的。
第 2 部分 Background
描述了软件和硬件基础技术。
这包括日志结构化存储、SSD 技术、Open 通道 SSDs 和我们的控制器。
2.1 Flash Solid State Drives (SSDs)
1. 主要 SSD 组件有两个:控制器和闪存存储介质。
2. 控制器专有固件,通常作为系统级芯片(SoC)实现,用于有效管理底层存储介质。
3. NAND 闪存构建的 SSD 必须在使用数据写入之前擦除,且内存只能承受有限数量的擦除次数,因此需要日志结构化来支持 Flash Translation Layer(FTL)将逻辑地址映射到物理闪存地址,并需要垃圾回收和磨损均衡来延长 SSD 寿命。
4. 存储介质是多个闪存通道的非易失性存储阵列。
5. 闪存通道用于 SSD 控制器和部分闪存芯片之间的通信,而芯片由多个块组成,每个块都包含多个页面。
6. 擦除的单位是块,读写操作在页面级别完成。
7. 为从闪存存储介质中获得更高的I/O性能,通常使用通道和芯片级别并行技术。
8. In-SSD 处理:现代 SSD 将处理和存储组件用于常规任务。这些计算资源为在 SSD 中运行用户定义程序提供了机会,多个 In-SSD 编程模型提供了巨大的功能性灵活性。
9. 例如,新兴的商业和科学研究 SSD 控制器包括具有内置硬件加速器以卸载处理密集型任务的通用型、多 GHz 时钟速度、多核处理器,以及多个千兆字节 DRAM 和 十几个底层存储介质通道,允许内部数据吞吐量达到 GB/s。
10. 在编程 SSD 时,利用现有工具、库和专业知识,而不是花费长时间学习低级、嵌入式开发过程,这是有利的。
11. SSD 在数据中心中的广泛应用,是因为它们支持与传统硬盘(HDDs)相同的块级接口。但这也导致了存储利用率不佳和性能下降 [13,17,25]。
12. 为解决这个问题,需要将 SSD 的内部存储介质分布和并行性暴露给主机,以便根据用户需求更好地控制数据放置和 I/O 调度 [10,14]。
13. 行业的一部分正在朝着这个方向发展:例如,Open-Channel SSDs [1,29] 引入了一种新的 I/O 接口,使得主机可以访问物理闪存页,而传统块设备抽象不能实现。
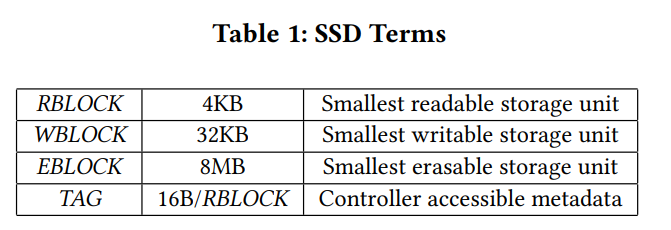
14. 我们将经常提到 SSD 的硬件元素。表 1 提供了我们将要使用的术语。
15. Log-structured file systems (LFS) [30] 被引入,以利用硬盘的高顺序性能。LFS 首先在大型主内存缓冲区中批量随机更新,然后将整个缓冲区顺序写入硬盘。
3. MULTI-PAGE WRITES
3.1 Batching I/Os
重点 1:日志结构化替换了多个写入 I/O 操作,使用单个包含 LPAGEs 的大型缓冲区。
重点 2:批量处理页面可以共享大量 I/O 路径到辅助存储设备。
重点 3:日志结构化缓冲区中的 LPAGEs 是有序的,即页面的更新顺序与缓冲区中的 LPAGEs 相同,在缓冲区之间也相同。
重点 4:读取必须暴露 SSD 状态,以反映写入顺序。
重点 5:与写入批次相关的读取在写入批次的开始之前不会看到批次的更新。
重点 6:与写入批次相关的读取在写入批次被确认之后会看到批次中的所有更新。
重点 7:与写入批次相关的读取在写入批次发出和确认之间会看到批次的有序前缀。
重点 8:与写入批次相关的读取但晚于早期确认的读取 A,会看到批次的有序前缀,其中前缀包括读取 A 看到的前缀。
重点 9:所有写入批次的写入操作最终都会出现在 SSD 的数据态中,或者不会出现在数据态中。
重点 10:基于主机的日志结构化需要数据管理系统(如 Deuteronomy)为每个逻辑页面(LPAGE)分配一个“物理地址”。
重点 11:主机将 LPID 映射到 SSD 地址,SSD 仅知道这种映射,而不了解主机映射的细节。
重点 12:这些映射关系在图 2 中示出。因此,当 SSD 进行垃圾回收时,它只需删除大块。
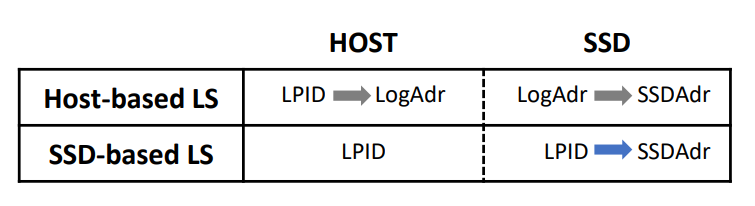
图 2 The double mapping of host logical pages with their LPIDs to SSD physical storage locations. Host-based LS and SSD-based LS denote host-based log structuring and our SSD controller based log structuring, respectively.
重点 13:主机必须对存储在数据垃圾收集中的 LPAGE 级更改页面进行更细粒度的处理。这需要主机从主内存中读取之前写入的缓冲区,以重新定位仍然有效的 LPAGE。
重点 14:基于主机的存储管理必须提供持久性。不仅页面中的数据必须具有持久性,主机还必须在写入的最后一个确认写入后持久地维护 LPID 与物理位置之间的映射关系。
重点 15:Deuteronomy 使用重做恢复与定期检查点来确保持久性。
重点 16:基于 SSD 控制器的日志结构化可以接受大型多页缓冲区。与主机系统不同,每个缓冲区中的 LPAGEs 通过存储在缓冲区头部的元数据(DESC)进行描述。DESC 表示缓冲区中存在的逻辑块及其在缓冲区中的偏移量(可以通过使用固定大小的 LPAGE 来计算偏移量),该顺序反映缓冲区中写入顺序的 blocks。
重点 17:SSD 控制器维护一个表格(MAP),将 LPAGE 映射到它们在物理 SSD 位置(通常称为闪存翻译层或 FTL)中写入的物理位置。
重点 18:SSD 现在负责:
- 根据检测到相同 LPAGE 的早期写入是否被后续写入写入的相同 LPAGE 的覆盖来执行垃圾收集。
- 由于 MAP(这是系统中的主要可恢复元素)在它的管理下,所以它负责恢复。
4. DURABILITY AND RECOVERY
4.1 Log Structuring Crash Recovery
1. SSD 的日志结构存储必须确保在系统崩溃前包括最后一个已确认的缓冲区写入之前的 MAP 和 LPAGE 状态的持久性。这种恢复对于传统的就地更新存储系统是不必要的。
2. MAP 可以被视为 SSD“数据库”的一部分。每个更新 LPID 都会更新其 MAP 条目的新物理闪存地址。虽然由主机写入的 LPAGE 是更新的来源,但可恢复的更新是 MAP 条目的更改。当然,SSD 本身提供持久性。写入到 flash WBLOCK 的内容是持久的。如果写入失败,可以通过尝试读取它来确定 WBLOCK 状态。
3. RBLOCK 每个都有 TAG 字段,其中我们存储与该 RBLOCK 相关的 LPID 以及更新日志序列号。这使得通过读取整个 SSD 上的 TAG 来恢复成为可能。但我们希望恢复速度更快。因此,我们使用数据库式恢复。数据库恢复利用写前日志(WAL)来确保在将更新写入数据库之前它们在日志中是稳定的。如果发生故障,将重放日志从检查点状态恢复当前数据库状态。日志长度由周期性检查点控制,从而允许控制恢复时间。因此,如果 SSD 控制器崩溃,我们重放 SSD“日志”以恢复 MAP,使用 LPAGE 物理位置作为更新后的 MAP LPID 条目。
4.2.1 更新协议。
我们的恢复日志是从每个批量中写入缓冲区的 DESC 块中提取的。DESC 将 LPID 与缓冲区块关联。SSD 将 LPID 与存储其数据的物理闪存地址关联。这在图 4 中进行了说明。
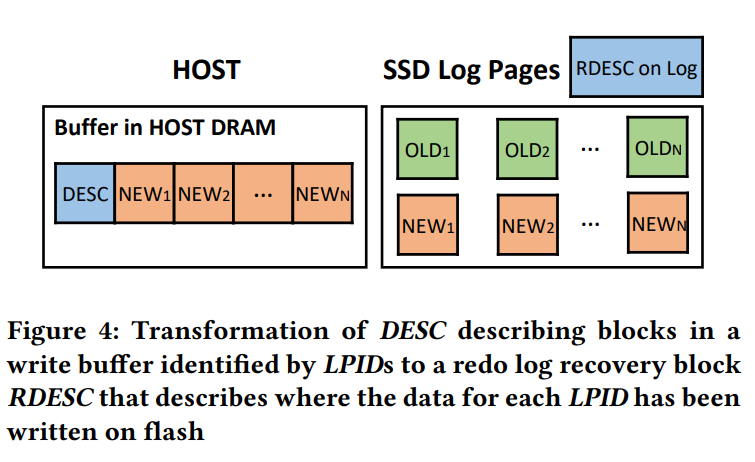
DESC 中的映射元数据用于创建(RDESC),它写入 SSD 恢复日志之前,在指定闪存地址之前。RDESC 的写入顺序与写入缓冲区的顺序相同。我们因在 WAL 协议中发布 RDESC 而产生延迟,因为我们必须等待此日志写入确认。RDESC 不会启用重做 LPAGE 写入,因为它不包含 LPAGE 数据。恢复只允许我们恢复 MAP。它假设已经成功地将 LPAGE 写入到 RDESC 指定的闪存位置。RDESC 信息允许我们通过读取它们来测试闪存位置,以确定它们是否已被成功写入。我们使用多个线程和闪存通道并行写入 LPAGE 的 RDESC 指定的闪存地址。这是使 LPAGE 持久化并利用并行性实现低延迟的最大的步骤。我们使用单个线程以保证第三部分的语义。在崩溃恢复中,我们使用相同的技术来更新 MAP。
故障。如果发生 LPAGE 写入错误,我们需要将其写入另一个位置,在更新 MAP 之前。我们还需要将 LPAGE 写入原始 RDESC 指示的位置的日志。我们使用修正日志记录 RDESC A 来提供写入失败的新的块位置。RDESC A 按与 RDESC 相同的方式组织,但只包含写入失败的 LPID 的条目。RDESC A 也在写入到 flash 的数据块之前, 写入到日志中。
5. SSD GARBAGE COLLECTION
5.1 Erase Block Based Garbage Collection
1. Flash 存储器不支持就地更新,但在重写前需要对 8MB 的擦除块(EBLOCK)执行擦除操作。这就是为什么 SSD 使用日志结构来管理 FTL 的原因。
2. 由于日志结构,旧版本会“挂起”直到垃圾回收。
3. 要利用 SSD 控制器的并行性,将主机写缓冲区的页面写入多个 EBLOCK。
4. 但是,EBLOCK 是擦除单位,因此我们需要确定每个 EBLOCK 中哪些 RBLOCK 已经被后续的 LPage 更新(复写)所覆盖。(编者注: 被复写的 RBlock 空间就无效了)。
5. 需要垃圾回收(GC)来重新回收这些存储空间。
6. 每个旧的 EBLOCK 中的 RBLOCK, 可以被重写到另外一个 EBLOCK(新的 Eblock, 使用前要擦除),因此它是可写的。
7. 当一个块中所有旧的 RBLOCK 都被“重写”后,旧块可以被擦除并重新使用。
8. 我们需要在跟踪哪些EBLOCK 中 RBLOCKS 是垃圾,哪些不是;在 EBLOCK 中哪些逻辑页面更新了, 需要将其 RBLOCK 重新定位到另一个 EBLOCK 中,并更新其映射条目。
9. 我们维护一个全局位向量 GBITV,以识别哪些 RBLOCK 是垃圾,哪些不是。
10. GBITV 与 EBLOCK 相关的部分也告诉我们 EBLOCK 存储中有多少垃圾。
11. 我们按可用的垃圾量(从大到小)顺序安排 EBLOCKS 进行垃圾收集。
12. 通过重写仍然有效的 RBLOCK 和其相关的 TAG 字段,GC 可以读取每个仍然有效的 RBLOCK 和其关联的 TAG 字段。
13. TAG 告诉我们 RBLOCK 映射条目的 LPID。
14. GC 将这个映射条目更新到新 EBLOCK 中。
15. 这种方法利用了 TAG 元数据,该元数据对主机不可见,可以在控制器 DRAM 中清理 EBLOCK,而无需读取整个 EBLOCK。
16. 我们实现了一个简单的方案,用于将热数据与冷数据分开,该技术可以提高日志结构文件系统的垃圾收集效率 [30](即减少每个 RBLOCK 需要重写的存储空间)。
17. 这减少了冷数据的重新写入,并将大多数垃圾收集集中于当前(假设为热)数据。
18. GC行为 和 主机写入行为, 使用不同的 EBLOCK 来重写 RBLOCK 的 EBLOCK。
19. 此外,第 4.3 节描述了恢复日志为 RDESC 的链接列表。但 RDESCS 的大小约等于 RBLOCK,而不是 WBLOCK。
20. 我们填充包含 RDESC 的 WBLOCK 中的数据页面。
21. 填充 WBLOCK 中的 RDESC 可以充分利用每个 WBLOCK 中的空间,同时保持 WAL 协议的低延迟。
22. 但是,如果垃圾回收器选择回收包含日志页面的 EBLOCK,我们的垃圾收集器就会出现问题。
23. 我们没有简单的方法将日志页面重定位,同时保持其链接列表。
24. 相反,我们标记 EBLOCK 为不受垃圾回收影响的区域,直到检查点截断恢复日志中 EBLOCK 的部分。
SSD CHECKPOINTING
1. Checkpoints truncate the part of the recovery log used to restore SSD state after a crash.
2. Apply redo log records that follow the latest checkpoint to the latest completed checkpoint.
3. End of log is detected when the next pointers in the recovery log point only to erased blocks.
4. Use a fuzzy incremental checkpoint to truncate the recovery log.
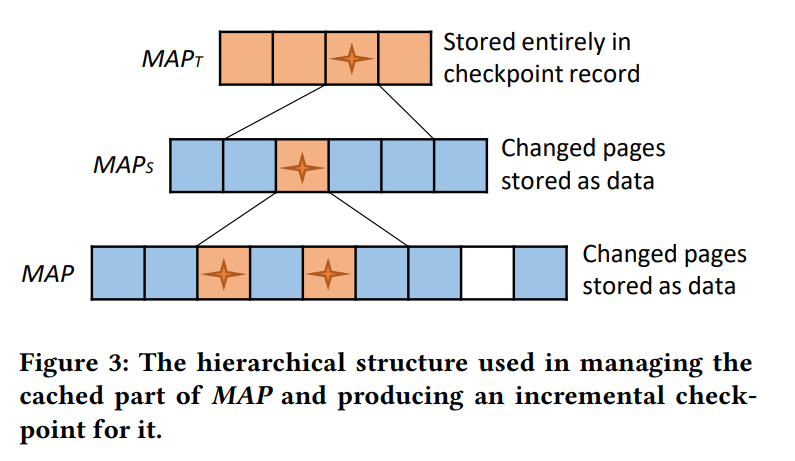
5. Checkpoint is fuzzy when it captures the state over some time interval and uses redo recovery to make the state precise as of the end of the interval.
6. Checkpoint is incremental when it only captures the part of the state that has changed since a prior checkpoint and merges that with the unchanged part.
7. Capture the state of the MAP, GBITV, and WEAR incrementally.
8. Save these states by treating their pages the same way we handle data updates.
9. Accumulate enough state to properly utilize each recovery log WBLOCK.
10. Complete the checkpoint by writing the checkpoint record in a \"well-known location.\"
11. MAP updates are produced whenever a data block is written to flash storage.
12. The update permits MAP to track the most recent state of any page on the SSD.
13. Such an update marks its MAP page as \"dirty\" in its MAP S entry, meaning the cached version is an update to the version of the MAP page stored durably in flash memory.
14. At some point, the checkpoint process needs to make the updated (dirty) MAP page itself durable.
15. When this happens, the page in MAP S that references this part of MAP is also marked as dirty and will need to be made durable.
16. Introduce an additional level for the mapping information called MAP T (T for tiny) table to avoid writing all of MAP S to flash during a checkpoint.
17. MAP T has 16 byte entries referencing the pages of MAP S and is 64KB in size.
18. It uses the first 12 bits of an LPID to identify a page in MAP S.
19. When persistent MAP S pages that have changed, update entries are written in MAP T.
20. MAP T is not on the access path to data blocks.
21. Accesses all start at MAP S.
22. The final checkpoint step is to include MAP T in its entirety as part of the checkpoint state in a \"well-known\" location.
23. Garbage is tracked using a bit vector per flash block, with the cumulative size of the bit vectors (GBTV) being 64MB.
24. A smaller table that tracks the updated pages of GBITV is called GBITV S and is 128KB.
25. GBITV S's size is not small enough to conveniently store entirely in the checkpoint record, so a tiny table GBITV T is introduced as we did with MAP T for mapping data.
26. GBITV T is stored in its entirety in the checkpoint record.
Preliminary Results
1. YCSB(Y Combinator Store Bw-tree)的总体吞吐量
2. Bw-tree key-value store 运行在(1)传统(Conv)和(2)可编程(Prog)SSDs 上,使用单个主机核心
3. 主机 DRAM 缓存大小在数据库大小的百分比范围内进行变化(图 6)
4. 对于每个 SSD 配置,我们测量了性能,包括启用了(持久性)和禁用了(非持久性)GC 和检查点
5. 在非持久性实验中,Conv 比 Prog 具有略微更好的性能
6. 当请求一个未缓存的页面时,Bw-tree 需要首先找到 SSD 中存储页面的位置,这是在主机上(Conv)或在 SSD(Prog)上执行的
7. 与写入I/O不同,Bw-tree总是以单页的方式读取,因此Prog中使用的较弱的处理器引入了比Conv更长的读取延迟
8. 在“持久性”配置中,Prog(持久性)比 Conv(持久性)快 1.91 倍 -2.49 倍
9. 在这个配置中,Conv(持久性)的吞吐量受到其需要在同一主机核心上运行检查点和 GC 的限制。相比之下,Prog(持久性)将这些过程卸载到 SSD 控制器上,使主机周期能够专门用于处理基准操作。
RELATED WORK
8.1 Programmable SSDs
重点:
1. 现代 SSD 包含计算组件(如嵌入式处理器和 DRAM),用于执行各种 SSD 管理任务,为在 SSD 中运行自定义程序提供了有趣的机遇。
2. 可编程 SSD 的概念在 [9] 中进行了概述。
3. 业界对利用可编程 SSD 的兴趣日益浓厚,因此该领域的研究可能会带来高额回报。
4. Do et al.是第一个在数据库查询处理上下文中发现此类机会的研究者。他们修改了一个商业数据库系统,将选择和聚合运算符推下到 SAS 闪存 SSD。
5. Jo et al.扩展了 MySQL,通过将数据扫描卸载到 NVMe SSD 上执行数据早期过滤。
6. 他们开创了使用闪存 SSD 开放成本效益处理数据的有创意方法,但他们的方法主要受 SSD 的硬件和软件方面的限制。
7. 原型 SSD 中的嵌入式处理器时钟频率较低,不足以运行各种自定义程序。
8. 软件开发环境使开发和分析非常具有挑战性,阻止了对存储器处理机会的全面探索。
9. 最近,研究人员研究了更好的可编程 SSD 的编程模型。在 [32] 中,Seshadri 等人提出了 Willow,一种基于 PCIe 的通用 RPC 机制,允许开发人员轻松地扩展 SSD 语义并添加自定义函数。
10. Gu 等人研究了基于流派的编程模型,其中 SSD 中的应用程序可以使用任务和数据管道动态构建。
11. 这些编程模型提供了极大的可编程性,但仍然远远不是真正的通用编程。
12. 现有大型应用程序可能需要根据模型的能力进行大量重设计。
13. Deuteronomy 架构 [23] 通过提供 TC 与数据管理组件(DC)之间的清晰分离,支持高效的 ACID 事务。
14. 该架构将数据库存储引擎内核的功能划分为 TC 和 DC。
15. TC 提供并发控制和恢复功能,DC 处理数据存储和管理职责(例如访问方法,缓存)。
16. 每个 Deuteronomy 组件都在现代硬件上实现,以实现 Bw-tree(即非锁定访问方法 [22])和 LLAMA(即非锁定、日志结构化缓存和存储器管理器 [21]。
17. 这两者的组合形成了一个键值存储,该存储在几个微软产品中得到应用,包括 SQL Server Hekaton[6] 和 Azure Cosmos DB [26]。
18. 相比之下,我们的工作利用了最先进的可编程 SSD,提供了强大的处理能力、丰富的内 SSD 计算资源以及一个通用的操作系统,允许轻松编程和调试。
CONCLUSION
我们的重点是利用新的SSD控制器功能来解决I/O问题。首先,Gray等人[11]提出了5分钟规则来强调这个问题。我们的DaMoN论文[24]展示了在数据缓存系统中提供数据管理时,执行I/O路径的高成本所带来的不愉快的性能影响。在存储层次结构中移动数据在低成本和高速存储之间是实现高性能存储的关键。冷数据需要低成本存储,而热数据需要高速存储。在存储层之间移动可以实现最佳成本/性能的数据存储,而无需缓存的存储往往太频繁地牺牲成本或性能。我们使用可编程的SSD控制器来实现一个存储接口,利用分页I/O来使I/O成本平均化到多个页面。这与日志结构技术相似。但是,将此功能放入存储控制器中,我们从主机系统卸载了日志结构开销。这将消除冗余功能,并提高由此产生的I/O接口的成本性能。
参考
免责声明:
本文根据公开信息整理,旨在学习交流,所载文章仅为作者观点,不构成投资或商用建议。本文禁止商用。若有疑问或有侵权行为请联系作者处理。