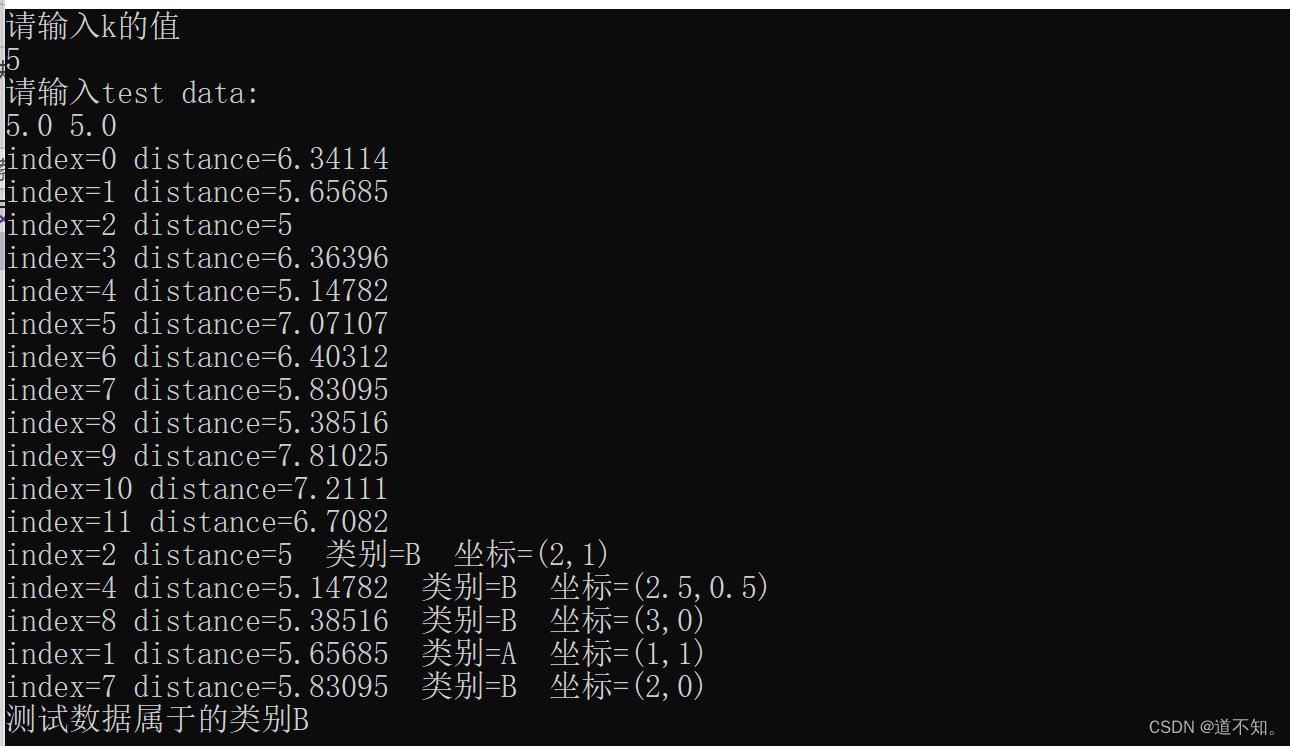
来源【机器学习实战之一】:C++实现K-近邻算法KNN_两个图像的特征向量应用knn模型进行匹配-CSDN博客
k-近邻(kNN, k-NearestNeighbor)是在训练集中选取离输入的数据点最近的k个邻居,根据这个k个邻居中出现次数最多的类别(最大表决规则),作为该数据点的类别。
//计算每个训练数据到待分类元组的距离,取和待分类元组距离最近的k个训练数据,k个数据中哪个类别的训练数据占多数,则待分类元组就属于哪个类别。
#include<iostream>
#include<map>
#include<vector>
#include<stdio.h>
#include<cmath>
#include<cstdlib>
#include<algorithm>
#include<fstream>
#include <filesystem>
using namespace std;
const int col = 2;
const int row = 12;
typedef double TData;
typedef char tData;
//typedef pair<int, double> Pari;
ifstream fin; //输入文件流,可以用于从文件中读取数据。通过构造函数或 open() 成员函数打开指定的文件,然后使用输入运算符( >> )和其他输入操作从文件中读取数据:
ofstream fout;
class KNN
{
private:
int k;
TData TSet[row][col]; //训练数据
TData Test[col]; //测试数据
tData labels[row]; //类别
map<int, double> dis_index;
map<tData,int> label_count;
public:
KNN(int k);
double distance(TData* t1, TData* t2);
void All_distance();
void get_label();
struct cmp
{
//调用运算符 operator() 的重载使得对象可以像函数一样使用,具有类似函数的行为,因此也称为函数对象。
bool operator()(const pair<int,double>& a, const pair<int,double>& b) //常量引用类型 const T&
{
return a.second < b.second;
}
};
};
KNN::KNN(int k)
{
this->k = k;
fin.open("data.txt");
if (!fin)
{
cout << "can not open the data.txt" << endl;
exit(1);
}
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
fin >> TSet[i][j];
}
fin >> labels[i];
}
cout << "请输入test data:" << endl;
for(int i=0;i<col;i++)
{
cin >> Test[i];
}
}
//数据集和测试数据对应坐标的距离和
double KNN::distance(TData *t1, TData *t2)
{
double sum = 0;
for (int i = 0; i < col; i++)
{
sum += pow((t1[i] - t2[i]), 2);
}
return sqrt(sum);
}
void KNN::All_distance()
{
double dis;
for (int i = 0; i < row; i++)
{
dis = distance(TSet[i], Test);
dis_index[i] = dis; //每一个训练数据到测试数据的dis
}
map<int, double>::const_iterator i = dis_index.begin();
for (i; i != dis_index.end(); i++)
{
cout << "index=" << i->first << " distance=" << i->second << endl; //获取键和值
}
}
//得到测试数据的类别
void KNN::get_label()
{
vector<pair<int,double>> vec_dis_index(dis_index.begin(), dis_index.end()); //包含了从 map 容器中复制出来的所有键值对
//sort(vec_dis_index.begin(), vec_dis_index.end(), cmp()); //通常用来对数组或向量等容器类型进行排序sort(first, last [, comp]);
sort(vec_dis_index.begin(), vec_dis_index.end(), [&](const pair<int, double>& a, const pair<int, double>& b) {return a.second < b.second; });
for (int i = 0; i < k; i++)
{
cout << "index=" << vec_dis_index[i].first << " distance=" << vec_dis_index[i].second << " 类别=" << labels[vec_dis_index[i].first] << " 坐标=(" << TSet[vec_dis_index[i].first][0] << "," << TSet[vec_dis_index[i].first][1] << ")" << endl;
label_count[labels[vec_dis_index[i].first]]++;
}
int max = 0;
tData t;
for (map<char, int>::const_iterator i = label_count.begin(); i != label_count.end(); i++)
{
if (i->second > max)
{
max = i->second;
t=i->first;
}
}
cout << "测试数据属于的类别" << t << endl;
}
int main()
{
int k;
cout << "请输入k的值" << endl;
cin >> k;
KNN knn(k);
knn.All_distance();
knn.get_label();
}结果
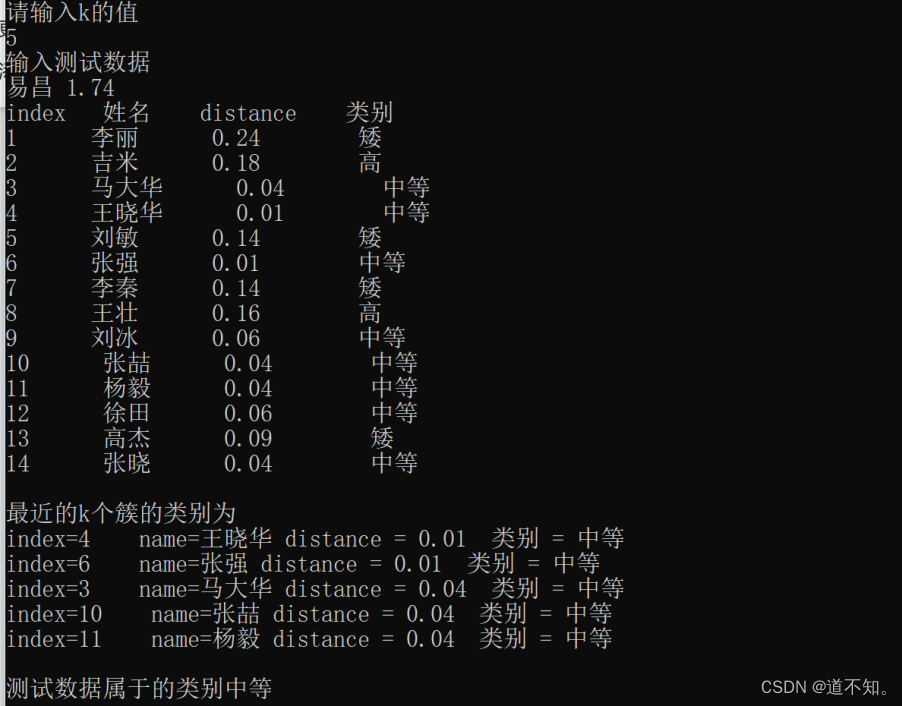
例题:
某班有14个同学,已登记身高及等级,新同学易昌,身高1.74cm,等级是什么。请用knn算法进行分类识别,其中k=5。
| 序号 |
姓名 |
身高(cm) |
等级 |
| 1 |
李丽 |
1.5 |
矮 |
| 2 |
吉米 |
1.92 |
高 |
| 3 |
马大华 |
1.7 |
中等 |
| 4 |
王晓华 |
1.73 |
中等 |
| 5 |
刘敏 |
1.6 |
矮 |
| 6 |
张强 |
1.75 |
中等 |
| 7 |
李秦 |
1.6 |
矮 |
| 8 |
王壮 |
1.9 |
高 |
| 9 |
刘冰 |
1.68 |
中等 |
| 10 |
张喆 |
1.78 |
中等 |
| 11 |
杨毅 |
1.70 |
中等 |
| 12 |
徐田 |
1.68 |
中等 |
| 13 |
高杰 |
1.65 |
矮 |
| 14 |
张晓 |
1.78 |
中等 |
//计算每个训练数据到待分类元组的距离,取和待分类元组距离最近的k个训练数据,k个数据中哪个类别的训练数据占多数,则待分类元组就属于哪个类别。
#include<iostream>
#include<map>
#include<vector>
#include<stdio.h>
#include<cmath>
#include<cstdlib>
#include<algorithm>
#include<fstream>
#include <filesystem>
#include <sstream>
#include <locale.h>
#include <Windows.h>
using namespace std;
ifstream fin; //输入文件流,可以用于从文件中读取数据。通过构造函数或 open() 成员函数打开指定的文件,然后使用输入运算符( >> )和其他输入操作从文件中读取数据:
ofstream fout;
struct Person {
std::string name;
double height;
std::string category;
};
vector<Person> dataset;
Person test;
class KNN
{
private:
int k;
map<int, double> dis_index;
map<string, int> label_count;
public:
KNN(int k);
double distance(Person t1, Person t2);
void All_distance();
void get_label();
};
KNN::KNN(int k)
{
this->k = k;
ifstream file("data.txt");
if (file.is_open())
{
string line;
while (getline(file, line)) {
stringstream ss(line); //
string name, category;
double height;
ss >> name >> height >> category;
dataset.push_back({ name, height, category });
}
}
}
//数据集和测试数据
double KNN::distance(Person t1, Person t2)
{
return abs(t1.height - t2.height);
}
void KNN::All_distance()
{
double dis;
for (int i = 0; i < dataset.size(); i++)
{
dis = distance(dataset[i], test);
dis_index[i] = dis; //每一个训练数据到测试数据的dis
}
map<int, double>::const_iterator i = dis_index.begin();
cout << "index " << "姓名 " << "distance " << "类别 " << endl;
for (i; i != dis_index.end(); i++)
{
cout << i->first+1 <<" " << dataset[i->first].name << " " << i->second << " " << dataset[i->first].category << endl; //获取键和值
}
}
//得到测试数据的类别
void KNN::get_label()
{
vector<pair<int, double>> vec_dis_index(dis_index.begin(), dis_index.end()); //包含了从 map 容器中复制出来的所有键值对
//sort(vec_dis_index.begin(), vec_dis_index.end(), cmp()); //通常用来对数组或向量等容器类型进行排序sort(first, last [, comp]);
sort(vec_dis_index.begin(), vec_dis_index.end(),
[&](const pair<int, double>& a, const pair<int, double>& b) {return a.second < b.second; });
cout << endl<<"最近的k个簇的类别为" << endl;
for (int i = 0; i < k; i++)
{
cout << "index=" << vec_dis_index[i].first+1 << " name="<< dataset[vec_dis_index[i].first].name<<" distance = " << vec_dis_index[i].second << " 类别 = " << dataset[vec_dis_index[i].first].category << endl;
label_count[dataset[vec_dis_index[i].first].category]++;
}
int max = 0;
string t;
for (map<string, int>::const_iterator i = label_count.begin(); i != label_count.end(); i++)
{
if (i->second > max)
{
max = i->second;
t = i->first;
}
}
cout << endl<<"测试数据属于的类别" << t << endl;
}
int main()
{
int k;
cout << "请输入k的值" << endl;
cin >> k;
cout << "输入测试数据" << endl;
cin >> test.name >> test.height;
KNN knn(k);
knn.All_distance();
knn.get_label();
}运行结果