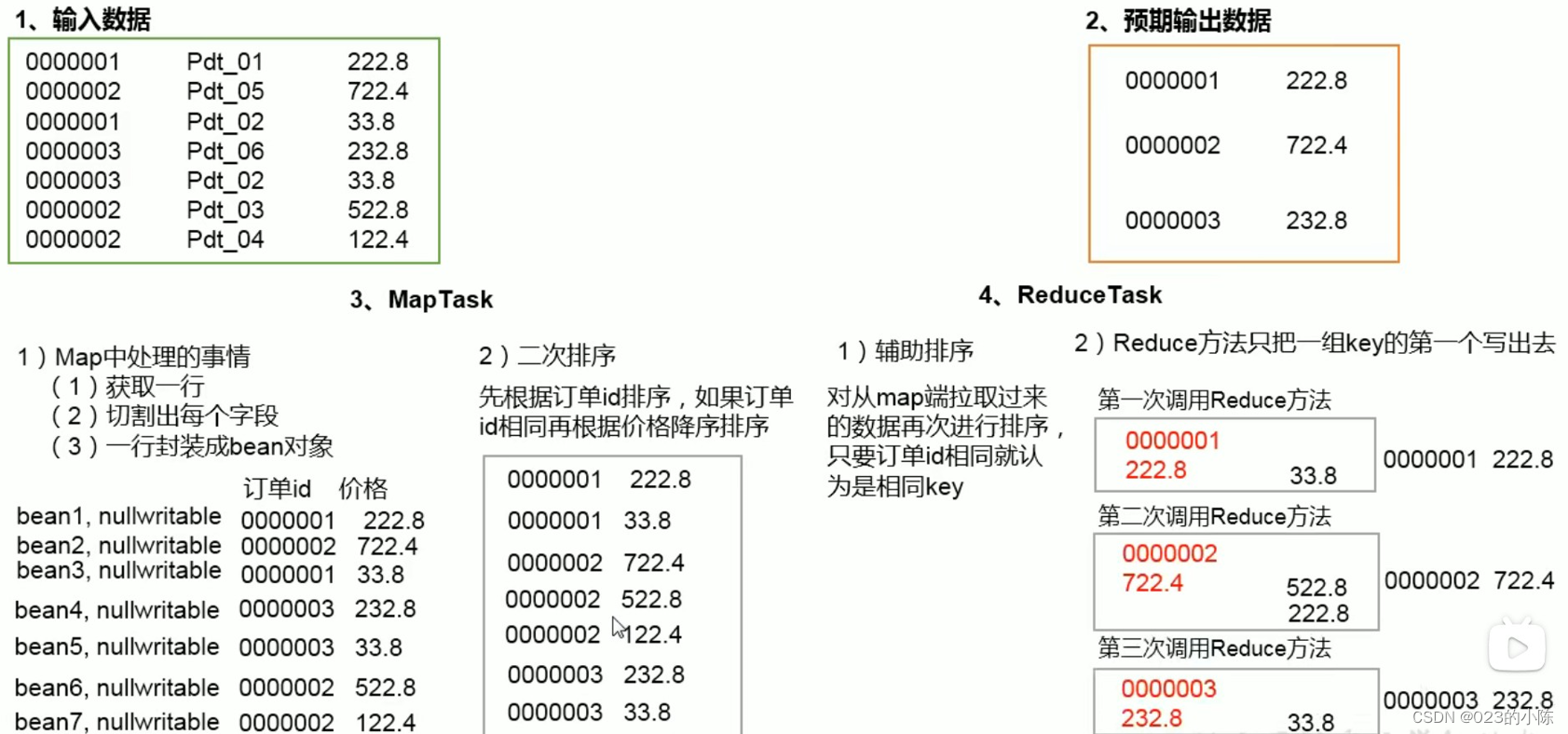
案列需求分析:
求出每个订单中最贵的商品
自定义数据类型OrderBean类:
1实现WritableComparable接口
2必须有一个空参构造函数
3实现序列化和反序列化,顺序必须保持一直
4重写toString()方法
5重写compareTo
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
int order_id;//订单id
String item_id;//商品id
float price;//价格
public OrderBean() {
super();
}
@Override
public String toString() {
return order_id+"\t"+item_id+"\t"+price;
}
//二次排序先按照订单大小排序再按照订单金额排序
public int compareTo(OrderBean o) {
if(this.order_id==o.order_id)
return this.price>o.price?-1:1;
else
return this.order_id>o.order_id?1:-1;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(order_id);
dataOutput.writeUTF(item_id);//序列化字符串
dataOutput.writeFloat(price);
}
public void readFields(DataInput dataInput) throws IOException {
this.order_id=dataInput.readInt();
this.item_id=dataInput.readUTF();//反序列化字符串
this.price=dataInput.readFloat();
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public String getItem_id() {
return item_id;
}
public void setItem_id(String item_id) {
this.item_id = item_id;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
}
MyMapper类:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] strings = line.split("\\t");
OrderBean k = new OrderBean();
k.setOrder_id(Integer.parseInt(strings[0]));
k.setItem_id(strings[1]);
k.setPrice(Float.parseFloat(strings[2]));
context.write(k,NullWritable.get());
System.out.println(k);
}
}
MyReducer类:
由于进行了分组排序,有相同订单id的分为一组,并且按照了金额由大到小排序,所以每组第一个数据即需求数据,context.write(key,NullWritable.get());即只是输出第一个数据
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<OrderBean, NullWritable,OrderBean,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}MyGroupingComparator类:
1继承WritableComparator
2重写compare方法,进行分组依据
3必须有一个构造函数,把要比较的类(实现了WritableComparable的类)传进去super(OrderBean.class,true);
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyGroupingComparator extends WritableComparator {
public MyGroupingComparator() {
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean= (OrderBean) a;
OrderBean bBean= (OrderBean) b;
int res=0;
if(aBean.getOrder_id()==bBean.getOrder_id())
res=0;
else if(aBean.getOrder_id()>bBean.getOrder_id())
res=1;
else
res=-1;
return res;
}
}
MyDriver类:
主要设置一下分组排序用的哪个类:
job.setGroupingComparatorClass(MyGroupingComparator.class);
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MyDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MyDriver.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
job.setGroupingComparatorClass(MyGroupingComparator.class);
FileInputFormat.addInputPath(job,new Path("/home/hadoop/temp/order.txt"));
FileOutputFormat.setOutputPath(job,new Path("/home/hadoop/temp/order_RES"));
FileSystem.get(conf).delete(new Path("/home/hadoop/temp/order_RES"),true);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
运行结果:
遇到的问题总结:
1 reduce()不工作的原因:
a 没有context.write()或者job类忘记设置Reducer类
b map阶段输出的(k,v)与reduce阶段输入的(k,v)类型匹配
c 完全分布式中,有可能是节点之间的通讯无法连接,导致reduceTask节点不能通过网络把mapTask节点输出的数据拉取过来
d 存在序列化时:序列化出错也会导致reduceTask节点无法把拉取过来的数据进行反序列化
2 String类型进行序列化和反序列化时分别用writeUTF()和readUTF()