目录
一:TensorFlow简介
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,是一个基于数据流编程(dataflow programming)的符号数学系统。被广泛应用于各类机器学习算法的编程实现,它支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各个领域的科学研究,对C和python支持的比较友好
二:TensorFlow工作形式
TensorFlow是采用数据流图(data flow graphs)来计算,所以首先我们得创建一个数据流流图,然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算,节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数值,即张量(tensor),训练模型时tensor会不断的从数据流图中的一个节点flow到另一个节点
三:图/Session
tf.Graph/图:用来定义运算流程,它与实际计算没有关系,只是勾画出计算流程,它不存储任何计算的值或者中间变量
tf.Session/会话:用来根据graph来进行实际运算,会分配资源,创建变量,并且保存变量的中间值以及结果
tensorflow的运算都必须在一个指定的session里进行
四:安装tensorflow
安装命令如下
pip install tensorflow==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --user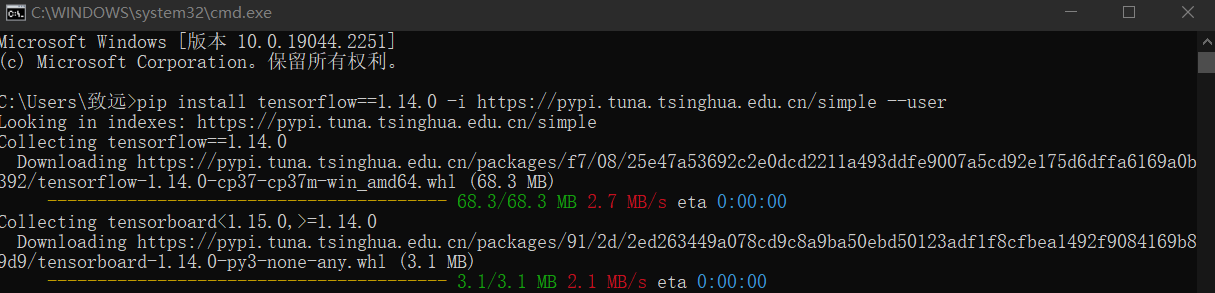
pip list检查是否安装成功

五:张量
张量tensor有多种,零阶乘张量为纯量或标量(scalar) 也就是一个数值,比如[1]
一阶张量为向量(vector),比如一维的[1,2,3]
二阶张量为矩阵(matrix),比如二维的[[1,2,3],[4,5,6],[7,8,9]]
以此类推,还有三阶三维的
张量创建的方法:
tf.ones
tf.ones_like
tf.zeros
tf.zeros_like
tf.convert_to_tensor(a)全1矩阵,如下
import tensorflow as tf
# 使用默认图
tensor = tf.ones((2, 2), dtype=tf.float32)
# 开启会话、启动图
with tf.Session() as sess:
print(sess.run(tensor))
输出结果:
[[1. 1.]
[1. 1.]]全0矩阵,如下
import tensorflow as tf
# 使用默认图
tensor = tf.zeros((2, 2), dtype=tf.float32)
# 开启会话、启动图
with tf.Session() as sess:
print(sess.run(tensor))
[[0. 0.]
[0. 0.]]创建一样的张量 ,如下
import tensorflow as tf
# 使用默认图
tensor = tf.zeros((2, 2), dtype=tf.float32)
tensor_like = tf.zeros_like(tensor)
# 开启会话、启动图
with tf.Session() as sess:
print(sess.run(tensor))
print(sess.run(tensor_like))
[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]
转换为张量,如下
import tensorflow as tf
import numpy as np
# 使用默认图
tensor = tf.zeros((2, 2), dtype=tf.float32)
tensor_like = tf.zeros_like(tensor)
np_ones = np.ones([3, 2])
tensor_ones = tf.convert_to_tensor(np_ones)
# 开启会话、启动图
with tf.Session() as sess:
# print(sess.run(tensor))
# print(sess.run(tensor_like))
print(sess.run(tensor_ones))
[[1. 1.]
[1. 1.]
[1. 1.]]六:变量/常量
变量Variable 定义语法
state = tf.Variable()
state = tf.Variable(0,name='counter')常量constant 定义语法
matrix1 = tf.constant([[3,3]])如下示例
import tensorflow as tf
# 1变量a
a = tf.Variable(0, name='a')
# 2常量b
b = tf.constant(1)
# 矩阵相加 实现加法模块
value = tf.add(a, b)
print(value)
输出结果如下:在实现加法模块OP后,就转为张量
Tensor("Add:0", shape=(), dtype=int32)OP:add加法、assign赋值、multiply乘法等
七:创建数据流图、会话
import tensorflow as tf
# 创建数据流图
graph = tf.Graph()
# 基于数据流图
with graph.as_default():
# 添加OP
var = tf.Variable(12, name='foo') # 创建变量
init = tf.global_variables_initializer() # 初始化所有变量
ass = var.assign(24)
# 创建一个会话,绘制启动的图
with tf.Session(graph=graph) as sess:
sess.run(init) # 如果图中有变量,必须执行初始化变量操作
sess.run(ass) # 执行OP 赋值
print(sess.run(var)) # 获取变量最终的值
输出结果值:24
八:张量经典创建方法
def random_normal(shape,
mean=0.0,
stddev=1.0,
dtype=dtypes.float32,
seed=None,
name=None):“服从指定正态分布的序列”中随机取出指定个数的值
shape:输出张量的形状,必选
mean:正态分布的均值,默认为0
stddev:正态分布的标准差,默认为1.0
dtype:输出的类型,默认为tf.float32
seed:随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
示例如下
import tensorflow as tf
tf_random = tf.random_normal((3, 4), mean=0.0, stddev=1.0, dtype=tf.float32, seed=666, name='normal')
# 使用默认图
# 开启会话、启动图
with tf.Session() as sess:
print(sess.run(tf_random))
输出结果如下
[[-0.15161146 -0.6076202 -0.5504767 -1.3674356 ]
[ 2.4222426 0.30945507 -1.6234491 -0.3828629 ]
[ 1.190534 1.1368927 0.45719737 -0.50563335]]九:变量赋值、初始化操作
如下,把value值,赋值给变量a
import tensorflow as tf
# 1变量a
a = tf.Variable(0, name='a')
# 2常量b
b = tf.constant(1)
# 矩阵相加 实现加法模块
value = tf.add(a, b)
# print(value)
# 变量赋值操作:把value赋值给a
update_op = tf.assign(a, value)
# 变量初始化
init = tf.global_variables_initializer()
# 开启会话,启动图
with tf.Session() as sess:
sess.run(init)
sess.run(update_op)
print(sess.run(a))
输出结果:1 (实现了加法模块OP)
下面示例为,求10个数的和
import tensorflow as tf
# 1变量a
num_var = tf.Variable(0, name='num_var')
sum_var = tf.Variable(0, name='sum_var')
# 2常量b
b = tf.constant(1)
# 矩阵相加 实现加法模块
value = tf.add(num_var, b)
# 变量赋值操作:把value赋值给a
update_num = tf.assign(num_var, value)
# 加法OP
value1 = tf.add(sum_var, update_num)
# 赋值给sum
assign_op = tf.assign(sum_var, value1)
# 变量初始化
init = tf.global_variables_initializer()
# 开启会话,启动图
with tf.Session() as sess:
sess.run(init)
for i in range(10):
sess.run(assign_op)
print(sess.run(num_var))
print(sess.run(sum_var))
10个数的求和为55,如下
10
55十:占位符
占位符 placeholder
import tensorflow as tf
import numpy as np
# 定义占位符
inp1 = tf.placeholder(np.float32)
inp2 = tf.placeholder(np.float32)
# 矩阵乘法OP
outinput = tf.multiply(inp1, inp2)
# 开启会话,启动图
with tf.Session() as sess:
# feed_dict 对占位符赋值 格式是字典
print(sess.run(outinput,
feed_dict={inp1: [8], inp2: [7]}))
print(sess.run(outinput, feed_dict={
inp1: [8.5, 6],
inp2: [7, 8.5]
}))
输出结果如下:
测试输出1为:8*7=56
测试输出2为:8.5*7=59.5 与 6*8.5=51
[56.]
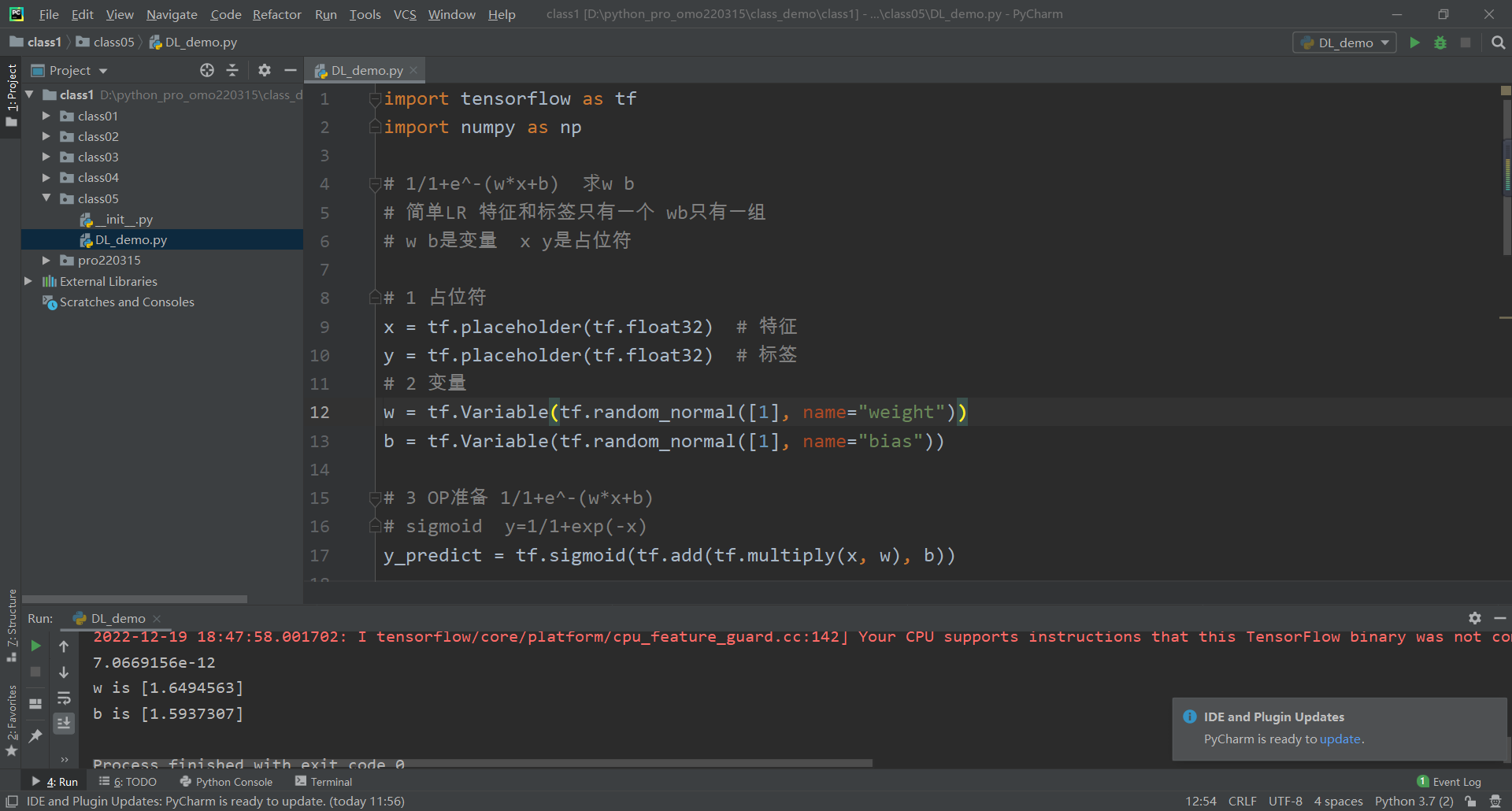
[59.5 51. ]十一:TensorFlow求解二元一次方程
import tensorflow as tf
import numpy as np
# 1/1+e^-(w*x+b) 求w b
# 简单LR 特征和标签只有一个 wb只有一组
# w b是变量 x y是占位符
# 1 占位符
x = tf.placeholder(tf.float32) # 特征
y = tf.placeholder(tf.float32) # 标签
# 2 变量
w = tf.Variable(tf.random_normal([1], name="weight"))
b = tf.Variable(tf.random_normal([1], name="bias"))
# 3 OP准备 1/1+e^-(w*x+b)
# sigmoid y=1/1+exp(-x)
y_predict = tf.sigmoid(tf.add(tf.multiply(x, w), b))
# 4 构建损失函数
num_samples = 400 # 数据样本数量
# pow幂计算(num,幂指数) cost损失值
cost = tf.reduce_sum(tf.pow(y_predict - y, 2.0)) / num_samples
# 5 梯度下降算法 求解最小损失值:AdadeltaOptimizer梯度算法(优化器)
Qptimizer = tf.train.AdadeltaOptimizer().minimize(cost)
# 6 初始化变量
init = tf.global_variables_initializer()
# 实际数据
xs = np.linspace(-5, 5, num_samples)
ys = np.sign(xs)
# print(xs,ys)
cost_pre = 0
# 开启会话,启动图
with tf.Session() as sess:
sess.run(init)
# 训练 解方程
for i in range(200):
# 从x,y中准备好数据,给优化器,存入占位符
for xa, ya in zip(xs, ys):
sess.run(Qptimizer, feed_dict={x: xa, y: ya})
train_cost = sess.run(cost, feed_dict={x: xa, y: ya})
print(train_cost)
if train_cost - cost_pre < 1e-6:
break
else:
cost_pre = train_cost
print('w is', sess.run(w, feed_dict={x: xa, y: ya}))
print('b is', sess.run(b, feed_dict={x: xa, y: ya}))
输出结果,如下
0.0023457657
0.0023456183
w is [-0.5132782]
b is [-0.8636957]每一次的运行结果不同
7.0669156e-12
w is [1.6494563]
b is [1.5937307]