问题引入
将中文字符“你”用UTF-8编码转成字节数组后,为什么是这样的三个数字?
byte[] bytes = "你".getBytes(StandardCharsets.UTF_8);
for (byte t:bytes){
System.out.println(t);
}打印的结果如下:
-28
-67
-96
你有没有很好奇,为什么是这三个数字?
问题分析
字节数组为什么长度是3
这个问题比较简单,因为UTF-8的规范就是,常见的中文字符是用占用三个字节的,所以你字转成二进制字节数组的长度就是3
怎么根据这三个数映射到字符你
验证的流程如下:
- 将10进制转成二进制
byte[] bytes = "你".getBytes("UTF-8");
for (byte b : bytes) {
String tmp = Integer.toBinaryString(0xFF & b);
System.out.println(tmp);
}解释下这段代码
0xFF是16进制,将16进制转成二进制的结果就是11111111,对应的10进制是255
byte在java中是占用一个字节的,也就是8bit,这里使用 0xFF & b的目的是让对应的byte数值对应的二进制只保留8位
打印的结果如下
11100100
10111101
10100000
- UTF-8字符集是怎么编码的
UTF-8的编码规则是这样的:
- 对于单字节的字符,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的字符 (n > 1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
这段是取自官方网站,可以详细的看到UTF-8字符集是怎么编码的。
byte数组对应的二进制进行组合,就是如下的二进制了
11100100 10111101 10100000
对这个源码进行UTF-8编码得到的结果就是,【剔除第一个字节的前四位,剔除第二个字节的前两位,剔除第三个字节的前两位】,得到的结果就是如下:
0100111101100000
- 编码查找
将编码后的二进制转成16进制,可以通过【在线进制转换 - 二进制转换器】在线转换,得到结果
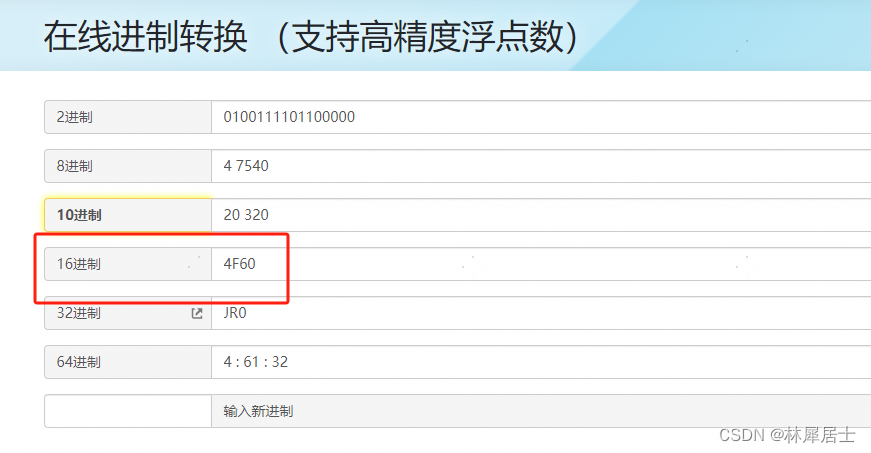
接着就可以根据Unicode字符集编码表,在线查找对应的字符了,字码表查询可以参考官网【Unicode Character Table - Full List of Unicode Symbols (◕‿◕) SYMBL】
查找的结果如下
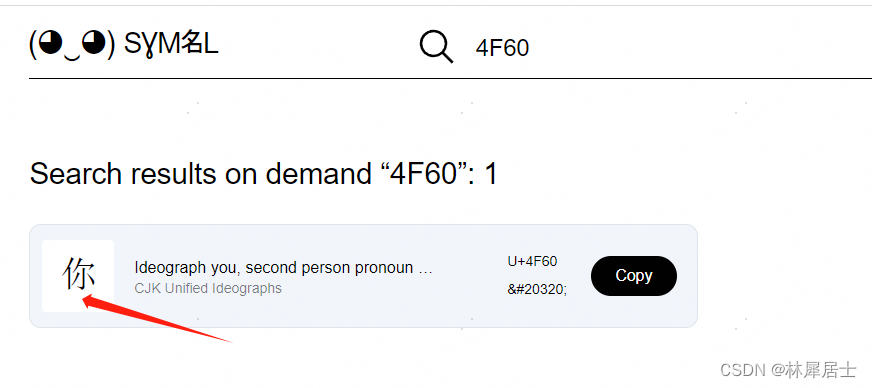
可以看到,刚好得应的字符就是你,至此,整个问题实现了闭环!