目录
编程实现 kNN 算法。
1、读取excel表格存放的Iris数据集。该数据集有5列,其中前4列是条件属性,最后1列是类别(已经表示为数值)。
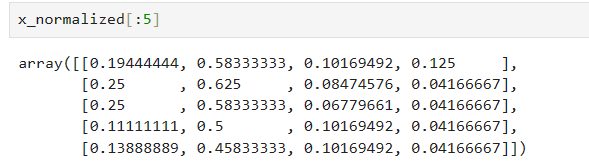
2、对数据集进行按列归一化,使每列的取值范围是[0,1].
3、从数据集中随机选取70%作为训练数据集,剩下30%用来测试,k=5.
4、输出测试数据的分类正确率,即正确分类的测试样本数除以总的测试样本数。
一、步骤
①准备数据,对数据进行预处理
②计算测试样本点(也就是待分类点)到其他每个样本点的距离 。
③对每个距离进行排序,然后选择出距离最小的K个点。
④对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。
二、实现代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
# 读取excal表格数据
iris_data=pd.read_csv('Iris.csv')
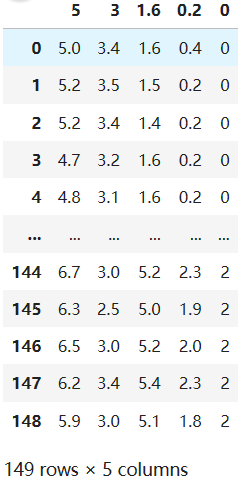
# 获取条件属性和类别
x=iris_data.iloc[:,:-1] #截取前4列属性
y=iris_data.iloc[:,-1] #截取最后一列类别
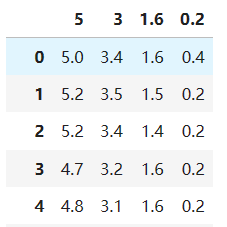

# 数据归一化
scaler=MinMaxScaler()
x_normalized=scaler.fit_transform(x)
# 划分测试集30%、训练集70%
x_train,x_text,y_train,y_text=train_test_split(x_normalized,y,test_size=0.3,random_state=42)
knn_classifier=KNeighborsClassifier(n_neighbors=5)# 5个最近相邻作为参考
knn_classifier.fit(x_train,y_train)# 训练分类器
y_pred=knn_classifier.predict(x_text)# 训练好的分类剩下的测试集
accuracy=accuracy_score(y_pred,y_text)# 比较测试精度
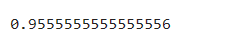
三、总结知识
1、切片
语法:
start:stop:step
start:起始索引
stop:终止索引
step:步长
举例:
a=[1,2,3,4,5,6,7,8,9,10]
a[2:5:]
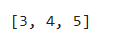
a[::-1]

a[-1::]
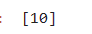
a[:-1:]
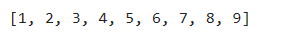
a[-5:-1:]
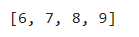
2、iloc方法
iloc是Pandas中按位置(整数位置)索引数据的方法
DataFrame.iloc[索引行,索引列]
其中索引行,索引列可以是单个整数、整数列表/数组、切片对象
iloc[:,:-1] #取前四列
iloc[:,-1] #取最后一列
3、归一化
什么是归一化
归一化是一种数据处理方法,它将数据转换为一定范围内的数值。这个范围可以是任意的,但是最常用的范围是0到1或-1到1之间。归一化的作用是,使得不同数据在参与运算和比较时更加公平和准确,从而提高模型的精度和可靠性。
为什么要归一化
在机器学习中,由于不同的特征在量级和范围上的不同,使得它们的贡献不同。在一些模型中,例如kNN、KMeans等,特征之间的距离就成了模型的核心,而这些模型在计算距离时需要保证特征之间具有同样的权重,这就需要对特征进行归一化。对于另一些模型如神经网络,特征之间的权重影响了模型的收敛速度和稳定性,进行归一化可以加快收敛速度和降低过拟合的情况。
4、MinMaxScale()
MinMaxScaler 是 scikit-learn 库中的一个类,用于进行最小-最大缩放(归一化)操作。归一化是一种将数据缩放到指定范围的方法,通常是 [0, 1]。这有助于确保不同特征之间的数值差异不会对机器学习模型产生不良影响。
具体来说,MinMaxScaler 将每个特征缩放到给定的最小值和最大值之间。其主要方法是使用以下公式
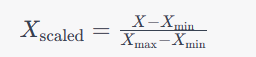
from sklearn.preprocessing import MinMaxScaler
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
# 对数据进行归一化
X_normalized = scaler.fit_transform(X)
fit_transform 方法将计算训练集的最小值和最大值,并使用上述公式对训练集进行归一化
5、 train_test_split划分测试集、训练集
X_train, X_test, y_train, y_test = train_test_split(X_normalized, y, test_size=0.3, random_state=42)
X_normalized: 归一化后的特征矩阵,即条件属性。
y: 目标(类别)列。
这行代码将数据集拆分为训练集和测试集,其中:
X_train: 训练集的特征矩阵。
X_test: 测试集的特征矩阵。
y_train: 训练集的目标(类别)。
y_test: 测试集的目标(类别)。
6、KNN算法
knn_classifier = KNeighborsClassifier(n_neighbors=5)
创建了一个 kNN 分类器对象。n_neighbors=5 表示选择最近的5个邻居作为参考来进行分类
knn_classifier.fit(X_train, y_train)
使用训练数据来拟合(训练)kNN 分类器。X_train 是训练集的特征矩阵,y_train 是训练集的目标(类别)列。通过这个过程,kNN 分类器学会了如何根据特征对数据进行分类
调用接口版.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
# 读取Excel表格数据用csv存储
iris_data = pd.read_csv('Iris.csv')
# 获取条件属性和类别
X = iris_data.iloc[:, :-1] # 前4列是条件属性
y = iris_data.iloc[:, -1] # 最后1列是类别
# 对数据进行按列归一化
scaler = MinMaxScaler()
X_normalized = scaler.fit_transform(X)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_normalized, y, test_size=0.3)
# 创建kNN分类器并进行训练
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn_classifier.predict(X_test)
# 计算分类正确率
accuracy = accuracy_score(y_test, y_pred)
print(f"分类正确率: {
accuracy}")
底层实现版.py
import operator
import numpy as np
import pandas as pd
# 读取Excel表格数据用csv存储
iris_data = pd.read_csv('data.csv')
# 获取条件属性和类别
X = iris_data.iloc[:, :-1] # 前4列是条件属性
y = iris_data.iloc[:, -1] # 最后1列是类别
# 对数据进行按列归一化
X_normalized = (X-X.min())/(X.max()-X.min())
# 将数据集拆分为训练集和测试集
def split_data(attribute,category):
# 随机种子
np.random.seed(40)
# 打乱数据集
indices=np.arange(len(attribute))
np.random.shuffle(indices)
# 训练集个数
split_size=int(len(attribute)*0.7)
# 训练集索引
x_train_indices=indices[:split_size]
# 测试集索引
x_text_indices=indices[split_size:]
# 训练集
x_train=attribute.iloc[x_train_indices]
y_train=category.iloc[x_train_indices]
# 测试集
x_text=attribute.iloc[x_text_indices]
y_text=category.iloc[x_text_indices]
return x_train,y_train,x_text,y_text
# 划分训练集和测试集
x_train,y_train,x_text,y_text=split_data(X_normalized,y)
# 创建kNN分类器并进行训练
# 训练属性,训练类别,测试数据,相邻数k
def knn_classify(x_train,y_train,x_text,k):
# 访问行数
x_train_size=x_train.shape[0]
# 初始化数组存放所有预测结果
prediction = []
for i in range(x_text.shape[0]):
# 欧式距离
# 测试集-训练集(x-y)平方
distances = (x_train-x_text.iloc[i])**2
# 按列相加
sum_distence=np.sum(distances,axis=1)
# 取根号
sqrt_distence=sum_distence**0.5
# 距离排序索引(0,1,2,3,4,5)
sort_distence=sqrt_distence.argsort()
# 取前k个值的属性,iloc[索引]选取的值
k_value=y_train.iloc[sort_distence[:k]]
# 统计类别的数量
class_dirt={
}
for i in k_value:
# 每个类别对应的个数
class_dirt[i]=class_dirt.get(i,0)+1
# 根据类别数量排序
sort_distence=sorted(class_dirt.items(),key=operator.itemgetter(1),reverse=True)
# 将最大类别加入到数组中
prediction.append(sort_distence[0][0])
return prediction
# 调用函数
knn=knn_classify(x_train,y_train,x_text,5)
# 计算分类正确率
# 测试样本个数
text_size=len(x_text)
# 预测成功个数
pre_size=sum(pre==actual for pre,actual in zip(knn,y_text))
# 测试精度
accuracy=pre_size/text_size
print(f'准确率:{
accuracy}')