1. 网络模型的保存和读取
网络模型有两种保存方式
vgg16=torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT)
#方式1 模型结构+参数
torch.save(vgg16,"vgg_method1.pth")
#方式2 模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg_method2.pth")
网络模型的两种读取方式
#方式一
model=torch.load("vgg_method1.pth")
#方式二 模型+参数 vgg16是模型 然后load_state_dict 导入参数
vgg16=torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT)
vgg16.load_state_dict(torch.load("vgg_method2.pth")
2.一般完整的训练步骤
import torch.optim
import torchvision
from torch.nn import Sequential
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from tutu.tensorboard.model import Net
test=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
train=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor())
train_data_size=len(train)
test_data_size=len(test)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
train_dataloader=DataLoader(dataset=train,batch_size=64)
test_dataloader=DataLoader(dataset=test,batch_size=64)
net=Net()
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(net.parameters(),lr=0.01)
train_step=0
test_step=0
epoch=10
writer=SummaryWriter("logs")
for i in range(epoch):
print("第{}轮开始".format(i+1))
for data in train_dataloader:
img,target=data
output=net(img)
loss=loss_fn(output,target)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_step =train_step+1
if train_step%100==0:
print("训练次数是{}的时候,loss是{}".format(train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),train_step) #每次的loss
#测试步骤
test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
img,target=data
output=net(img)
loss=loss_fn(output,target)
test_loss=test_loss+loss.item()
accuracy=(output.argmax(1)==target).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss{}".format(test_loss))
print("整体测试集上的正确率{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", test_loss, test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, test_step)
test_step = test_step+1
网络模型
class Net(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1=Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,input):
x=self.model1(input)
return x
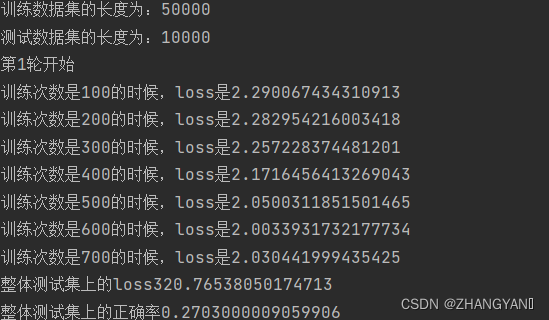
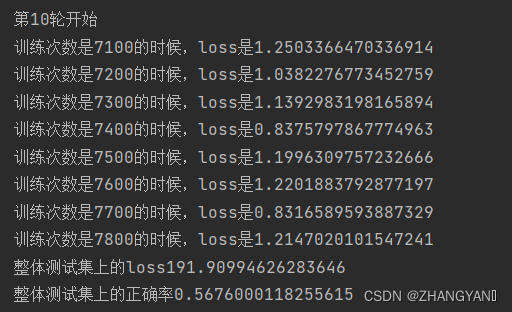
第10轮结束后准确率依然很低,所以可以加大轮数或者更改网络模型或者更改学习率等等。

3.如何调整换到GPU/CPU运行
方式一
如果想用GPU进行训练只需要在原有训练中
网络模型.cuda()

训练数据.cuda()
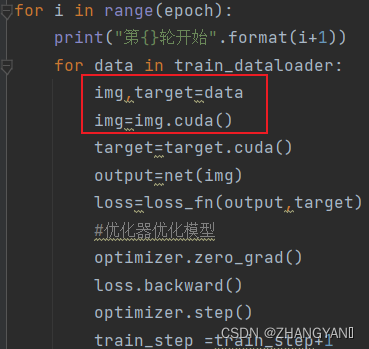
损失函数.cuda()

方式二
device=torch.device('cuda’if torch.cuda.is_available() else ‘cpu’)
网络模型 损失函数.to(device)

训练数据.to(device)
