目录
一、AmpliGraph
1、介绍
AmpliGraph是Accenture实验室开发的基于TensorFlow 1.x的开源库,可利用它生成知识图谱嵌入、进行链接预测、开发和评估新的关系模型。
知识图谱嵌入即将知识(知识图谱中的实体、关系、属性)嵌入到低维连续的向量空间中,帮助计算机对知识进行语义计算,是知识推理(链接预测、三元组分类)的基础。
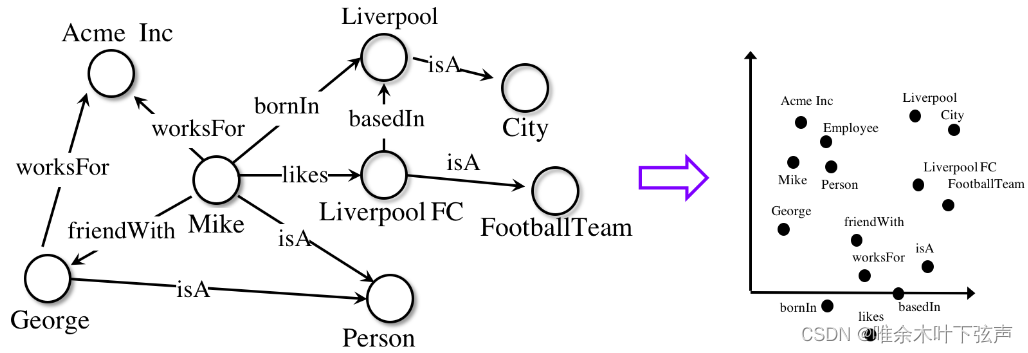
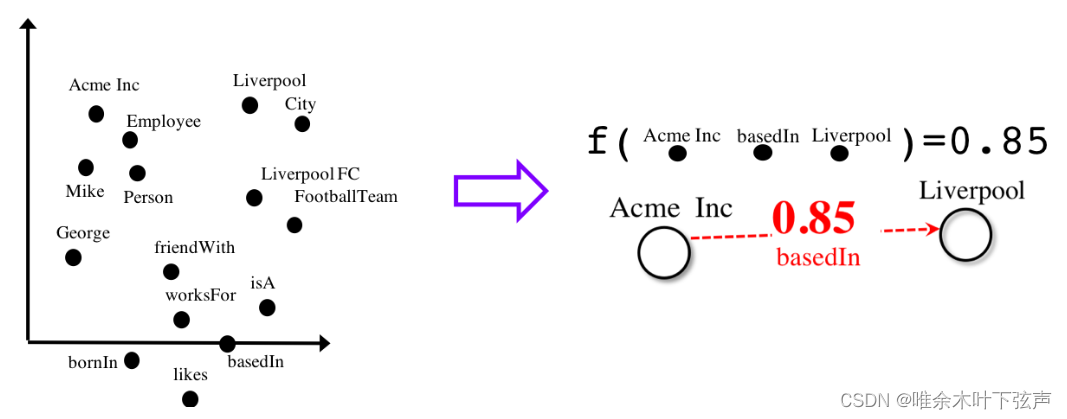
然后,AmpliGraph可将嵌入向量与知识表示模型的评分函数相结合,从知识图谱中发现新实体、新关系。
2、特点
- 直观的API:AmpliGraph API 旨在减少学习预测知识图谱中链接的模型所需的代码量。
- 可使用GPU:AmpliGraph基于TensorFlow,可在CPU和GPU设备上无缝运行,加快训练速度。
- 可扩展:通过扩展 AmpliGraph,可运行自己的知识图谱嵌入模型。
3、模块
AmpliGraph包括以下子模块:
- 数据集:提供加载数据集的功能函数。
- 模型:AmpliGraph包含TransE,DistMult,ComplEx,HolE,ConvE,ConvKB这些知识图谱嵌入模型。
- 评估:用于评估模型链接预测能力的指标和评估协议。
- 发现:用于知识发现的高级、方便的 API(发现新事实、聚类实体、预测近似重复项)。
4、安装AmpliGraph
条件:
- Linux, macOS, Windows
- Python 3.7
创建并激活虚拟环境 (conda):
conda create --name ampligraph python=3.7
source activate ampligraph安装 TensorFlow:
AmpliGraph基于TensorFlow 1.x,可用 pip 或 conda 安装:
#CPU
pip install "tensorflow>=1.15.2,<2.0"
conda install tensorflow'>=1.15.2,<2.0.0'
#GPU
pip install "tensorflow-gpu>=1.15.2,<2.0"
conda install tensorflow-gpu'>=1.15.2,<2.0.0'安装ampligraph:
从 pip 安装最新的稳定版本,当前最新版本为1.4.0版本
pip install ampligraph
>> import ampligraph
>> ampligraph.__version__
'1.4.0'如果想要最新的开发版本,则可以克隆存储库并从源代码安装。下面的代码段将以可编辑模式安装库(-e):
git clone https://github.com/Accenture/AmpliGraph.git
cd AmpliGraph
pip install -e .预测能力评估(MRR Filtered):
AmpliGraph包括TransE,DistMult,ComplEx,HolE,ConvE和ConvKB的实现。他们的预测能力如下表所示,并与文献中最先进的结果进行了比较。
| FB15K-237 | WN18RR | YAGO3-10 | FB15k | WN18 | |
|---|---|---|---|---|---|
| Literature Best | 0.35* | 0.48* | 0.49* | 0.84** | 0.95* |
| TransE (AmpliGraph) | 0.31 | 0.22 | 0.51 | 0.63 | 0.66 |
| DistMult (AmpliGraph) | 0.31 | 0.47 | 0.50 | 0.78 | 0.82 |
| ComplEx (AmpliGraph) | 0.32 | 0.51 | 0.49 | 0.80 | 0.94 |
| HolE (AmpliGraph) | 0.31 | 0.47 | 0.50 | 0.80 | 0.94 |
| ConvE (AmpliGraph) | 0.26 | 0.45 | 0.30 | 0.50 | 0.93 |
| ConvE (1-N, AmpliGraph) | 0.32 | 0.48 | 0.40 | 0.80 | 0.95 |
| ConvKB (AmpliGraph) | 0.23 | 0.39 | 0.30 | 0.65 | 0.80 |
* Timothee Lacroix, Nicolas Usunier, and Guillaume Obozinski. Canonical tensor decomposition for knowledge base completion. In International Conference on Machine Learning, 2869–2878. 2018.
** Kadlec, Rudolf, Ondrej Bajgar, and Jan Kleindienst. "Knowledge base completion: Baselines strike back. " arXiv preprint arXiv:1705.10744 (2017).
二、API接口
1、数据
设置环境变量(建议):AMPLIGRAPH_DATA_HOME
export AMPLIGRAPH_DATA_HOME=/YOUR/PATH/TO/datasets当试图加载一个数据集时,该模块会首先判断是否已存在AMPLIGRAPH_DATA_HOME中,如果数据集不存在,则会下载并放入AMPLIGRAPH_DATA_HOME目录下。
数据集加载函数:
| load_fb15k_237([check_md5hash, ...]) | 加载 FB15k-237 数据集 |
| load_wn18rr([check_md5hash, clean_unseen, ...]) | 加载 WN18RR 数据集 |
| load_yago3_10([check_md5hash, clean_unseen, ...]) | 加载 YAGO3-10 数据集 |
| load_fb15k([check_md5hash, add_reciprocal_rels]) | 加载 FB15k 数据集 |
| load_wn18([check_md5hash, add_reciprocal_rels]) | 加载 WN18 数据集 |
| load_wn11([check_md5hash, clean_unseen, ...]) | 加载 WordNet11 (WN11) 数据集 |
| load_fb13([check_md5hash, clean_unseen, ...]) | 加载 Freebase13 (FB13) 数据集 |
数据集介绍:
| Dataset | 训练集 | 验证集 | 测试集 | 实体 | 关系 |
|---|---|---|---|---|---|
| FB15K-237 | 272,115 | 17,535 | 20,466 | 14,541 | 237 |
| WN18RR | 86,835 | 3,034 | 3,134 | 40,943 | 11 |
| FB15K | 483,142 | 50,000 | 59,071 | 14,951 | 1,345 |
| WN18 | 141,442 | 5,000 | 5,000 | 40,943 | 18 |
| YAGO3-10 | 1,079,040 | 5,000 | 5,000 | 123,182 | 37 |
| WN11 | 110,361 | 5,215 | 21,035 | 38,194 | 11 |
| FB13 | 316,232 | 11,816 | 47,464 | 75,043 | 13 |
加载自有数据集:
| load_from_csv(directory_path, file_name[, …]) | 从csv文件中加载知识图谱 |
| load_from_ntriples(folder_name, file_name[, …]) | 加载RDF ntriples |
| load_from_rdf(folder_name, file_name[, …]) | 加载RDF文件 |
2、模型
| RandomBaseline([seed, verbose]) | Random baseline |
| TransE([k, eta, epochs, batches_count, …]) | Translating Embeddings (TransE) |
| DistMult([k, eta, epochs, batches_count, …]) | The DistMult model |
| ComplEx([k, eta, epochs, batches_count, …]) | Complex embeddings (ComplEx) |
| HolE([k, eta, epochs, batches_count, seed, …]) | Holographic Embeddings |
| ConvE([k, eta, epochs, batches_count, seed, …]) | Convolutional 2D KG Embeddings |
| ConvKB([k, eta, epochs, batches_count, …]) | Convolution-based model |
AmpliGraph的模型包含以下组件:得分函数Scoring function、损失函数Loss function、优化算法Optimization algorithm、正则化Regularizer、初始化Initializer、负例生成策略Negatives generation strategy、支持边权重Support for Numeric Literals on Edges
调用TransE训练嵌入:
TransE输入参数以及fit、predict、get_embeddings等函数具体调用方法可见源文档。
>>> import numpy as np
>>> from ampligraph.latent_features import TransE
>>> model = TransE(batches_count=1, seed=555, epochs=20, k=10, loss='pairwise',
>>> loss_params={'margin':5})
>>> X = np.array([['a', 'y', 'b'],
>>> ['b', 'y', 'a'],
>>> ['a', 'y', 'c'],
>>> ['c', 'y', 'a'],
>>> ['a', 'y', 'd'],
>>> ['c', 'y', 'd'],
>>> ['b', 'y', 'c'],
>>> ['f', 'y', 'e']])
>>> model.fit(X)
>>> model.predict(np.array([['f', 'y', 'e'], ['b', 'y', 'd']]))
[-4.6903257, -3.9047198]
>>> model.get_embeddings(['f','e'], embedding_type='entity')
array([[ 0.10673896, -0.28916815, 0.6278883 , -0.1194713 , -0.10372276,
-0.37258488, 0.06460134, -0.27879423, 0.25456288, 0.18665907],
[-0.64494324, -0.12939683, 0.3181001 , 0.16745451, -0.03766293,
0.24314676, -0.23038973, -0.658638 , 0.5680542 , -0.05401703]],
dtype=float32)3、评估
该模块包括神经图嵌入模型的性能指标,以及最佳模型ranking,负例生成以及文献中使用的learning-to-rank-based评估协议的实现。
指标:
| rank_score(y_true, y_pred[, pos_lab]) | Rank of a triple |
| mrr_score(ranks) | Mean Reciprocal Rank (MRR) |
| mr_score(ranks) | Mean Rank (MR) |
| hits_at_n_score(ranks, n) | Hits@N |
负例生成:
基于局部封闭世界假设Local Closed-World Assumption (LCWA)
| generate_corruptions_for_eval(X, …[, …]) | 用于评估 |
| generate_corruptions_for_fit(X[, …]) | 用于训练 |
评估&模型选择:
| evaluate_performance(X, model[, …]) | Evaluate the performance of an embedding model |
| select_best_model_ranking(model_class, …) | 基于网格搜索或随机搜索的嵌入模型选择,返回最佳训练嵌入模型 |
评估程序的实用程序和支持功能:
| train_test_split_no_unseen(X[, test_size, …]) | 分隔训练集、测试集 |
| create_mappings(X) | 创建实体和关系的string-IDs映射 |
| to_idx(X, ent_to_idx, rel_to_idx) | 将三元组转换为ID |
4、发现
此模块提供一些在图嵌入中执行知识发现的功能函数。
| discover_facts(X,模型[,top_n,策略,...]) | 从现有知识图谱中发现新事实 |
| find_clusters(X, model[, ...]) | 对知识图谱执行基于链接的聚类分析。 |
| find_duplicates(X, model[, mode, metric, ...]) | 根据嵌入向量在图谱中查找重复的实体、关系或三元组。 |
| query_topn(模型[,top_n,头部,关系,...]) | 输入三元组的其中两个元素,返回按模型预测分数排序的top_n链接预测结果。 |
| find_nearest_neighbours(kge_model,实体) | 返回实体的最近邻。 |
5、其他实用函数
| save_model(model[、model_name_path、protocol]) | 将训练的模型保存到磁盘 |
| restore_model([model_name_path]) | 从磁盘恢复保存的模型 |
| create_tensorboard_visualizations(model, loc) | 导出嵌入向量到Tensorboard. |
| dataframe_to_triples(X, schema) | 将DataFrame转换为三元组格式 |
三、实例代码
1、训练和评估嵌入模型
#导包
import numpy as np
from ampligraph.datasets import load_wn18
from ampligraph.latent_features import ComplEx
from ampligraph.evaluation import evaluate_performance, mrr_score, hits_at_n_score
def main():
#加载Wordnet18数据集
X = load_wn18()
# 用pairwise损失函数初始化ComplEx模型
model = ComplEx(batches_count=10, seed=0, epochs=20, k=150, eta=10,
# 使用adam优化器,学习率为1e-3
optimizer='adam', optimizer_params={'lr':1e-3},
#使用pairwise损失函数,margin值为0.5
loss='pairwise', loss_params={'margin':0.5},
#L2正则,正则权重为1e-5
regularizer='LP', regularizer_params={'p':2, 'lambda':1e-5},
# 显示进度条
verbose=True)
#定义filter用于过滤替换头实体或尾实体生成负例时产生的正例样本
filter = np.concatenate((X['train'], X['valid'], X['test']))
#通过训练集、验证集训练模型
model.fit(X['train'],
early_stopping = True,
early_stopping_params = \
{
'x_valid': X['valid'], #验证集
'criteria':'hits10', #用hits10 criteria提前停止训练,防止过拟合
'burn_in': 100, #至少在100个epochs后才会停止训练
'check_interval':20, #每20个epochs验证一次
'stop_interval':5, #如果连续5次验证效果下降,则停止训练
'x_filter': filter, # 用filter过滤正例
'corruption_entities':'all', #使用所有实体
'corrupt_side':'s+o' #替换头实体或尾实体生成负例
}
)
#在测试集上进行评估
#可以通过filter_triples=None不进行过滤
ranks = evaluate_performance(X['test'],
model=model,
filter_triples=filter,
use_default_protocol=True, #分别替换头实体、尾实体
verbose=True)
# 计算并打印评价指标:
mrr = mrr_score(ranks)
hits_10 = hits_at_n_score(ranks, n=10)
print("MRR: %f, Hits@10: %f" % (mrr, hits_10))
# 输出: MRR: 0.886406, Hits@10: 0.935000
if __name__ == "__main__":
main()2、模型选择
from ampligraph.datasets import load_wn18
from ampligraph.latent_features import ComplEx
from ampligraph.evaluation import select_best_model_ranking
def main():
#加载Wordnet18数据集
X_dict = load_wn18()
model_class = ComplEx
#使用下面给出的模板进行网格搜索
param_grid = {
"batches_count": [10],
"seed": 0,
"epochs": [4000],
"k": [100, 50],
"eta": [5,10],
"loss": ["pairwise", "nll", "self_adversarial"],
#将参数映射到相应的类
"loss_params": {
#margin对应pairwise和adverserial loss
"margin": [0.5, 20],
#alpha对应adverserial loss
"alpha": [0.5]
},
"embedding_model_params": {
#在训练过程中使用所有实体生成负例
"negative_corruption_entities":"all"
},
"regularizer": [None, "LP"],
"regularizer_params": {
"p": [2],
"lambda": [1e-4, 1e-5]
},
"optimizer": ["adam"],
"optimizer_params":{
"lr": [0.01, 0.0001]
},
"verbose": True
}
#在超参数的所有可能组合上训练模型,并在验证集上验证模型,返回在训练集和验证集上重新训练的模型
best_model, best_params, best_mrr_train, \
ranks_test, mrr_test = select_best_model_ranking(model_class, # Class handle of the model to be used
# Dataset
X_dict['train'],
X_dict['valid'],
X_dict['test'],
# Parameter grid
param_grid,
#使用过滤集进行评估
use_filter=True,
#评估时替换头实体、尾实体
use_default_protocol=True,
#记录所有模型超参数和评估统计信息
verbose=True)
print(type(best_model).__name__, best_params, best_mrr_train, mrr_test)
if __name__ == "__main__":
main()3、保存、导入模型
import numpy as np
from ampligraph.latent_features import ComplEx
from ampligraph.utils import save_model, restore_model
#使用ComplEx模型
model = ComplEx(batches_count=2, seed=555, epochs=20, k=10)
#简单数据集
X = np.array([['a', 'y', 'b'],
['b', 'y', 'a'],
['a', 'y', 'c'],
['c', 'y', 'a'],
['a', 'y', 'd'],
['c', 'y', 'd'],
['b', 'y', 'c'],
['f', 'y', 'e']])
#训练
model.fit(X)
#预测
y_pred_before = model.predict(np.array([['f', 'y', 'e'], ['b', 'y', 'd']]))
print(y_pred_before)
#[-0.29721245, 0.07865551]
#保存模型
example_name = "helloworld.pkl"
save_model(model, model_name_path = example_name)
#导入模型
restored_model = restore_model(model_name_path = example_name)
#使用导入的模型进行预测
y_pred_after = restored_model.predict(np.array([['f', 'y', 'e'], ['b', 'y', 'd']]))
print(y_pred_after)
# [-0.29721245, 0.07865551]4、分割数据集
import numpy as np
from ampligraph.evaluation import train_test_split_no_unseen
from ampligraph.datasets import load_from_csv
#假设有一个知识图谱以(h,r,t)形式存储在“my_folder/my_graph.csv”文件中,
#加载数据集
X = load_from_csv('my_folder', 'my_graph.csv', sep=',')
#将三元组分割为训练集和测试集
#在此示例中,测试集只包括2个三元组
X_train, X_test = train_test_split_no_unseen(X, test_size=2)
print(X_train)
'''
X_train:[['a' 'y' 'b']
['f' 'y' 'e']
['b' 'y' 'a']
['c' 'y' 'a']
['c' 'y' 'd']
['b' 'y' 'c']
['f' 'y' 'e']]
'''
print(X_test)
'''
X_test: [['a' 'y' 'c']
['a' 'y' 'd']]
'''
#若想将图谱分割为训练集、验证集、测试集,需要分割两次,验证集和测试集分别含有2个三元组
X_train_valid, X_test = train_test_split_no_unseen(X, test_size=2)
X_train, X_valid = train_test_split_no_unseen(X_train_valid, test_size=2)
print(X_train)
'''
X_train: [['a' 'y' 'b']
['b' 'y' 'a']
['c' 'y' 'd']
['b' 'y' 'c']
['f' 'y' 'e']]
'''
print(X_valid)
'''
X_valid: [['f' 'y' 'e']
['c' 'y' 'a']]
'''
print(X_test)
'''
X_test: [['a' 'y' 'c']
['a' 'y' 'd']]
'''5、评估
filter_triples = np.concatenate((X_train, X_test))
ranks = evaluate_performance(X_test,
model=model,
filter_triples=filter_triples,
use_default_protocol=True,
verbose=True)
mr = mr_score(ranks)
mrr = mrr_score(ranks)
print("MRR: %.2f" % (mrr))
print("MR: %.2f" % (mr))
hits_10 = hits_at_n_score(ranks, n=10)
print("Hits@10: %.2f" % (hits_10))
hits_3 = hits_at_n_score(ranks, n=3)
print("Hits@3: %.2f" % (hits_3))
hits_1 = hits_at_n_score(ranks, n=1)
print("Hits@1: %.2f" % (hits_1))
'''
MRR: 0.25
MR: 4927.33
Hits@10: 0.35
Hits@3: 0.28
Hits@1: 0.19
'''四、tensorflow2-GPU运行Ampligraph
Ampligraph是基于tensorflow1.x开发的,由于tensorflow1.x和2.x版本不兼容,有一些1.x的函数被移除或是更换了函数名,在2.x环境下使用Ampligraph会报错。
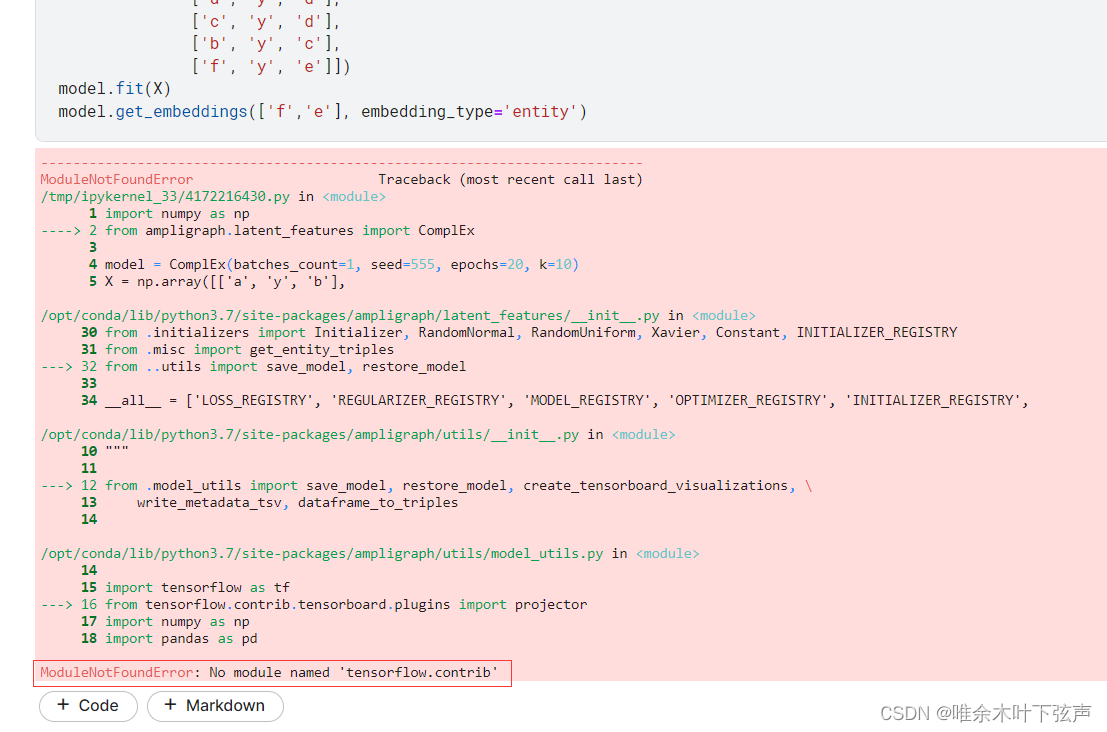
将不兼容的函数替换掉,并将“import tensorflow as tf”替换为以下代码:
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf即可在tensorflow2.x-GPU版本使用Ampligraph:
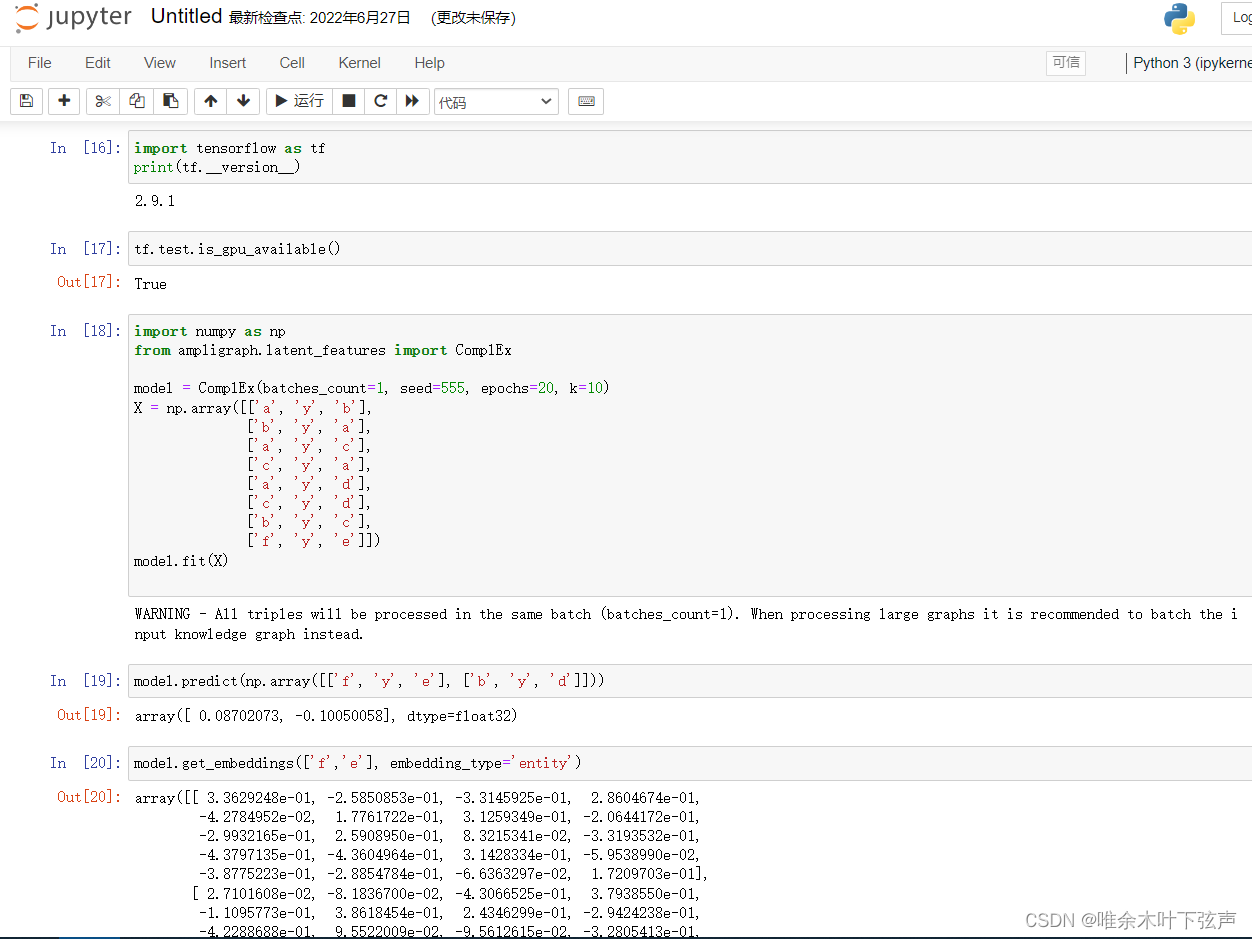
具体有哪些不兼容的函数我忘了,我把Ampligraph文件夹打了个包,有需要的可以自行下载替换,点击百度云链接,提取码:abcd。不过,我只修改了ComplEx模型的代码,其他模型如果运行出问题,可以再看着改改。