文章目录
- 前言
- 一、Bridge DMA
- 二、Convolution Pipeline
- 三、Convolution DMA
- 四、Convolution Buffer
- 五、Convolution Sequence Controller
- 六、Convolution MAC
- 七、Convolution Accumulator
- 八、MCIF
- 九、SRAMIF
- 总结
前言
本系列内容力求将nvdla的硬件设计和架构分析理清楚,如果有分析不对的请指出。
前面已经分析了一篇信号和寄存器的文章,NVDLA硬件信号和架构设计整理一
欢迎持续关注我对内核态代码的解读,链接分别如下:
系列文章1:NVDLA内核态驱动代码整理一
系列文章2:NVDLA内核态驱动代码整理二
系列文章3:NVDLA内核态驱动代码整理三
系列文章4:NVDLA内核态驱动代码整理四
系列文章5:NVDLA内核态驱动代码整理五
系列文章6:NVDLA内核态驱动代码整理六
其中系列文章3有大量关系架构部分的介绍。
我们把系列文章3:NVDLA内核态驱动代码整理三中的架构图搬出来:
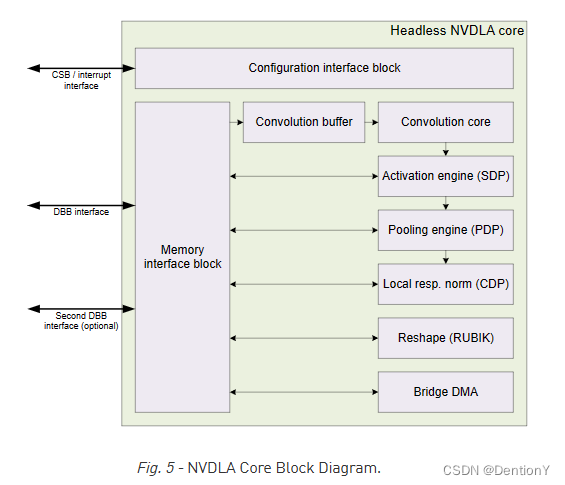
note:本文中的激活值、特征、特征值、输入、ACT均指向同一内容,不做区分。
一、Bridge DMA
为了利用片上SRAM,NVDLA需要在外部DRAM和SRAM之间移动数据,而Bridge DMA(BDMA)完全满足这个需求。其实现有两条独立的路径:1、将数据从外部DRAM复制到内部SRAM;2、从内部SRAM复制数据到外部DRAM。注意,两个方向不能同时工作。BDMA还可以将数据从外部DRAM移动到外部DRAM,或者从内部SRAM移动到内部SRAM。BDMA有两个DMA接口,一个连接外部DRAM,另一个连接内部SRAM。这两个接口都支持读写请求。两个接口的数据宽度均为512 bit,最大burst长度为4。
关于BDMA如何读取cube内(将cube理解成多个通道、长宽的激活值或者权重)的数据,官网是这么描述的:
In order to move all data in a cube, BDMA support line repeat which can fetch
multiple lines with address jumps between lines, reflect a surface. And also, BDMA
will support one more layer of repeat, that fetch of multiple lines can be repeated,
which reflect multiple surfaces, reflect a cube.
有两种模式:
1、BDMA支持line repeat,所谓的line repeat就是允许一次性取出多行,可以体现surface,行与行之间存在地址跳跃。具体怎么一个地址偏移的情况还得看BDMA相关的介绍或者源码;
2、BDMA支持one more layer of repear,允许重复取出多行,可以体现cube。
这里的line、surface和cube就是很典型的激活值与权重矩阵的1D、2D、3D要素。
关于BDMA的架构设计如下:

这里的MCIF的架构如下:

MCIF用于仲裁来自内部子模块的请求,并转换为AXI协议以连接到外部DRAM。MCIF将同时支持读和写通道,但一些NVDLA子模块将只有读要求,因此子模块和MCIF之间的接口将支持读、写或两者兼有。上图中的CDMA0和CDMA1将需要只读,其他5类子模块将同时需要读和写。
这里的SRAMIF的架构如下:

SRAMIF模块用于将内部子模块连接到片上SRAM。与MCIF类似,但总线延迟预计会更低。SRAMIF将同时支持读和写通道,但一些NVDLA子模块将只具有读要求,因此DMA Engine和SRAMIF之间的接口将支持读、写或两者兼有。CMDA0~1将只需要读通道,而其他5类子模块将同时需要读取和写入。
二、Convolution Pipeline
官网是这么概述Convolution Pipeline:
The Convolution Pipeline has five stages, which are: Convolution DMA, Convolution
Buffer, Convolution Sequence Controller, Convolution MAC and Convolution
Accumulator. They are also called CDMA, CBUF, CSC, CMAC and CACC respectively. Each
stage has its own CSB slave port to receive configuration data from the controlling
CPU. A single synchronization mechanism is used by all stages.
Convolution Pipeline(卷积流水线)由五级组成,分别是Convolution DMA(CDMA)、Convolution Buffer(CBUF)、Convolution Sequence Controller(CSC)、Convolution MAC(CMAC)和Convolution Accumulator(CACC)。以上概念的缩写将频繁出现在conv.c内核态驱动代码中。流水线设计架构图如下:

参照这里的介绍:
CDMA(Convolution DMA):DMA部件,用于从外部存储器中读取待卷积数据(包括图片、特征值、权重)
CBUF(Convolution Buffer):数据缓存
CSC(Convolution Sequence Controller):将待卷积的数据进行整形,以便更高效地利用CMAC
CMAC(Convolution MAC):卷积乘加阵列,由大量的乘加部件组成,数量可以配置(8~4096)
CACC(Convolution Accumulation):卷积累加器,利用CMAC进行卷积运算时,会产生很多中间结果,这些中间结果在累加器中持续累加,得到完整的卷积结果后再送出,以此可以减少对外部存储部件的需求。
NVDLA的卷积计算模式有三种:
1、Direct convolution for feature data, or DC mode
2、Convolution of image input, or image input mode
3、Winograd convolution, or Winograd mode
详细细节可以看:NVDLA内核态驱动代码整理三
卷积流水线包含用于int16或fp16的1024个MAC,以及用于部分和存储的32 逐元素累加器阵列。MAC资源也可以被配置为2048个INT8格式的MAC阵列。此外,CBUF中有512KB的SRAM,提供输入权重和激活存储。
2.1 Direct Convolution
首先回顾一下卷积,包括膨胀卷积、padding等元素。从官网扒图,如下:
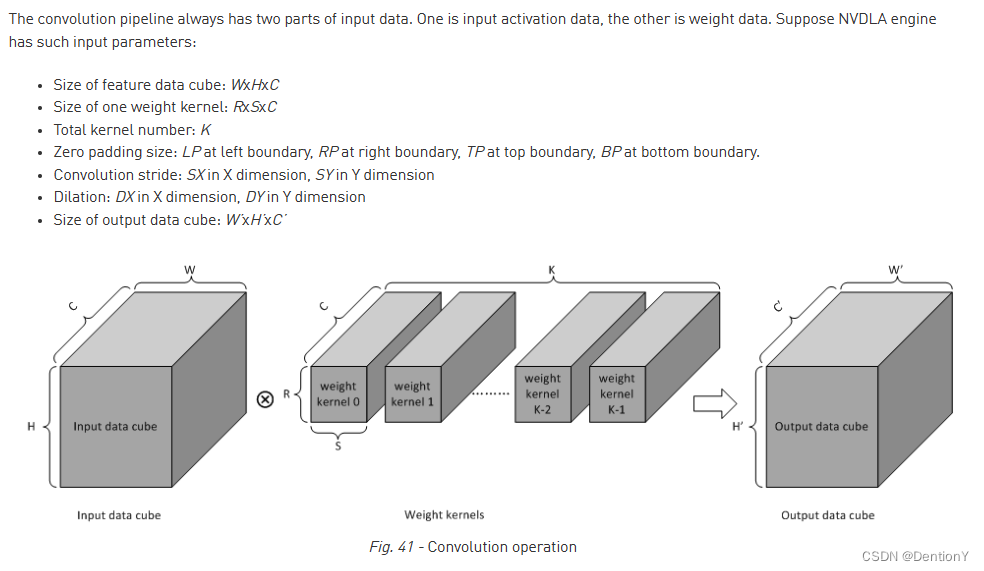
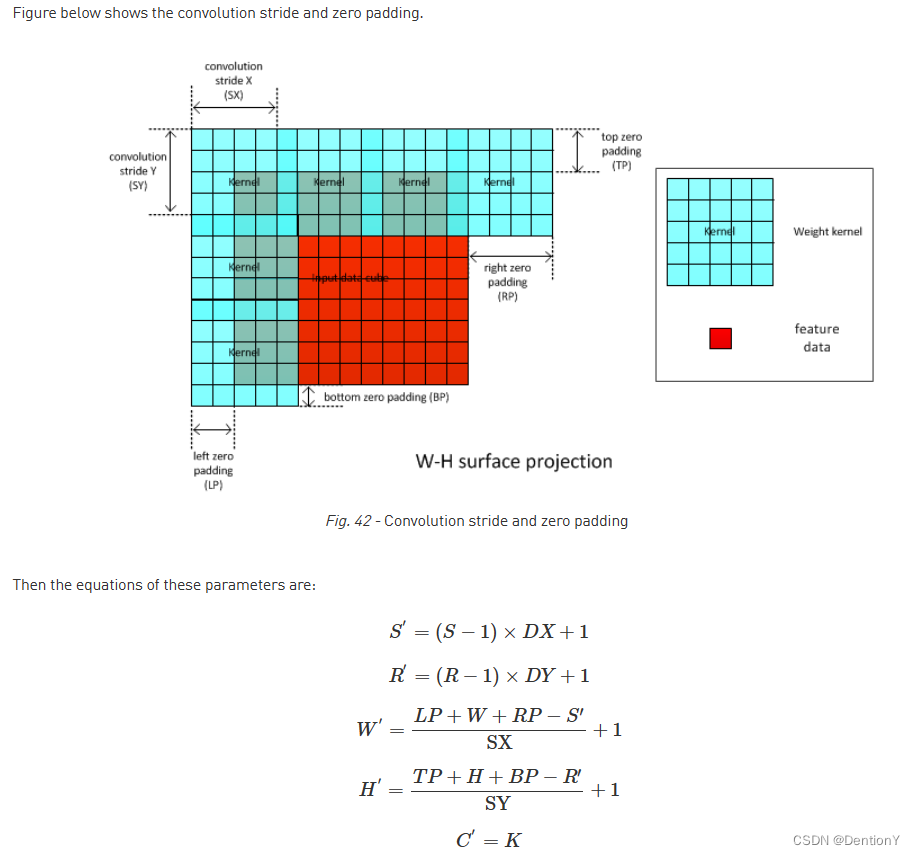
这边可能比较难以理解S'和R',建议看这里关于膨胀卷积的示意图,很容易理解为什么膨胀卷积后的宽度或者高度都被压缩了。
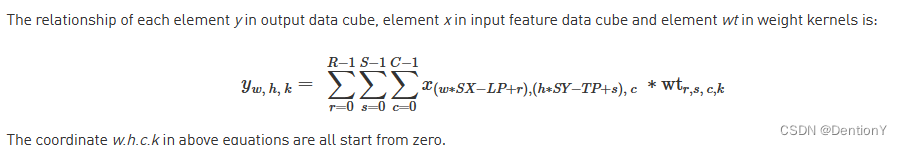
接下来进入Direct Convolution,The key idea of direct convolution is to split the multiplication operations from each convolution kernel into groups such that each group contains 64 multiplications.,所以直接卷积的核心是将卷积中的乘法操作分解为groups,每个groups包含64个乘法。
那关于细节的描述是:
1、Distribute all MACs hardware into 16 sub units. One sub unit is called MAC Cell, and has hardware for 64 int16/fp16 MACs, or for 128 int8 MACs.
# 将所有的MACs硬件部分分解为16个子单元,每个子单元是MAC Cell且含有64个INT16/FP16的MACs或者128个INT8的MACs。
2、The assembly of MAC Cells is called MAC Cell Array.
# MAC Cells的聚合被称为MAC Cell Array
3、Divide all input data cubes into 1x1x64 element small cubes for int16, fp16 and int8.
# 将所有的input data cube分解为若干个1x1x64的element small cubes,数据格式是INT16/FP16/INT8
4、Divide all weight data cubes into 1x1x64 element small cubes for int16, fp16 and int8.
# 将所有的weight data cube分解为若干个1x1x64的element small cubes,数据格式是INT16/FP16/INT8
5、Multiply one small input data cube by one small weight data cube, and add products together. These multiplications and additions are performed within one MAC cell.
# 将input data cude和weight data cube相乘,并且和进行相加。上述乘法和加法操作都是在一个MAC Cell中实现的。
6、Combine these compute operations into 4 operation levels, which are atomic operation, stripe operation, block operation and channel operation.
# 将上述计算操作融合到4个操作层次中,包括atomic operation、stripe operation、block operation和channel operation。
把几个概念整理一下:
1、MAC Cell:所有的MACs硬件部分分解得到的子单元,总共有16个。每个MAC Cell含有64个INT16/FP16
的MACs或者128个INT8的MACs。在一个MAC Cell中实现input data cude和weight data cube相乘,并
且和进行相加。我们不妨译为`MAC单元`
2、MAC Cell Array:MAC Cell的聚合体。我们不妨以为`MAC单元阵列`
3、1x1x64 element small cubes:来源是input data cubes和weight data cubes。
接下来就围绕四个操作层次展开。
2.1.1 Atomic Operation
官网对于Atomic Operation的解释如下:Atomic Operation是Direct Convolution的基础步骤。在一个Atomic Operation中,每个MAC单元缓存单个weight kernel的一个1x1x64 weight data cube。因此,16个MAC单元缓存16个int16/fp16 weight kernel或32个int8 weight kernel。feature data的一个1x1x64 cube由所有MAC单元共享。MAC单元执行上述规则5中提到的计算。每个MAC单元的输出称为部分和。此操作需要1个周期才能完成,因此每个周期产生16个部分和。部分和被送到CACC(Convolution Accumulation)卷积累加器进一步计算。注意到,卷积核的分组是按照通道每64个数分割。所以官网给出了如下图:
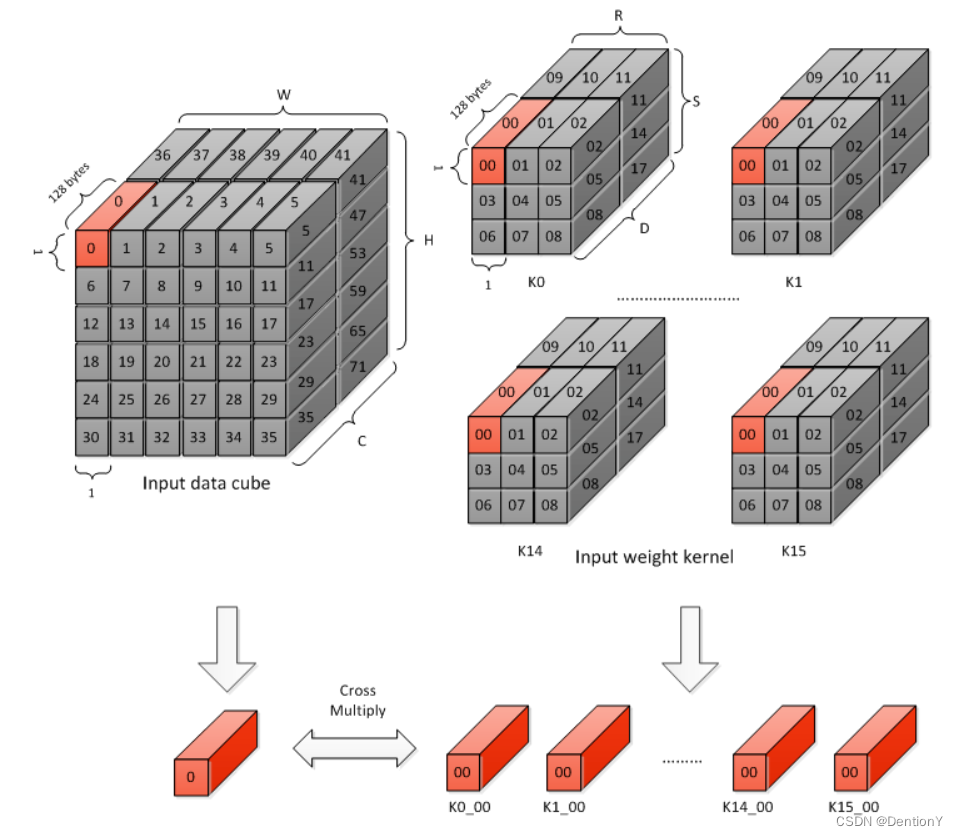
图示从K0、K1到K14、K15是表明有16个1x1x64卷积核被放到16个MAC Cell上,输入的Input data cube被这16个MAC Cell共享。因为使用的数据格式是INT16,所以占用的字节数数是64*16/8=128Byte,那么每一个MAC Cell内完成乘累加,16个MAC Cell最后传送出来16个部分和。
2.1.2 Stripe Operation
Stripe Operation其实就是若干个卷积的一组Atomic Operation。在一个Stripe Operation操作期间,MAC Cell Array中的权重数据保持不变。输入数据沿Input Data Cube滑动。Stripe Operation的长度有限制,下限16是因为需要去获取用于下一个Stripe Operation所需权重的内部带宽。由于CACC(Convolution Accumulation)卷积累加器中的缓冲区大小限制,使得Stripe Operation的长度上限为32。在某些极端情况下,可支持的长度可能小于下限。
官网给出了下图示意:
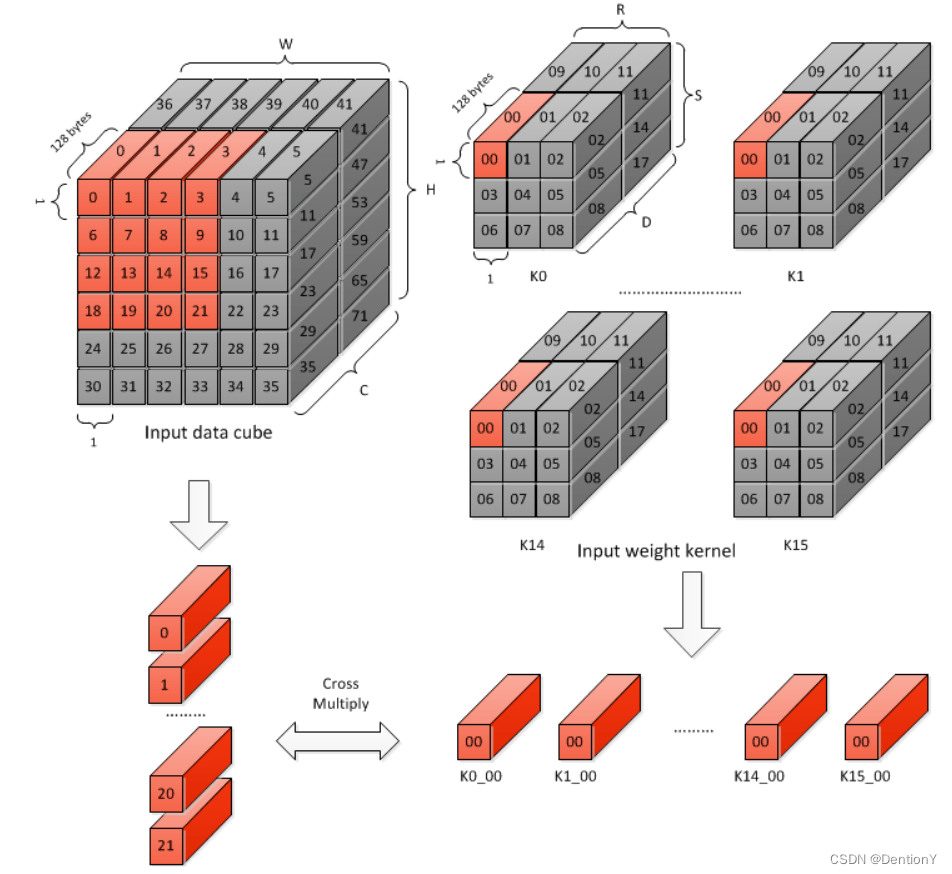
很容易看明白在填充完16个MAC Cell以后,一一进入MAC Cell Array的Input data cube是按照行的形式滑动,所以综合2.1.2可以暂时总结一下计算优先权:
1、权重:优先选择单个Kernel的Channel,为了实现并行,使用多个Kernel。
multi-Channel-in-Kernel with multi-Kernel and HW mapped fixed
2、激活值或者特征图数据:优先Channel,随后计算结束后,按照image内左右-上下滑动选择。
multi-Channel-in-Image with one-Image and HW mapped flushed
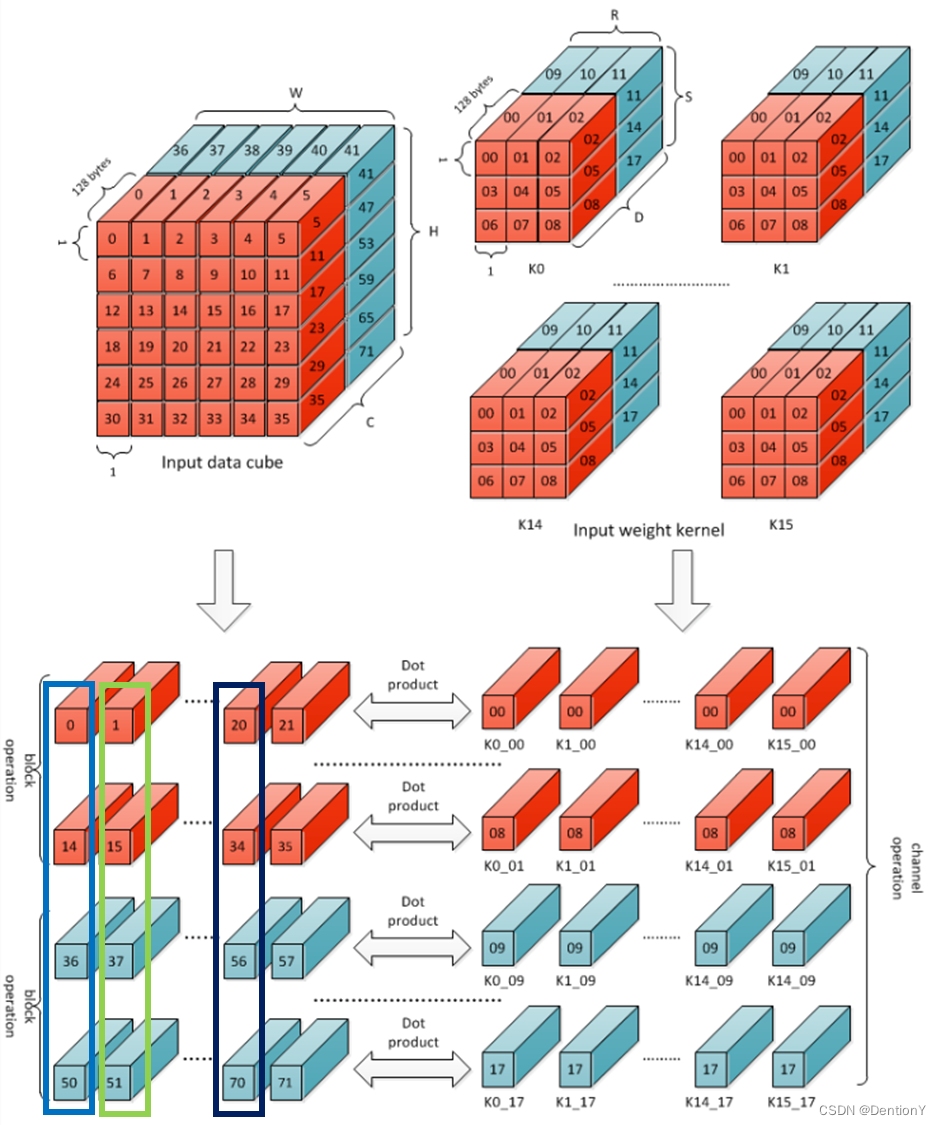
2.1.3 Block Operation
在Block Operation操作期间,权重中的每个Filter都使用RxSx64个元素,以及大小适当的Input data cube。
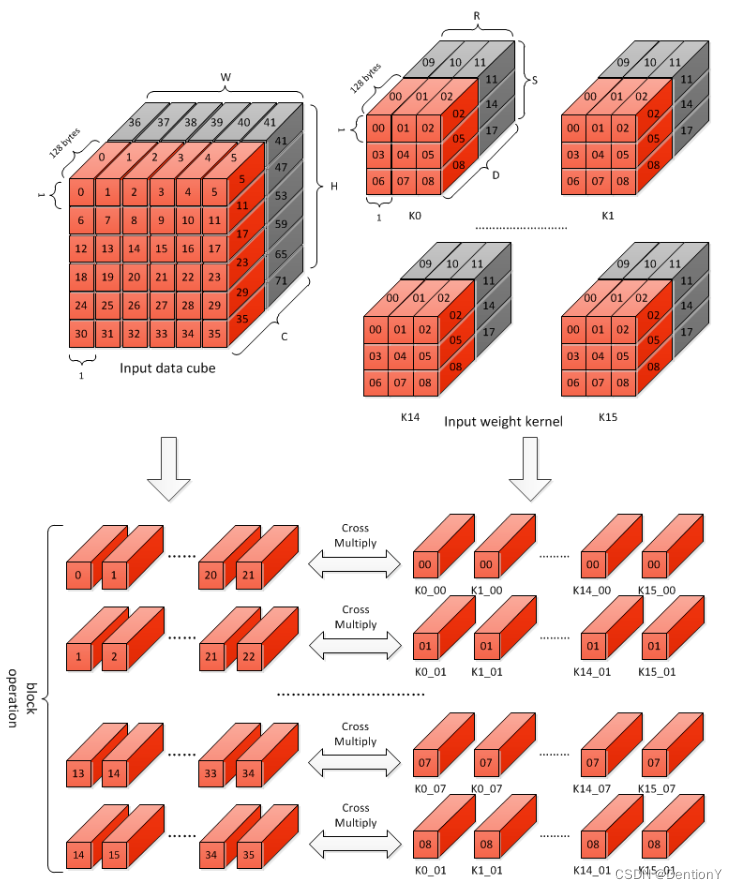
根据该图,可以很清晰地理解:对于权重中序号为1的元素,在输入或者激活值内被卷积的对象是0~3、6~9、12~15、18~21;对于权重中序号为2的元素,在输入或者激活值内被卷积的对象是1~4、7~10、13~16、19~22;对于权重中序号为3的元素,在输入或者激活值内被卷积的对象是2~5、8~11、14~17、20~23。到此为止,横行遍历完。对于纵向,道理类似,不再赘述。
那么哪一块内应当累加?
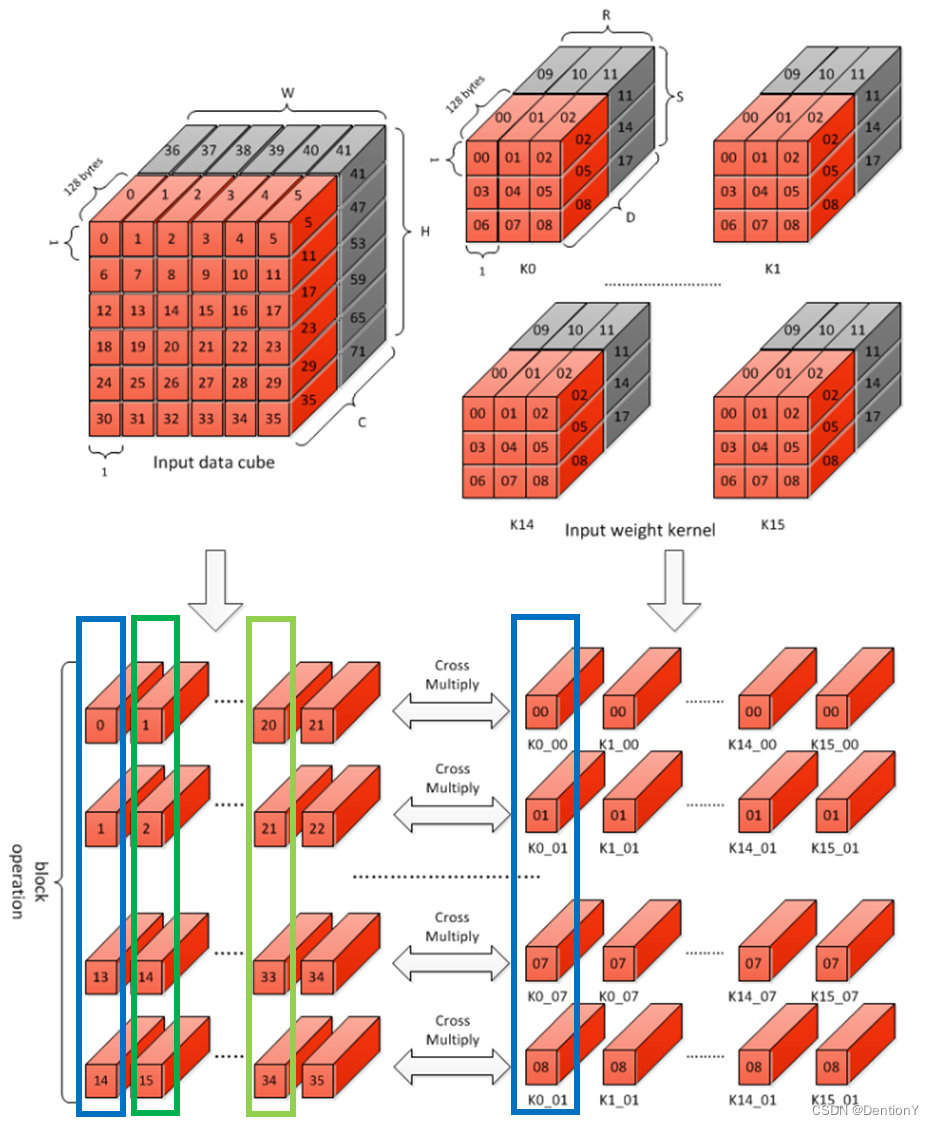
图示卷积的蓝色框其实就是复原了一组多通道的卷积核,图示激活值的若干框各自组成了可以被卷积的激活值小框。因此被卷积后的若干激活值小框内的数值可以累加。按照官网的说法,这样得到的累加值被称为Accumulative Sum,不同于前面提到的Partial Sum。
2.1.4 Channel Operation
Channel Operation则是更高级的操作,图示:
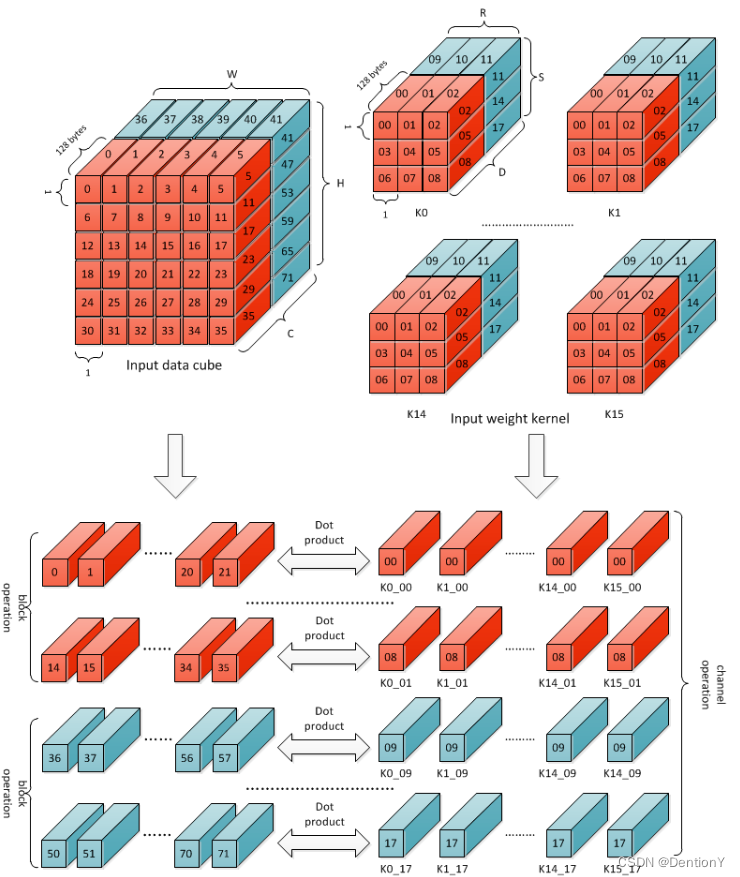
那么完成的累加操作应该是相同列,如下:
2.1.5 4层操作总结
四层操作总结下来就是:

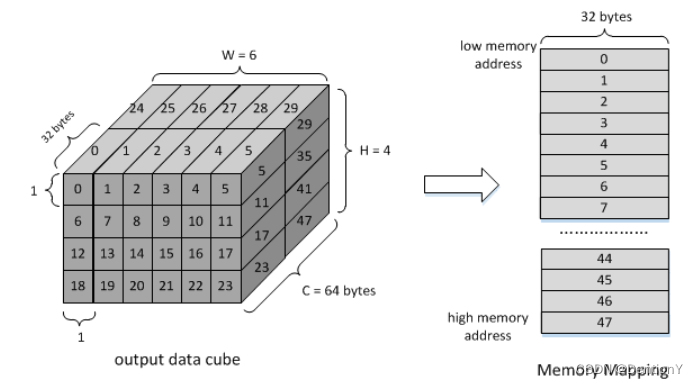
2.1.6 Output Sequence
每个操作中提到的序列主要用于输入特征数据和权重数据。输出数据的顺序为C’(K’) -> W -> H -> C(K),这个顺序其实就是上方我画的2.1.5的图。这里C’或K’是指内核组大小,对于int16/fp16为16,对于int8为32。
2.2 Winograd Convolution
Winograd Convolution用于减少Direct Convolution常用的im2col与GEMM方法下的乘法次数,NVDLA官网只支持3x3卷积核大小的Winograd Convolution。官网给出了Winograd Convolution的算法描述:

但是这里太抽象,有位博主在这篇文章下解释得很不错。因为如果直接套用若干个矩阵相乘,你会发现乘法数量远远高于原来两个矩阵相乘的乘法,那么问题出在哪里呢?其实答案特别直观:我贴出该文章下的一张图:

核心就在于几个常数矩阵有很多0和1,因此可以避开一堆乘法,固定用加法和减法来表达。那么总的乘法次数其实就是逐点乘法的16次乘法操作,而不是原来的滑动卷积需要的4*9=36次乘法。因此也就得到了36/16=2.25这个数值,和官网的一段描述对应起来:
Only 16 multiplications are required to calculate 4 results for a 3x3 kernel, while
in direct convolution mode 36 multiplications are required. Winograd is therefore
2.25 times the performance of Direct Convolution.
我顺带贴一下Winograd Convolution的几个特点:
1、卷积的stride等于2时加速收益不高
2、深度可分离卷积用Winograd不划算
3、Winograd卷积由于一些系数是是除不尽的, 所以有一定的精度损失
4、tile块越大, 加速效果越好
官网声明,在NVDLA Engine运行起来之前,软件部分应该实现权重矩阵的转换。另外,与Direct Convolution不同的是,Winograd Convolution将卷积核和激活值分割为4x4x4的cube。接下来谈谈NVDLA是如何实现的?我们先贴一张原汁原味的图:

为了对比,我们把公式再搬出来:
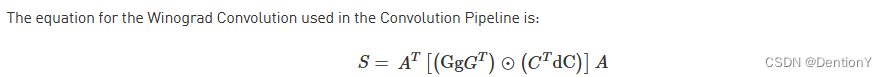
计算步骤:
1、软件先计算权重的转换:C'dC;
2、硬件完成激活值的转换:GgG',我们将这一步和上一步在MAC Cell Array中进行逐点相乘;——这一步被
称为PRA。
3、硬件完成后2得到了4x4x4的tensor,其中维度表示是(W, H, C)。Phase 1完成的步骤是C方向的累
加,从而得到4x4的matrix。
4、硬件完成3得到了4x4的matrix,我们记为R。随后需要回到MAC Cell Array中进行矩阵乘,完成A'*R
得到2x4的matrix,我们记为S。
5、硬件完成4得到了2x4的S matrix,随后需要回到MAC Cell Array中进行矩阵乘,完成S*A得到2x2的最
终结果。
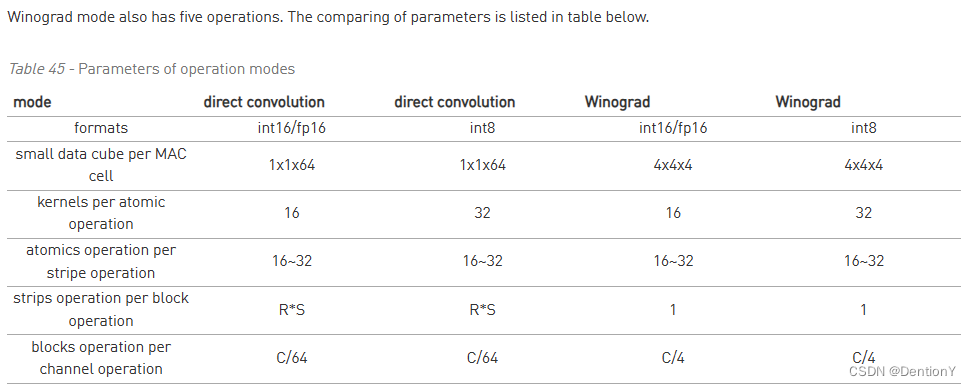
和Direct Convolution类似,Winograd Convolution也有若干层Operation,如下:
2.3 De-Convolution
反卷积这部分我很少涉及,因此展开不讲。感兴趣的可以阅读官网的详细资料。
2.4 Convolution with Image Input Mode
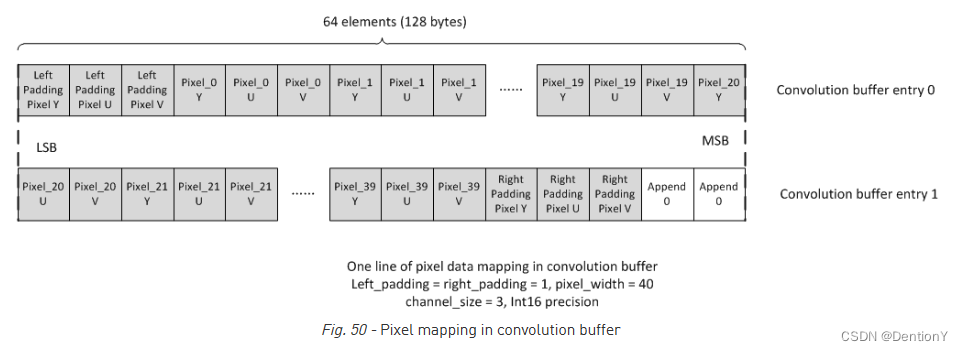
NVDLA只支持Direct Convolution下的Image Input Mode,根据存储容量大小选择放部分或者全部的image surface。需要特别提及的是卷积缓冲区中的数据映射。左、右填充和输入像素行的所有元素都紧凑地驻留在CBUF entry中。见下图,如果通道大小为4,则元素映射顺序为R(Y)->G(U)->B(V)->A(X)。如果通道大小为3,则顺序为R(Y)->G(U)->B(V)。
当然还提到了和Direct Convolution for Feature Data模式,也就是所谓的DC模式,这两者之间的区别:

2.5 Channel Post-Extension
前面提到NVDLA有16个MAC Cell,每一个MAC Cell有64个MAC。之所以提出Channel Post-Extension的原因是在卷积通道中,一个Atomic Operation需要64个通道方向上的元素(不包括Winograd模式)。如果Input Data Cube的通道大小小于64,则MAC在每个周期中不是100%被利用,因此为了提升MAC利用率,使用了调整硬件通道数的方案。具体的实施方案是什么呢?举一个非常浅显易懂大的例子,如果当前卷积核通道只有32个的时候,复制同样的32个卷积核通道并放到64个MAC中,那么传入的激活值矩阵可以使用两条相邻的Stripe。关于Post-Extension的系数可以取2或者4.

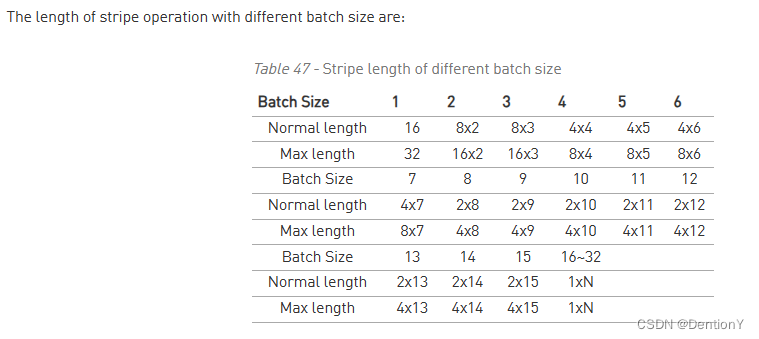
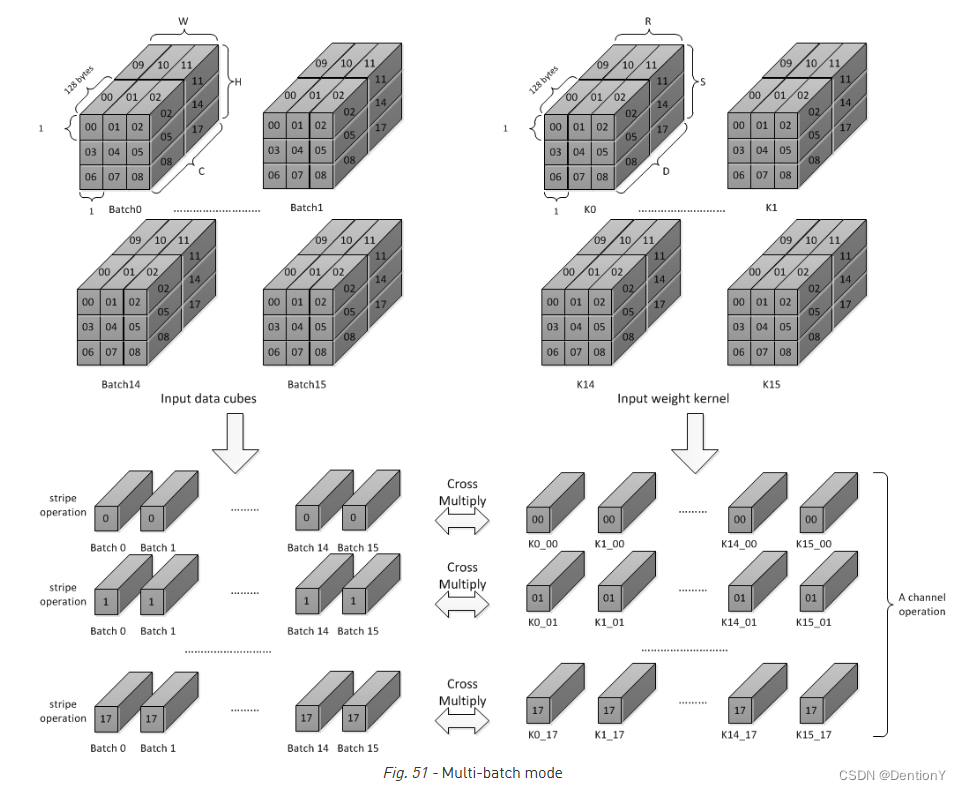
2.6 Multi-Batch
NVDLA之所以引入Multi-Batch Mode的原因是FC层的权重对于任何一个输出节点来说都只用一次,然而更换下一个输出节点的权重需要16个周期,因此如果当前只处理一张图片,那么结果就是在FC层出现了MAC Cell Array利用率不高的问题,理论计算是1/16=6.25%。但如果同时处理多张图片,那么当图片足够多,如果有16张图片进行处理,即使最慢的权重传入,也可以完成权重传入的隐藏,同时复用上一批FC层的权重数据。
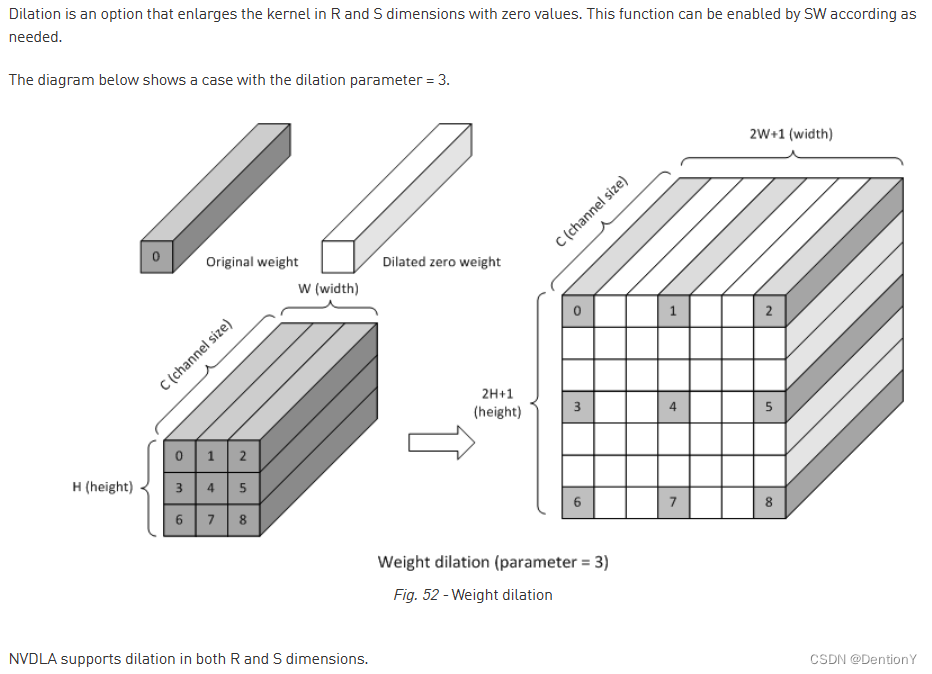
2.7 Dilation
NVDLA支持卷积核R和S的膨胀卷积,NVDLA的膨胀卷积只支持Direct Convolution,不支持Winograd Convolution和Image Input Mode。虽然膨胀卷积使得卷积核扩大了感受野,但是这个感受野的扩大也仅仅来自于当前的单帧图片,不如空间和通道方向上的注意力机制的全局效果更好。此外,膨胀卷积和类似的可变形卷积一样都需要额外的存储寻址成本和存储容量,对硬件不友好。因此现在主流的目标检测方案几乎不涉及膨胀卷积。
2.8 Power Consideration
NVDLA支持卷积流水级的时钟门控。
Convolution pipeline supports clock gating for each major pipeline stage. If the
pipeline stage is idle and no valid HW-layer is available, the data path of pipeline
stage will be clock gated.
三、Convolution DMA
3.1 Overall
回到经典老图,看一下CDMA的位置在哪里。
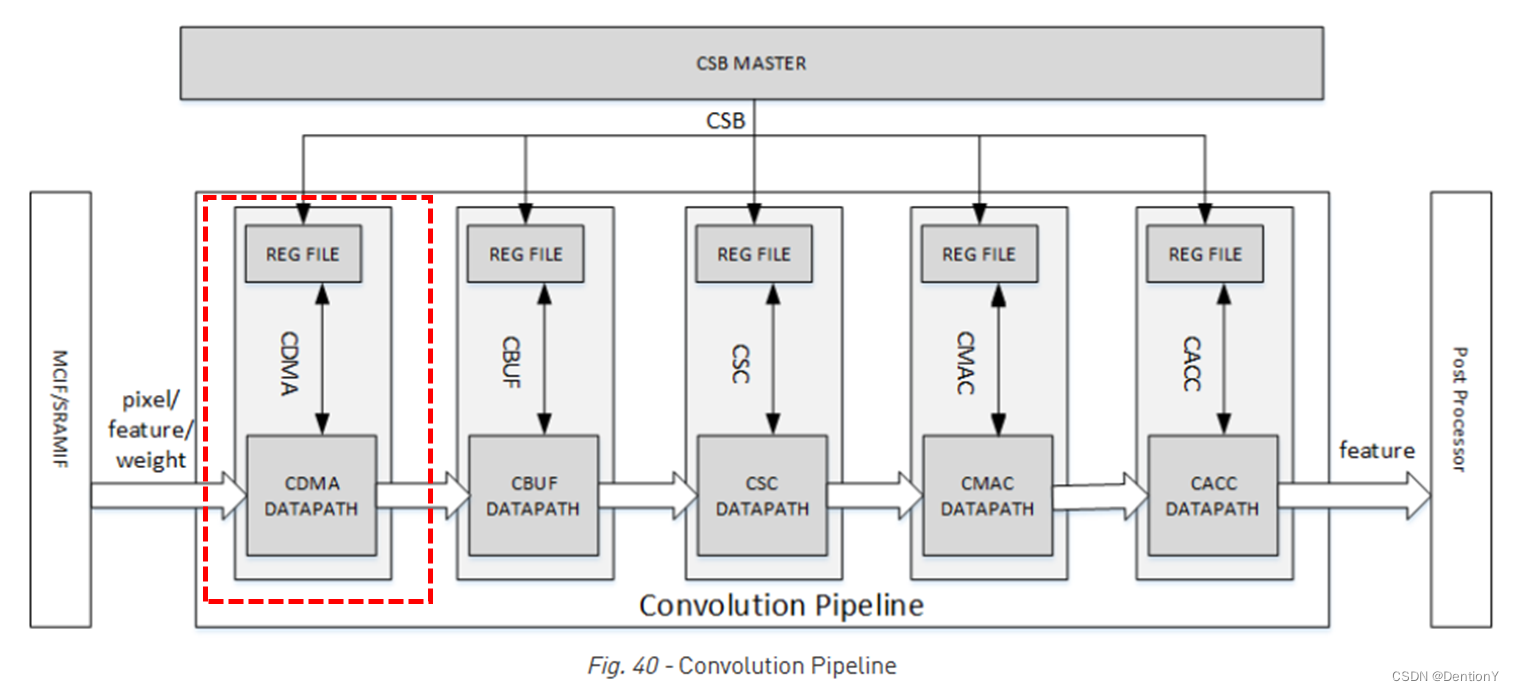
CDMA用于从外部存储器中读取待卷积数据(包括图片、特征值、权重),它从SRAM/DRAM中获取用于卷积操作的数据,并按照Convolution Engine所需的计算顺序将其存储到CBUF中。支持的输入格式有:Pixel data、Feature data、Uncompressed/compressed weight、WMB和WGS。
关于WMB和WGS的描述可见这里:
Sparse algorithm uses one-bit tag to indicate a weight element
is zero or not. Bit tags of one kernel group compose a weight
mask bit group, or WMB. WMBs reside in a dedicate memory
surface. Since 0 values are marked by bit tags (assign 0 to
corresponding bit), they can be removed from original weight
memory surface. A third memory surface recodes remaining byte
number of each kernel group (WGS).
解释解释就是如果用了权重的稀疏性,那么稀疏算法会使用1bit的标记来指示权重元素是否为零。那么很显然要存储两份东西,第一份是所有的标记,也就是tag,存储tag的专用存储被称为WMB;第二份是具体的数值,这个交给了第三方存储,这个存储被称为WGS。
好,扯回来接着唠CDMA。两个读通道从CDMA连接到AXI接口。这些是权重读通道和数据读通道。要获取上面列出的输入格式,通道将针对该格式进行配置。下表记录了读通道映射的输入数据格式。
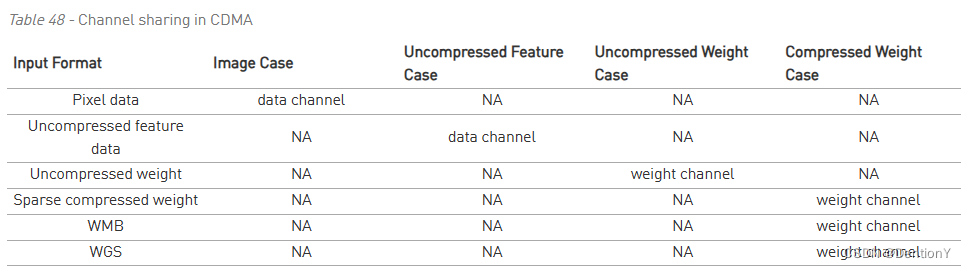
当然了,CDMA只支持读请求,且支持CDMA访问的存储都是64byte对齐。看一下架构图:

CDMA由3个子模块组成,用于获取像素数据或特征数据:CDMA_DC、CDMA_WG和CDMA_IMG。 这些子模块的过程类似,但不同之处在于它们如何将数据排序到CBUF RAM中。在任何时候,只有一个子模块被激活来获取像素/特征数据。
3.2 CDMA_DC/CDMA_WG/CDMA_IMG的原理
以CDMA_DC为例,其流程如下:
1、检查Convolution Buffer(CBUF)的状态是否有足够的可用空间
2、生成读事务
3、在Shared Buffer中缓存特征数据
4、将feature cube按照正确顺序进行重排
5、生成CBUF写入地址
6、将特征数据写入CBUF
7、更新CDMA_STATUS子模块中的状态
然后看下CMDA_WG和CDMA_IMG两个模块的命名,很容易发现这俩DMA分别用于Winograd Convolution和Direct Convolution for Image Input Mode两种卷积模式。关于CDMA_WG、CDMA_IMG、CDMA_DC、CDMA_WT之间的区别如下:
1、CDMA_WG与CDMA_DC具有非常相似的结构和功能。然而,CBUF中得到的特征数据组织方式是不同
的。因此CDMA_WG有一个特殊的获取序列。
2、CDMA_IMG从外部存储器获取像素数据。它根据数据格式生成地址,对像素元素重排,并将它们写入
CBUF。
3、仅CDMA_DC支持multi-batch处理模式。最大batch大小可达32。
4、CDMA_WT与其他DMA相比,可以同时支持三个读取流。如果输入权重格式未压缩,则仅获取权重数据。如
果输入的权重格式是压缩的,则权重、WMB和WGS都会被获取。关于输入先后的竞争问题:如果输入权重数据
被压缩,则启用两个仲裁器来确定读取流的顺序。 首先,加权循环仲裁器批准来自权重流或WMB流的请求。
然后获胜者通过静态优先级仲裁与 WGS 请求流竞争。 WGS 始终具有优先权。最终获胜请求发送到权重通
道进行数据获取。
5、那么怎么知道当前数据生命周期结束?CDMA维护CBUF中权重缓冲区和输入数据缓冲区的状态。CDMA和CSC中有两份状态副本。通过两个模块交换信息,从而决定何时获取新的特征/像素/权重数据。
3.3 Power Consideration
DMA使用了时钟门控,因此在空闲状态下可以不用,but,DMA下的子模块regfile并不被允许时钟门控。
四、Convolution Buffer
话不多说,还是先看位置在哪里?
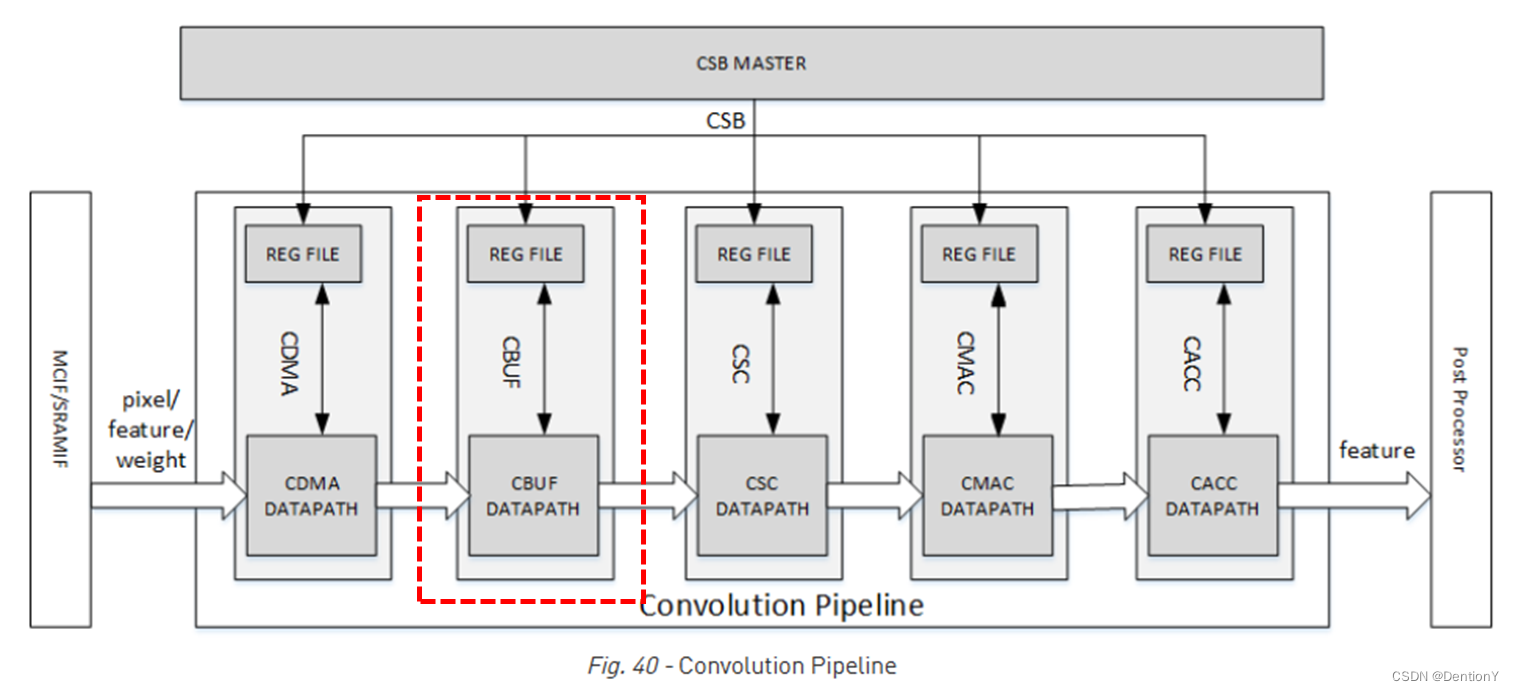
4.1 Overall
CBUF总共包含512KB的SRAM。SRAM缓存来自CDMA的输入像素数据、输入特征数据、权重数据和WMB数据,并由CSC模块读取。CBUF有2个写端口和3个读端口。CBUF包含16个32KB的存储单元。每个存储单元由2个512-bit wide、256 entry双端口SRAM组成。架构如下图所示:如果权重被压缩,则将bank15分配给WMB缓冲区,而另外2个缓冲区可以使用bank0~bank14;如果权重未被压缩,则WMB缓冲区不会分配给任何存储单元。在这种情况下,数据缓冲区和权重缓冲区可以充分使用所有16个存储单元。如果所需的存储单元总数少于16个,则剩余存储单元不被使用。
那么怎么更新呢?其实就是采用了环形覆盖的策略。每个缓冲区都充当循环缓冲区。新的输入数据/权重/WMB具有增量入口地址。如果地址达到最大值,它将回绕到零,然后再次开始增加。
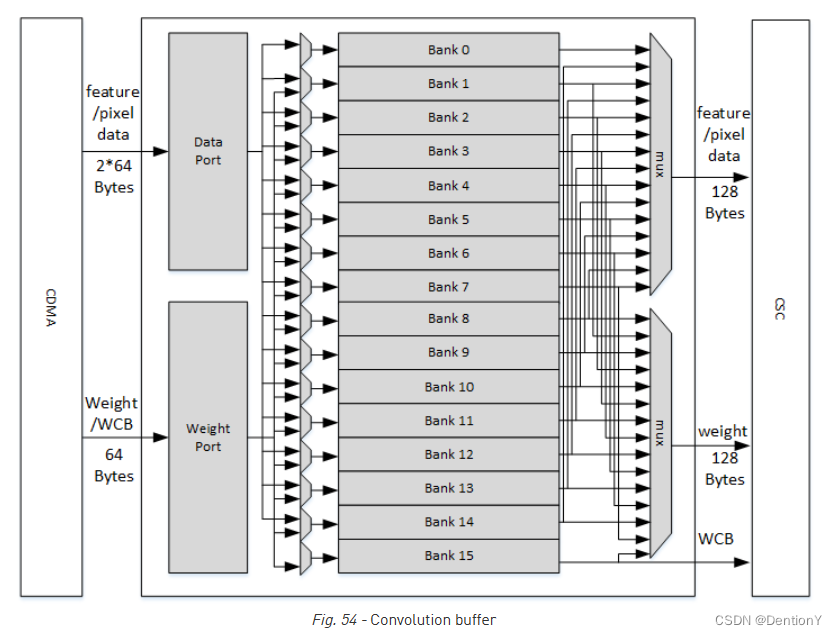
4.2 Power Consideration
卷积缓冲器对SRAM之外的数据路径中的寄存器应用时钟门控。 当卷积缓冲器数据路径空闲并且可编程寄存器没有可用的硬件层时,其时钟由SLCG门控。
五、Convolution Sequence Controller
还是先看位置:
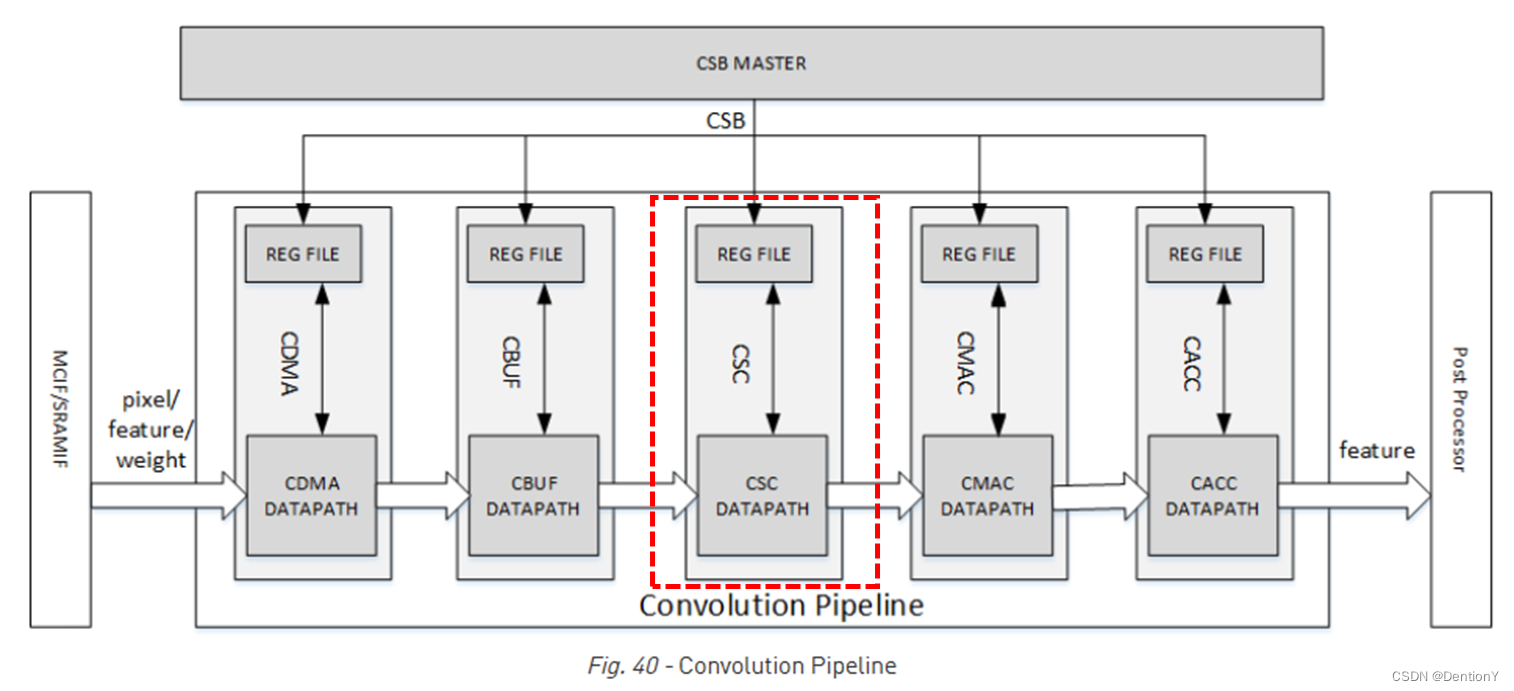
5.1 Overall
CSC负责从CBUF加载输入特征数据、像素数据和权重数据并将其发送到CMAC。CSC包括3个子模块:CSC_SG、CSC_WL和CSC_DL。
具体架构如下:

1、CSC_SG:convolution sequence generator,卷积序列生成器。该模块生成序列来控制卷积运算。
2、CSC_WL:convolution weight loader,卷积权重加载器。它从CSC_CG接收数据包,从CBUF加载权重
并进行必要的解压缩并将其发送到CMAC。它维护权重缓冲区状态并与CDMA_WT通信以保持状态最新。
3、CSC_DL:convolution data loader,卷积数据加载器。该模块包含执行特征/像素加载序列的逻辑,
从CSC_SG接收数据包、从CBUF加载特征/像素数据并发送到CMAC。它还维护数据缓冲区状态并与CDMA通信以
保持状态最新。对于Winograd模式,它还执行PRA(预加法)对输入的特征数据进行变换。
5.2 CSC_CG的工作原理
那么CSC_CG是如何工作的?
1、轮询CBUF中是否有足够的数据和权重
2、生成一对序列包,包括权重加载包和数据加载包。每个包代表一个Stripe Operation。
3、将两个包分别推入两个FIFO。
4、权重计数器、特征/像素计数器均向下计数。
5、当计数器达到零时,检查来自CACC的信号是否有空闲,如果空闲则进入6。
6、如果一切条件准备就绪,则将权重和特征发送给CSC_WL和CSC_DL。
5.3 Power Consideration
CSC对数据路径中的寄存器使用了时钟门控。
六、Convolution MAC
还是先看CMAC模块所处的架构位置!
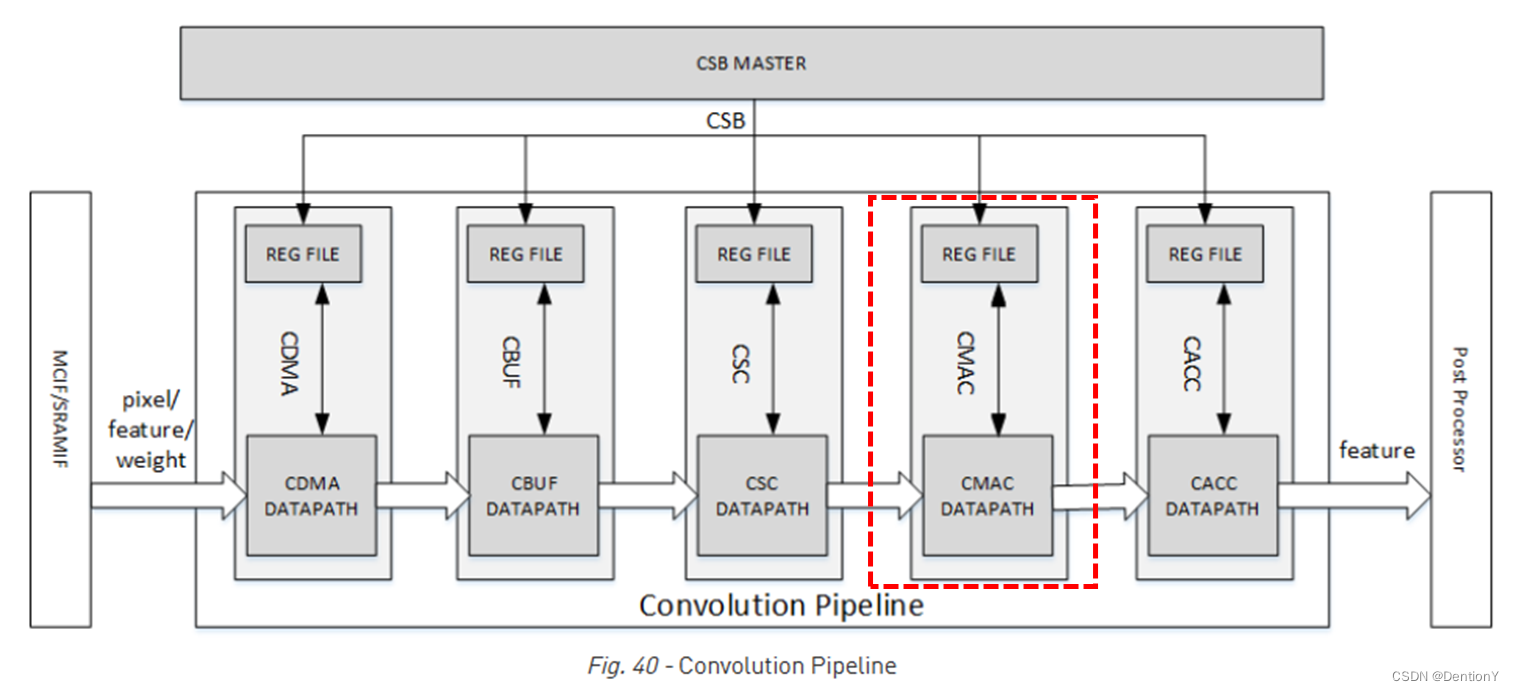
6.1 Overall
CMAC模块从CSC接收输入数据和权重,执行乘法和加法,并将结果输出到CACC。 当在 Winograd模式下工作时,CMAC对输出执行POA(后加法),将结果转换回标准激活格式。CMAC有16个相同的子模块,称为MAC单元。每个MAC单元包含64个用于int16/fp16的16位乘法器。它还包含72个用于Winograd POA的int16/fp16加法器。每个乘法器和加法器可以分成两个int8 的计算单元。流水线深度为7个周期。
CMAC设计了一个bypass,用于传递开始和结束操作标志的状态。注意!实现该操作需要4个周期。为了物理设计优化,CMAC分为两部分:CMAC_A 和CMAC_B。每个部分都有一个单独的 CSB接口和regfile。

6.2 Power Consideration
CMAC支持对单个CMAC单元进行时钟门控。
七、Convolution Accumulator
这是卷积流水线的最后一级,看一下所处位置:
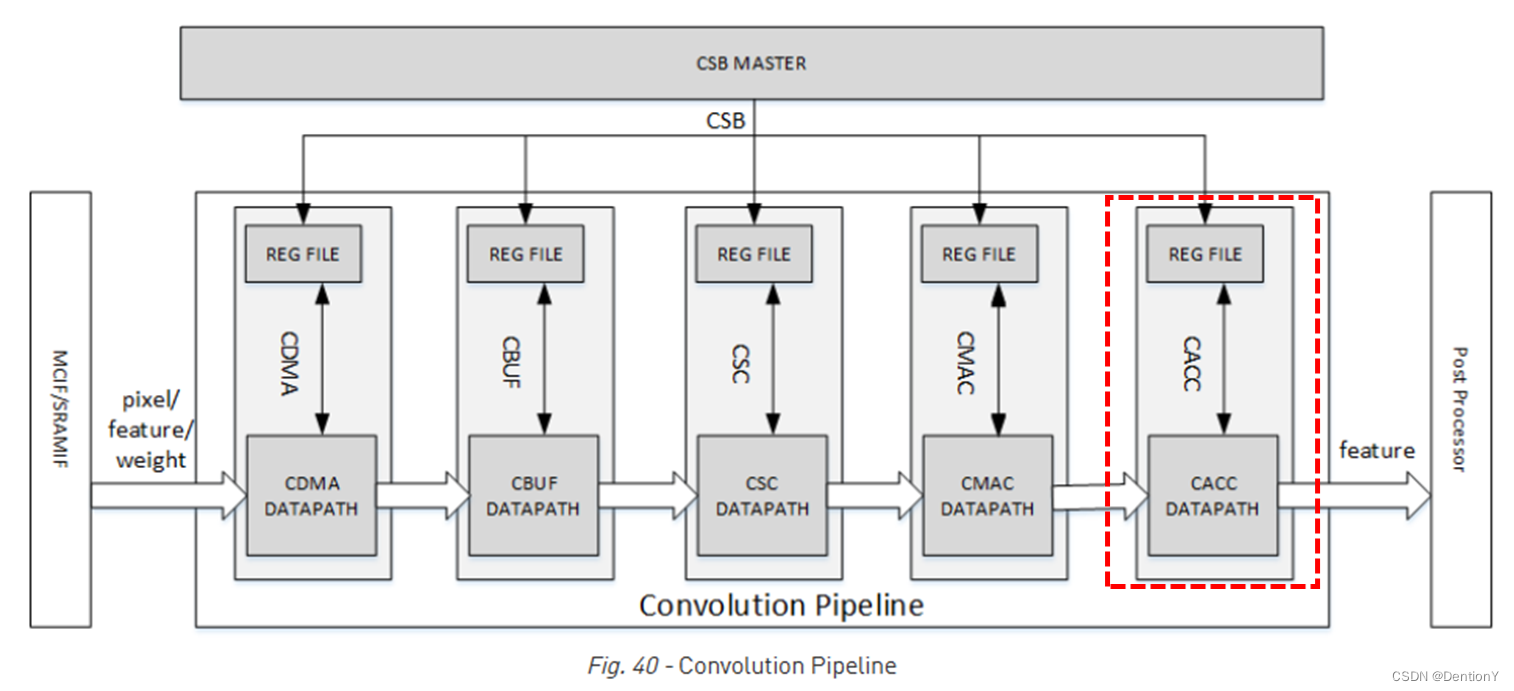
7.1 Overall
CACC是CMAC后的卷积流水线阶段,对来自CMAC的部分和进行累加,并在发送到SDP之前对结果进行舍入。此外,CACC的存在可以缓解卷积流水线的峰值吞吐量压力。CACC和SDP的位宽是32。CACC包括Assembly SRAM Group、Delivery SRAM Group、加法器阵列adder array、截断阵列truncating array、valid-credit controller和检查器checker。

下面介绍CACC的工作流程:
1、从Assembly SRAM Group中预取累加值。
2、当部分和到达时,将它们与累加和一起发送到加法器数组。如果部分和来自第一个Stripe Operation,则累加和应为0。
3、从加法器阵列的输出端收集新的累加和,并存入Assembly SRAM Group。
4、重复以上步骤1~步骤3,直到完成一个Channel Operation。
5、如果完成Channel Operation,加法器的输出将被舍入。
6、收集上一步的结果并将其存储到Delivery SRAM Group中。
7、从Delivery SRAM Group加载结果并将其发送到SDP。
关于2个存储的介绍如下:

部分和的精度和加法器的分配如下:
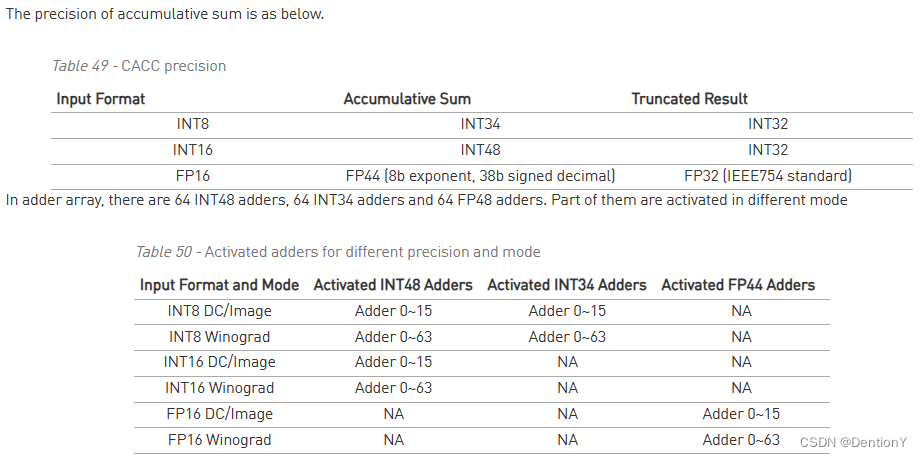
7.2 Power Consideration
和前面的流水级各模块一样,也设置了门控时钟。
八、MCIF
MCIF的架构如下:
MCIF用于仲裁来自内部子模块的请求,并转换为AXI协议以连接到外部DRAM。MCIF将同时支持读和写通道,但一些NVDLA子模块将只有读要求,因此子模块和MCIF之间的接口将支持读、写或两者兼有。上图中的CDMA0和CDMA1将需要只读,其他5类子模块将同时需要读和写。
九、SRAMIF
这里的SRAMIF的架构如下:
SRAMIF模块用于将内部子模块连接到片上SRAM。与MCIF类似,但总线延迟预计会更低。SRAMIF将同时支持读和写通道,但一些NVDLA子模块将只具有读要求,因此DMA Engine和SRAMIF之间的接口将支持读、写或两者兼有。CMDA0~1将只需要读通道,而其他5类子模块将同时需要读取和写入。
总结
本文重点对卷积模块各流水级进行深入解释。