文章目录
- 前言
- 一、nvdla_core_callbacks.c代码解读一
- 二、nvdla_core_callbacks.c代码内函数整理一
- 三、nvdla_core_callbacks.c代码结构体整理一
- 总结
前言
本系列内容力求将nvdla的内核态驱动整理清楚,如果有分析不对的请指出。
前面已经分析了一大块代码了,链接分别如下:
系列文章1:NVDLA内核态驱动代码整理一
系列文章2:NVDLA内核态驱动代码整理二
本章是分析nvdla_core_callbacks.c代码第一部分,同时借助nvdla_config结构体引出NVDLA IP Core的架构与外部接口。
由于仍然需要用到前面两篇文章下的结构体,因此此处贴出:
| 结构体 | 功能 |
|---|---|
nvdla_gem_object |
包含重要的变量,首先是drm_gem_object,用于drm存储管理和分配的结构体;其次是*kvaddr:这是一个指针成员,通常用于存储内核虚拟地址。这个地址指向内核中的数据缓冲区,该缓冲区可能包含了与图形或DMA相关的数据。这个成员可能被用于快速访问数据,而无需进行物理内存地址转换;最后是和dma相关的地址和属性 |
nvdla_mem_handle |
作为媒介联通用户态空间任务结构体nvdla_ioctl_submit_task和内核态空间任务结构体nvdla_task |
nvdla_ioctl_submit_task |
用户态空间任务结构体 |
nvdla_task |
内核态空间任务结构体 |
nvdla_device |
包含的信息是设备常用信息,比如中断、平台设备、drm设备等 |
nvdla_submit_args |
该结构体包含任务信息,用于用户态空间传入任务相关数据的参数,并通过该参数和nvdla_ioctl_submit_task交互,总体来说,任务粒度高于nvdla_ioctl_submit_task |
drm_file |
包含针对该file的每个文件描述符操作后的状态变量 |
drm_gem_object |
描述drm的存储分配对象,包含了该对象归属的设备drm_device和对象的大小size |
drm_device |
描述了drm设备结构体,包含了该总线设备的数据结构 |
sg_table |
Scatter-Gather表,用于描述分散在物理内存中的连续数据块的位置和大小 |
drm_ioctl_desc |
定义drm的ioctl操作,可以自行添加自定义ioctl操作,但需要注意ioctl的flags |
drm_ioctl_flags |
ioctl的flags说明 |
drm_driver |
包含驱动的常见定义变量 |
一、nvdla_core_callbacks.c代码解读一
1. nvdla_config结构体引出NVDLA架构
继续读代码,来到对nvdla_config结构体的配置,如下:
static struct nvdla_config nvdla_config_os_initial = {
.atom_size = 32,
.bdma_enable = true,
.rubik_enable = true,
.weight_compress_support = true,
};
static struct nvdla_config nvdla_config_small = {
.atom_size = 8,
.bdma_enable = false,
.rubik_enable = false,
.weight_compress_support = false,
};
static struct nvdla_config nvdla_config_large = {
.atom_size = 32,
.bdma_enable = false,
.rubik_enable = false,
.weight_compress_support = false,
};
这里给出的若干配置,可以和NVDLA官方生成Verilog过程中用到的配置文件相互对应起来。关于这一整个流程实现,后面有机会做介绍。
此处最核心的部分是nvdla_config结构体,在nvdla_linux.h中找到结构体的定义:
/**
* @brief Configuration parameters supported by the engine
*
* atom_size Memory smallest access size
* bdma_enable Defines whether bdma is supported
* rubik_enable Defines whether rubik is supported
* weight_compress_support Defines whether weight data compression is supported
*/
struct nvdla_config
{
uint32_t atom_size;
bool bdma_enable;
bool rubik_enable;
bool weight_compress_support;
};
其中atom_size是内存中支持最小访问的宽度,其中出现了bdma和rubik都是NVDLA架构中的内容,简单做个介绍。
2. NVDLA架构介绍
这里直接照搬NVIDIA关于NVDLA的介绍:
NVDLA是一种可配置的固定功能硬件加速器,适用于深度学习应用中的推理操作。
它通过加速CNN内每个层相关的操作(例如卷积、反卷积、全连接、激活、池化、BN等)
的块来为卷积神经网络提供完整的硬件加速。维护独立且可独立配置的模块意味着NVDLA
可以针对许多小型应用进行适当的调整,在这些应用中,之前的方案由于成本、面积或功耗
限制而无法进行推理。这种模块化架构可实现高度可配置的解决方案,该解决方案可随时扩
展以满足特定的推理需求。
NVDLA其实只是一个加速IP,按照异构计算模式,首先需要CPU作为主控来分配指令、接收中断与处理中断。NVDLA官方文档中详细介绍了这个流程:
NVDLA操作从主CPU发送一个硬件层的配置以及“激活”命令开始。由于每个模块都有一个
用于其配置寄存器的双缓冲区,因此它可以捕获第二层的配置,以便在激活层完成后立即
开始处理。一旦相关的硬件引擎完成其任务,它将向主CPU发出中断以报告完成情况,
然后主CPU将再次开始该过程。这个过程就是不断重复“命令-执行-中断”流程,直到
完成整个网络的推理。
所以必然意味着NVDLA具有中断发送、核心模块计算的能力。关于中断部分,稍微做点延申,将ZCU102作为控制NVDLA IP核的主控。如下:

中断使用Petalinux载入.hdf或者.xsa的board support package后自动导出:

可以很明显发现该设备树代码中NV_nvdla_wrapper_0这个NVDLA IP core被分配的中断号是89,想到哪说到哪吧,<0 89 4>中的0表示使用SPI中断、4表示使用高电平触发中断。89的序号可以查阅ZCU102的use guide即可确定,因为我们只用了1个中断,优先使用89号中断。从这段BSP提供的信息中也可以看到reg的信息,reg = <0x0 0xa0000000 0x0 0x10000>,刚好可以对应到NV_nvdla_wrapper_0节点的起始地地址和地址长度(Vivado中的起始地址和地址范围),也就是手动封装该IP时的起始地址和地址范围。关于验证该IP的设备树代码是否和硬件BSP一致,读该代码就行,略去不表。
接下来抛开整体可工作的SoC架构谈谈NVDLA IP Core的架构设计。如下图所示,下图来自:NVDLA Hardware Architectural Specification

很直观地看到该架构中设计了CNN模式下的绝大多数算子实现。从官网继续扒东西,该IP的工作模式如下:
NVDLA 有两种工作模式:独立模式和融合模式。
·独立操作是指每个单独的块被配置为何时执行和执行什么,每个块都处理其分配的任务。独立操作的开始
和结束,分配的模块执行存储器到存储器操作,进出主系统存储器或专用SRAM存储器。
·融合操作类似于独立操作,但是,有些块可以组装成pipeline;这通过减少对存储器的访存来提高加速性
能,而是让模块通过小型FIFO相互通信,从而实现无需在计算块和下一个待执行算子的计算块之间执行存储
器到存储器操作)。
接下来继续扒NVDLA IP Core的各部分实现设计。
2.1 Convolution Core工作模式介绍
首先从官网可以找到Convolution Core的4种计算模式,这是为了保证高效硬件使用而提出的,因为权重和激活值都存在不同的尺寸模式:
1. Direct Convolution:最直接简单的方式。
2. Image-input:并不按照img2col模式去存放输入,该模式下需要在计算模块和内存或SRAM之间建立重排buffer和重排单元,典型方案可以见Samsung第三、四代硬件加速器。
3. Winograd Convolution:适用于特定尺寸的卷积核组来提高计算效率。
4. Batching Convolution:复用权重且通过并行的方式来加速,减少多次搬运重复权重所占用的带宽。
同时NVDLA 卷积引擎保留了一个内部RAM,用于权重和输入特征存储,称为"Convolution Buffer"。这种设计大大提高了内存效率,因为减少了在每次需要权重或激活值时向系统内存控制器发送请求次数。
2.1.1 Direct Convolution模式
NVDLA支持两种内存带宽优化模式:
1. Sparse compression: 从稀疏压缩模式出发,这算是考虑算法存在的稀疏特征,设计专门的稀疏
识别、稀疏重排、稀疏zero-skipping技术等部件来配合实现数据少传输的目的。
2. Second memory interface: 提供了一个高效的片上buffer。Usually an on-chip SRAM
can provide 2x~4x of DRAM bandwidth with 1/10 ~ 1/4 latency. NVDLA始终通过DBBIF
与外部存储器有一个基本接口。除此之外,NVDLA还可以支持第二个内存总线接口SRAMIF。该接口可
以连接到片上SRAM或其他高带宽、低延迟的总线。
当然啦,以上描述对于实现硬件还是有很大难度的,因为可选细节很多,但是,我们只需要理解内核态驱动是怎么去配置硬件抽象的功能就行!
那接下来就是最重要的硬件参数,对于后续代码的理解帮助很大!
Atomic – C sizing
Atomic – K sizing
Data type supporting
Feature supporting – Compression
Feature supporting – Second Memory Bus
扩展介绍一下这里的硬件参数可选值。
首先是Data Type Supporting:
Parameter: Data type supporting
Values: Binary/INT4/INT8/INT16/INT32/FP16/FP32/FP64
Affected operations: All
然后是Atomic_c和Atomic_k的取值说明:
Necessary Descrip: This value indicates the parallel MAC operation in input feature
channel dimension. This parameter impacts total MAC number, convolutional buffer
read bandwidth.
Parameter: Atomic – C sizing
Values: 16~128
Affected operations: Convolution
Necessary Descrip: This value indicates the parallel MAC operation at output feature
channel dimension. This parameter impacts total MAC number, accumulator instance
number, convolutional write-back bandwidth.
Parameter: Atomic – K sizing
Range of values: 4~16
Affected scope: Convolutional function
关于这里的Atomic_c和Atomic_k,简单做个说明!
直接挪用甄建勇老师的《AI加速器架构设计与实现》书内的图片,看下图中的符号标记即可理解:

2.1.2 Image-input Convolution模式
Image-input模式就是一种特殊的Direct Convolution模式,针对第一层只有3个通道,官网是这么介绍的:
Image-input mode is a special direct convolution mode for the first layer, which
contains the input feature data from an image surface. Considering that the image
surface format is quite different from the normal feature data format, feature data
fetching operations follow a different path from direct convolution operations.
Normally the first layer only has 3 channels for image input, additional logic
was added here to enhance MAC utilization. Even though the first layer has 3
(or even 1) channel, a channel extension feature maintains average MAC
utilization close to 50%, even if Atomic-C setting is large (e.g., 16).
这里需要记住一个概念image surface,就是image,但是这个surface频繁出现在驱动代码中,造成很大困扰。另外,该模式是针对第一层原始resize之后的图片数据进行优化,主要是为了改进Direct模式下对第一层的MAC利用率低的问题。接下来就是最重要的硬件参数:
Atomic – C sizing
Atomic – K sizing
Data type supporting
Feature supporting – Compression
Feature supporting – Second Memory Bus
Image input support
关于Data type supprting的参数可选值:
NVDLA supports multiple data type inference based on different workloads. Use of
these parameters can be used to improve network accuracy for a given power and
performance constraint. Floating point data has a high precision (FP64/FP32/FP16);
integer data type (INT16/INT8/INT4), or even single bit binary can be used for lower
precision applications.
所以其实可以看到NVDLA支持FP64/FP32/FP16和INT16/INT8/INT4,同样也支持更低bit精度的数据。关于数据精度转换的表达式如下:

(老实说,目前没有get到想表达的意思!)
介绍Feature supporting – Compression的参数可选值:
Parameter: Feature supporting – Sparse Compression
Possible values: Weight/Feature/Neither/Both
Affected operations: Convolution
介绍Feature supporting – Second Memory Bus的参数可选值:
Parameter: Feature supporting – Second Memory Bus
Possible values: Yes/No
Affected operations: All
介绍Image Input Support的参数可选值:
Parameter: Image input support
Possible values: combinations of 8-bit/16-bit/both; RGB/YUV/both; non-planar/semi-planar/full-planar
Affected operations: Convolution
2.1.3 Winograd Convolution模式
按照官网的描述,Winograd Convolution模式是用于优化Direct Convolution性能的可选算法。Winograd卷积减少了乘法,同时增加加法以实现完整的计算,加法算子替代乘法算子,将大大减小计算功耗。例如,使用Winograd的3x3卷积核的卷积以2.25x来减少MAC操作次数,顺带提高性能和能效。权重转换是离线完成的,因此总权重数据大小会增加。
接下来就是最重要的硬件参数:
Feature supporting – Winograd
介绍Feature Supporting - Winograd下的参数可选值:
Parameter: Feature supporting – Winograd
Possible values: Yes/No
Affected operations: Convolution
2.1.4 Batching Convolution模式
按照官网的描述,无脑照搬——NVDLA批处理功能支持一次处理多组输入激活(多张图片)。这样可以重复使用权重并节省大量内存带宽,从而提高性能和功耗。全连接层的内存带宽要求远大于计算资源。全连接层中权重数据的大小很大,在MAC功能中仅使用一次(这是内存带宽瓶颈的主要原因之一)。允许多组激活共享相同的重量数据意味着它们可以同时运行时间(减少整体运行时间)。但是,这样的方式很显然对于内存的考验还是极大的,因为需要一次性输入很多图片数据。谨慎使用!
接下来是硬件参数:
Feature batch support
Max batch number
介绍Feature batch support下的参数可选值:
Parameter: Feature supporting – batch
Possible values: Yes/No
Affected operations: Convolution
关于Max batch number的可选值如下:
Parameter: MAX Batch number
Range of values: 1~32
Affected operations: Convolution
2.1.5 Convolution Buffer设计
按照官网的描述,Convolution Buffer是Convolution Core流水线的一部分,包含了卷积的权重数据和激活值。Convolution Buffer一个很精彩的功能是可以动态配置weight和activation的存储比例,以便于适应各种拓扑类型的网络。
关于Convolution Buffer的端口:
1. Read port for feature data
2. Read port for weight data
3. Write port for feature data
4. Write port for weight data
5. (Optional) Ports for compression tags if using Compression Scheme
硬件参数如下:
BUFF bank
BUFF bank size
关于BUFF bank的可选值如下:
Parameter: BUFF bank #
Range of values: 2~32
Affected operations: Convolution
关于BUFF bank size的可选值如下:
Parameter: BUFF bank size
Range of values: 4KB~32KB
Affected operations: Convolution
2.2 Activation Engine(SDP)工作模式介绍
看一下Single Data Point Processor (SDP)官网的描述:
The Single Data Point Processor (SDP) allows for the application of both linear
and non-linear functions onto individual data points. This is commonly used
immediately after convolution in CNN systems.
· The SDP provides native support for linear functions (e.g., simple bias and
scaling) and uses lookup tables (LUTs) to implement non-linear functions.
· This combination supports most common activation functions as well as other
element-wise operations including: ReLU, PReLU, precision scaling, batch
normalization, bias addition, or other complex non-linear functions, such as
a sigmoid or a hyperbolic tangent.
这边解释一下,就是SDP单元可以实现线性和非线性操作,非线性的实现依赖于线性和查找表,可以实现ReLU、PReLU、Precision Scaling、Batch Normalization、Bias Addition、Sigmoid、Hyperbolic Tangent等操作。
硬件参数如下:
SDP function support
SDP throughput
介绍SDP function support的参数可选值:
Parameter: SDP function support
Possible values: Scaling/LUT
Affected operations: Single Data Point
随后是SDP throughput的可选值:
Parameter: SDP throughput
Range of values: 1~16
Affected scope: SDP
2.2.1 Linear Function
参照原文的表达:
1. Precision Scaling. Control memory bandwidth throughout the full inference
process; feature data can be scaled to its full range before chunking into lower
precision and writing to memory . Scale key resources (e.g., MAC array) to support
full range for best inference result (other linear functions may be applied). Revert
input data before any of the non-linear functions (i.e., keep input data of non-
linear functions as original data).
# 表达的意思是Precision Scaling技术允许特征数据扩展到full range,随后再使用低精度数据。但是
伴随着这一技术的使用,关键资源比如MAC array需要扩展以适应于full range的推理,当然这一技术只局
限于在Linear Funct,在使用Non-Linear Funct之前,需要将数据调整回原来的数据格式。
我直接联想到的是训练后动态/静态数据量化操作。
2. Batch Normalization. In an inference function batch normalization requires a
linear function with a trained scaling factor. SDP can support a per-layer parameter
or a per-channel parameter to do the batch normalization operation.
# 表达的意思是SDP支持per-layer和per-channel的BN操作。
3. Bias Addition. Some layers require the bias function at the output side, which
means that they need to provide an offset (either from a per-layer setting or
per-channel memory surface or per-feature memory surface) to the final result.
# 表达的意思是SDP支持偏置的加和。
4. Element-Wise Operation. The element-wise layer (used in some CNN) refers to a
type of operation between two feature data cubes which have the same W, H and C
size. These two W x H x C feature data cubes do element-wise addition,
multiplication or max/min comparison operation and output one W x H x C feature
data cube. NVDLA supports common operations in element-wise operations (e.g., add,
sub, multiply, max).
# 表达的意思是SDP支持逐元素加、减、乘、最大、最小,并且输出维持输入的拓扑格式。
值得注意的是偏置的累加放在SDP内。
2.2.1 Non-Linear Function
支持ReLU、PReLU、Precision Scaling、Batch Normalization、Bias Addition、Sigmoid、Hyperbolic Tangent等操作,关于数学表达式,网上随便就可以搜到。
2.3 Pooling Engine(PDP)工作模式介绍
关于Planar Data Processor (PDP) 的描述如下:
PDP支持以下三种池化:
1、maximum-pooling – get maximum value from pooling window.
2、minimum-pooling – get minimum value from pooling window.
3、average-pooling – average the feature value in the pooling window.
硬件参数如下:
PDP throughput
关于PDP throughput的可选值:
Parameter: PDP throughput
Range of values: 0~4
Affected operations: PDP
2.4 Local Resp. Norm(CDP)工作模式介绍
关于Cross-channel Data Processor (CDP)的解释如下:用于应用局部响应归一化(LRN)函数,这是一种特殊的归一化函数,在通道维度上运行,而不是空间维度。LRN表达式如下:
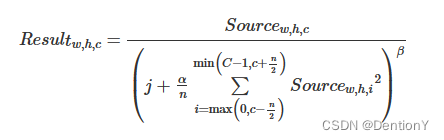
硬件参数如下:
CDP throughput
关于CDP throughput的可选值:
Parameter: CDP throughput
Range of values: 0~4
Affected operations: CDP
2.5 Reshape(RUBIK)工作模式介绍
关于RUBIK的解释如下:
The data reshape engine performs data format transformations (e.g., splitting or
slicing, merging, contraction, reshape-transpose). Data in memory often needs to be
reconfigured or reshaped in the process of performing inferencing on a convolutional
network.
所以一句话概括就是凡是出现了split、slice、merge、contract、reshape、transpose等操作,都是由RUBIK单元负责完成。
RUBIK单元有3种工作模式:
1、##Contract Mode##: Contract mode in Rubik transforms mapping format are used to
de-extend the cube. It’s a second hardware layer to support deconvolution. Normally,
a software deconvolution layer has deconvolution x stride and y stride that are
greater than 1; with these strides the output of phase I hardware-layer is a
channel-extended data cube.
# 支持反卷积操作
2、##Split Mode and Merge Mode##: Split and merge are two opposite operation modes
in Rubik. Split transforms a data cube into M-planar formats (NCHW). The number of
planes is equal to channel size. Merge transforms a serial of planes to a feature
data cube.
# Split模式和Merge模式分别完成“输入图片格式”为“NCHW”、“NCHW”为“输入图片格式”
硬件参数如下:
Rubik function support
介绍RUBIK的参数可选值:
Parameter: Rubik function support
Possible values: Yes/No
Affected operations: MISC
2.6 Bridge DMA(BDMA)工作模式介绍
关于bridge DMA (BDMA)的解释如下:用于系统DRAM和专用高性能内存接口之间的数据移动。
硬件参数如下:
BDMA function support
介绍BDMA的参数可选值:
Parameter: BDMA function support
Possible values: Yes/No
Affected operations: MISC
到此为止整个NVDLA IP Core架构已经介绍完毕,就剩下NVDLA IP Core暴露给主控和内存的外部接口,这部分将在2.7节展开介绍。
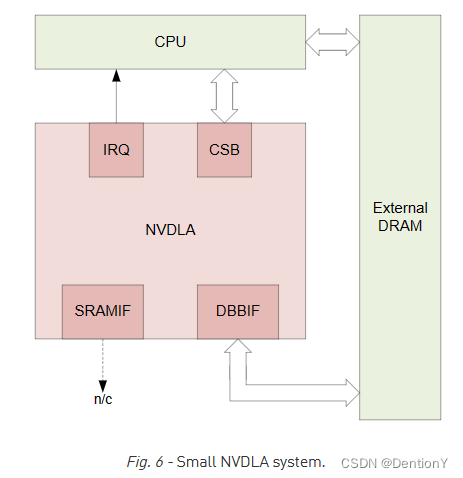
2.7 Small和Large NVDLA的配置
官网给了small和large两种模式的配置,在这里挂一下。
关于small的配置可以是,注意啊,是其中一种示例:
Data type supporting = INT8
Feature supporting - Winograd = No
Feature supporting - Second Memory Bus = No
Feature supporting - Compression = No
Image input support = R8, A8B8G8R8, A8R8G8B8, B8G8R8A8, R8G8B8A8, X8B8G8R8, X8R8G8B8, B8G8R8X8, R8G8B8X8, Y8___U8V8, Y8___V8U8
SDP function support = Single Scaling
BDMA function support = No
Rubik function support = No
Atomic - C sizing = 8
Atomic - K sizing = 8
SDP throughput = 1
PDP throughput = 1
CDP throughput = 1
BUFF bank # = 32
BUFF bank size = 4KB
那么就由此得到small的架构:
关于large的配置可以是,注意啊,是其中一种示例:
Data type supporting = FP16/INT16
Feature supporting - Winograd = Yes
Feature supporting - Second Memory Bus = Yes
Feature supporting - Compression = Yes
Image input support = A8R8G8B8/YUV16 Semi-planar
SDP function support = Scaling/LUT
BDMA function support = Yes
Rubik function support = No
Atomic - C sizing = 64
Atomic - K sizing = 16
SDP throughput = 16
PDP throughput = 4
CDP throughput = 4
BUFF bank # = 16
BUFF bank size = 32KB
由此得到large的架构图:
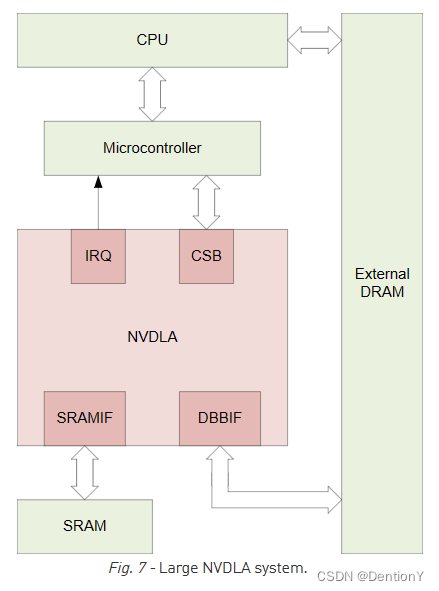
这边不约而同都提到四个模块,分别是IRQ、CSB、SRAMIF、DBBIF。
| 外部接口模块 | 功能 |
|---|---|
External interrupt (IRQ) |
NVDLA中的某些状态要求向正在命令NVDLA的处理器异步报告,这些状态包括操作完成和错误条件。外部中断接口提供了一个单独的输出引脚,以补充CSB接口。 |
Configuration space bus (CSB) |
主机系统通过一个非常简单的地址/数据接口访问和配置NVDLA寄存器组。一些系统可以通过合适的总线桥将主机CPU直接连接到CSB接口;其他可能更大的系统将把一个小型微控制器连接到CSB接口,将管理NVDLA的一些工作卸载到外部核心。 |
SRAM connection (SRAMIF) |
一些系统可能需要比系统DRAM所能提供的更多的吞吐量和更低的延迟,并且可能希望使用小型SRAM作为高速缓存来提高NVDLA的性能。为连接到NVDLA的可选SRAM提供了符合AXI4的辅助接口。 |
Data backbone (DBBIF) |
NVDLA包含自己的DMA引擎,用于加载和存储系统其余部分的值(包括参数和数据集)。data backbone是AMBA AXI4兼容接口,旨在访问大量相对高延迟的存储器(如系统DRAM)。 |
关于外部接口模块的若干信号将另外开一篇博文介绍。
二、nvdla_core_callbacks.c代码内函数整理一
此章没有,因此略去。
三、nvdla_core_callbacks.c代码结构体整理一
| 结构体 | 功能 |
|---|---|
nvdla_config |
实现NVDLA IP Core的内部配置,包括atom_size、bdma_enable、rubik_enable、weight_compress_support,关于参数的选择都在第1节中详细介绍 |
总结
本章从nvdla_config引出十分重要的NVDLA IP Core的硬件抽象,包括架构抽象和外部接口介绍。