SCI期刊:
《CVPR》 ,AI、CV领域三大顶级期刊之一

论文:
《SCConv: Spatial and Channel Reconstruction Convolution for Feature
Redundancy》

单位:
1.School of Communication and Electronic Engineering, East China Normal University, Shanghai, China.
2.Department of Computer Science and Technology, Tongji University, Shanghai, China.
0、前言:
之所以关注于这篇文章,不仅仅因为它中了CVPR,而是工作需要。工作以来,我主要关注于人工智能领域以下几个方面进展:
1、全新的积分神经网络
2、自建CNN模型的工程经验
3、CNN在通道、空间维度的有效信息提取
4、研发一种全新的CNN模型,能够与目前最先进的专门处理EEG信号的Baseline模型的各个Benchmark相媲美、甚至超越
5、目前世界上各个轻量级模型最新进展
上述5点中,前4点因为其他原因我不会在此交流,但第5点我在之前的博客中说的已经够多了,这是因为,目前AI创新模型有以下两种发展:
1.要么开发一种全新的大模型
2.要么探索一种良好的轻量级模型
首先,对于大模型,我并没有进行细致的研究,但是也都或多或少知道,但据我所知,截至2023年,目前国内高校和企业大模型共计188个,比如华为盘古大模型、腾讯的混元、科大讯飞的星火;国外目前有18个大模型,名气最大的便是深度学习之父弟子创建的OpenAI公司的ChatGPT,不得不说,国内在这方面遥遥领先!
但是,2023.11.8日发表的一篇Nature文章严谨地指出:大模型只会搞角色扮演,并不真正具有自我意识。文章指出,GPT-4、PaLM、LIama等大模型在人类面前表现的彬彬有礼的样子,只是装出来的而已,事实上它们并没有人类的情感,也没有什么像人的样子,该文来自谷歌DeepMind和Eleuther AI,论文指出:大模型就是个角色扮演的引擎而已。对于这句话,文章说的太狠了,直接封死研发大模型的未来意义,一个AI方向,没了未来实际意义,一般over,国内费劲投钱投人开发大模型,结果11月被Nature当头一棒,国内遥遥领先!
哈,感兴趣的可以看一下这篇最新的Nature文章:
Shanahan M, McDonell K, Reynolds L. Role play with large language models. Nature. 2023 Nov;623(7987):493-498. doi: 10.1038/s41586-023-06647-8.IF: 64.8 Q1 . Epub 2023 Nov 8. PMID: 37938776.
所以我说,研发全新的轻量级CNN模型和结构设计以及工程化落地是明智且一直正确的。
1、引言:
言归正转,说一下这个SCConv轻量级模型。卷积神经网络在各种计算机视觉任务中取得了显著的性能,但这是以巨大的计算资源为代价的,部分原因是卷积层提取的冗余特征。
在本文中,作者尝试利用特征之间的空间和通道冗余来进行CNN压缩,并提出了一种高效的卷积模块,称为SCConv (spatial and channel reconstruction convolution),以减少冗余计算并促进代表性特征的学习。提出的SCConv由空间重构单元(SRU)和信道重构单元(CRU)两个单元组成。SRU采用分离重构的方法来抑制空间冗余,CRU采用分离变换融合的策略来减少信道冗余。此外,SCConv是一种即插即用的架构单元,可直接用于替代各种卷积神经网络中的标准卷积。实验结果表明,scconvo嵌入模型能够通过减少冗余特征来获得更好的性能,并且显著降低了复杂度和计算成本。
先说一下,计算机中的冗余,冗余:数据重复,浪费空间。放在神经网络中就是卷积层提取了重复的特征,占用了内存空间,使得其他有利于分类的有效特征被挤兑掉了,结果便是模型性能被限制。这也是我上面提到的关注点3,所以能够通过该模型,学到不少其他好的东西。下面我简单的对该模型进行讲解。
2、模型设计:
2.1 SCConv

如图,SCConv 由两个单元组成,即空间重构单元 (SRU) 和信道重构单元 (CRU) ,两个单元按顺序排列。输入的特征 X 先经过空间重构单元 ,得到空间细化的特征Xw。再经过通道重构单元 ,得到通道提炼的特征 Y 作为输出。
SCConv 模块利用了特征之间的空间冗余和信道冗余,模块可以无缝集成到任何 CNN 框架中,减少特征之间的冗余,提高 CNN 特征的代表性。
作者对 SRU 和 CRU 进行不同的组合,包括:
- 不使用 SRU 和 CRU
- 单独使用 SRU
- 单独使用 CRU
- 并行使用 SRU 和 CRU
- 先使用 CRU 再使用 SRU
- 先使用 SRU 在使用 CRU
最终发现先使用 SRU 再使用 CRU 的效果最好:

2.2 SRU 空间重建单元

Spatial Reconstruction Unit.SRU,该单元采用分离-重构的方法
分离 的目的是将信息量大的特征图从信息量小的特征图中分离出来,与空间内容相对应。作者使用组归一化 (Group Normalization) 里的缩放因子来评估不同特征图中的信息含量。
分离公式:
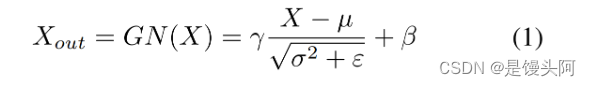


重构 操作是将信息量较多的特征和信息量较少的特征相加,生成信息量更多的特征并节省空间。具体的操作是交叉重建,将加权后的两个不同信息特征合并,得到 Xw1 和 Xw2 ,连接起来后得到空间细化特征图 Xw。

经过 SRU 处理后,信息量大的特征从信息量小的特征中分离出来,减少了空间维度上的冗余特征。
2.3 CRU 通道重建单元

Channel Reconstruction Unit. 单元采用 分割-转换-融合 的方法
分割 操作将输入的空间细化特征 Xw分割为两部分:一部分的通道数是 aC ,另一部分的通道数是 (1−a)C ,其中 a 是超参数且 0≤a≤1 。随后对两组特征的通道数使用 1×1 卷积核进行压缩,分别得到 Xup 和 Xlow。
转换 操作将输入的 Xup作为“富特征提取”的输入,分别进行 GWC 和 PWC,然后相加得到输出 Y1 。将输入 Xlow作为“富特征提取”的补充,进行 PWC,得到的结果和原来的输入取并集得到 Y2 。
融合 操作使用简化的 SKNet 方法来自适应的合并 Y1 和 Y2 。具体来说,首先使用全局平均池化技术,将全局空间信息和通道统计信息结合起来,得到经过池化的 S1 和 S2 。然后对 S1 和 S2 做 Softmax 得到特征权重向量 B1 和 B2 。最后使用特征权重向量得到输出 �=B1Y1+B2Y2 ,Y 即为通道提炼的特征。
其实很简单,通道模块就是把上个空间单元得到的特征数据,把通道分开,然后上路是主干,下路可以说是补充,上边进行群智能卷积GWC和点智能卷积PWC,下面只进行PWC再做特征相加再池化再点击再拼接
那关键在于,一开始的通道数怎样分配给上路和下路?作者给出了答案:

2.4 分类实验
确定完最佳通道分割比后,也确定好SRU、CRU排列顺序后,作者把该模型与相当多的目前CV
SOTA模型进行了对比,结果如下:


2.5 Pytorch复现代码
'''
Description:
LastEditTime: 2023-07-27 18:41:47
FilePath: /chengdongzhou/ScConv.py
'''
import torch
import torch.nn.functional as F
import torch.nn as nn
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int,
group_num:int = 16,
eps:float = 1e-10
):
super(GroupBatchnorm2d,self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.weight = nn.Parameter( torch.randn(c_num, 1, 1) )
self.bias = nn.Parameter( torch.zeros(c_num, 1, 1) )
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view( N, self.group_num, -1 )
mean = x.mean( dim = 2, keepdim = True )
std = x.std ( dim = 2, keepdim = True )
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.weight + self.bias
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5,
torch_gn:bool = True
):
super().__init__()
self.gn = nn.GroupNorm( num_channels = oup_channels, num_groups = group_num ) if torch_gn else GroupBatchnorm2d(c_num = oup_channels, group_num = group_num)
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = self.gn.weight/sum(self.gn.weight)
w_gamma = w_gamma.view(1,-1,1,1)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
w1 = torch.where(reweigts > self.gate_treshold, torch.ones_like(reweigts), reweigts) # 大于门限值的设为1,否则保留原值
w2 = torch.where(reweigts > self.gate_treshold, torch.zeros_like(reweigts), reweigts) # 大于门限值的设为0,否则保留原值
x_1 = w1 * x
x_2 = w2 * x
y = self.reconstruct(x_1,x_2)
return y
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel:int,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha*op_channel)
self.low_channel = low_channel = op_channel-up_channel
self.squeeze1 = nn.Conv2d(up_channel,up_channel//squeeze_radio,kernel_size=1,bias=False)
self.squeeze2 = nn.Conv2d(low_channel,low_channel//squeeze_radio,kernel_size=1,bias=False)
#up
self.GWC = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=group_kernel_size, stride=1,padding=group_kernel_size//2, groups = group_size)
self.PWC1 = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=1, bias=False)
#low
self.PWC2 = nn.Conv2d(low_channel//squeeze_radio, op_channel-low_channel//squeeze_radio,kernel_size=1, bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self,x):
# Split
up,low = torch.split(x,[self.up_channel,self.low_channel],dim=1)
up,low = self.squeeze1(up),self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat( [self.PWC2(low), low], dim= 1 )
# Fuse
out = torch.cat( [Y1,Y2], dim= 1 )
out = F.softmax( self.advavg(out), dim=1 ) * out
out1,out2 = torch.split(out,out.size(1)//2,dim=1)
return out1+out2
class ScConv(nn.Module):
def __init__(self,
op_channel:int,
group_num:int = 4,
gate_treshold:float = 0.5,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.SRU = SRU( op_channel,
group_num = group_num,
gate_treshold = gate_treshold )
self.CRU = CRU( op_channel,
alpha = alpha,
squeeze_radio = squeeze_radio ,
group_size = group_size ,
group_kernel_size = group_kernel_size )
def forward(self,x):
x = self.SRU(x)
x = self.CRU(x)
return x
if __name__ == '__main__':
x = torch.randn(1,32,16,16)
model = ScConv(32)
print(model(x).shape)
都封装好了,想用直接调用即可。
3、布莱克变秃事件
狗蛋学者在上周探索AI模型技术时,不慎把毛烧焦,目前变秃,希望布莱克学者早日康复,在此贴一张狗蛋学者被烧前一晚的帅照
