目录

更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

接下来的一段时间我将总结下关于【Python进阶系列】的一系列开发技术知识点的分享文章,主要为初学者从零基础到进阶再到高级和项目实战,结合目前最新的Python版本3.12来做代码示例的样式,并同时也会标注出与Python2的一些异同点。
然后关于Python的Web开发、爬虫开发、操作系统开发、网络安全开发应用领域这块,可以分别参考我的公众号CTO Plus【Flask进阶系列】、【Django进阶系列】、【DRF进阶系列】、【互联网分布式爬虫系列】和【网络安全系列】的内容,敬请关注,欢迎交流。
![]()
以下是【Python3进阶系列】的部分内容

Python是一种功能强大且灵活的编程语言,广泛应用于各个领域。在Python中,有许多优秀的爬虫框架可供选择,其中最受欢迎的包括pyspider和scrapy。
通过前面两篇文章对这两个框架的详细介绍和使用《互联网分布式爬虫技术之Scrapy网络数据采集的利器框架简介和使用(文末加群)》和《互联网分布式爬虫技术之pysipder框架使用详解与实战案例(文末加群)》,我们已经大概知道这两个框架的一些特点,那么,本篇文章我将对这两个框架进行对比,以帮助读者选择适合自己需求的爬虫工具。
1. 功能特点
pyspider是一个强大的分布式爬虫框架,它具有简单易用、可视化界面(WebUI)、支持JavaScript渲染等特点。pyspider使用Python 3编写,支持异步IO,可以同时处理多个任务,适用于高并发的爬取需求。它还提供了强大的数据处理和存储功能,可以将数据保存到数据库中,或者导出为各种格式的文件。
scrapy是一个成熟且功能丰富的爬虫框架,它使用Python编写,支持异步IO和多线程,并提供了强大的数据处理和存储功能。scrapy具有良好的可扩展性,可以通过编写插件来增加功能。它还提供了强大的调度器和去重器,可以高效地管理爬虫任务,并避免重复爬取。
可以在pyspider中的WebUI进行爬虫的编写和调试;Scrapy采用代码、命令行操作的方式,实现可视化需对接Portia。
pyspider 支持使用 PhantomJS 对JavaScript 渲染页面的采集;Scrapy 需对接Scrapy-Splash组件。
pyspider 内置了 PyQuery作为选择器;Scrapy对接了 XPath、CSS选择器和正则匹配。
pyspider 扩展性相对来说比较弱;Scrapy 模块之间耦合度低,扩展性强,如:可以通过对接 Middleware、Pipeline 等组件实现更强功能。
2. 使用难度
pyspider相对于scrapy来说,更加简单易用。它提供了直观的可视化界面,可以通过简单的拖拽和配置来创建爬虫任务。同时,pyspider还提供了丰富的示例代码和文档,可以帮助用户快速上手。
scrapy相对于pyspider来说,更加复杂一些。它需要用户编写一些额外的代码来定义爬虫的逻辑和数据处理过程。虽然scrapy提供了详细的文档和教程,但对于初学者来说,可能需要花费一些时间来学习和理解。
3. 社区支持
scrapy是一个非常成熟的爬虫框架,拥有庞大的用户社区和活跃的开发者社区。用户可以在社区中获取到大量的示例代码、教程和解决方案。同时,scrapy还有许多第三方库和插件可供选择,可以帮助用户扩展功能。
pyspider相对于scrapy来说,社区规模较小。尽管如此,pyspider仍然有一些活跃的用户社区和开发者社区,用户可以在社区中获取到一些有用的资源和支持。
更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

4. 活跃度和受欢迎程序
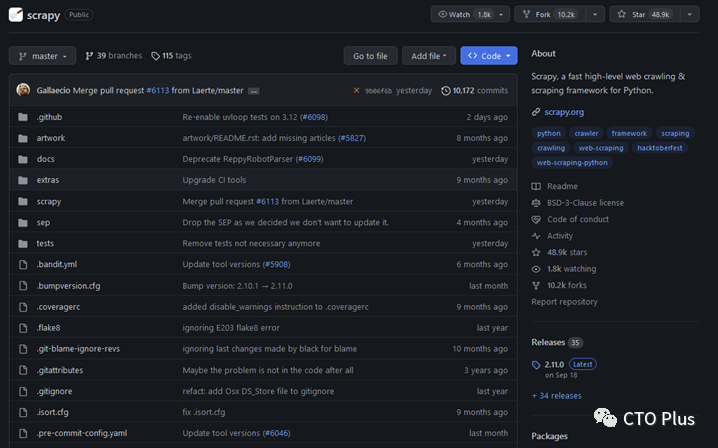
scrapy 48.9k stars
pyspider 16.1k stars
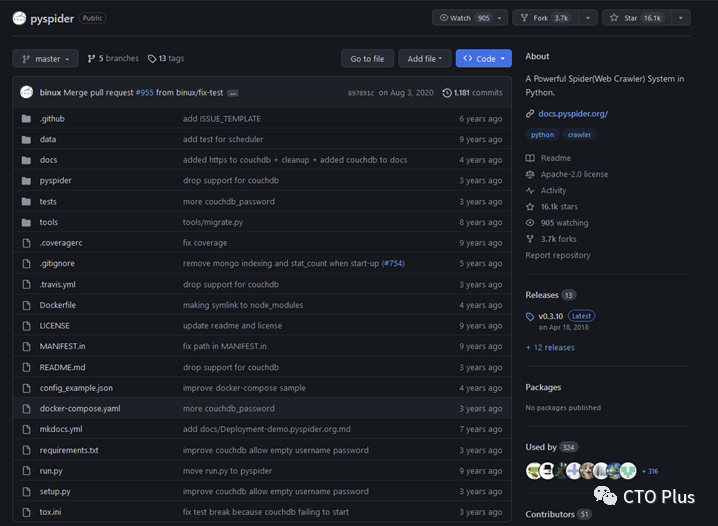
截止到本文当前时间(2023年10月19日18:03:03)scrapy在github上拥有48.9k stars,更新也比较频繁,相比于pyspider的16.1k stars还是比较受欢迎的,而且pyspider也年久失修。
综上所述,pyspider和scrapy都是优秀的Python爬虫框架,具有各自的特点和优势。如果你是初学者或者对爬虫任务的复杂度要求不高,可以选择pyspider。如果你对爬虫任务有更高的要求,或者需要更多的自定义功能和扩展性,可以选择scrapy。无论选择哪个框架,都需要根据自己的需求和技术水平做出合适的选择,并在使用过程中遵守相关法律法规,尊重网站的权益和用户的隐私。
最后就是本人自己的选择态度:推荐大家使用scrapy。
总的来说,pyspider 更加便捷,Scrapy扩展性更强,如果要快速实现爬取优选 pyspider,如果爬取规模较大、反爬机制较强,优选 scrapy。
Python专栏
https://blog.csdn.net/zhouruifu2015/category_5742543
更多精彩,关注我公号,一起学习、成长


CTO Plus
一个有深度和广度的技术圈,技术总结、分享与交流,我们一起学习。 涉及网络安全、C/C++、Python、Go、大前端、云原生、SRE、SDL、DevSecOps、数据库、中间件、FPGA、架构设计等大厂技术。 每天早上8点10分准时发文。
306篇原创内容
公众号
标准库系列-推荐阅读:
最后,不少粉丝后台留言问加技术交流群,之前也一直没弄,所以为满足粉丝需求,现建立了一个关于Python相关的技术交流群,加群验证方式必须为本公众号的粉丝,群号如下:
