

背景

什么是AB增量?
▐ AB实验简介
▐ AB增量计算


-
分别计算实验组和对照组的DAU人均值(即手淘来访率):实验组DAU/实验组UV -
然后计算实验组和对照组DAU人均值的差值,得到淘宝来访率增量 -
最后用实验组UV*淘宝来访率增量得到实验的DAU增量

▐ 裂变污染原理
AB实验方案设计
理想情况下,AB实验中,实验组是能够参与策略玩法的用户群,对照组是不能参与策略玩法的用户群。
但是有社交裂变玩法的情况下,AB实验设计常见分为:完全策略实验、非完全策略实验。
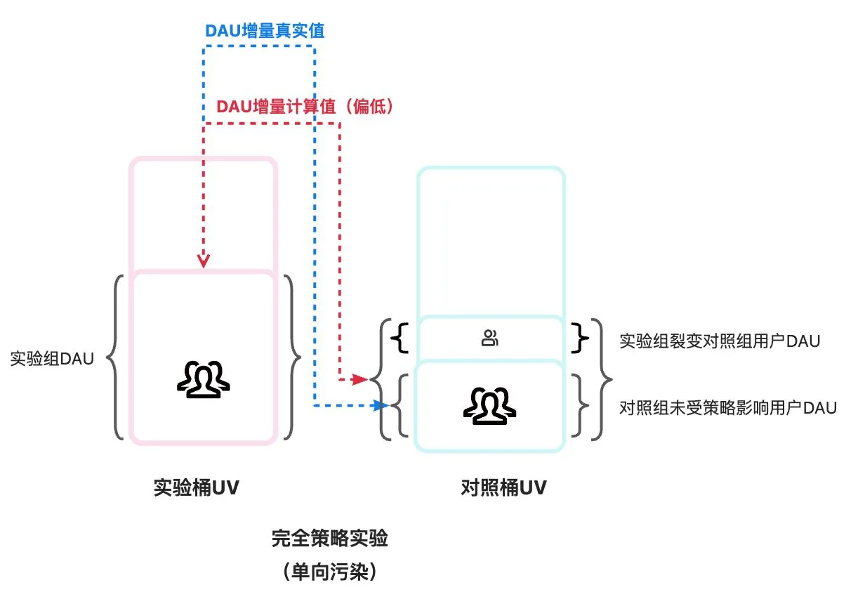
完全策略实验中,对照组的用户感知不到策略,即使通过分享路径进入产品,也提示没有玩法;如业务有无实验/新财年策略实验等
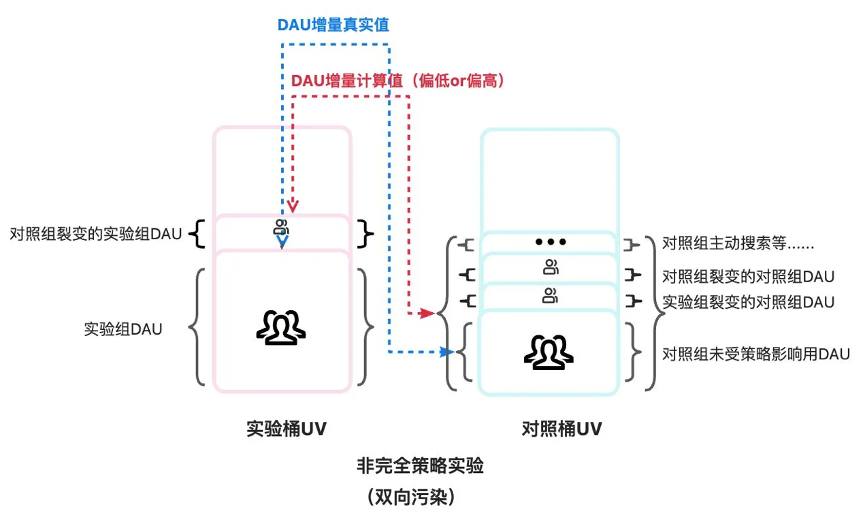
非完全策略实验中,受舆情/技术成本等客观业务因素限制,对照组没有入口,但通过分享路径可以参与或部分参与玩法
-
裂变污染原理与方向性
根据AB实验设计的方案不同,实验组和对照组受社交裂变污染的程度不同。
在完全策略实验中,污染是单向的,仅对照组受污染,在这种情况下,仅对照组受污染影响指标水位上涨导致AB增量计算偏低;
在非完全策略实验中,由于对照组在一定程度上可以参与策略玩法,在受实验组裂变影响后,可以反过来继续影响实验组/对照组自身。在这种实验设计方案中,污染是双向的,实验组和对照组的指标水位均受污染影响变高,理论上AB增量的计算可能偏高、也可能偏低,实际应用中大多实验桶受反向污染程度低,结果往往偏低。
以DAU为例:
▐ 污染科学评估方案
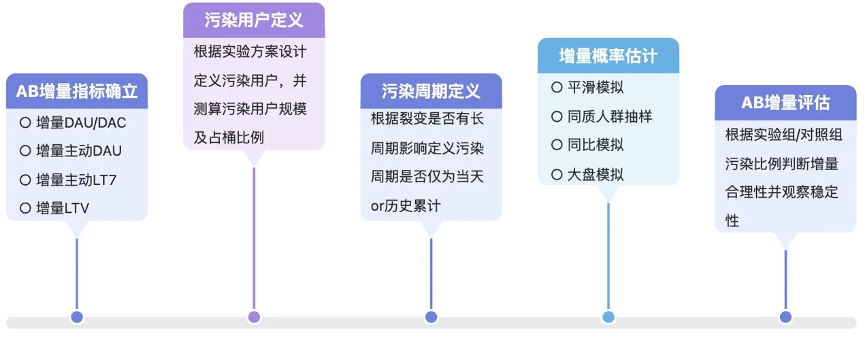
增量目标确立
根据业务北极星目标确定增量处理指标,是日指标还是周期性指标,常见的有手淘增量DAU/增量DAC/增量主动DAU/增量主动LT7/增量LTV等,前两者属于日指标,后两者为周期性指标,日指标的评估方案相对灵活。
污染用户定义
进行污染处理的第二步,需要首先明确哪些用户是被污染的用户,再决定对于污染用户的指标处理方式。污染用户的追踪分为以下几个步骤:
污染方向性:根据AB实验设计方案确立是否为单向/双向污染,其中单向污染用户为参与策略的所有空桶用户,双向污染为参与策略的所有对照组用户(含实验组裂变召回/对照组裂变召回/主动搜索/历史分享链接进入等)+被对照组裂变召回的实验组用户,具体根据各个业务实际情况而定
污染口径:
窄口径:独占用户:被污染召回,且是实验策略的手淘独占用户;首触用户:被污染召回,且是实验策略的手淘首触用户
宽口径:按照实验设计本不该参与策略,但实际参与策略的所有用户
-
窄口径与宽口径区别: 窄口径相对严格,对于独占口径,非独占用户也有可能因为该场景访问并被路由到其他场景;对于首触口径,非首次触达的用户首次可能也是非主动来访,首次触达来自该策略。具体业务采用的污染口径可根据业务实际情况而定,大部分情况下会采用宽口径去定义
污染周期定义
一般根据业务的情况,有两种污染周期定义方法:
当天被污染的用户:适用于社交裂变行为不对后续来访有长期影响的裂变形式,如一次性助力、助力链接时效性短等场景
历史累计被污染过,即纳入污染用户范围:适用于社交裂变行为大概率会影响后续来访,如分享组队、分享退出后有强引导的回访教育策略等
注:长期存在的常态业务往往不适合用历史累计口径,涉及污染用户量过大会加入过多稀疏行为用户进而影响后续评估的准确性和稳定性,可根据业务形式评估影响周期,取近期累计污染周期等折中口径,如近7天等
增量概率估计
-
自然访问概率:本身在裂变当日有一定的自然访问淘宝概率,这里用条件概率P(来访淘宝|不受裂变影响)来代替 -
真实访问概率:受社交裂变影响,将来访这一概率事件转化为确定性事件 P(来访手淘|受裂变影响)=1(确实访问了淘宝) -
裂变增量uplift:所以污染的增量uplift来源为P(来访淘宝|受裂变影响)-P(来访淘宝|不受裂变影响)=1-P(来访淘宝|不受裂变影响)
那么增量污染评估的核心在于评估用户不受社交裂变影响时的条件访问概率P(来访淘宝|不受裂变影响)。
注:对于个体的条件概率估计具有较大的有偏性,但群体估计可以一定程度解决有偏的问题。

接下来介绍已经在互动业务上验证的4种增量概率估计方案。
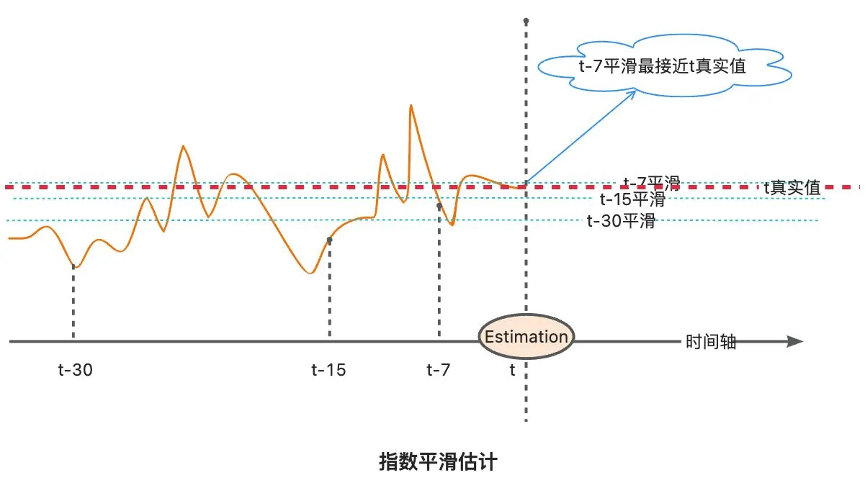
指数平滑估计
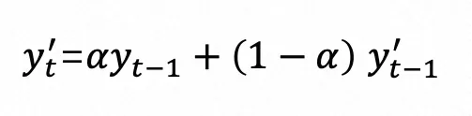
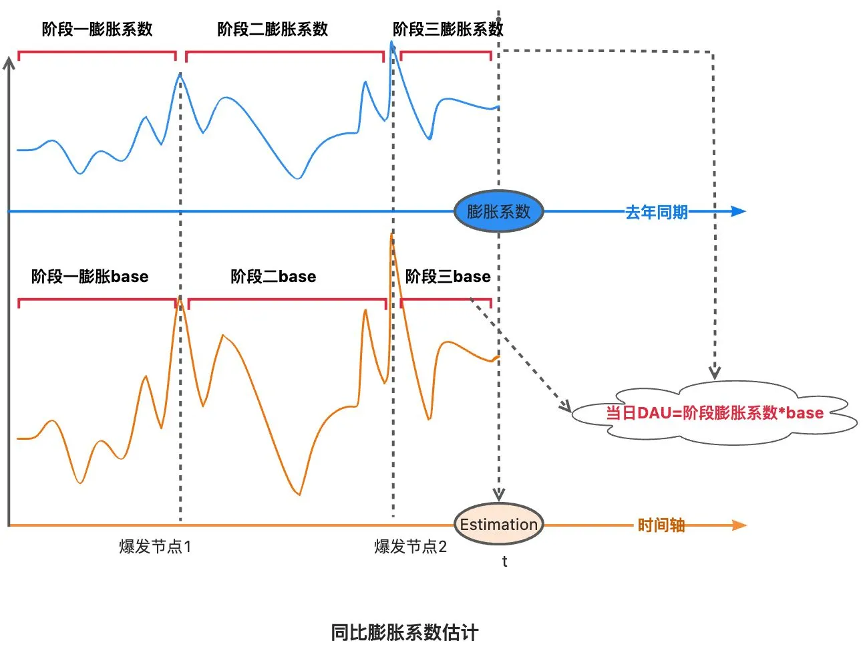
同比膨胀系数估计
对于非常态业务,i.e.大促主互动,短期大量的DAU规模且大促期的节点性非常突出,平滑趋势估计方法不再适用。
这种场景可尝试在指数平滑的基础上,使用同比膨胀系数来模拟估计:
以t-7为例,膨胀系数t=去年t日DAU/去年(t-1~t-7日)日均DAU
并以该膨胀系数作为今年同期的膨胀系数
今年t日DAU=今年(t-1~t-7日)日均DAU x 膨胀系数t
但这种方法未考虑年同比影响,且多个指标膨胀系数不一致,滚动计算成本相对较高。
大盘膨胀系数估计
与同比膨胀系数估计方法类似,在无往年数据可借鉴的情况下,可以采用今年的大盘膨胀系数来进行估计,其中实验桶采用淘宝大盘进行膨胀系数的计算,对照组采用未参与策略的淘宝大盘用户进行膨胀系数的计算。
同质人群抽样
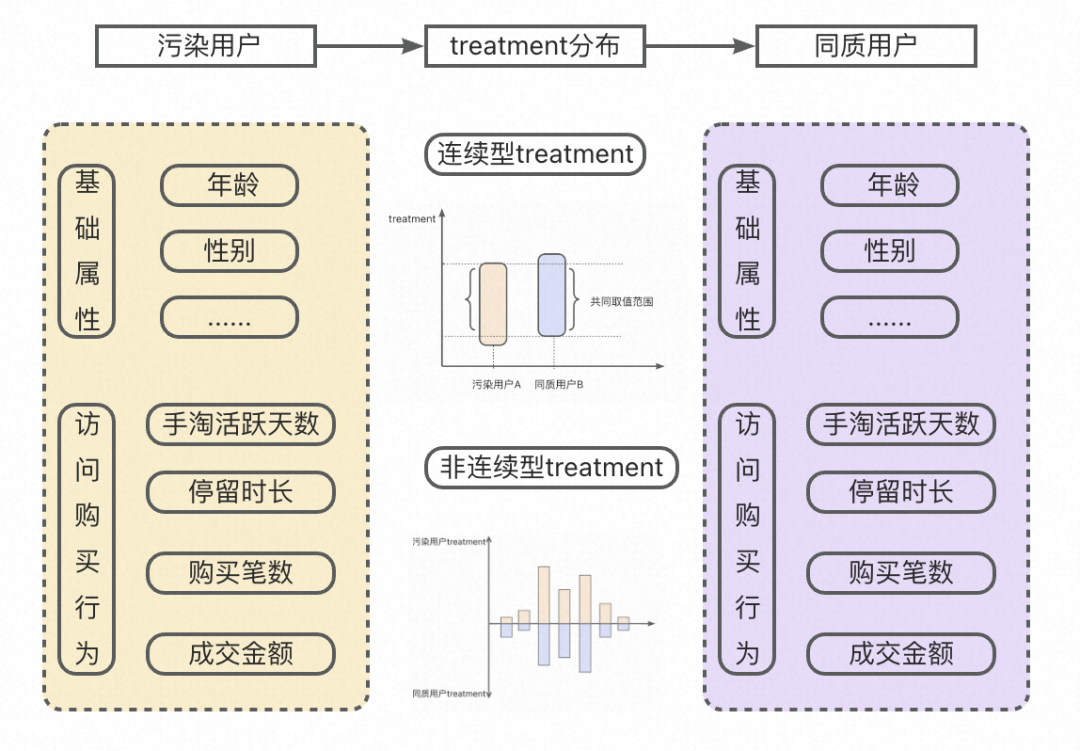
上述三种方法均是根据污染用户自身历史水平来估计当日淘宝访问的条件概率,另一种思路是根据污染用户的估计目标(treatment)来进行桶内同质人群抽样,以同质人群的当天淘宝访问作为污染用户的手淘访问概率,这种方案可根据具体用户计算增量处理后的p值及显著性。一般的同质抽样有以下两种:
确定性目标抽样:以淘宝DAU增量目标为例,在污染用户所在的桶内,根据污染用户规模,抽取和污染用户在[t-n]抽样周期内,在多个维度上具有相同分布的同质人群,指标选取以【与增量评估指标相关性高】为标准来进行选取。
若估计手淘DAU指标,可选取“淘宝活跃度”标签作为抽样标准(在抽样规模充足的条件下可加入一下用户基础标签/频道访问标签等);
其中数值型字段如成交金额需要进行分层抽样,同时需要重点关注分层粒度,分层过粗会导致抽样不精准、过细会导致可抽样用户不足。
但这种方法也存在一定的局限性,如可抽样人群较少、数值型字段取值区间较大数据分布稀疏,对于同质抽样的准确性有较大的影响。
PSM抽样估计:采用PSM方法进行同质人群抽样,该方法在策略评估域有广泛的应用,相对确定性目标抽样较为黑盒,具体不再赘述~
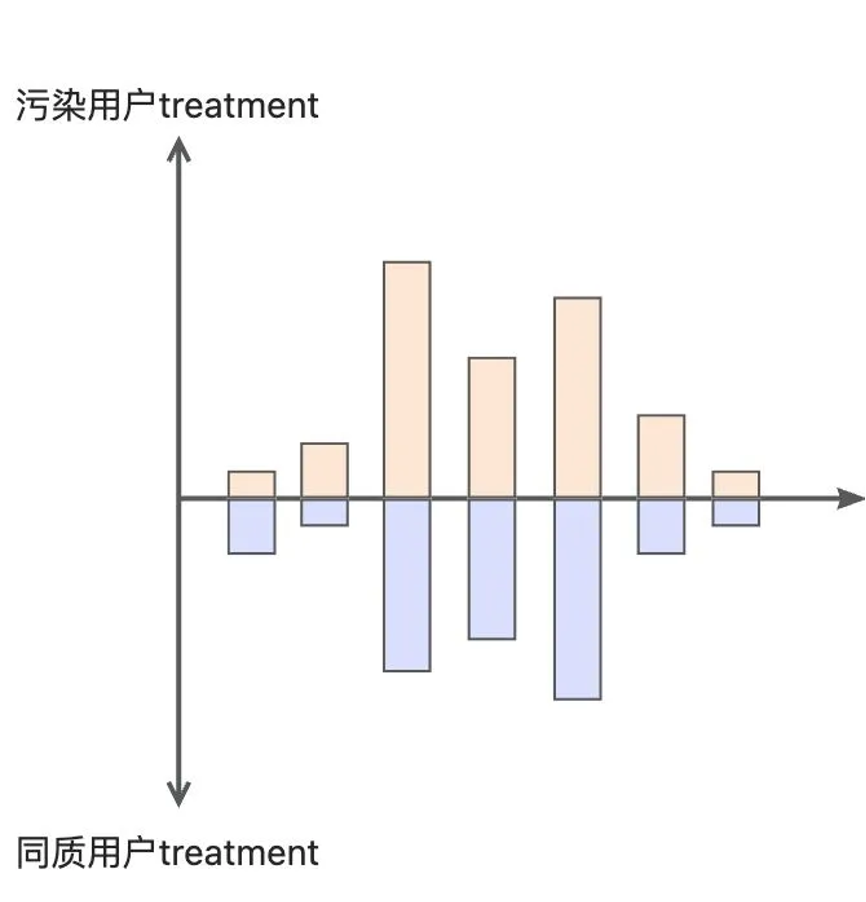
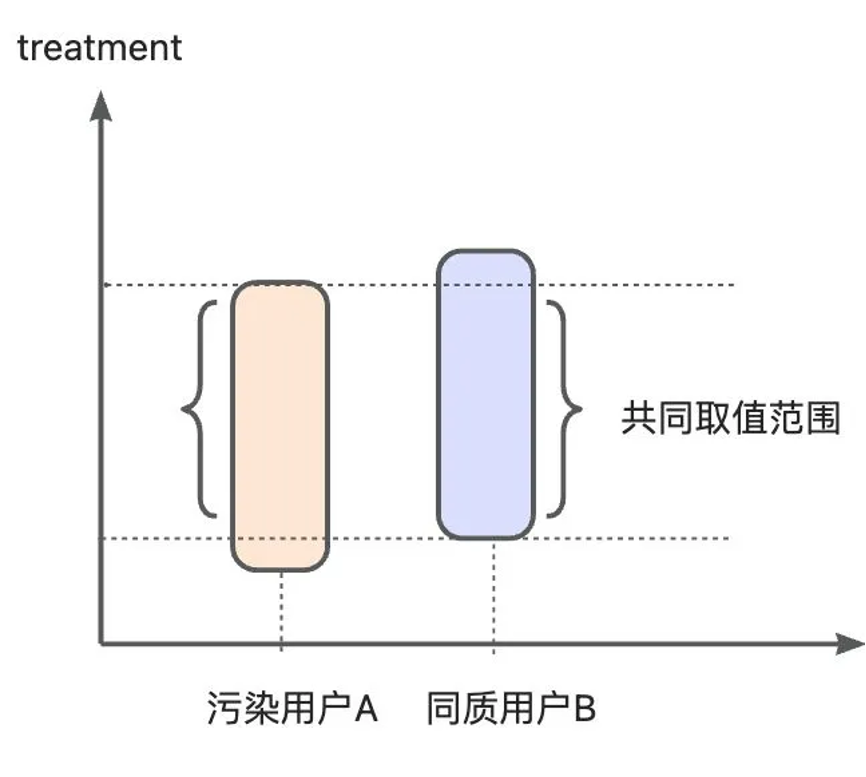
同质性校验:同质性抽样后需要对污染用户和同质用户做treatment同质性校验:对于污染用户和抽样的同质用户,在类别型(左图)/数值型(右图)treatment的抽样周期内,需要具有高度的分布重合度(通常认为在diff在5%内符合同质性校验)。
▐ AB增量科学评估总结
根据各业务实验方案设计、裂变模式设计、策略规模及特点选取合适的评估方案。


参考文献
《AB实验:科学归因与增长的利器》
《关键迭代》
《时间序列分析》

我们是淘天集团用户技术团队,致力于基于淘宝天猫全域数据,建立多领域的用户全生命周期数据和价值体系,通过主动的数据分析来挖掘和发现电商业务各场景的增长机会。团队成员具备丰富的数据分析和算法解决方案设计经验,能够利用运筹优化、博弈论、因果推断、机器学习建模等方法对手淘内各场景的权益效率提升、用户留存等问题进行建模分析,实现用户规模及用户粘性的增长。还专注于数据产品建设,负责科学分析能力产品的落地,包括多维分析、归因分析、智能tips等多种数据科学组件。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。