

-
基本结构 = 入口 + 内核 + 依赖 内核 = 简单逻辑 + 复杂流程 简单逻辑 = 业务脚本 + 能力执行 复杂流程 = 流程编排 + 节点衔接 + 能力(任务)执行 -
演化 = 主题讨论 + 组件选取(市场组件优先)


▐ 入口
VSEF 观点:入口要清晰明确
就像 “要理清乱了的线团,就要找到线头一样”,将入口放在一个完整的目录,或者模块中的好处是:可以快速地功能总览,了解“提供哪些服务”、“接收那些消息”、“实现哪些任务”。
这里的目录类型有:
服务 service : 对外提供的 rpc 服务, 如HSF。这个一般会搭配一个服务 client 可调用者使用。
消息 message:可以再区分 metaq 和 notify 目录。
调度 scheduler:一些调度任务。
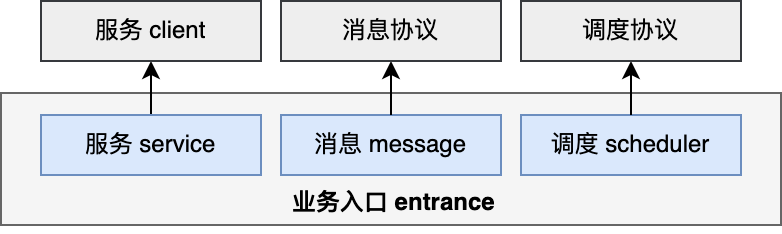
业务入口
▐ 内核
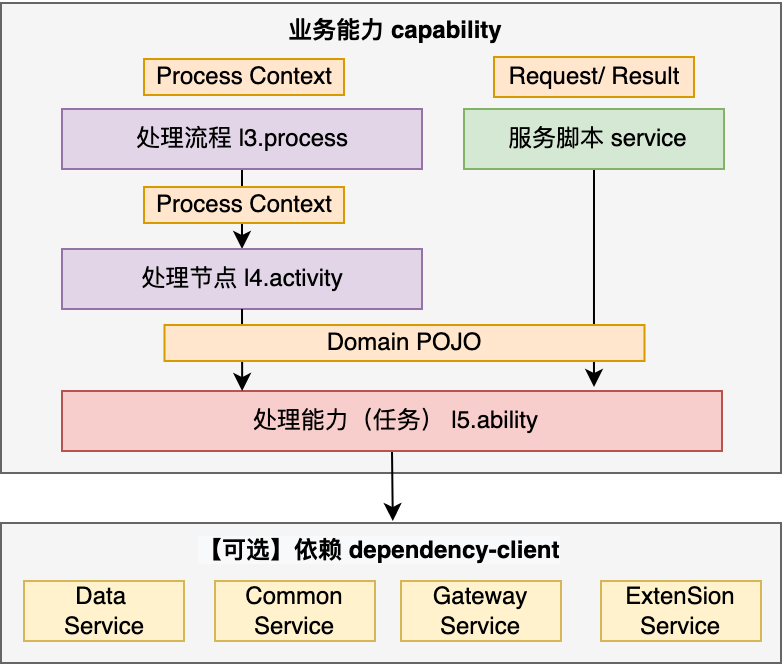
内核结构
-
流程 l3.process:进行业务活动编排,理解整个请求要完成什么事情。 -
活动 l4.activity:提供每个执行步骤的能力,代表了事情的关键节点。 -
能力(任务) l5.ability:节点执行时要做的一些具体任务,期望包装为能力,具备一定的复用性。
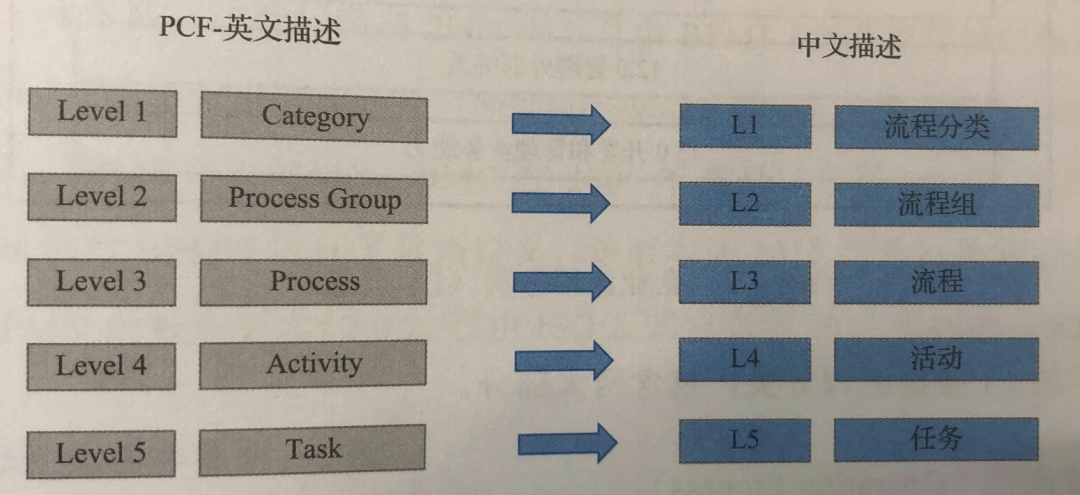
简单流程,主要是只读服务,如查询数据等,可以直接进入服务脚本 service。简单服务直接使用 l5能力(任务)。当逻辑逐渐复杂的时候,可以重构为复杂流程。
VSEF 观点:完成任务需要使用的资源都是依赖,依赖皆服务。服务都通过 l5能力 进行使用。
l5 能力在进行具体操作的时候,需要从数据、扩展、外调、中间件等渠道获取需要加工的数据,形成自己的理解。这个过程中,依赖的东西被称为“依赖”,通过“服务”的方式进行集成。
▐ 依赖
可以放进依赖的类型:
存储实现 repository : 数据库的读写操作。
中间件使用 middleware:包括缓存(tair)、发送消息(metaq、notify)、配置(diamond、switch)等。
网关实现 gateway:外部系统的调用,比如订单服务、退款服务等。
扩展实现 extension:业务差异性设计的扩展能力,需要业务提供扩展插件,或者平台代写。
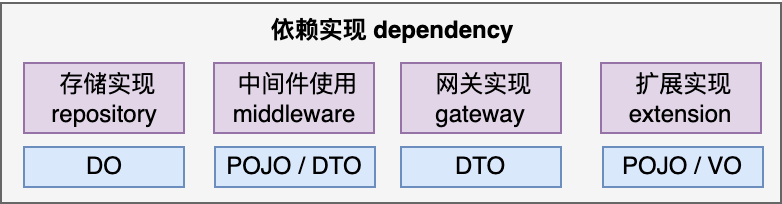
VSEF 观点:基础设施是否易变,可自行判断,稳定时可以直接依赖。
这里值得讨论的是:如果基于六边形架构,这些基础设施被视为具体实现,应该通过抽象接口,依赖倒置的策略,实现解耦。但是实际在大家的系统中,可以判断其易变性,如果长期保持稳定的话,可以减少依赖抽象这一层,直接依赖基础设施,减少抽象成本,在思考层面做到 less is more。

VSEF 的目录只是一个初始化、相对简单的系统结构。如果随着业务的发展,各个组成部分会逐渐臃肿,系统风格可能也会变化。所以需要引入一些主题的讨论,结合业务情况进行一些设计,并选取相关组件,进行集成,形成有具体组织特征的、新特性的应用结构。
VSEF 观点:演化后的系统结构,结合了功能特性,才是各个组织的合适的系统结构。
注重平台服务的:关注平台逻辑和扩展机制。
注重组件表达的:与用户有交互,需要关注组件化协议。
注重领域协作的:需要关注协调者的模型和设计、应用内的领域划分逻辑。
注重数据服务的:关注数据能力性能、功能范围、数据模型映射。
VSEF 主题
▐ 组件协议
如果系统是平台型的,并且带界面表达,那么需要解决的就是各个端、各个页面、各个业务不一样的扩展能力。在内部模型和视图模型之间增加一层ViewModel, 然后基于这个进行各种转换,是不错的思路,比较典型的组件有:奥创、Astore等。

这里细化开来,关于 ViewModel 能够有多定制,有2个不同的走向:
转换主要在组件框架中:在核心逻辑之外,进行各种框架植入,如奥创、Astore, 在数据出口侧进行转换,转换的手段一般是基于规则表达式,利用相关反射能力进行数据组装。
转换主要在业务扩展中:不想在组件框架中承载过多代码,想和业务普通扩展逻辑走的近一些,在系统执行过程中的扩展逻辑中,植入视图的扩展,可以较好匹配前台组件。
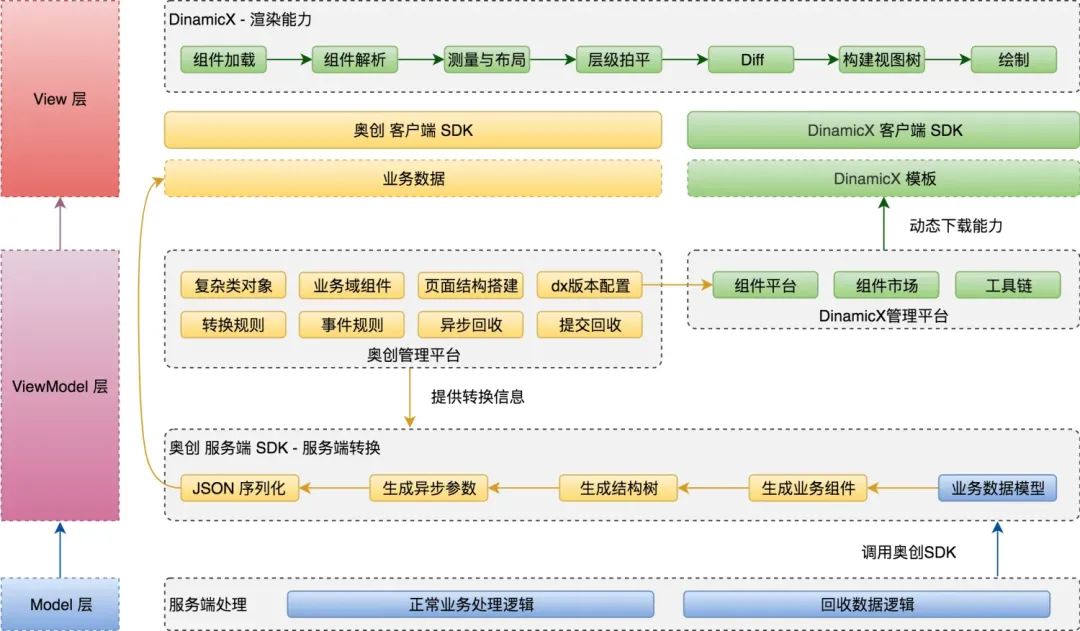
奥创&DinamicX 方案运行原理
▐ 活动编排
流程编排是对一个业务操作执行过程进行进一步的划分,常见的编排组件有:Tbbpm、SmartEngine 等。但在实际开发过程中,常常会有这样的疑惑:为什么是这几个节点?为什么是这样的顺序?
为什么是这些节点?
-
是不是调用了一个服务?那么准备服务参数,调用,返回结果判断可以包装为一个节点。 -
是不是都在操作一个对象?那么这些操作可以归类为:初始化,修改,转换等内聚的方法。 -
是不是一些通用的处理?比如安全校验、日志监控、数据统计等。 -
是不是存在业务扩展性?可以单独独立出来,作为抽象方法,或者使用组合,提供相关接口定义。

-
为什么是这样的顺序
-
上下文数据依赖 -
本身地位:需要对最终结果进行收口,需要最后执行。 -
系统框架要求必须进行初始化先执行 -
其它等等
-
每个顶点出现且只出现一次 -
若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面
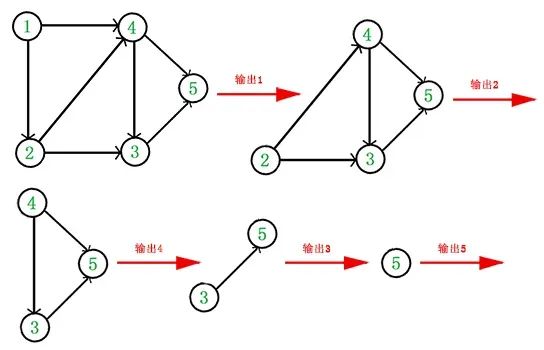
排序的背后是依赖
▐ 设计模式
-
模版方法 :模版方法是说对一个执行过程进行抽象分解,通过骨架和扩展方法完成一个标准的主体逻辑和扩展。平台和扩展能力的设计,做类比是比较合适的。基础的模版就是整个流程的编排和对应的节点,可扩展的地方就是各种业务定制区域。这样形成了平台和业务较好的融合。 -
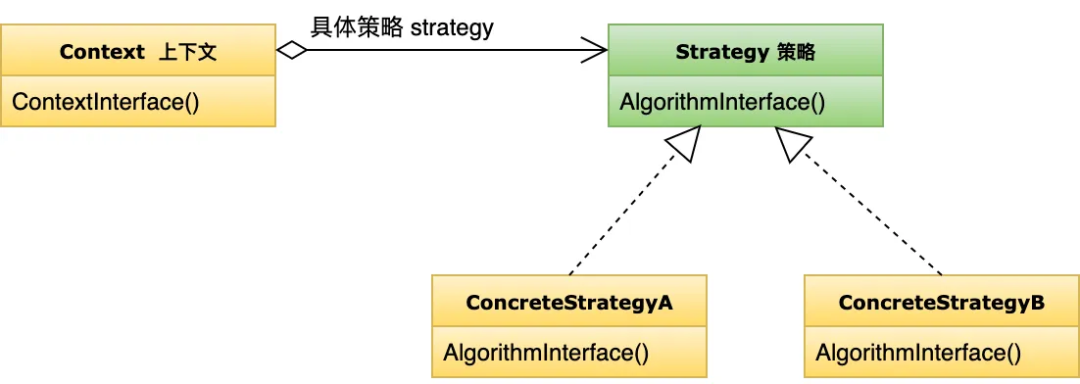
策略模式 :策略是说完成一个事情有不同的算法,可以进行相关切换。在逆向退款中,需要支持不同的退款链路,有些需要是担保交易,有些是保证金链路,有些是微信支付,有些是退卡、退资产。为了支持多种出账策略,采用了策略模式,可以通过扩展点定制各种资金策略。 -
责任链模式 :责任链是说将请求让队列内的处理器一个个执行,直到找到愿意执行的。扩展中,在执行回收结果的时候,会遍历实现的插件,并结合回收规则,进行及时的熔断。 -
观察者模式 :观察者模式是说我们通过注册、回掉这样的协作设计,完成变化通知的协作机制。系统间基于消息的观察模式还是很多的。通过消息的异步通知方式,既可以较好地进行解耦,也可以在失败时利用消息的重投机制,增加成功的概率。 -
中介者模式 :当多个类之间要协调的时候,往往引入中介者进行协调,减少大家的知识成本。系统中的流程执行过程中,会有一个大的上下文,这个上下文会协调各个领域的数据。
▐ 元数据
认知复杂性:度量理解软件所需要的努力,即捕获程序的逻辑流,并度量逻辑流的各种特性。
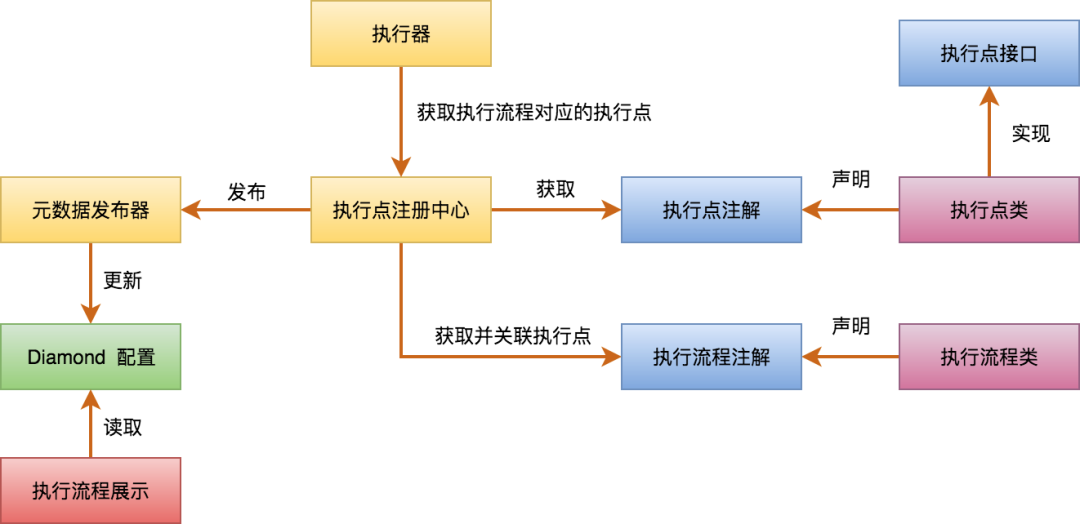
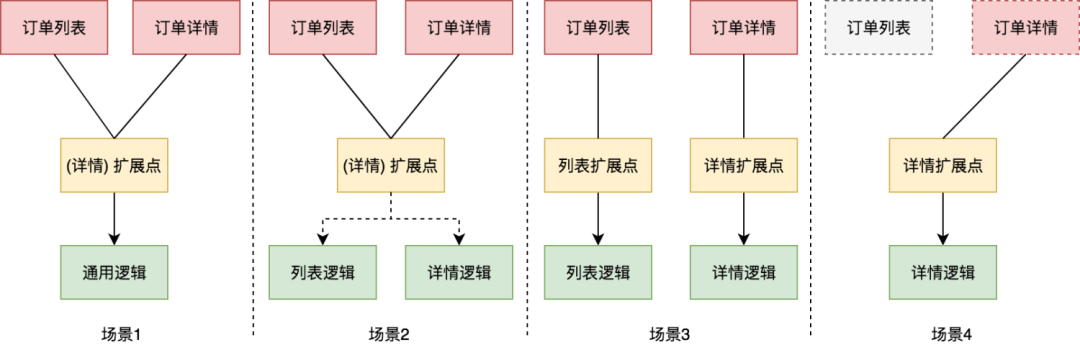
▐ 复用独立
单刃为刀,双刃为剑。们在用这个双刃剑的时,当一面对着敌人,另一面一定会对着自己,这时如果将剑刃对着敌人砍去的时候,敌人用兵器一挡,剑就会反弹回来,对自己就会有一定的危险。
代码复用是一把双刃剑。复用意味着代码的影响面会增加,虽然提高了开发效率,但是一但进行改动,影响范围变大的副作用也很明显:要求你得足够了解影响的范围,进一步增加了认知的复杂性。在影响较大的情况下,不合理的复用会产生很多令人崩溃的补丁逻辑。
有时,为了业务独立快速迭代,会独立逻辑,因为我们预判一直演化下去最终可能会产生两份完全不同的代码。
有时,虽然业务逻辑看上去不太一样,但是我们会收口到一起,尽量复用一份逻辑,因为我们预判发展下去会产生更多的复用逻辑。
到底是分还是合?哪些要复用?哪些要独立发展?显然与我们的预判息息相关。总的来说,离“业务”越近的地方,应该越尽可能独立,离“平台”越近的地方,应该近可能复用,代码是否稳定是重要的判断因素。
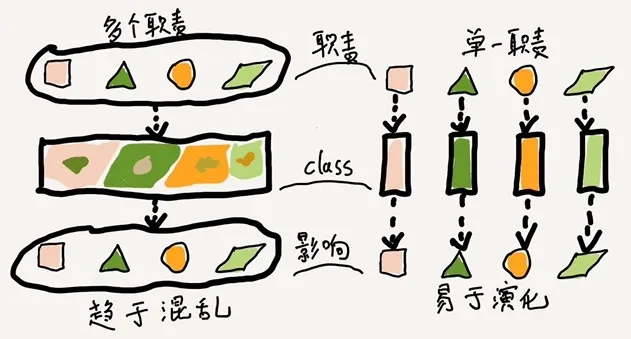
▐ 领域划分
在VSEF里面,淡化了领域的概念,因为认为领域都在网关服务里面,而系统本身的领域,则分散在能力里面,对外整体作为一个领域。
-
思想一:看核心管理数据载体。 我们可以认为一个域实际上是一个或多个实体对象的信息集合,并对所管理的实体对象的生命周期进行管理。 -
思想二:确定核心白名单,其它可扩展。 既然无法维护一个涵盖整个企业的统一模型,那就不要再受到这种思路的限制。通过预先决定什么应该统一,并实际认识到什么不能统一,我们就能够创建一个清晰的、共同的视图,然后需要用一种方式来标记出不同模型之间的边界和关系。
此外,我们常常会发现划分调整的背后事务:
调整的内容:其实是匹配生产关系。
调整的原则:追求职责的内聚,精细化分工。
不断调整的原因:业务在发展,内聚的标准需也要与时俱进。
从关联的角度看,往往我们看组织架构,就能看到领域的边界,核心原因还是组织架构也是要适应生产关系,follow更优解的结构,是相辅相成的,也就能互相窥探。
▐ 逻辑模型
在数据库操作的时候,在数据服务的路口,选择逻辑模型是天然的一个选择。比如属性,在逻辑模型中可能是一个map,在DO中是一个String,如果使用DO流转,就会非常不方便。
这里还可以探讨的是,逻辑模型应该如何抽象?要不要聚合多个表。最容易理解、维护以及发展的情况,当然是领域模型与数据模型能够形成1:1的维护关系。但是由于底层数据很难变动,而理解和业务发展是与时俱进的,当我们持续设计的时候,逻辑模型势必会不太一样。常见的一些场景有:
一个逻辑模型维护一个表:这个是比较简单的场景,一个逻辑模型直接负责一个表,比较干净易理解。
多个逻辑模型共享一个表:这个是因为表中记录的数据比较多,但是实际上有不同的领域数据存的冗余储,比如交易订单上的营销优惠信息、资金信息、物流信息等。
一个逻辑模型维护多个表:当我们对原始的领域重新划分,又不能重新建立表结构的时候,对于较大的一些域,往往数据来自多个表,这时候就会遇到这样的情况,一个领域模型要从多个数据库表里面聚合数据。
聚合逻辑模型的复杂情况:这个在DDD里面主要是聚合根这样聚合了多个实体的情况。举个例子来说,资金单有支付单、垂直表、还有多个支付单,这样的聚合关系就更加复杂了。

▐ 模型策略
-
共享内核 shared kernel :通常是共享核心领域或者是一组通用子领域。 -
客户/供应商关系 customer/supplier :上下游关系。不同客户需要协商来平衡,上游团队需要有自动测试套件。 -
跟随者模式 conformist :单方面跟随模式。上游的设计质量较好,容易兼容,可以采用严格遵循上游团队的模型。 -
防腐层 anticorruption layer :防腐层、隔离层,使用 facade 等模式,减少其它系统变动对本系统的影响。 -
各行其道 separate way :声明一个与其它上下文毫无关联的限界上下文,使开发人员能够在这个小范围内找到简单、专用的解决方案。

▐ 扩展机制
如果只是基于模式扩展,可能采用一些局部的策略模式就可以了。但是如果期望服务多个业务,且期望隔离业务定制,那么就需要提供一些插件包,隔离权责出来。
每个层次都可以设计自己的扩展机制
无论是扩展框架TMF的迭代,还是后面星环体系的提出,一个重要的目的是为了解决“业务和平台的隔离”,这也是开闭原则的重要体现。核心逻辑应该由比较熟悉的平台人员进行控制,应该尽量通用,较少修改;扩展逻辑应该由业务开发人员理解,应该尽量灵活,便于调整。
往系统内部看,其实还有很多域能力的扩展,比如:支付的时候可以走直连支付宝,也可以经过支付系统链接到微信等非支付宝渠道。这样的扩展,也是开闭原则的体现,只是离核心流程更近,影响面更大。
往扩展外部看,即使是业务APP包、产品包等插件内部,还是可能会服务多个行业、多个场景,可能有很多的再次路由与扩展。比如:淘系要服务很多行业,服饰、家电等,不同业务定制也不太一样,往往会用一些策略、责任链的扩展模式。

组件选取
不同业务组织,在进行相关主题的讨论与思考后,会定制一套适合自己的发展结构。后面在快速启动的时候,期望有一些复用的组件。这部分组件,分为外部市场的组件,和自己建立的组件。
组件分为市场已有的组件,还有自己期望自建的组件,这里VSEF框架中会提供一些概念组件。
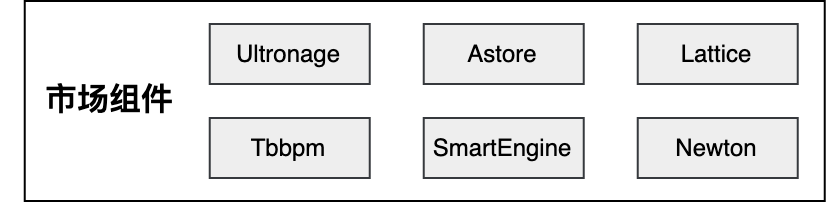
▐ 市场组件
市场组件应该被优先选择,因为那个是服务更多场景的,有更强的包容性。当然,如果系统比较小除外。如果定位比较大,那么还是建议及早引入,随着流量的增加,理解也不断增加,越到后面,越能巧妙应用。
交易系统中使用的一些组件举例如下:
协议化组件:Ultronage、Astore
流程编排组件:Tbbpm、SmartEngine
扩展组件:Lattice、TMF
配置化组件:Newton
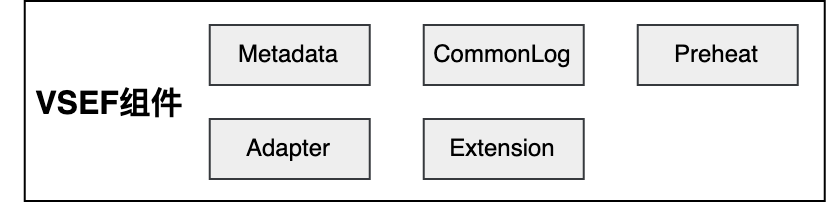
▐ VSEF组件
-
元数据组件 :Metadata , 期望能够生成知识索引数据。 -
日志组件 :CommonLog,期望能够统一格式,方便统一监控、清理。 -
预热组件 :Preheat,期望能够抽象接口预热方式,便于预热操作。 -
适配器组件 :Adapter,一些市场组件的抽象包装,快速集成。 -
扩展组件 :Extension,简单扩展组件,解决系统扩展性问题,且不那么得重。
VSEF组件的一些案例

本文介绍了一些简洁架构VSEF的一些框架结构理解,并且抛出了一些演化的主题,这些主题的不同思考会让系统发展成不同的风格,实际也是应用定位的必然结果。最后介绍了一些组件的部分,这个部分应该是水到渠成的结果,而不应该是事先预设的标准。

本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。