本篇继续使用CIFAR-10数据集进行机器学习步骤的展示,本篇可以与上篇博客连续一起阅读CIFAR-10数据集详解与可视化-CSDN博客

进行批次训练的意义
上篇博客中,我们通过torchvision.datasets.CIFAR10语句获得了数据集的内容,并通过transforms的方式将数据转换成了图片张量的储存形式,从方法上来说其实是可以直接将数据放进自己定义好的模型里面进行训练的,但是从数据集的角度进行分析,训练的数据集就有50,000多张图片以及对应的标签,测试集也有10,000多张图片以及对应的标签,每次迭代训练一次性把全部训练集的数据放进模型里进行参数的更新,不仅使每次参数更新的周期延长,存在内存溢出的风险,而且会使训练出来的模型受数据集本身存在噪音的影响更大,综合分析,在机器学习中进行分批次训练的意义总结如下:
- 提高计算效率:当训练数据集非常大时,将所有数据一次性载入内存进行训练可能会导致内存溢出。通过将数据集划分为多个批次,可以在每个批次中使用部分数据进行模型训练,从而节省内存资源。
- 减小噪音影响:对于噪声数据,如果一次性全部处理,可能会对模型产生很大的影响,导致模型性能降低。而分批次处理数据,可以减小噪声数据对模型的影响。
- 错误反向传播:在神经网络训练过程中,需要进行反向传播算法来调整神经元的权重,这需要计算损失函数对于权重的梯度。如果采用批量训练方法,可以在每个批次中计算梯度并更新权重,这样可以加速训练过程。同时,每个批次的梯度方向也可以提供一定的随机性,有助于模型跳出局部最小值,找到更好的优化结果。
- 可以更好地拟合数据规律:批次训练的优势之一是模型可以在一个批次内部学习到的一些潜在规律,可能可以在下一批次的训练中取得更好的效果。
分批次处理数据集代码实现
需要导入的库:
import torch
from torchvision import transforms,
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10下载获得数据集/已下载则从路径上读取数据集,注意download参数的设置
# 获得数据集数据
my_trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意以下路径更改为你需要下载数据集的路径或者已经下载好的数据集的路径
train_dataset = CIFAR10('D:/deep_learning/12_16/data/', train=True, transform=my_trans, download=False)
test_dataset = CIFAR10('D:/deep_learning/12_16/data/', train=False, transform=my_trans, download=False)
进行批次设置
# 批次迭代器的生成
train_boarder = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_boarder = DataLoader(test_dataset, batch_size=10)batch_size就是每一个批次的数据大小,这里设置成每个批次有10个数据放进训练,shuffle表示打乱训练的数据的次序,提高模型的泛化能力
值得注意的是,Dataloader函数返回的是生成器,也就是迭代返回,其函数是通过yeid返回的,我们用代码来打印出生成的train_boarder
<torch.utils.data.dataloader.DataLoader object at 0x000001550DFA0EB0>对数据有直观查看,方法之一就是将生成的数据转换成迭代器
# 生成迭代器
train_boarder_see = iter(train_boarder)
# 赋值到第一批次(前10个数据)的图像和对应标签
imgs,labels = next(train_boarder_see)
print(imgs.shape)
print(labels.shape)打印出来的结果为
# imgs
torch.Size([10, 3, 32, 32])
# labels
torch.Size([10])可以看到,imgs数据已经是标准的图像张量的形式,即[B,C,W,H],分别对应批次数量,通道数,像素宽度,像素高度,labels也是这一个批次中十个数据图像所对应的10个标签数据,这样处理后,数据就能方便地被放进模型中进行训练;数据格式的统一,同样也方便损失函数的计算以及优化器的更新
实践对比
为了让大家更直观的感受批次训练的效果,本篇博客附带一件资源代码,使用CIFAR10数据集进行模型的训练与评估,大家就可以在训练批次里做调整,不使用分批次训练的方式就将batch_size设置为1,使用分批次训练的方式就将batch_size设置成对应的批次大小
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import time
# 设置批次的大小
train_batch_size = 1
test_batch_size = 1
# 设置数据集的下载/储存路径
data_path = r"这里放入CIFAR10的路径"
# 创建多进程时防止报错
if __name__=='__main__':
my_trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# my_trans = transforms.Compose([transforms.ToTensor()])
train_dataset = CIFAR10(data_path, train=True, transform=my_trans, download=False)
test_dataset = CIFAR10(data_path, train=False, transform=my_trans, download=False)
train_boarder = DataLoader(train_dataset, batch_size=train_batch_size, num_workers=5, shuffle=True)
test_boarder = DataLoader(test_dataset, batch_size=test_batch_size, num_workers=5)
# 搭建网络模型
class CNNnet(nn.Module):
def __init__(self):
super(CNNnet,self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=2), nn.MaxPool2d(2, 1))
self.layer2 = nn.Sequential(nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1), nn.MaxPool2d(2, 1))
self.fc1 = nn.Linear(3200, 128)
self.out = nn.Linear(128, 10)
def forward(self,x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
# print(x.shape) # [4, 32, 5, 5]
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.softmax(self.out(x), dim=1)
return x
# 模型送入GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
print(device)
model = CNNnet()
model.to(device)
# 定义损失函数和优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_funcation = nn.CrossEntropyLoss()
# 模型训练
epoch_num = 10
time1 = time.perf_counter()
for epoch in range(epoch_num):
train_loss = 0
train_acc = 0
model.train()
for imgs, labels in train_boarder:
imgs = imgs.to(device)
labels = labels.to(device)
out = model(imgs)
loss = loss_funcation(out, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item()
_,pred = out.max(1)
correct_num = (pred == labels).sum().item()
train_acc += correct_num/imgs.size(0)
train_acc_all = train_acc/len(train_boarder)
train_loss_all = train_loss/len(train_boarder)
model.eval()
test_loss = 0
test_acc = 0
for imgs, labels in test_boarder:
imgs = imgs.to(device)
labels = labels.to(device)
out = model(imgs)
loss = loss_funcation(out, labels)
test_loss += loss.item()
_,pred = out.max(1)
correct_num = (pred == labels).sum().item()
test_acc += correct_num/imgs.size(0)
test_acc_all = test_acc/len(test_boarder)
test_loss_all = test_loss/len(test_boarder)
print('epoch:{}, Train Loss:{:.4f}, Train Acc:{:.4f}, Test Loss:{:.4f}, Test Acc:{:.4f}'.format(epoch, train_loss_all, \
train_acc_all, test_loss_all, test_acc_all))
time2 = time.perf_counter()
time_using = time2-time1
print("消耗的时间:",time_using)
代码中使用比较简单的模型进行训练,迭代训练次数只设置到了10次,主要目的是对比批次训练的效果,不分批次训练的打印结果
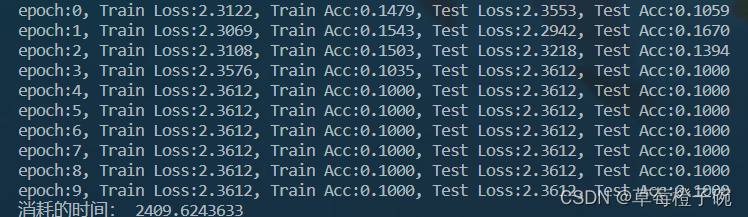
批次设置为10的训练结果

非常明显,不分批次训练时,模型的准确率提高不大,且消耗时间大,分批次训练后,模型准确率有明显的提升,且消耗的时间明显下降
欢迎大家讨论交流~