import re
import sys
import requests
from lxml import etree
import requests
import requests
cookies = {
'SNUID': 'D853A081EFF6FEA1A2DF44E7F083E7ED',
'SUV': '001B49DC6E50A328659A03A63CC38863',
'wuid': '1704592295136',
'FUV': 'e684f4ff4b2c2f2569315844b34c2cf4',
'search_tip': str(1704592346673),
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'SNUID=D853A081EFF6FEA1A2DF44E7F083E7ED; SUV=001B49DC6E50A328659A03A63CC38863; wuid=1704592295136; FUV=e684f4ff4b2c2f2569315844b34c2cf4; search_tip=1704592346673',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
while True:
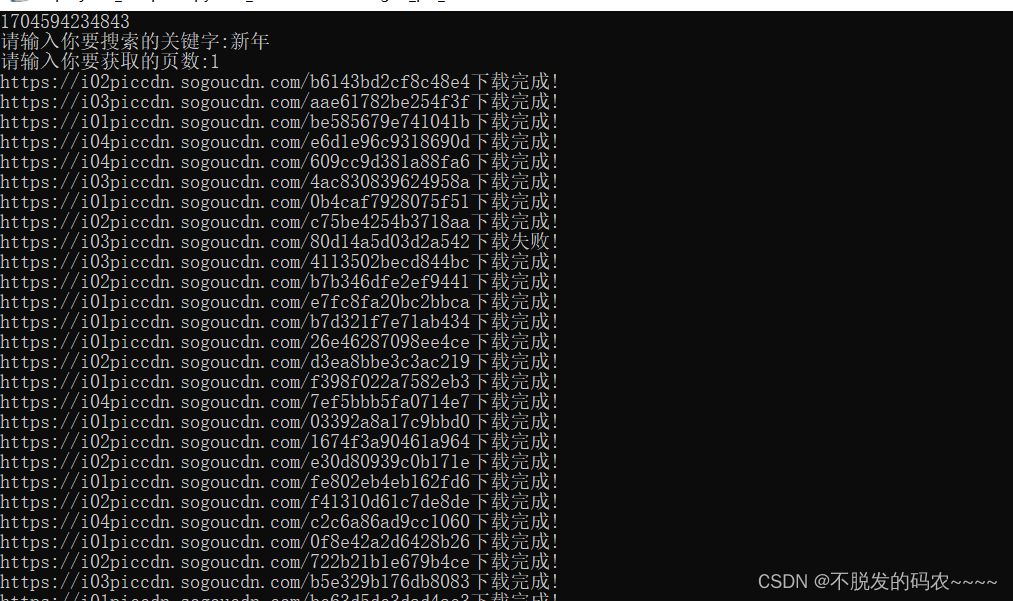
keyword=input("请输入你要搜索的关键字:")
page=input("请输入你要获取的页数:")
for i in range(int(page)):
params = {
'mode': '1',
'start': f'{48*i}',
'xml_len': '48',
'query': keyword,
}
response = requests.get('', params=params, cookies=cookies, headers=headers)
# print(response.text)
pic_url_lst=re.findall('\"thumbUrl\"\:\"(.*?)\"\,',response.text)
title_lst = re.findall('\"title\"\:\"(.*?)\"\,', response.text)
for item in list(zip(title_lst,pic_url_lst)):
try:
response=requests.get(item[1])
with open(item[0]+".png","wb")as fp:
fp.write(response.content)
print(item[1] + "下载完成!")
except:
print(item[1]+"下载失败!")
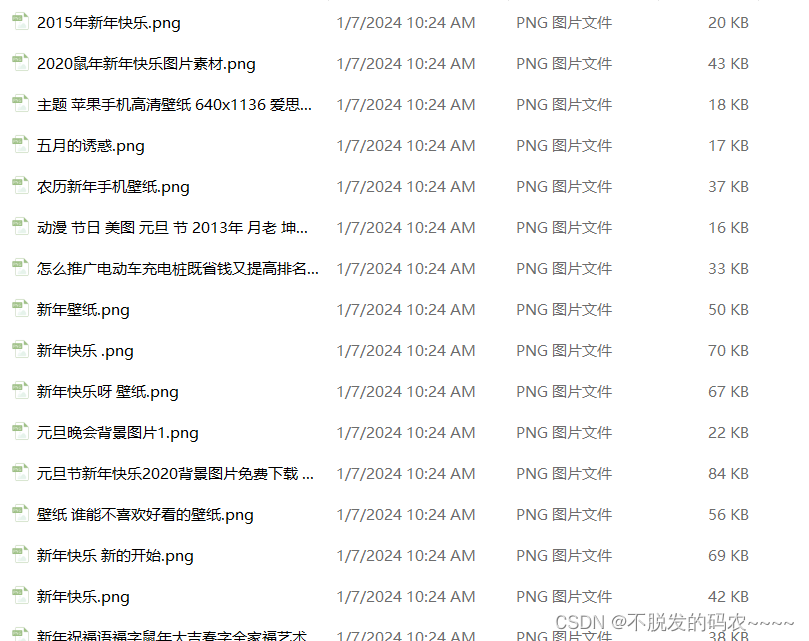
效果图