将所有Unicode十进制数字字符,转换成ASCII版数字字符:
import unicodedata ,sys
digitmap = {c:ord('0') + unicodedata.digit(chr(c))
for c in range(sys.maxunicode)
if unicodedata.category(chr(c)) == 'Nd'}
print(len(digitmap))
#print(digitmap)
x='\u0661\u0662\u0663'
print(x)
print(x.translate(digitmap))
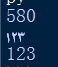
运行结果如上。580,表示现在Unicode里面有580个数字字符(即58种1-10的表示方法)
将字符串处理成只有ASCII字符:
import unicodedata ,sys
print()
a = 's\u00f1o'
print(a)
print(ascii(a))
b = unicodedata.normalize('NFD',a)
print(b)
print(ascii(b))
print()
result1 = a.encode('ascii','ignore').decode('ascii')
print(result1)
result = b.encode('ascii','ignore').decode('ascii')#这里的ascii可以改成你想处理成的任何编码格式
print(result)
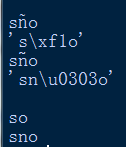
运行结果如上。如果ñ是全组成的,那么就会被消掉。如果ñ是组合字符,那么只会去掉~符号。一般由于UTF-8使用方便,所以程序里面的ascii改成utf-8就可以了。
将字符串处理成只有UTF-8字符:
def to_utf8(s):
result = s.encode('utf-8','ignore').decode('utf-8')
return result
encode()与decode():
str对象可以使用encode(XXX),返回bytes对象。此bytes对象,是根据字符和某种编码方式里面的对应关系(实际是该字符在该编码方式下存储的字节),即若干十六进制数。

比如这个“上”字,它用utf-8来存储,实际存储的是b'\xe4\xb8\x8a'。
用gbk来存储,实际存储的是b'\xc9\xcf'。
所以当你拿到了bytes对象,并且知道了这个某个字符串在计算机实际存储的字节,但你还得知道这是那种方式转换而来实际存储字节,知道到底这是utf-8还是gbk或者别的编码方式的实际存储方式。
bytes对象可以使用decode(XXX),返回str对象。根据实际存储的字节和某种编码方式,通过编码方式的对应关系,把存储字节转换为字符。

如图所示,b'\xe4\xb8\x8a'本来是utf-8的一条对应关系,但是gbk中却没有这条对应关系所以报错,而且这个可能也跟utf-8用三个字节来存储一个汉字,gbk只用两个字节来存储一个汉字有关。
总之,在对bytes对象使用decode(XXX)时,一定要搞清楚bytes对象是通过哪种编码方式来的(即encode(XXX)里的XXX),再使用同样的XXX。