1、Series
1.1 定义及创建
- Series是一种类似于一维数组的对象,由下面两个部分组成:
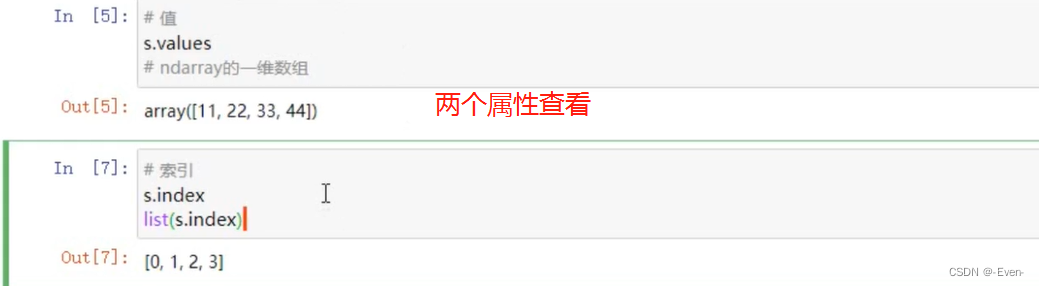
- values:一组数据(ndarray类型)
- index:相关的数据索引标签

-
导包
import numpy as np import pandas as pd -
两种创建方式
-
由列表或Numpy数组创建
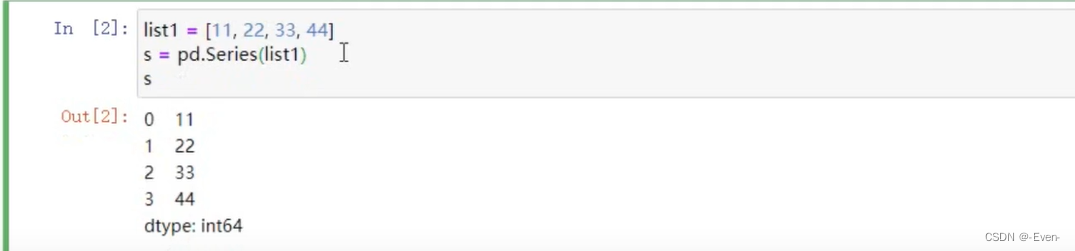
——————————————————————————————分隔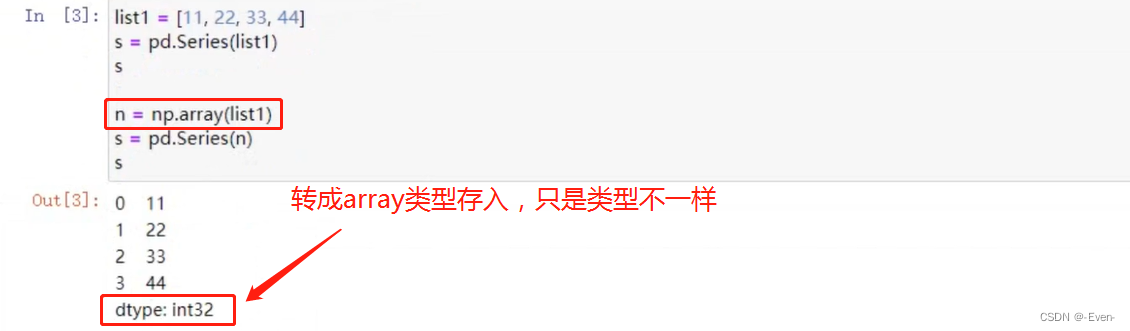
——————————————————————————————分隔
-
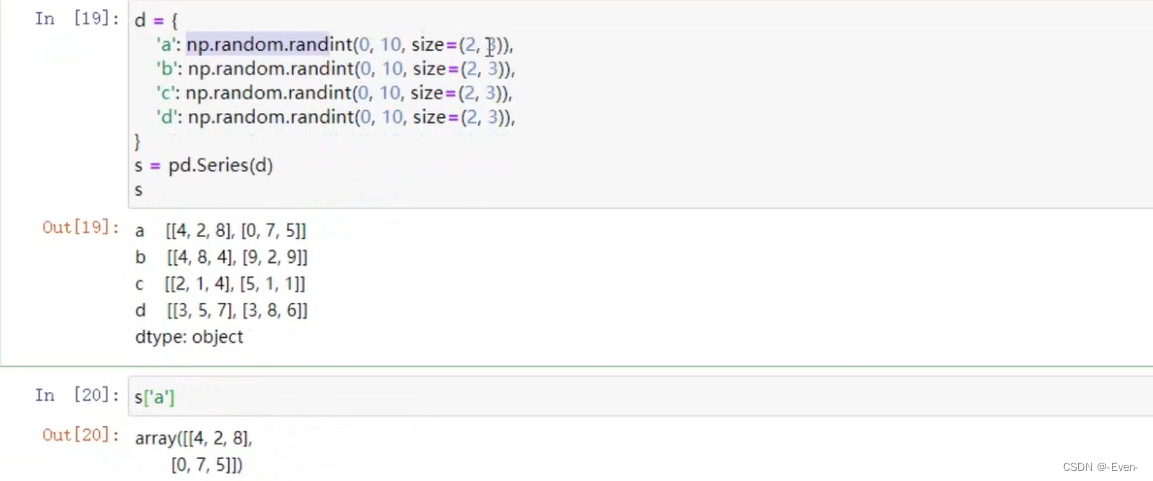
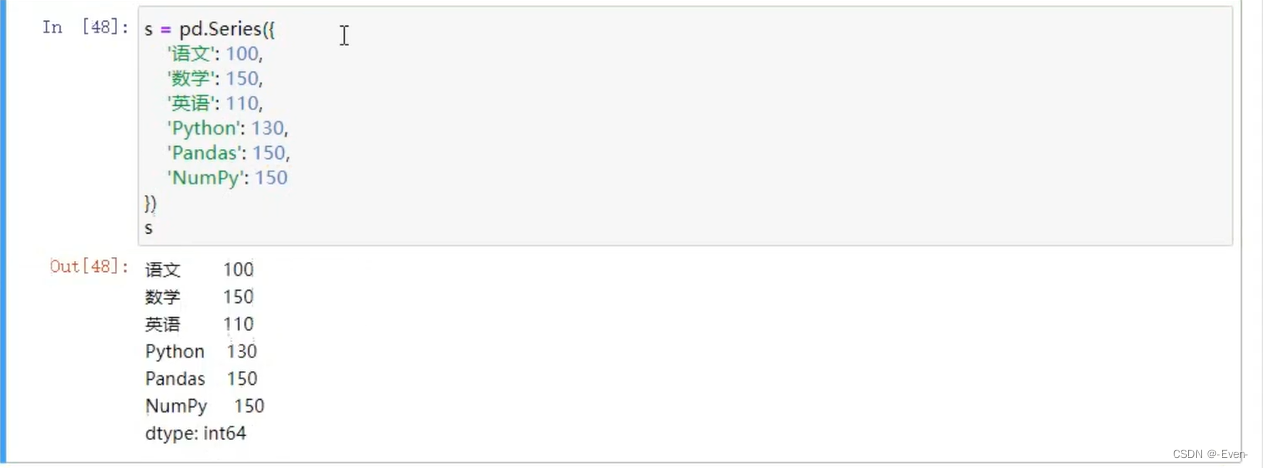
由字典创建
-


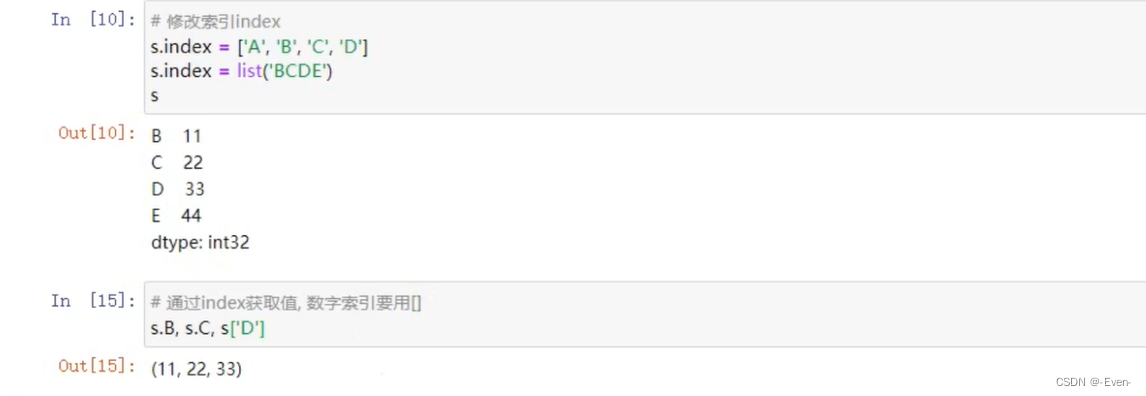
1.2 索引
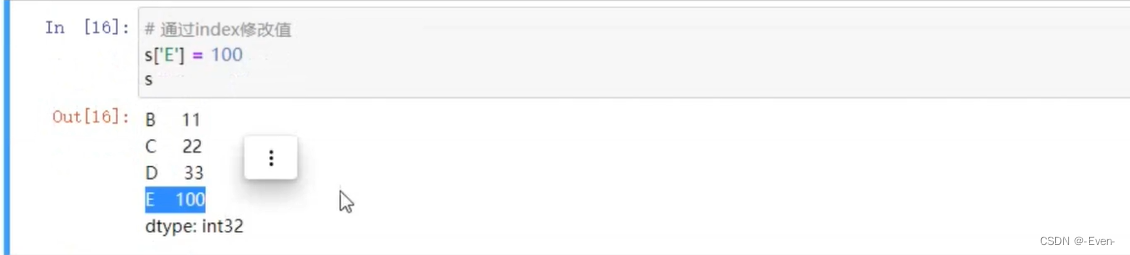
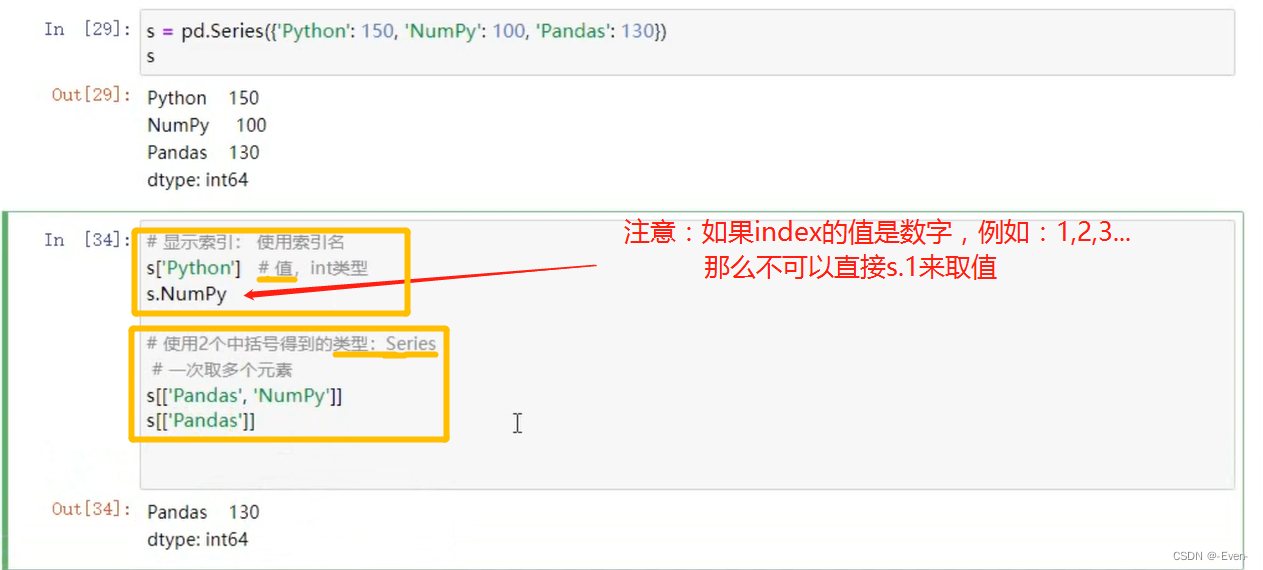
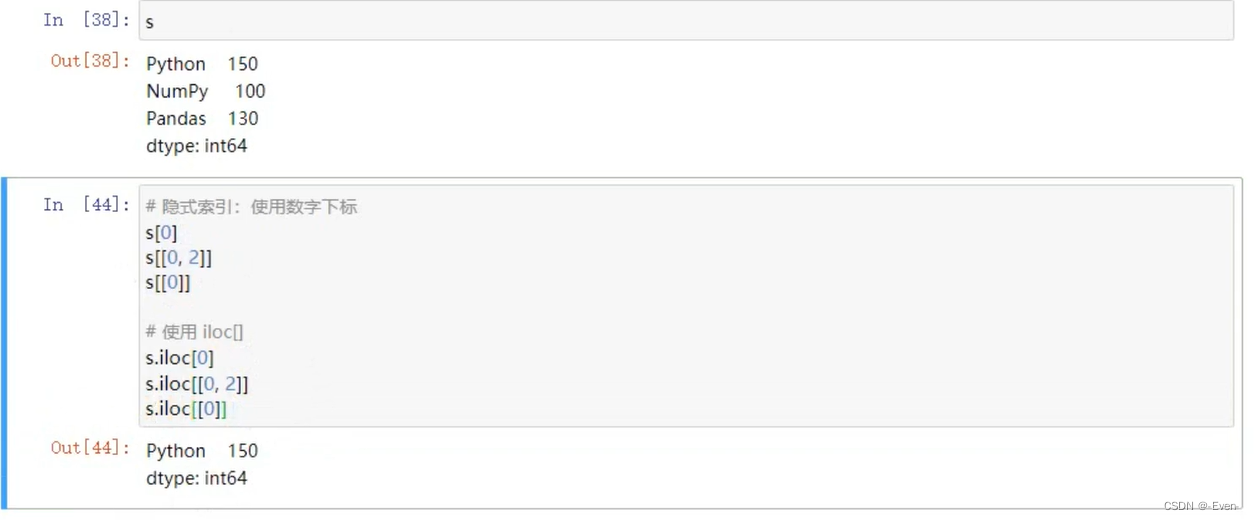
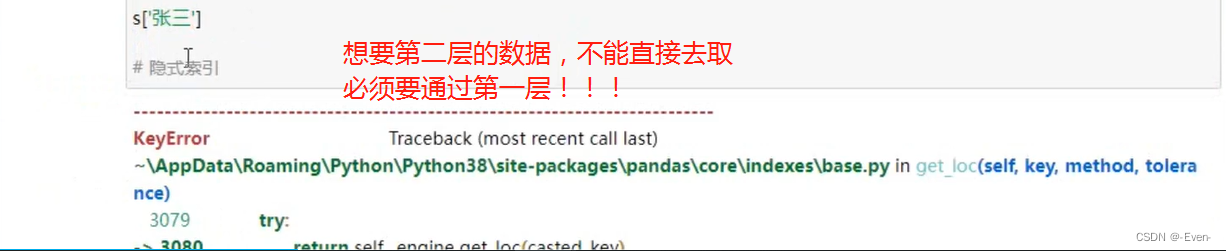
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的仍是一个Series类型)。分为显示索引和隐式索引。
1.2.1 显式索引


1.2.2 隐式索引


1.3 切片
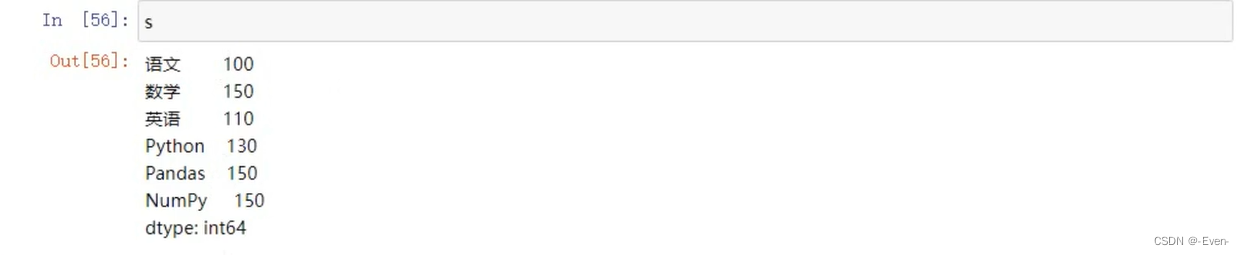
1.3.1 基本属性和方法














1.3.2 隐式切片
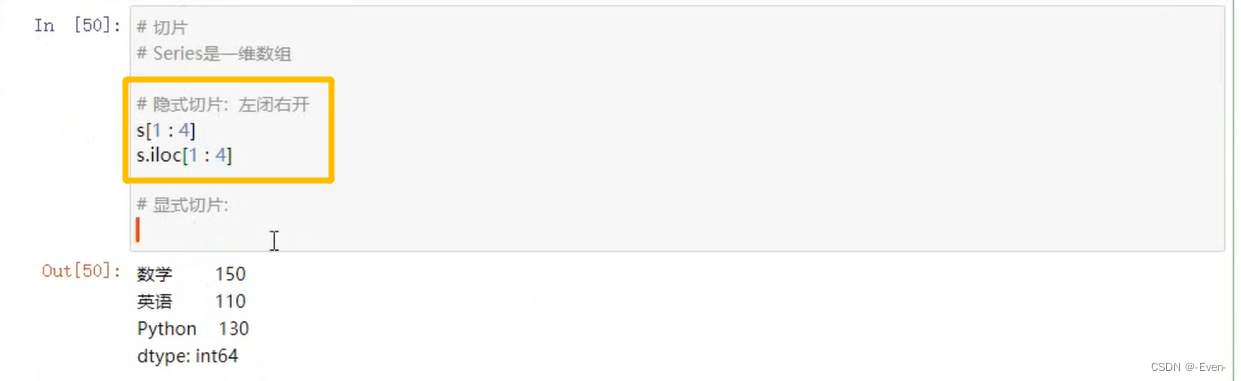
1.3.3 显式切片

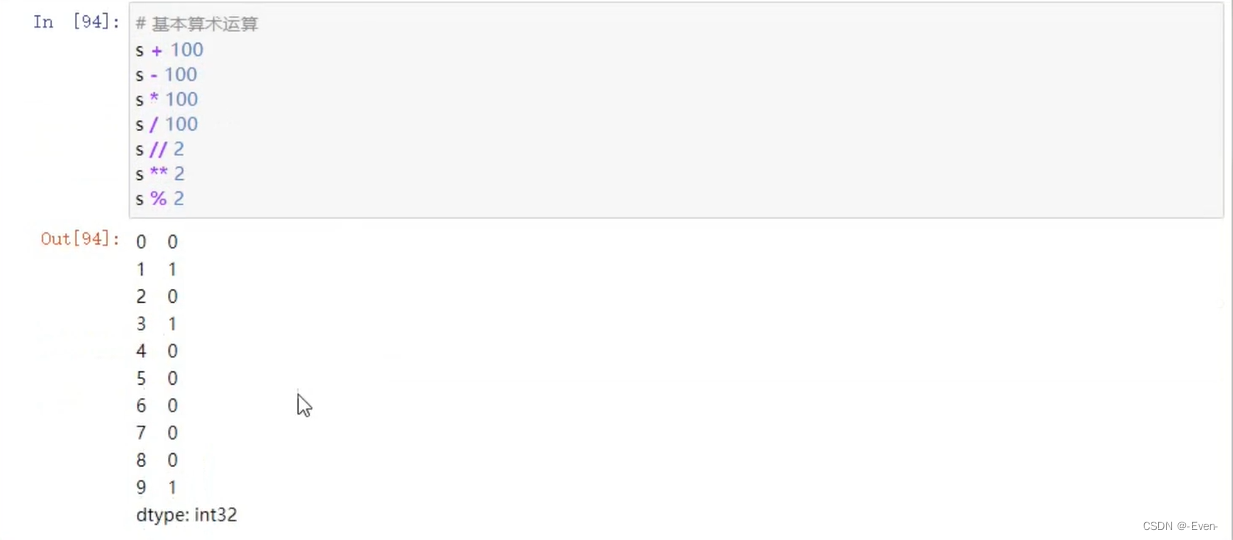
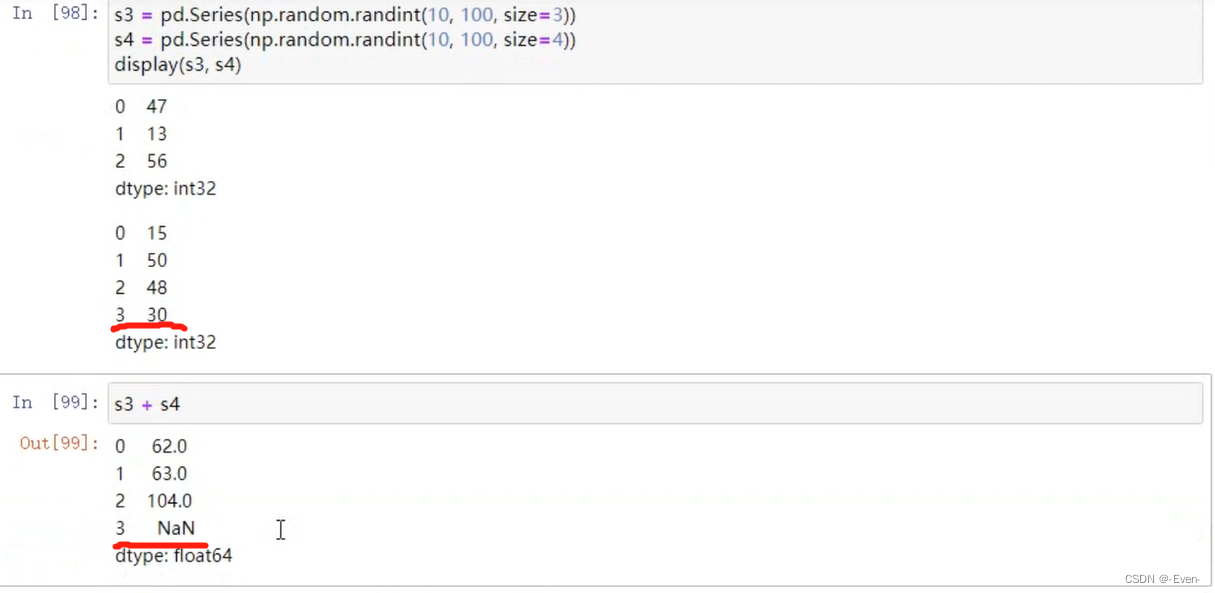
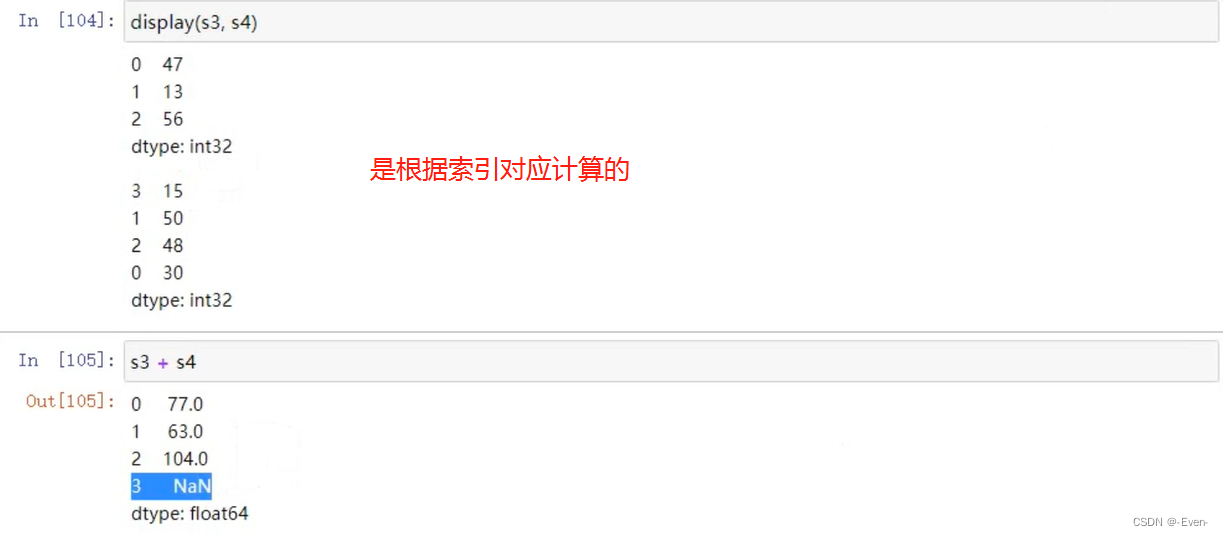
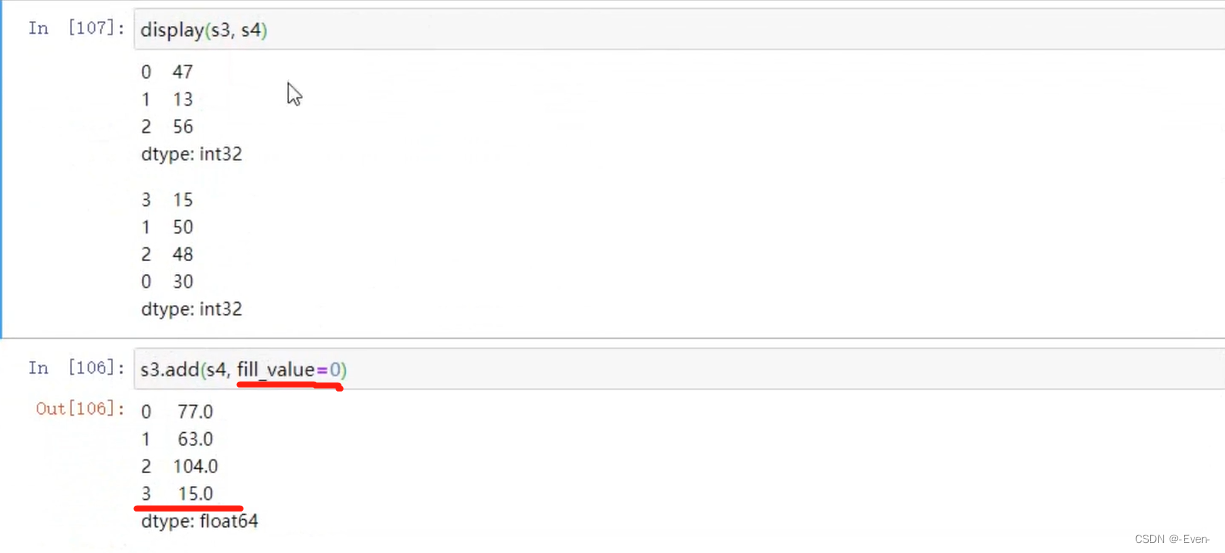
1.4 运算
1.4.1 适合于Numpy数组的运算也适用于Series
1.4.2 Series之间的运算



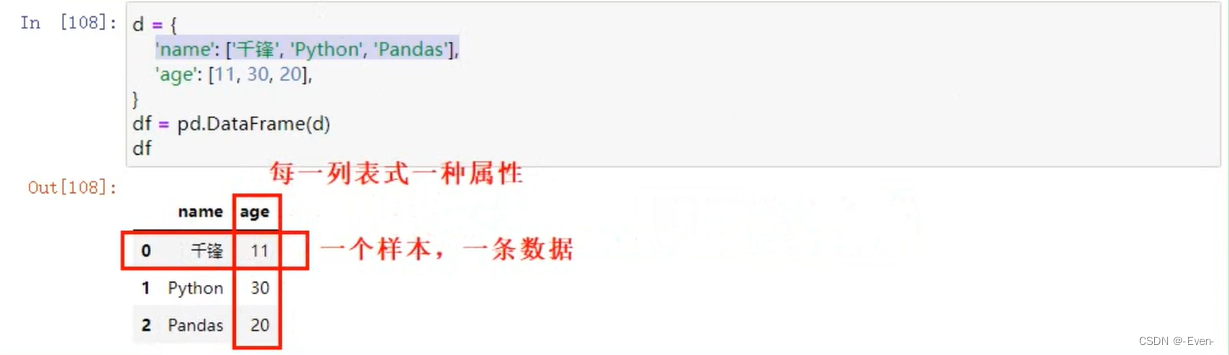
2、DateFrame
- DateFrame是一个【表格型】的数据结构,可以看做是[由Series组成的字典](共用同一个索引)。
- DateFrame由一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。
- DateFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(Numpy的二维数组)
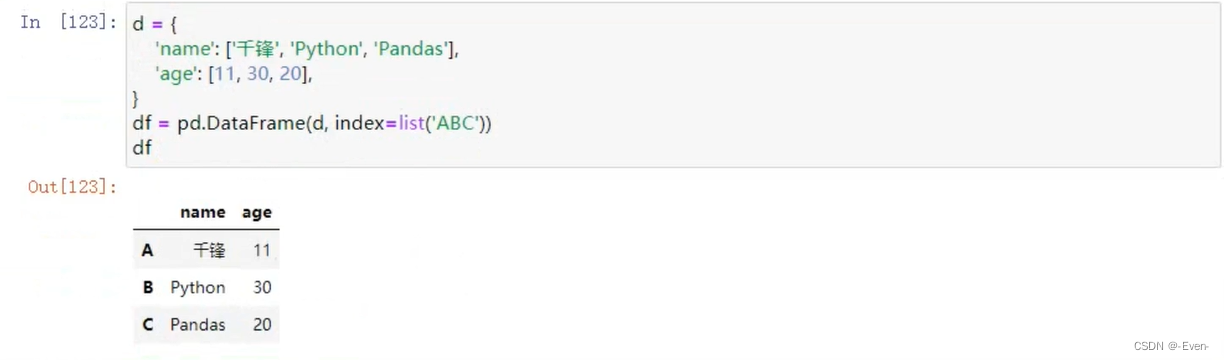
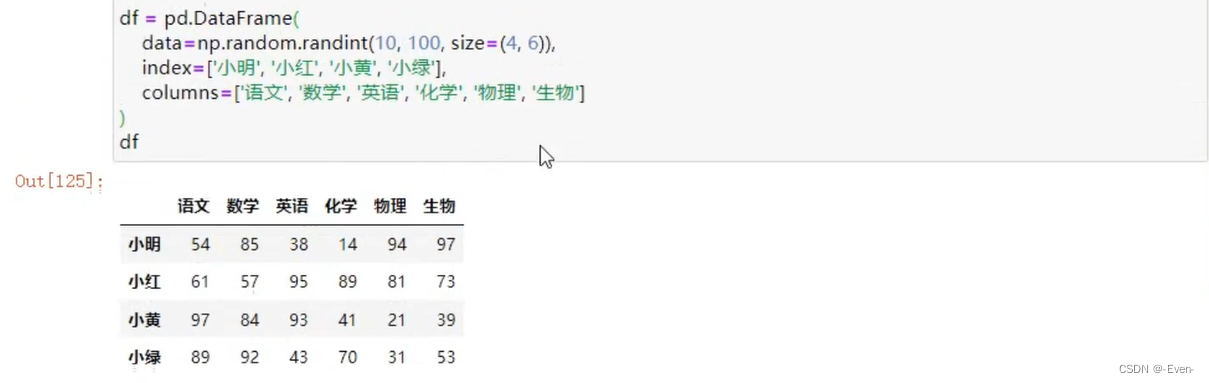
2.1 创建

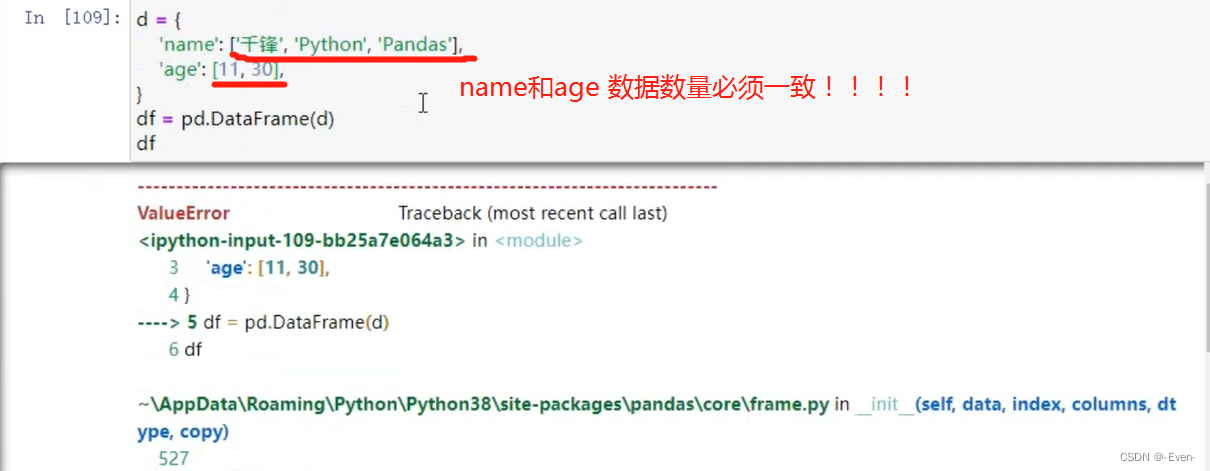
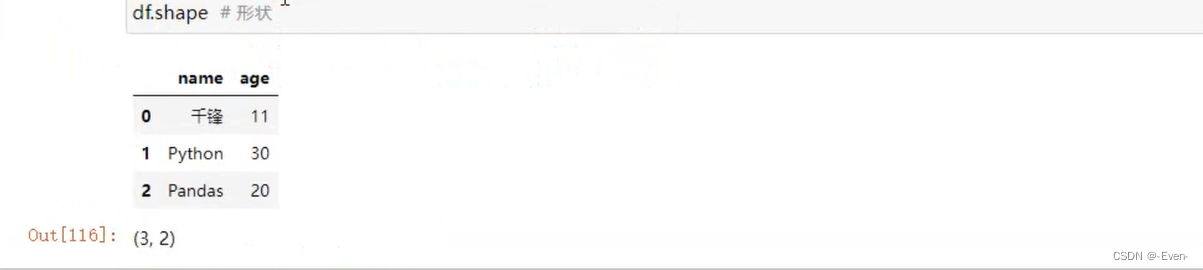
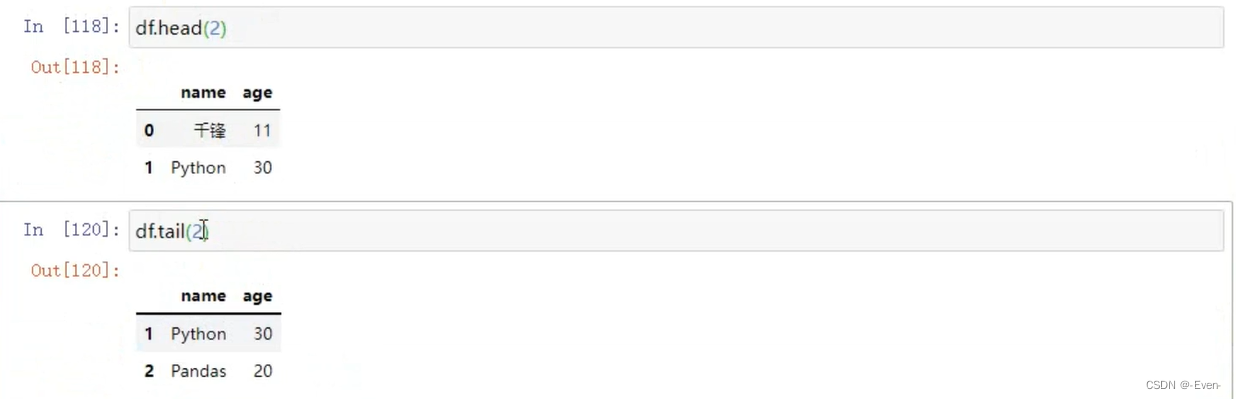
2.2 基本属性和方法

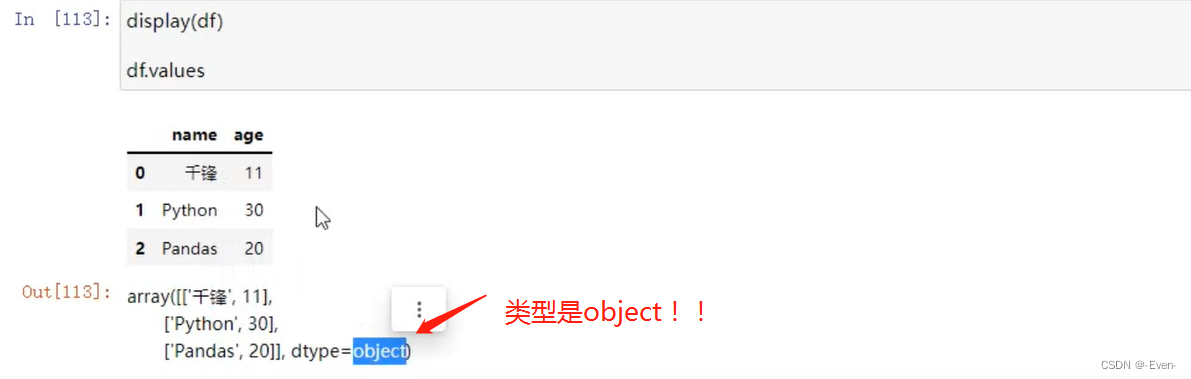
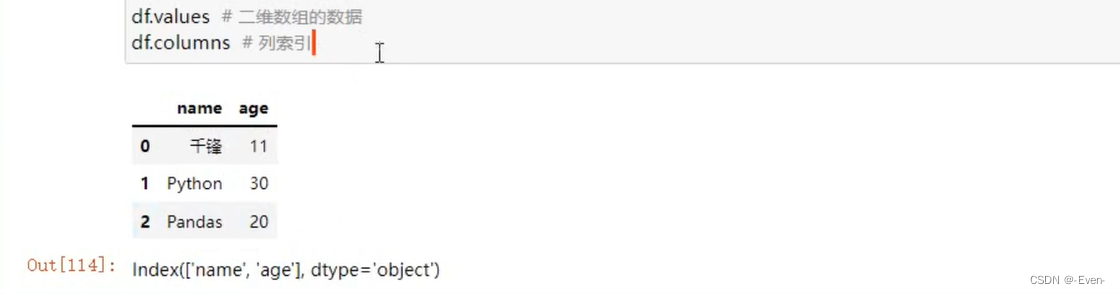
————————分隔————————————————————————
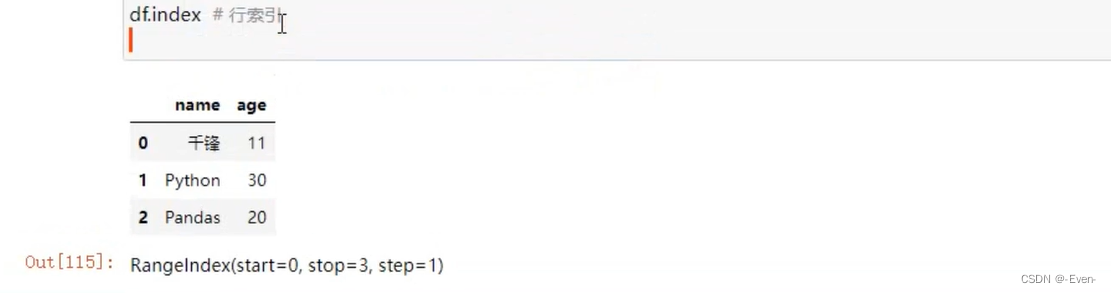
————————分隔————————————————————————
————————分隔————————————————————————
————————分隔————————————————————————

————————分隔————————————————————————

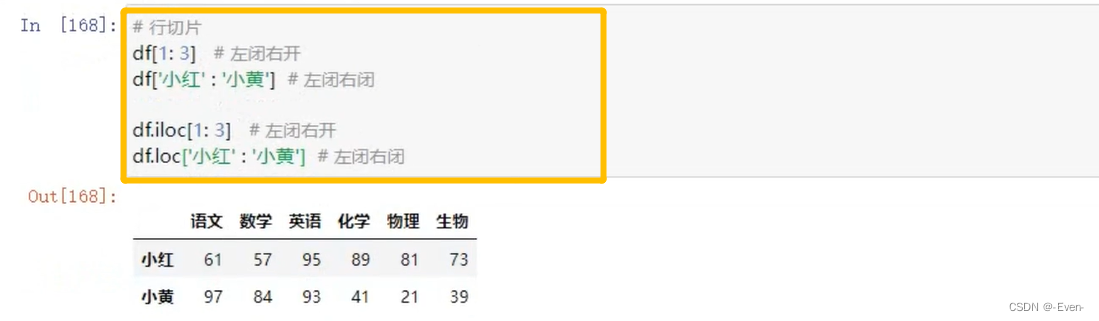
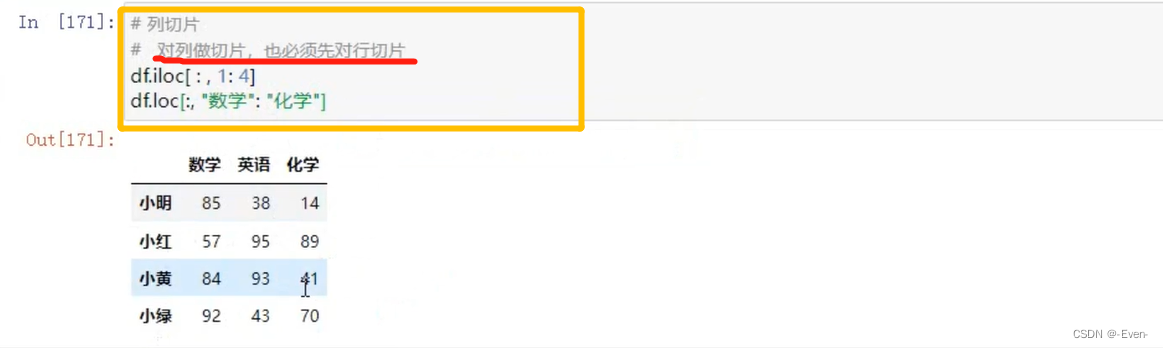
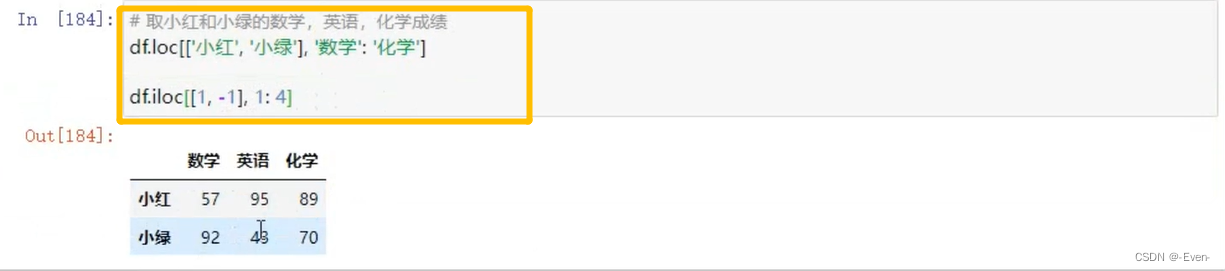
2.3 切片


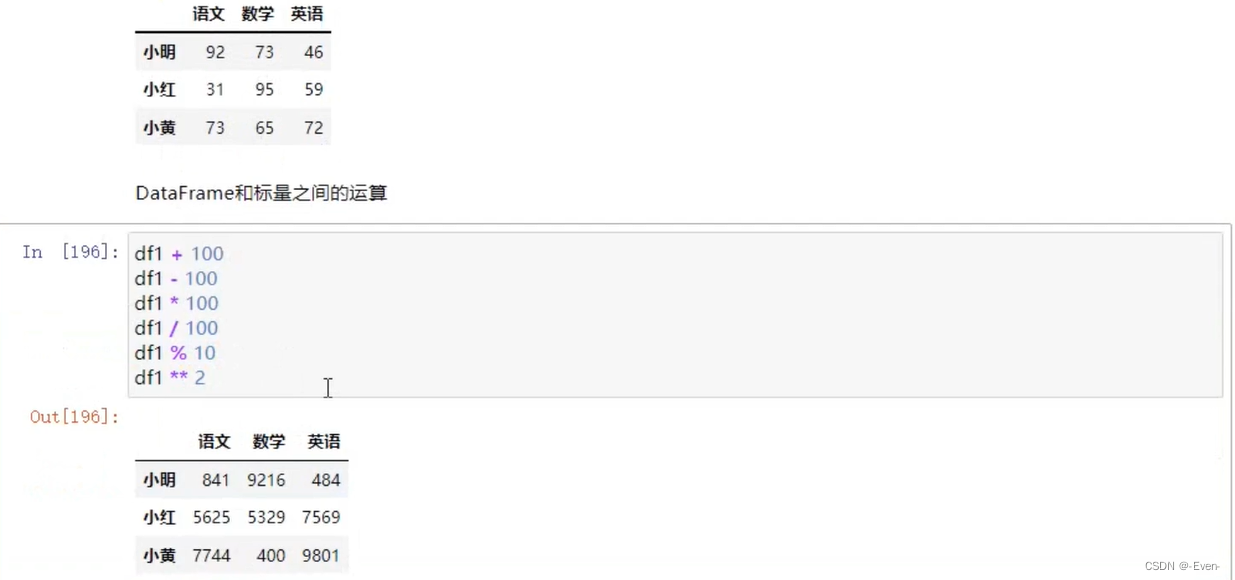
2.4 运算

————————分隔————————————————————————
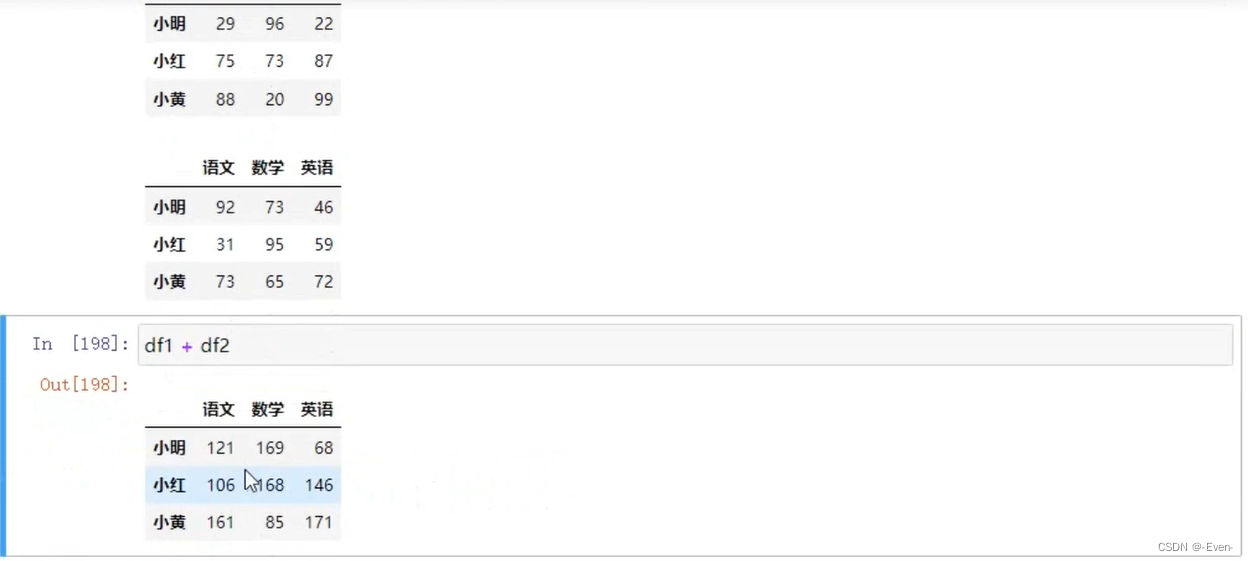
————————分隔————————————————————————
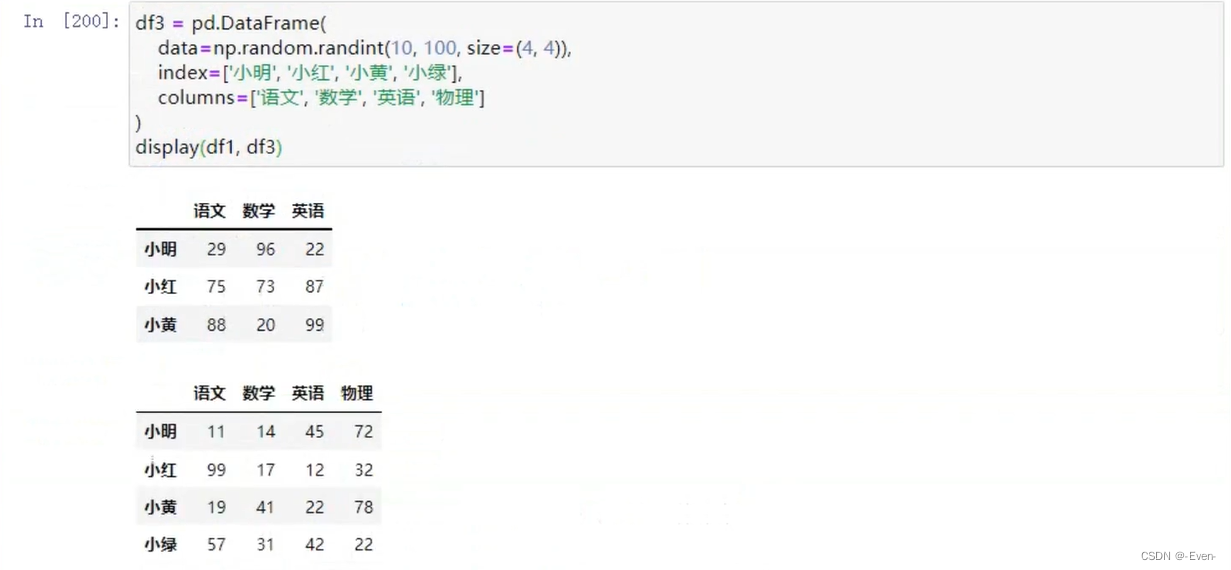
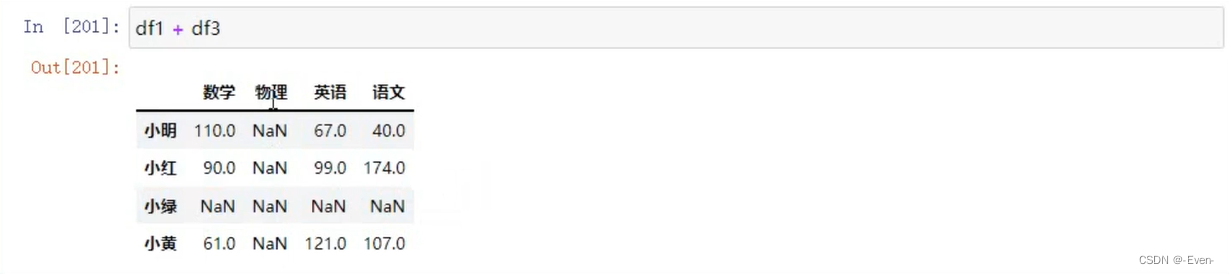

2.5 Series与Dataframe之间的运算

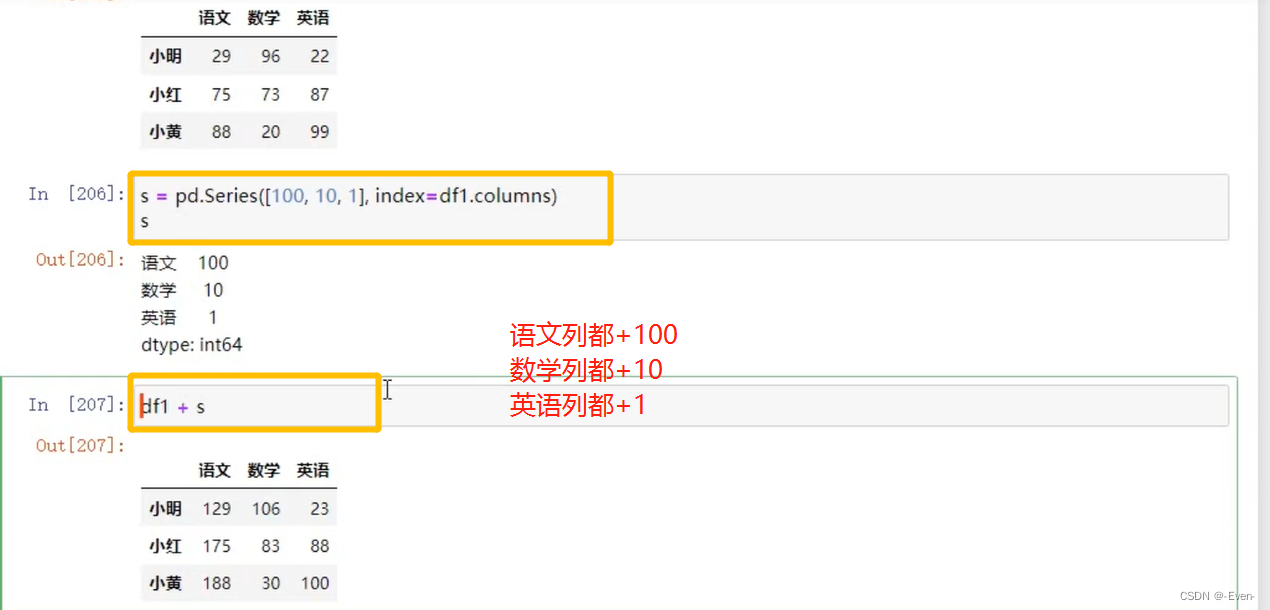
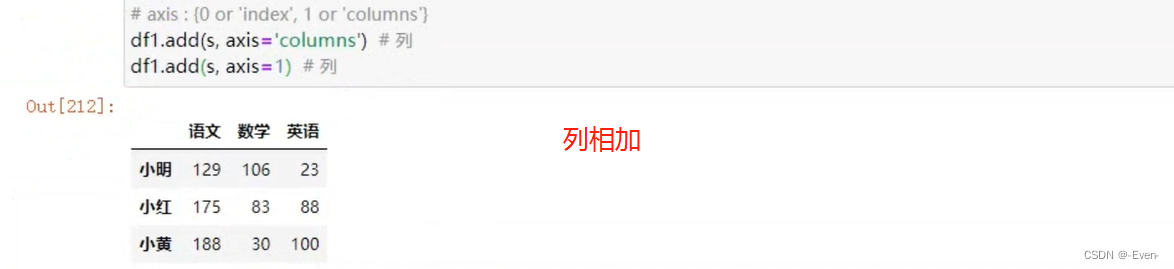
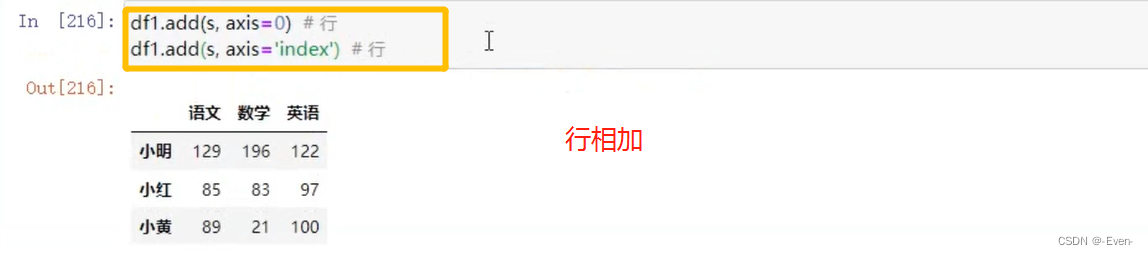
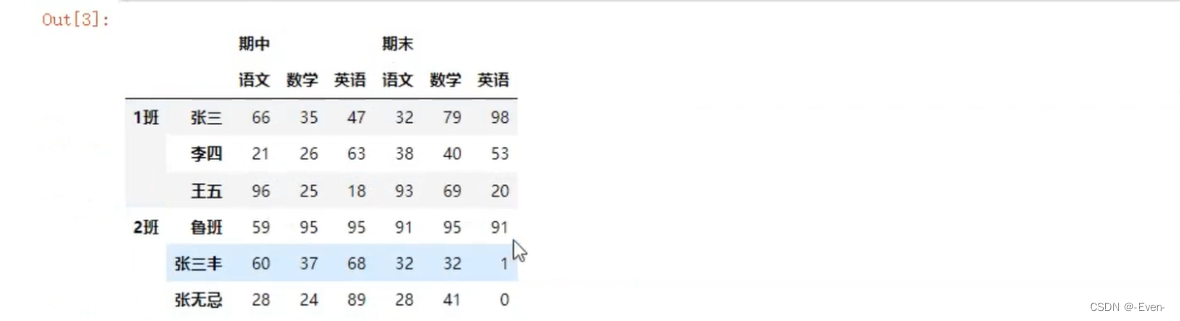
3、Pandas层次化索引
3.1 创建层次化索引
3.1.1 隐式构造
-
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组

-
Series也可以创建多层索引
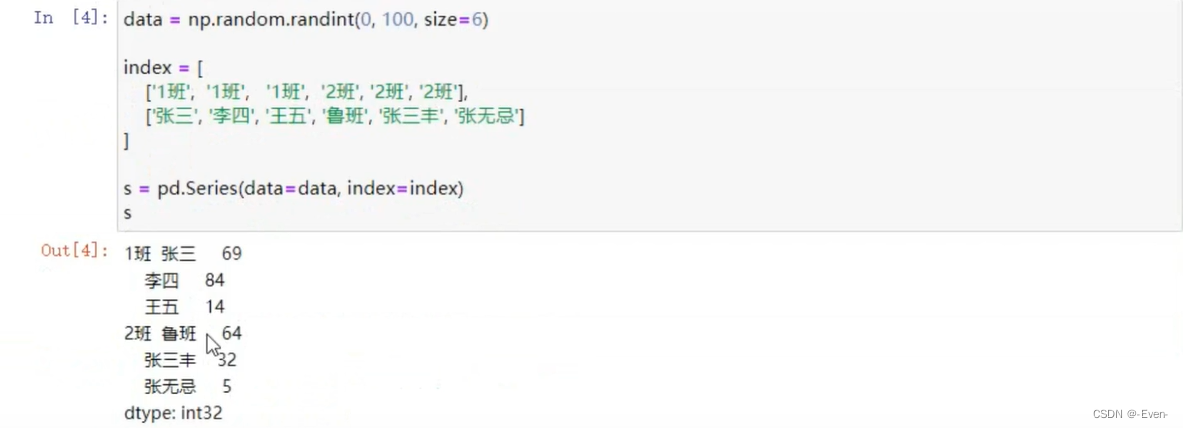
3.1.2 显示构造pd.MultiIndex
- 使用数组

- 使用tuple
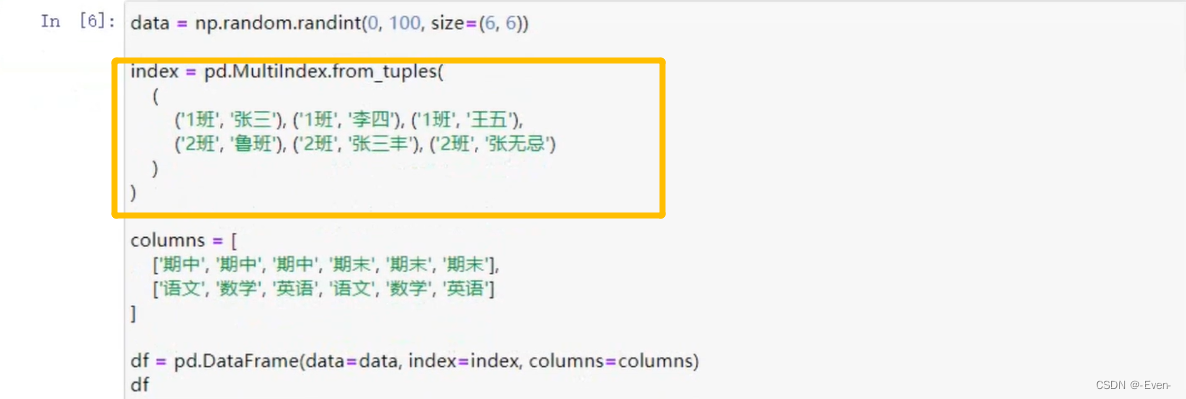
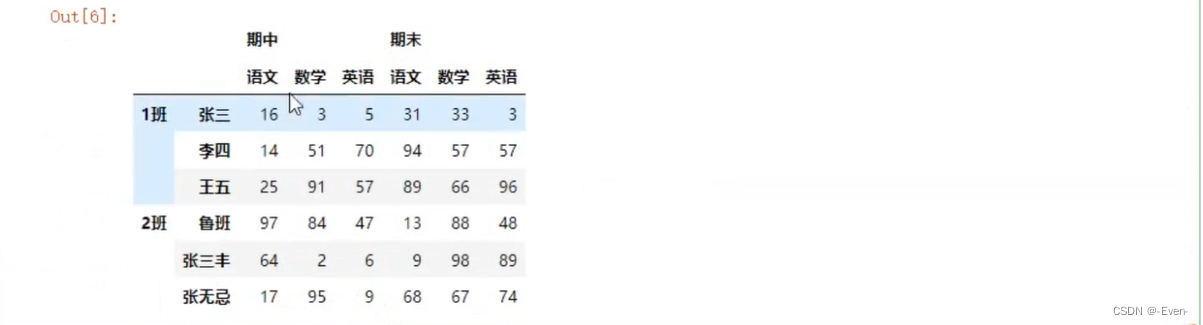
- 使用product
- 笛卡尔积
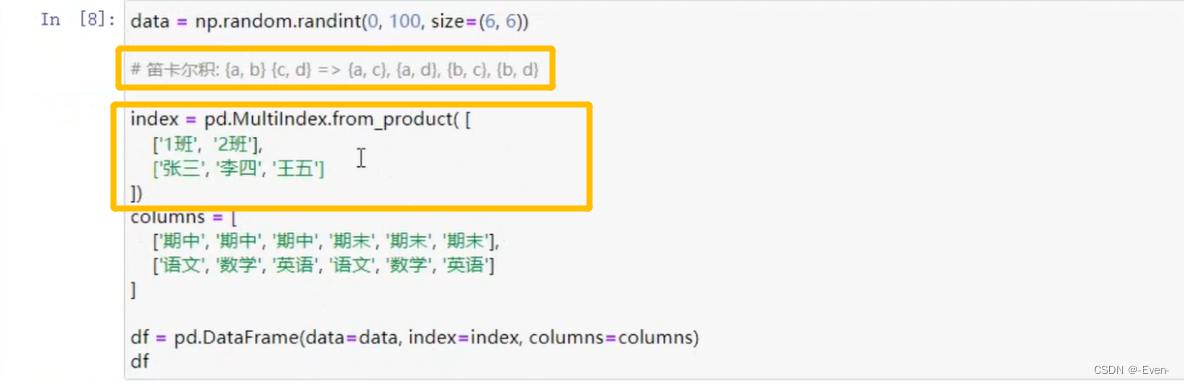
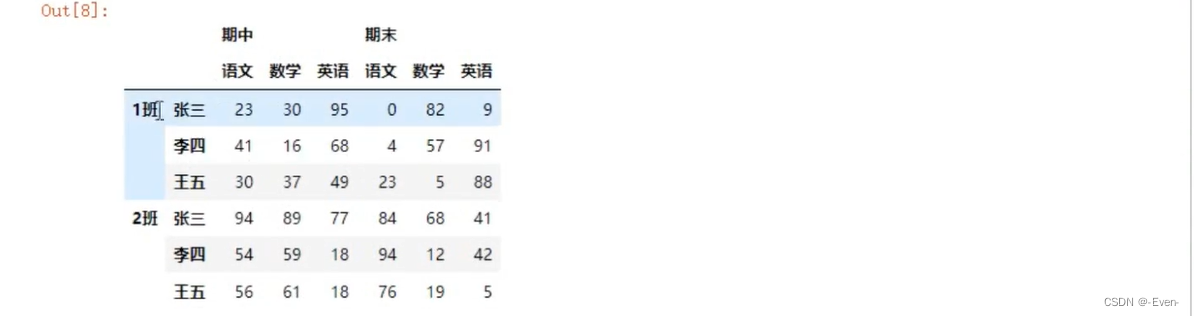
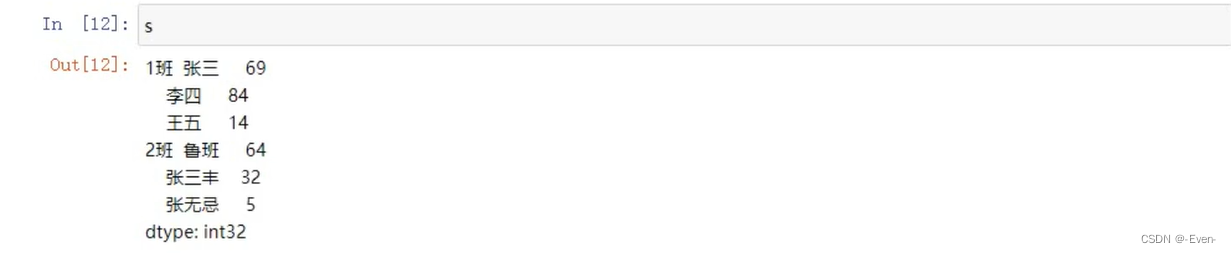
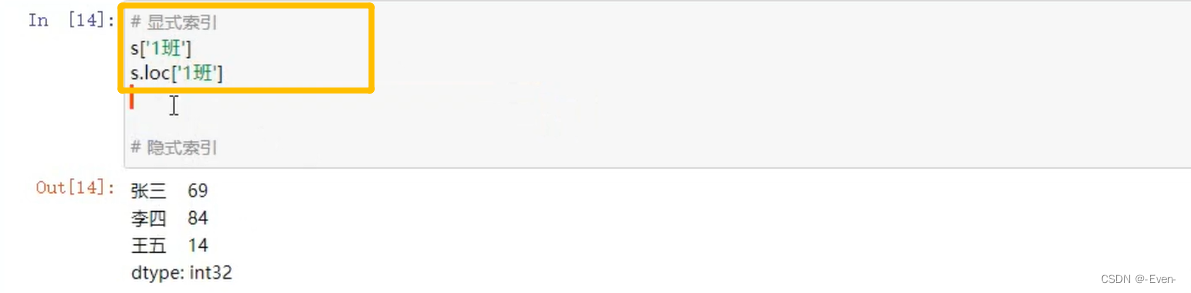
3.2 多层索引
3.2.1 Series的操作

——————分隔——————————————————

——————分隔——————————————————



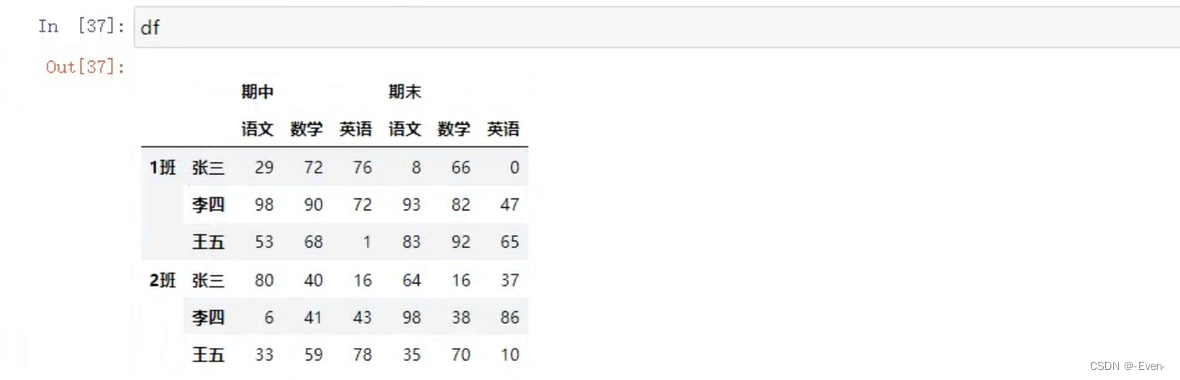
3.2.2 DataFrame的操作



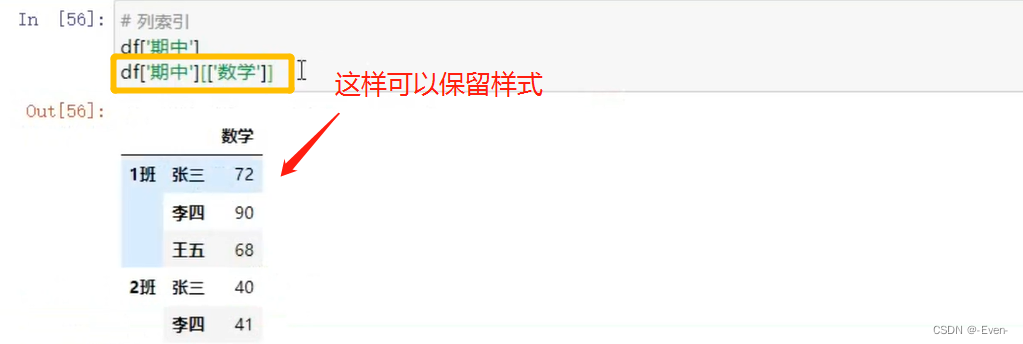

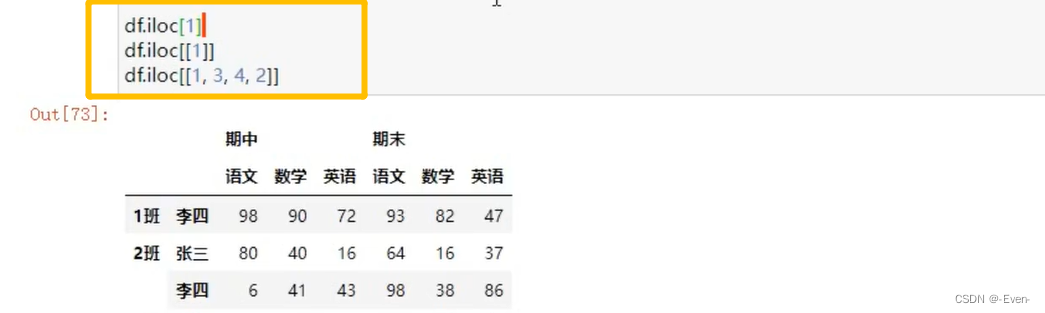
3.3 多层列切片
3.3.1 Series的操作
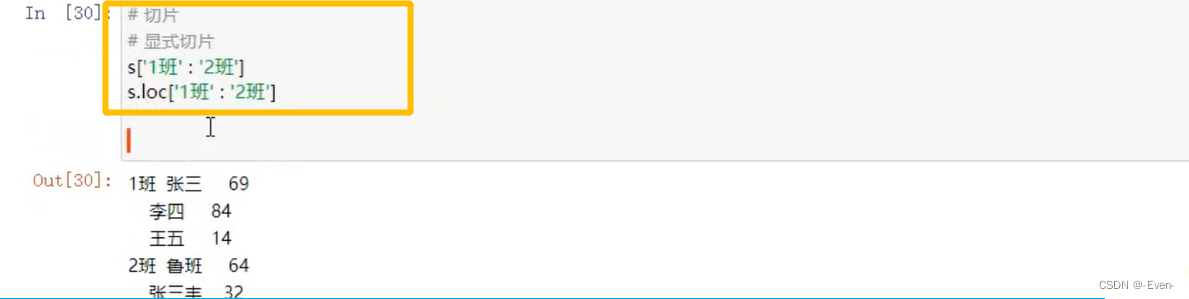



3.3.2 DataFrame的操作
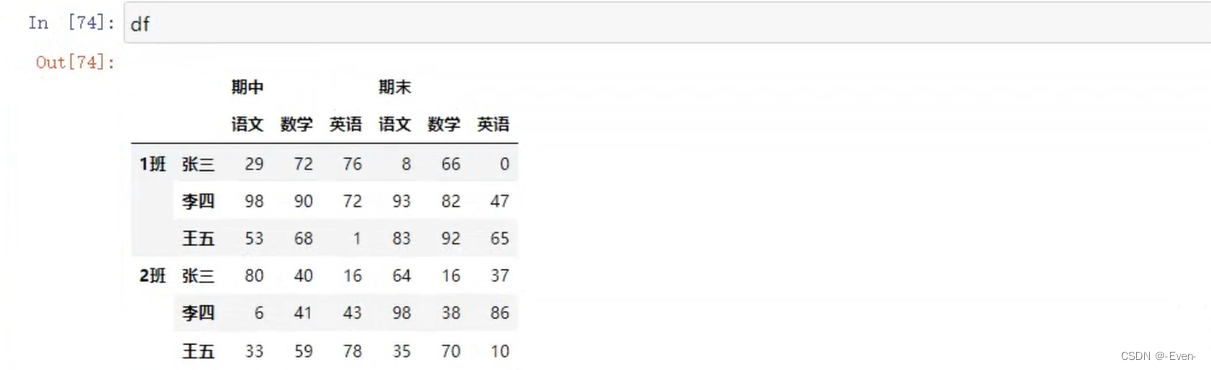
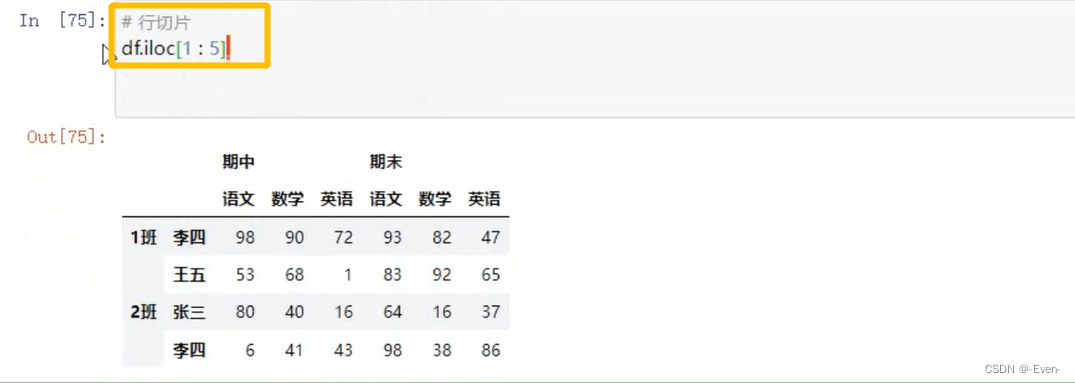
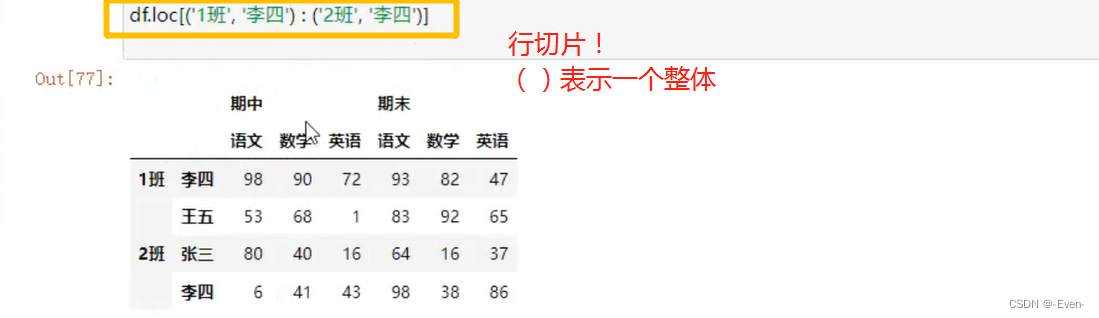
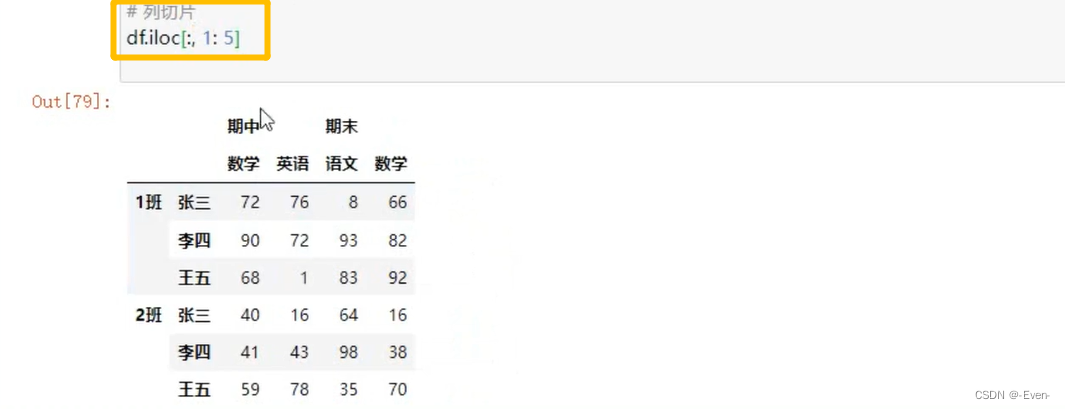
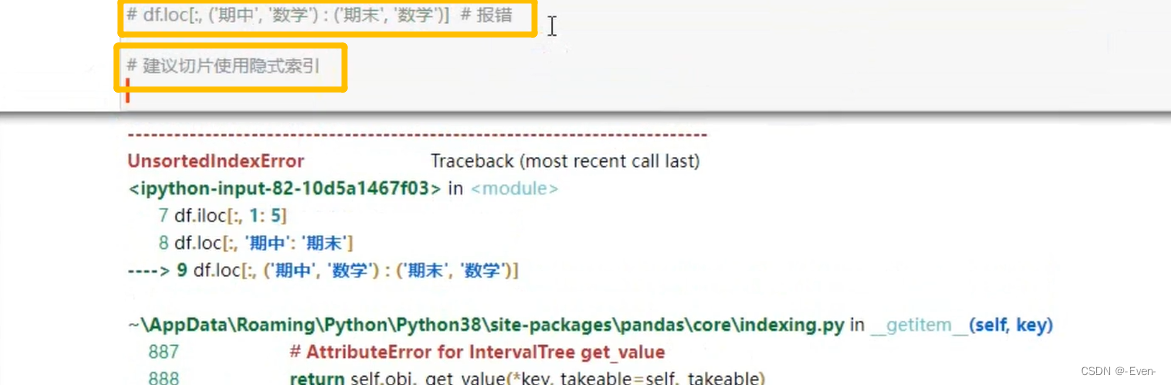
3.4 多层次索引的堆叠

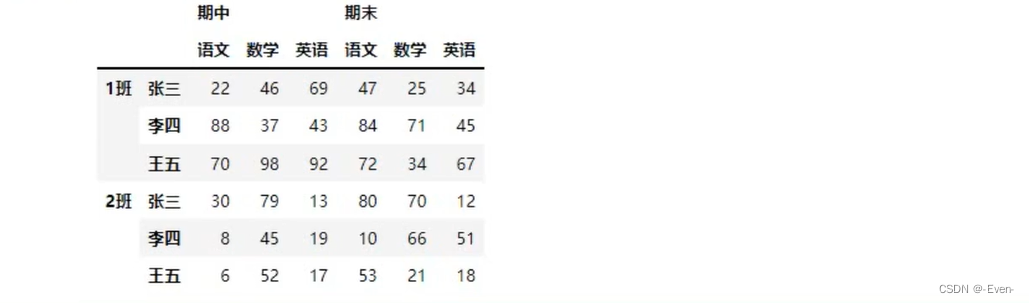

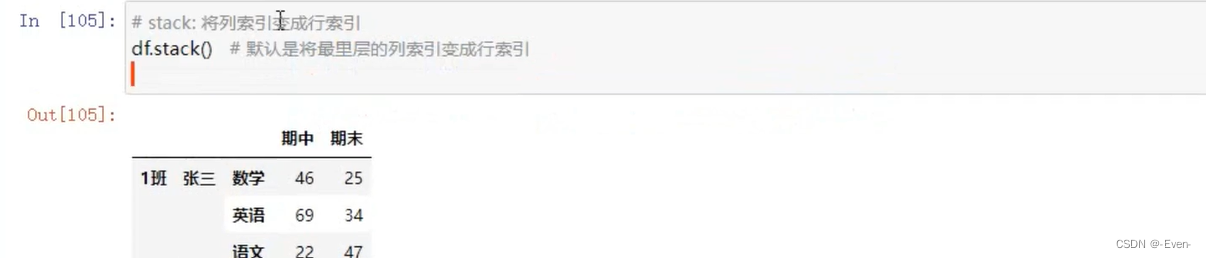

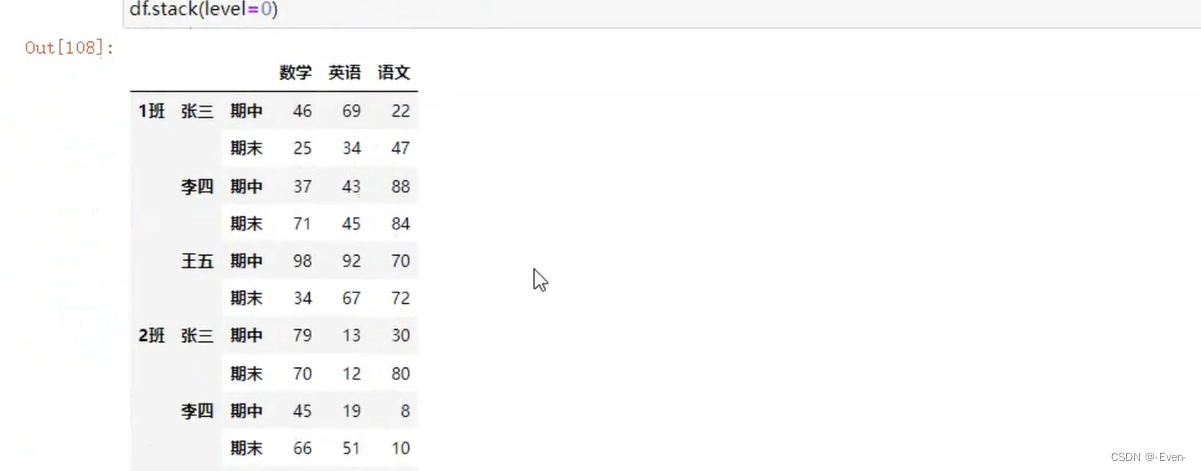

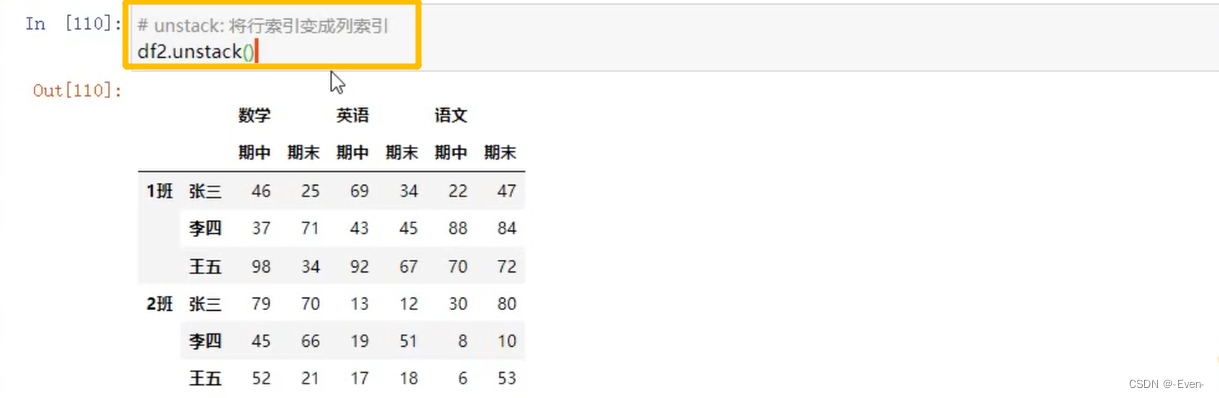

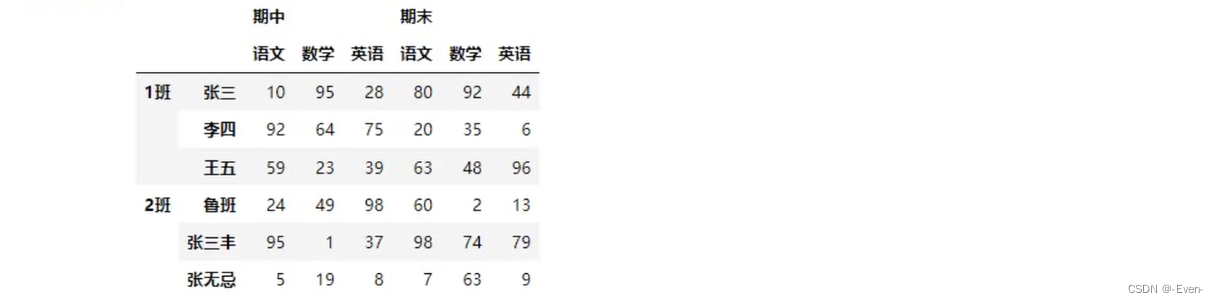
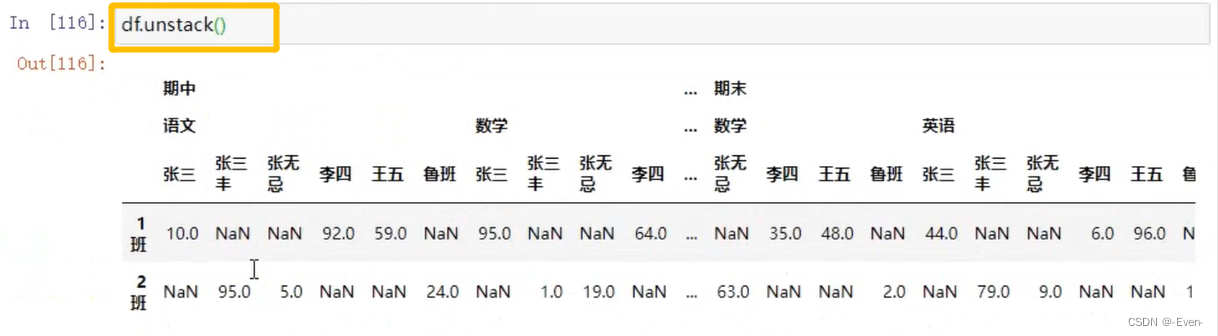
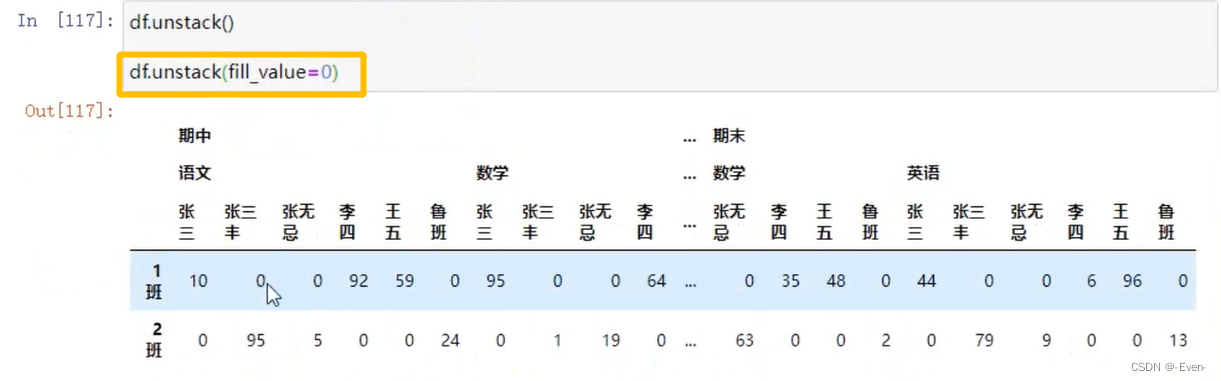
3.5 聚合操作
3.5.1 Dataframe聚合函数

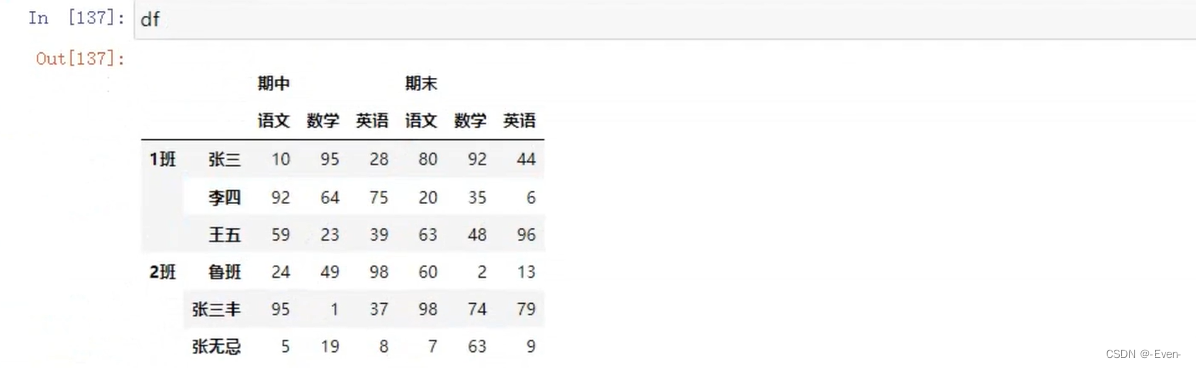
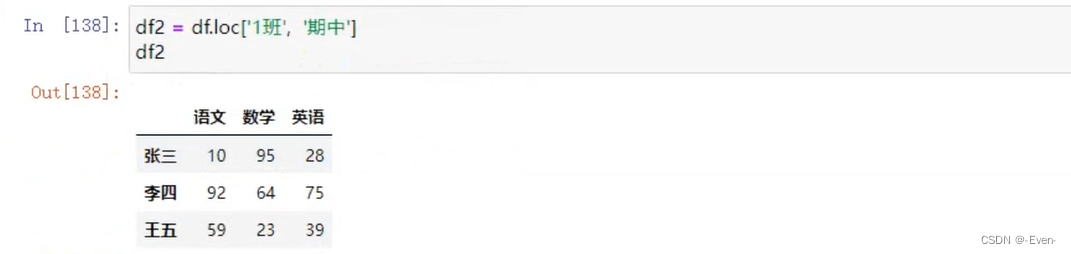
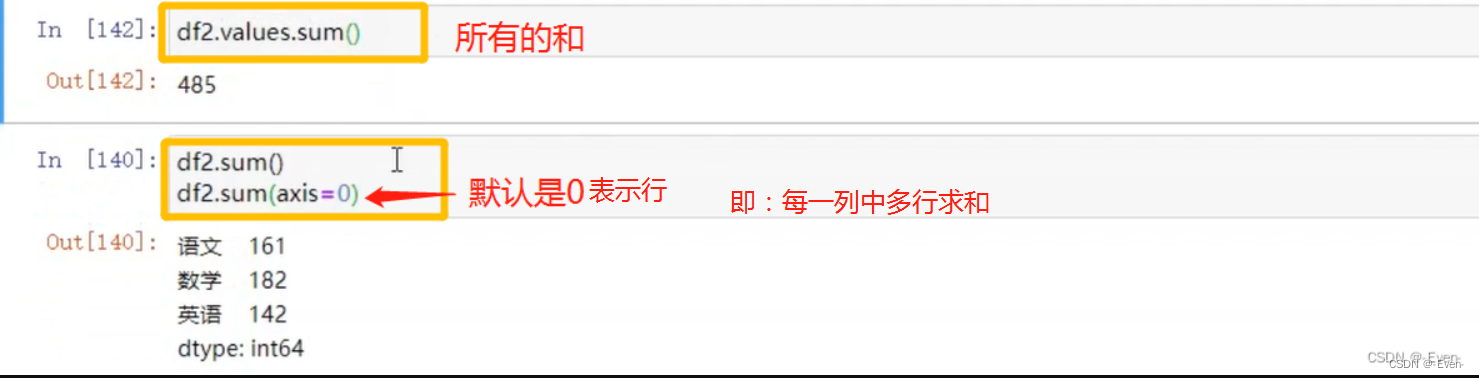
3.5.2多层索引聚合操作
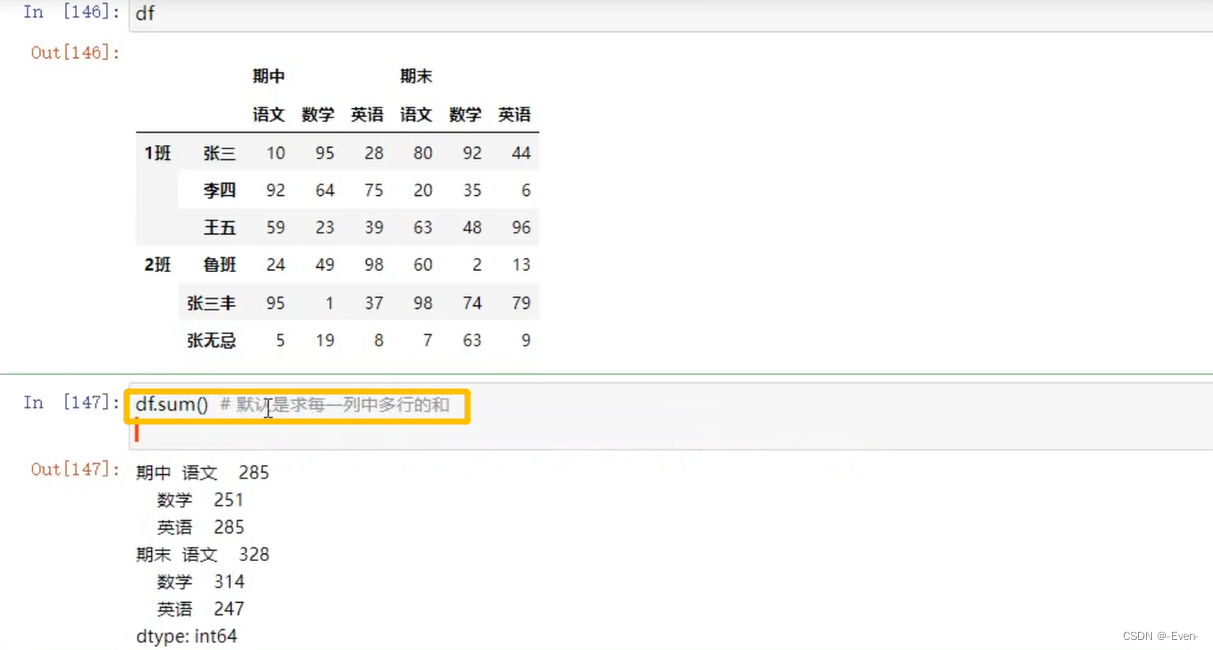


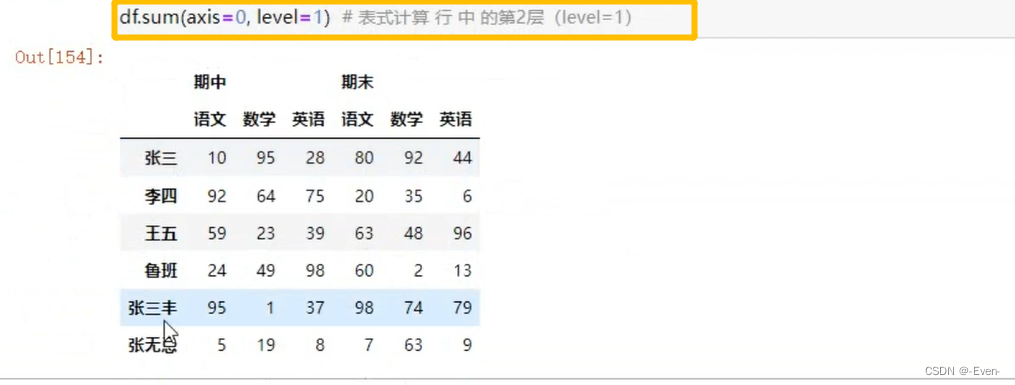
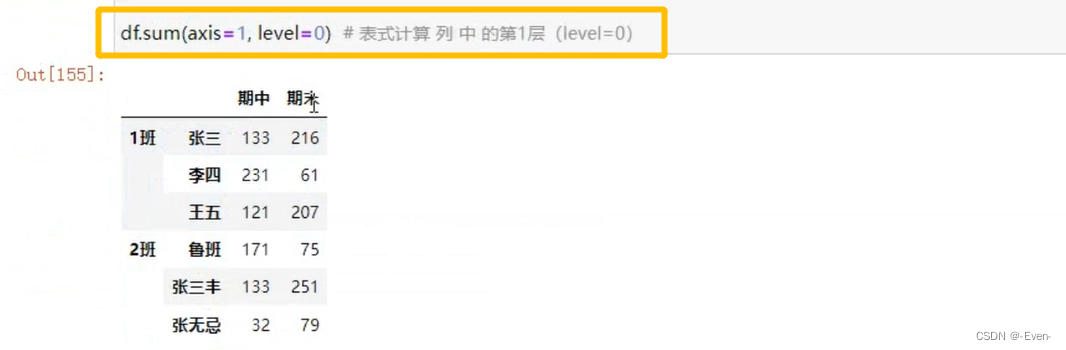
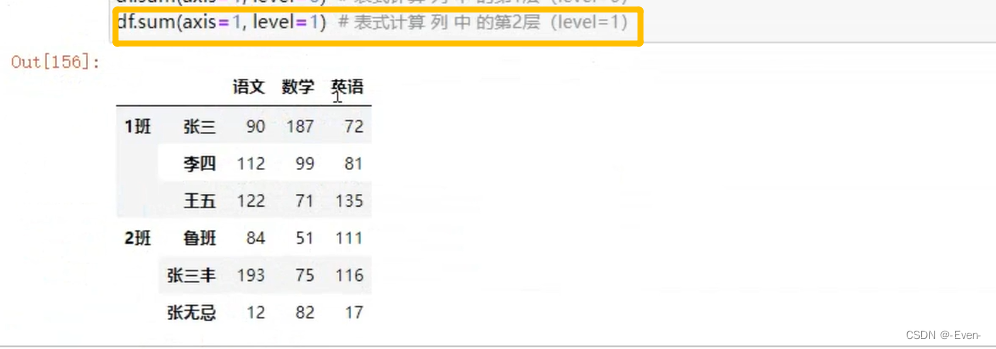
4、数据合并

4.1 concat函数级联

4.1.1 简单级联
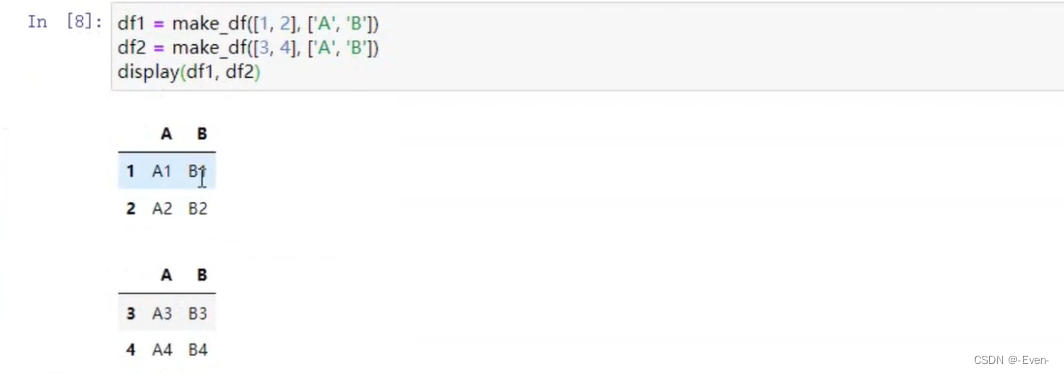
-
级联
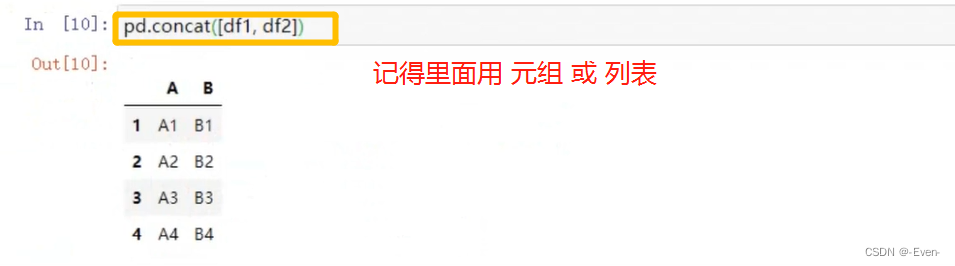
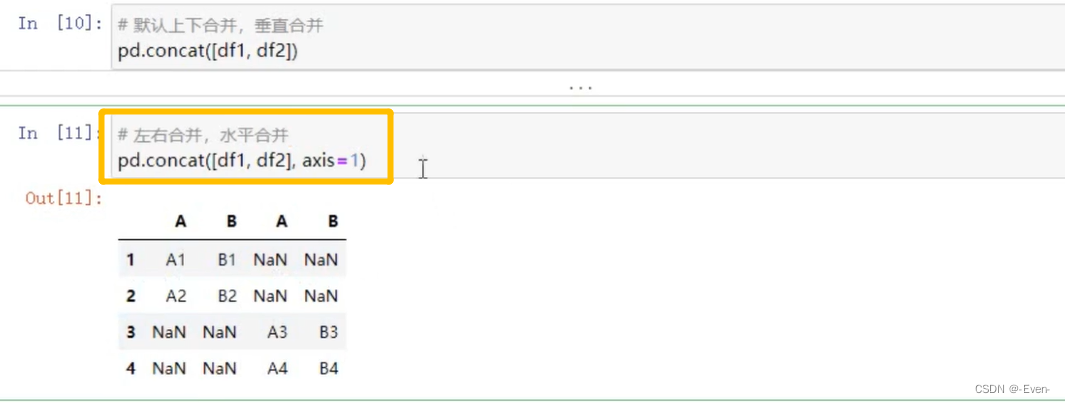
-
忽略行索引
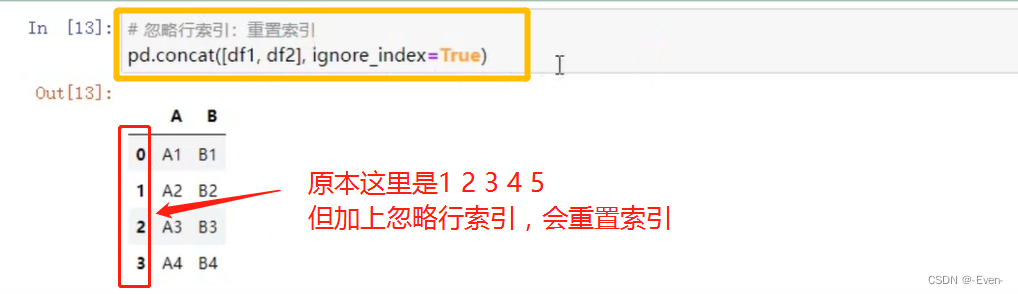
-
使用多层索引
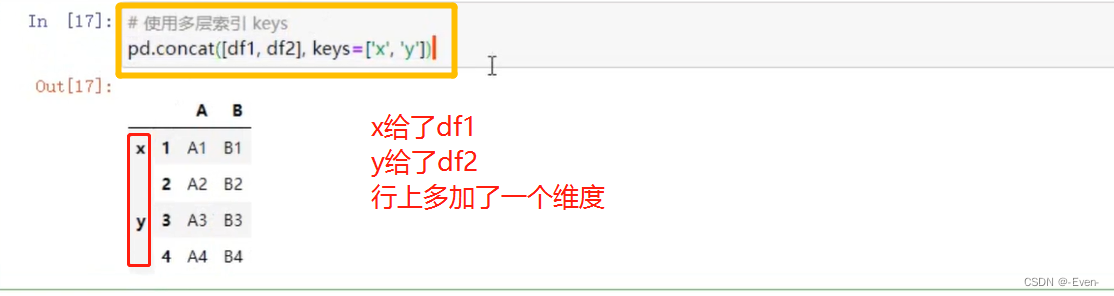
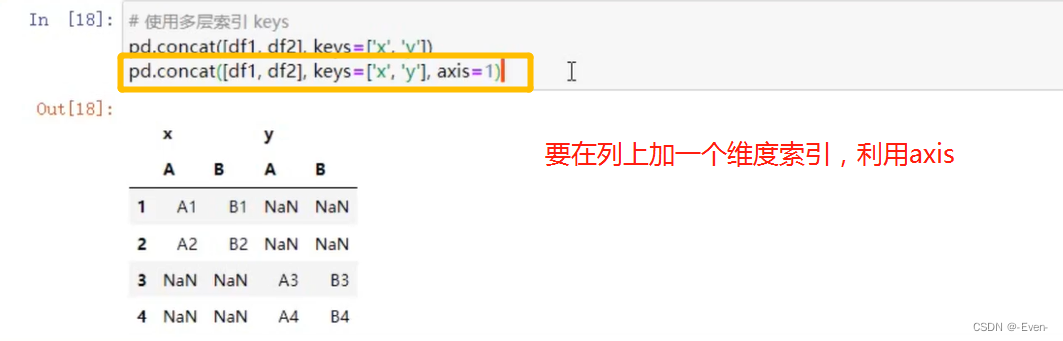
4.1.2 不匹配级联

-
不匹配级联

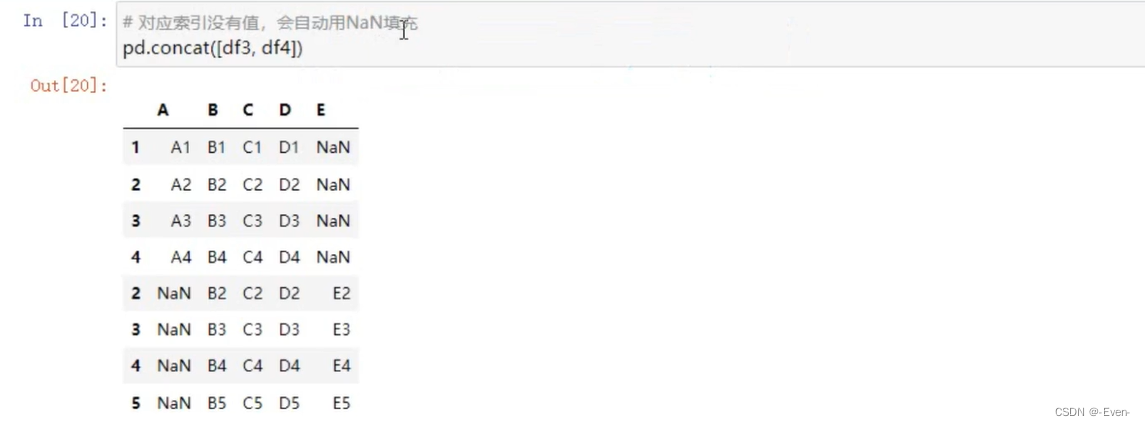
-
外连接:补NAN(默认模式)
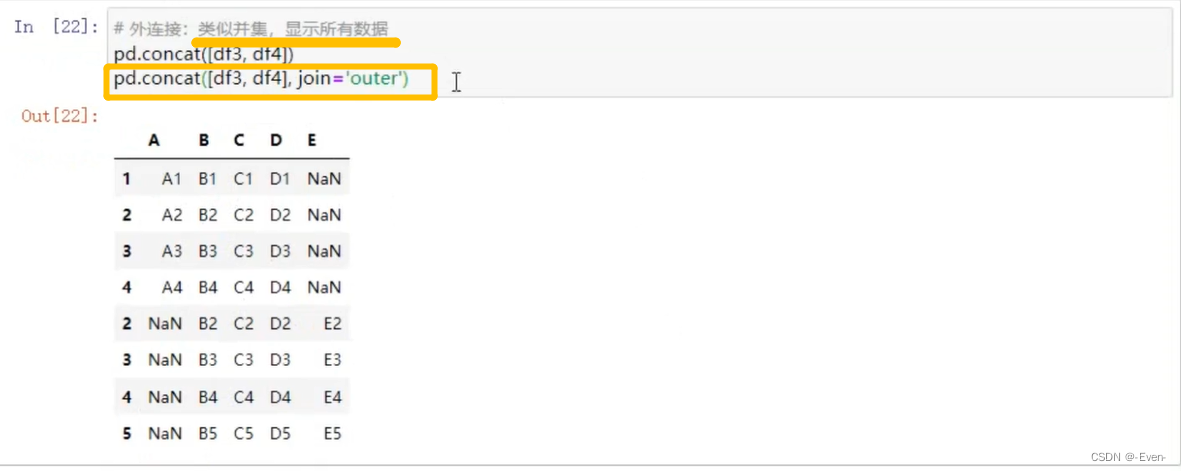
-
内连接:只连接匹配的项
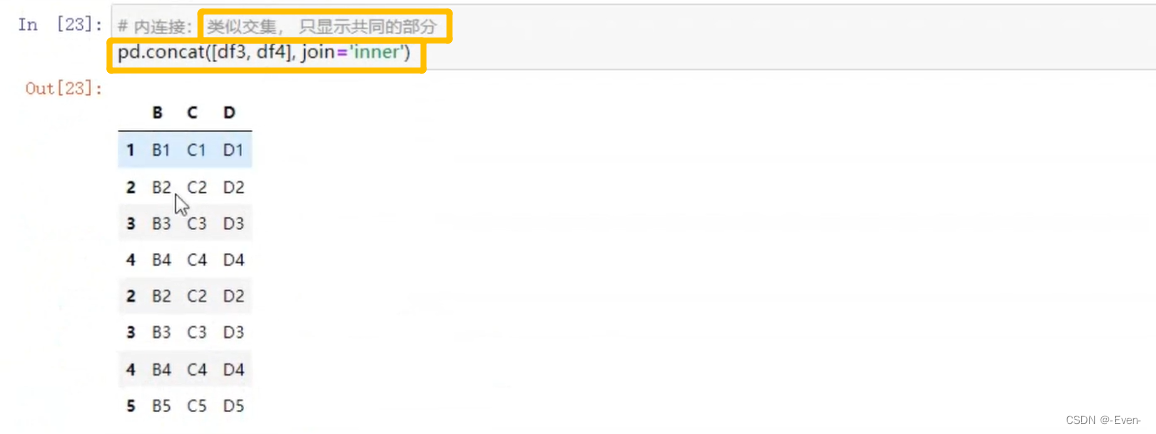
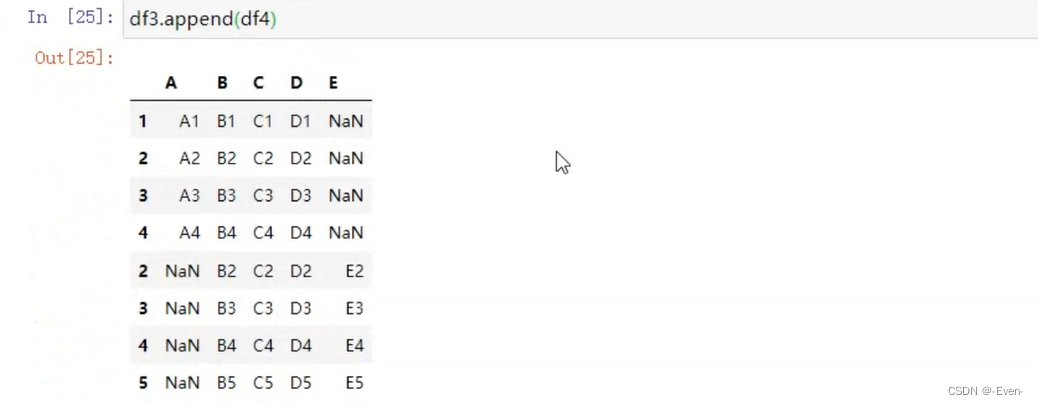
4.2 append函数添加

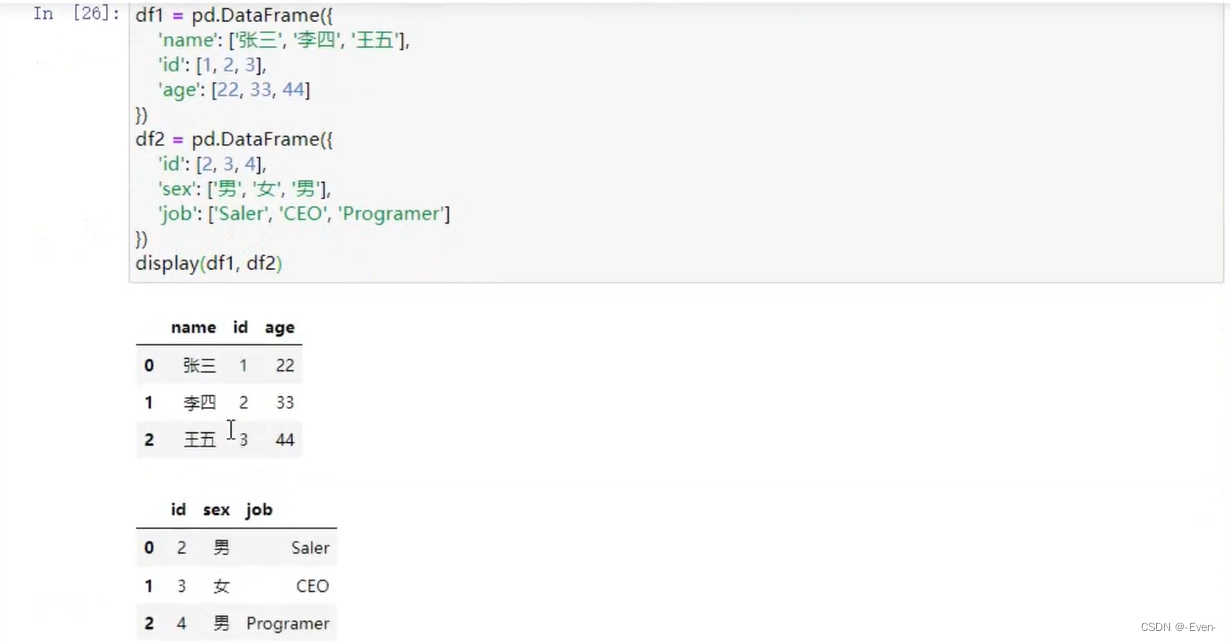
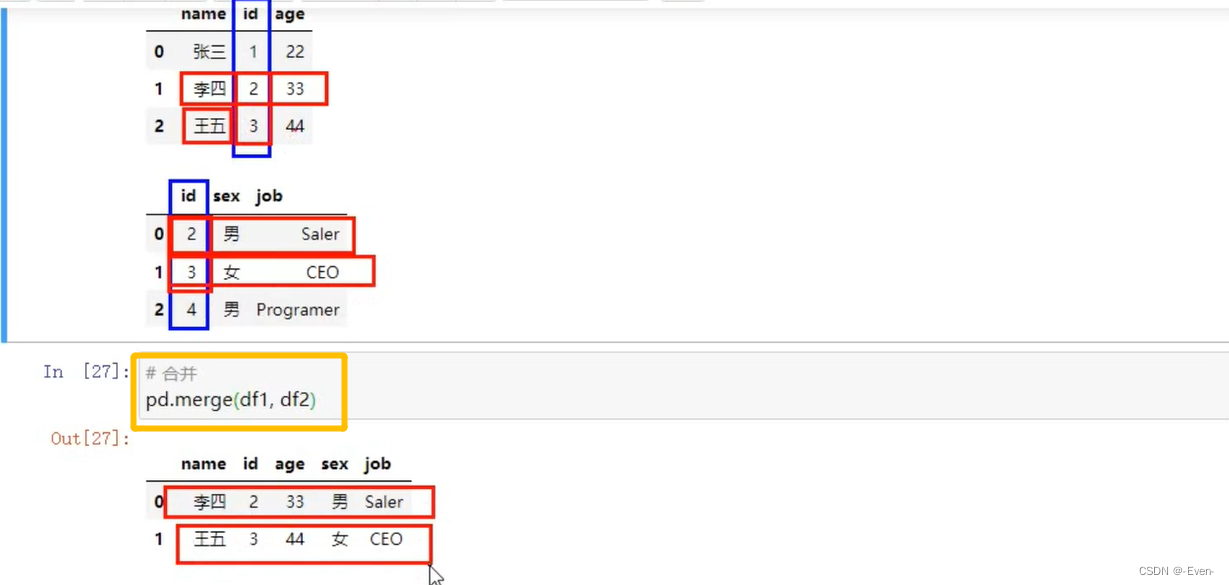
4.3 pd.merge()合并

4.3.1 一对一合并
4.3.2 多对一合并


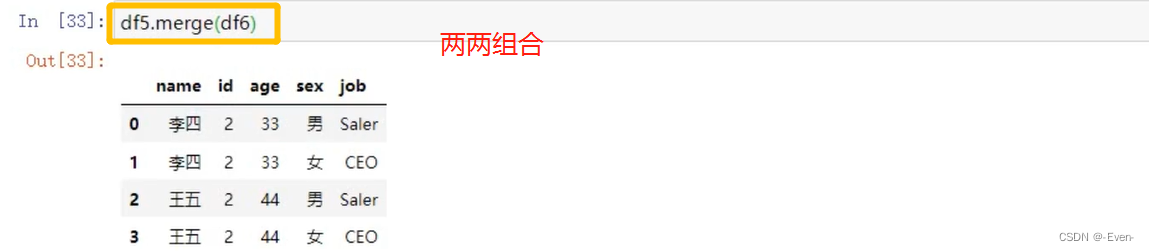
4.3.3 多对多合并

4.3.4 key的规范化


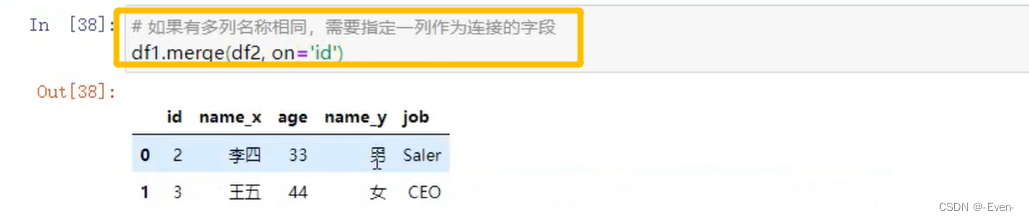






4.3.5 内合并与外合并
-
内合并:只保留两者都有的key
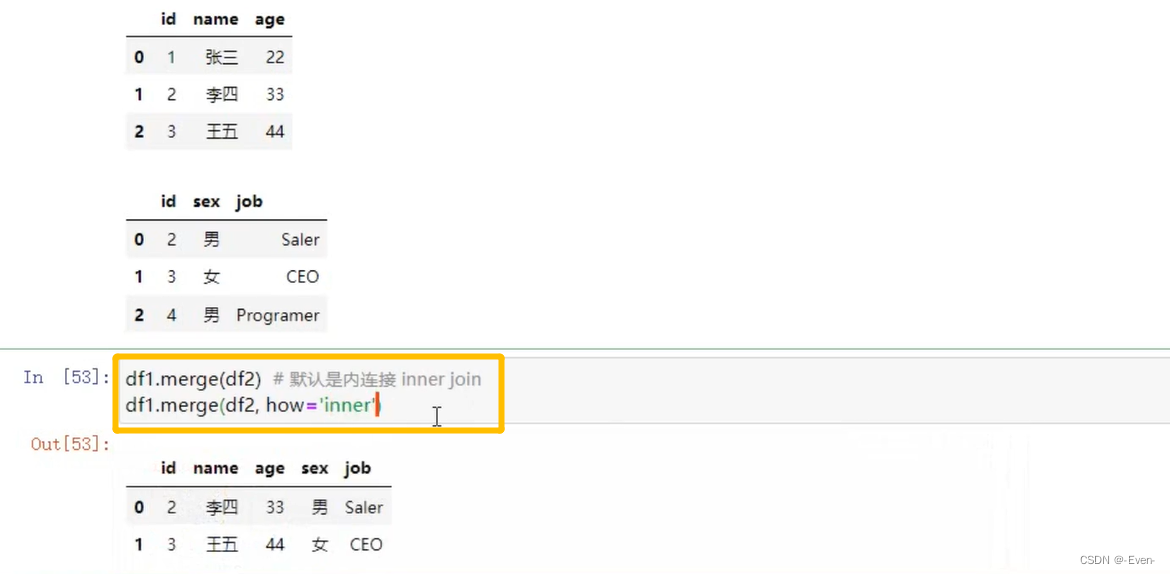
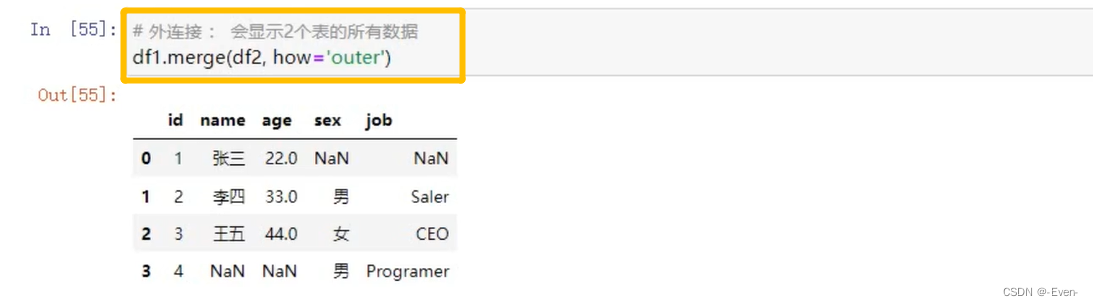
-
外合并:how=‘outer’:补NAN
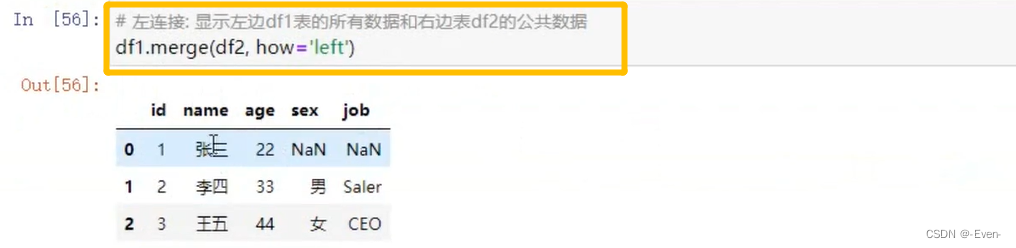
-
左合并、右合并:how=‘left’,how=‘right’
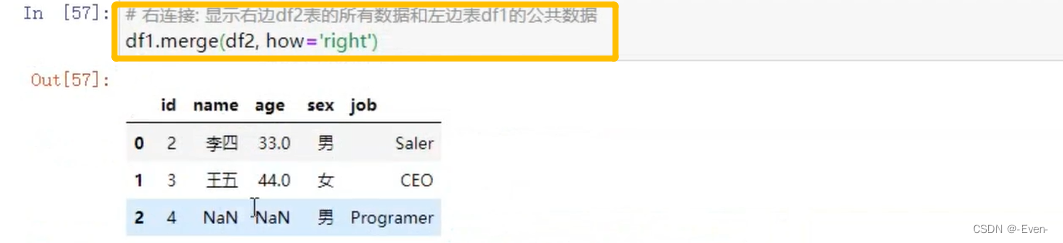
4.3.6 列冲突的解决

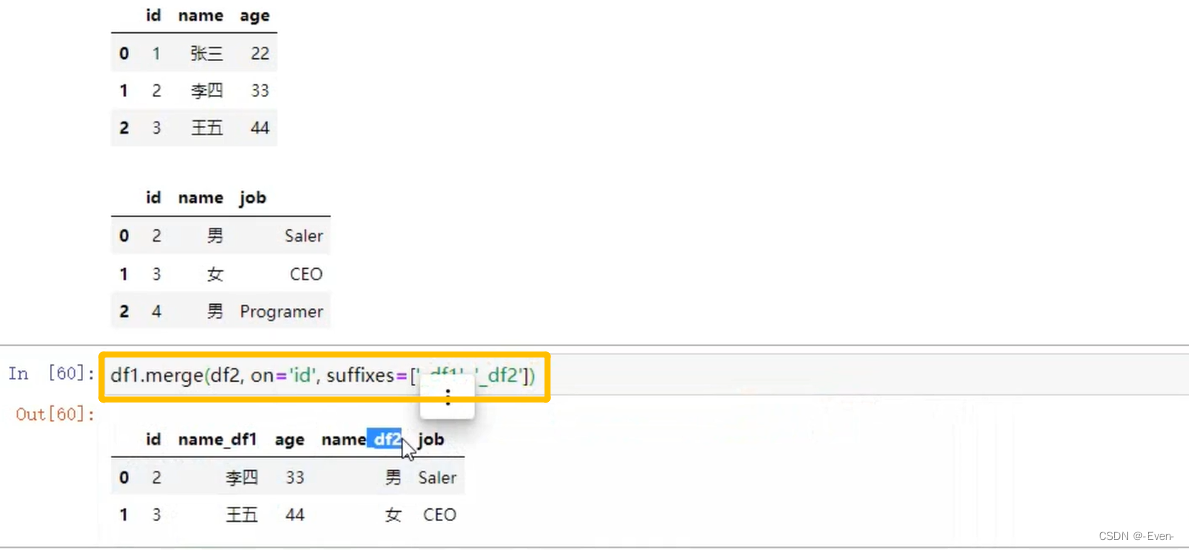
5、缺失值处理


5.1 None与np.nan
- None

不建议使用这种!!!!! - np.nan


5.2 Pandas中的None与NaN
5.2.1 Pandas中的None与NaN都视为np.nan
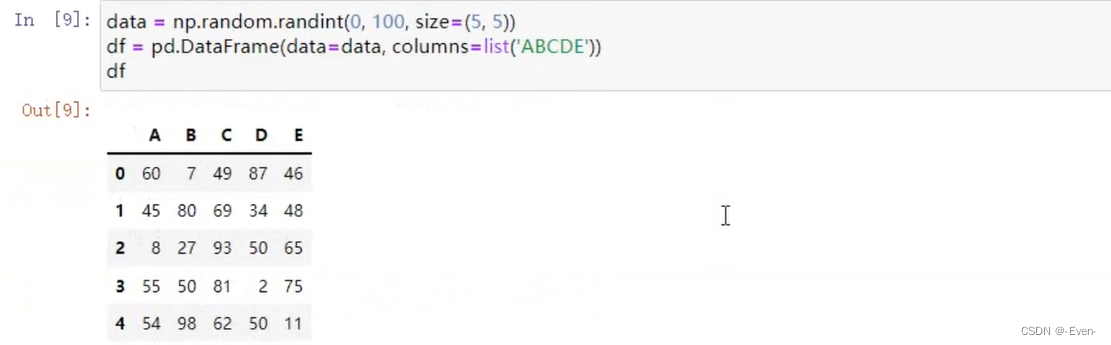
-
创建Dataframe
-
使用Dataframe行索引与列索引修改Dataframe数据
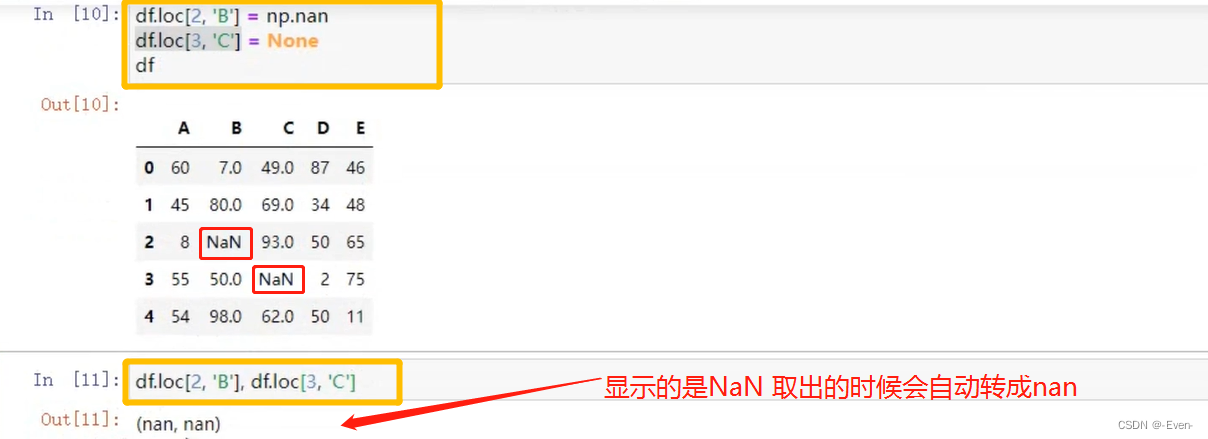
不管存的是python的None还是Numpy的None,最终得到的都是Numpy的None!!
5.2.2 Pandas中None与np.nan的操作

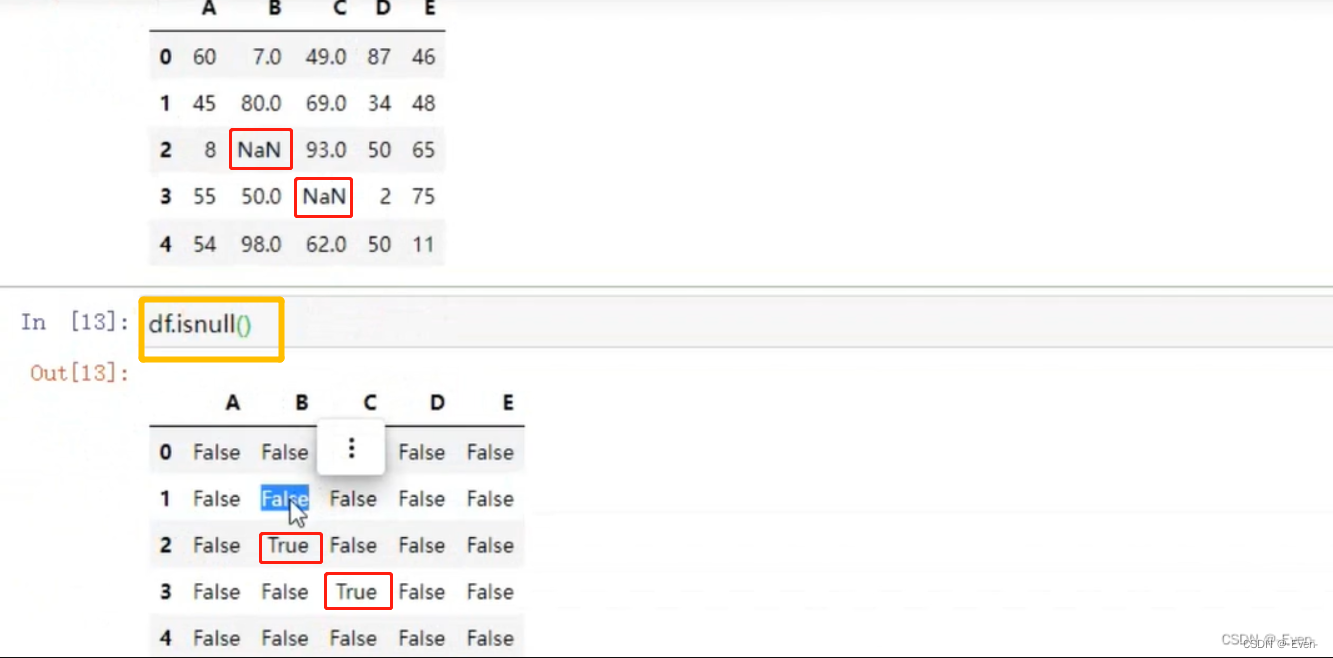
——————分隔——————————————
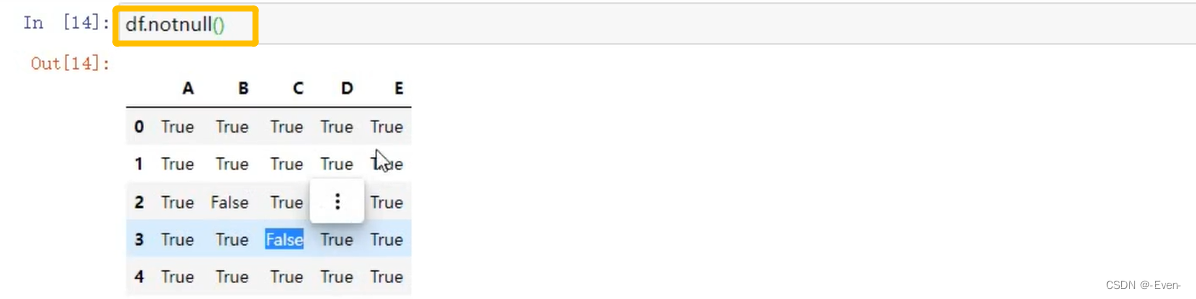
——————分隔——————————————
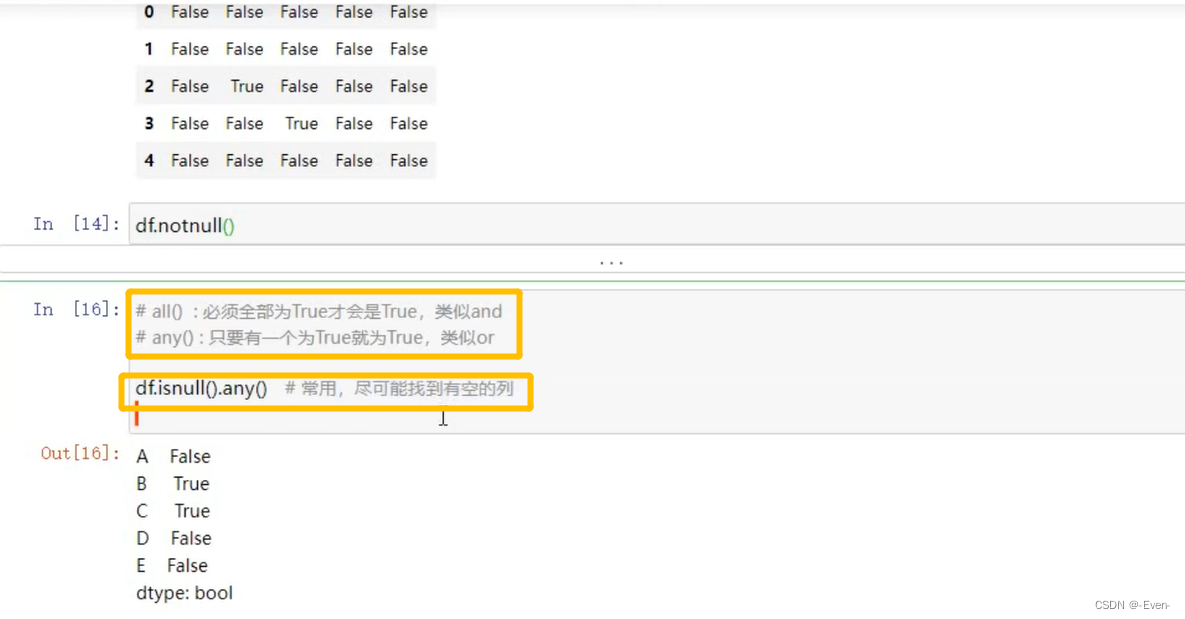
——————分隔——————————————
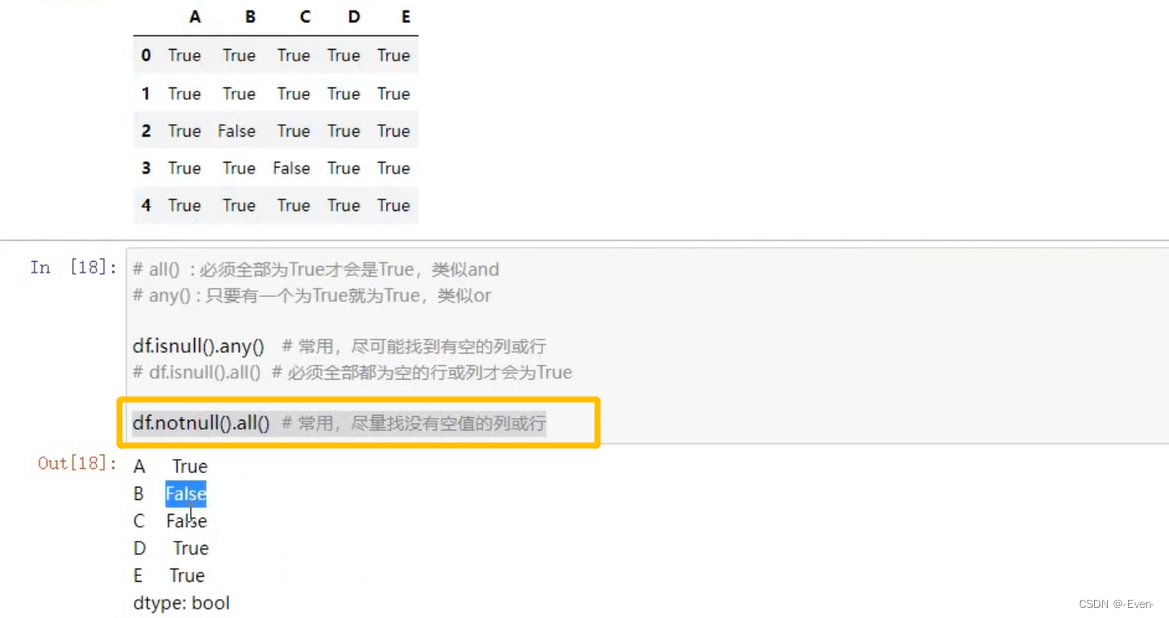
——————分隔——————————————
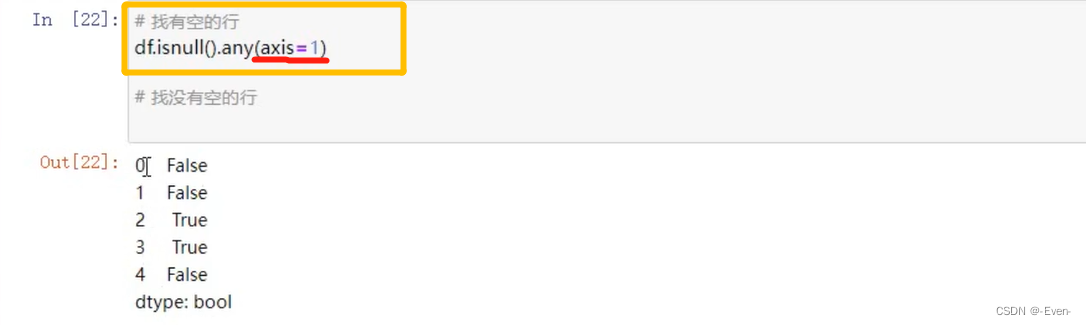
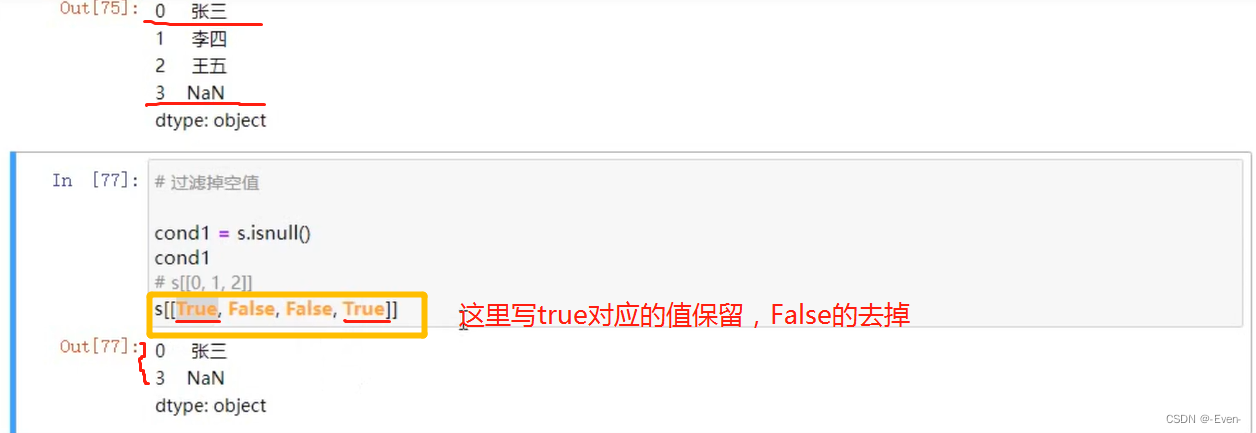
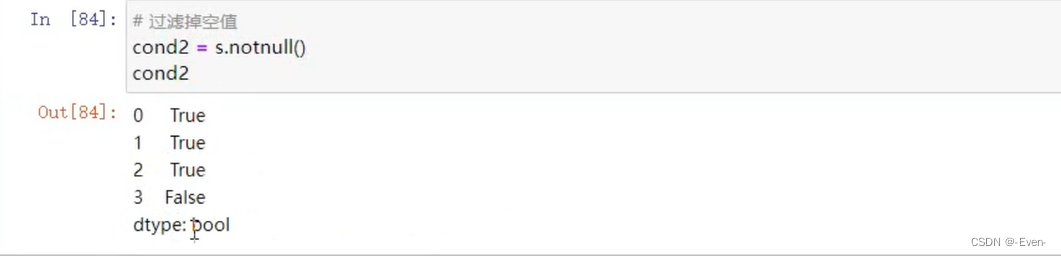
5.2.3 使用bool值索引过滤数据
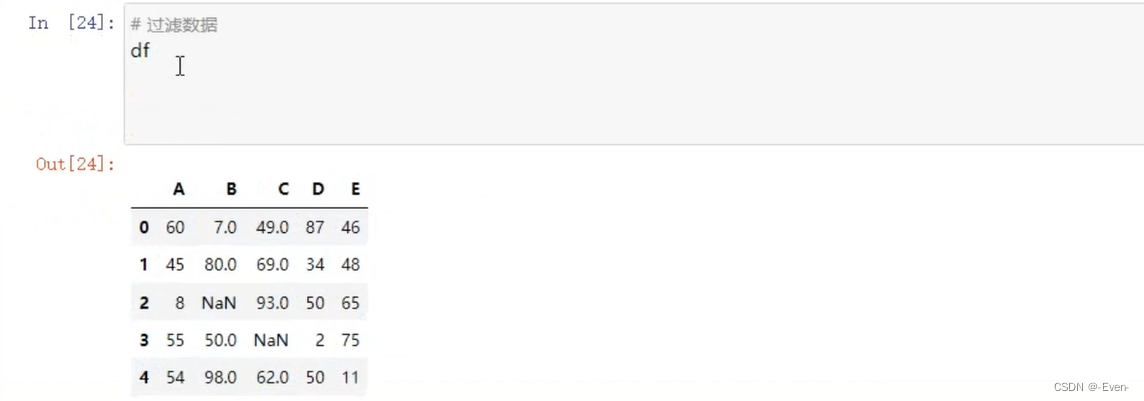
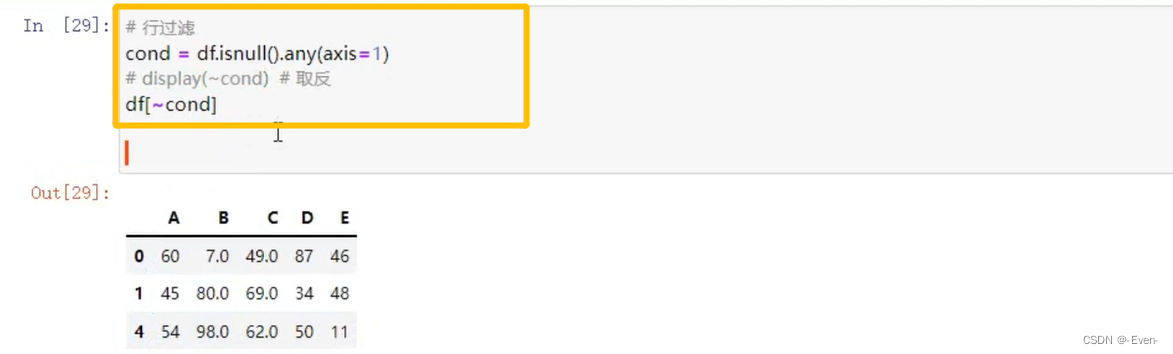
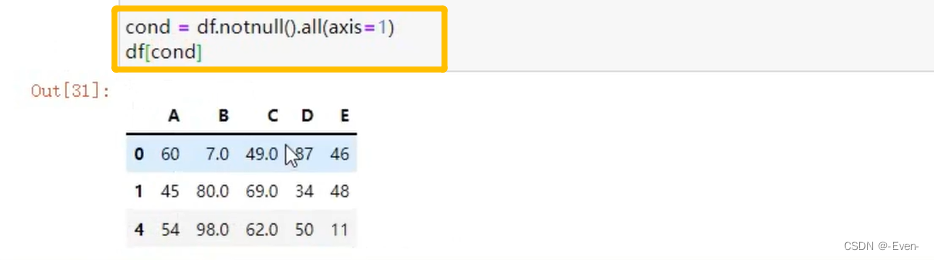


5.2.4 过滤函数
- dropna()

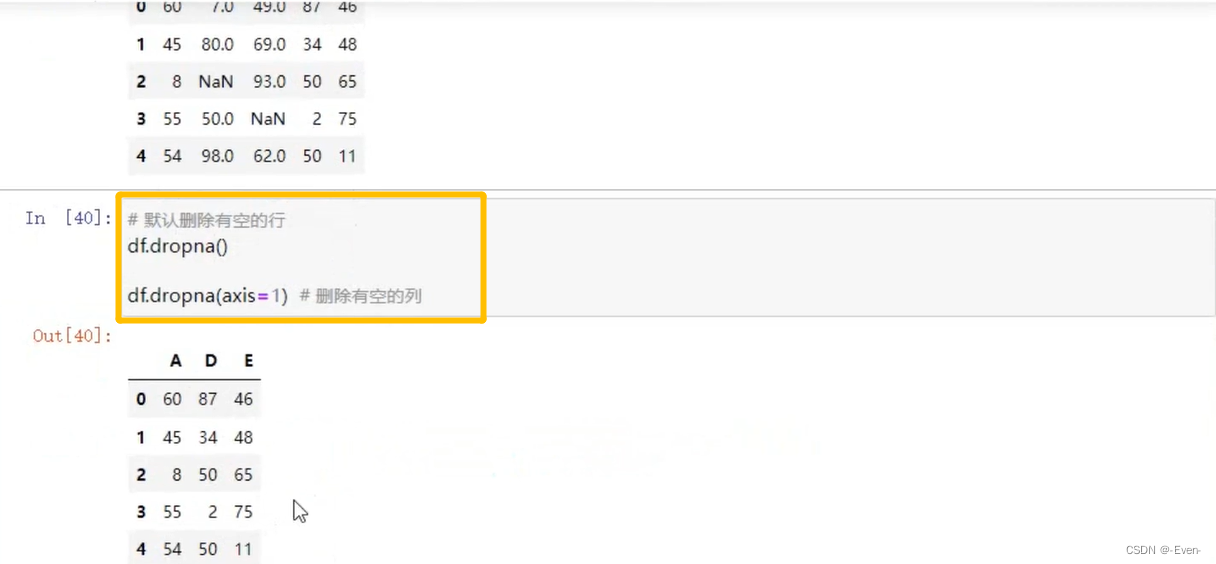

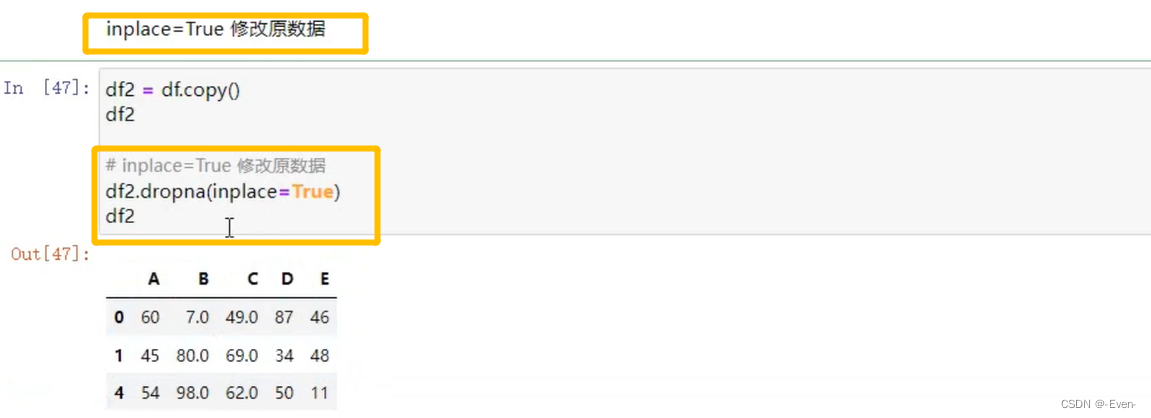
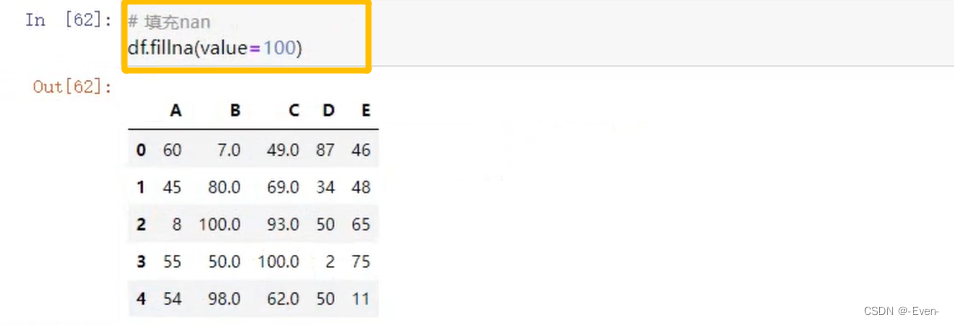
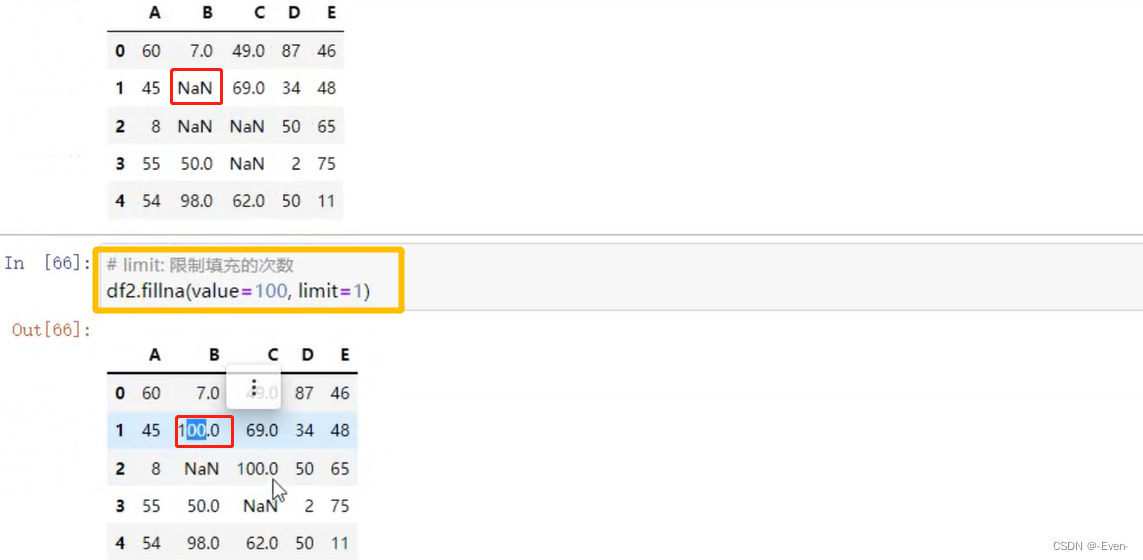
5.2.5 填充函数
- fillna()
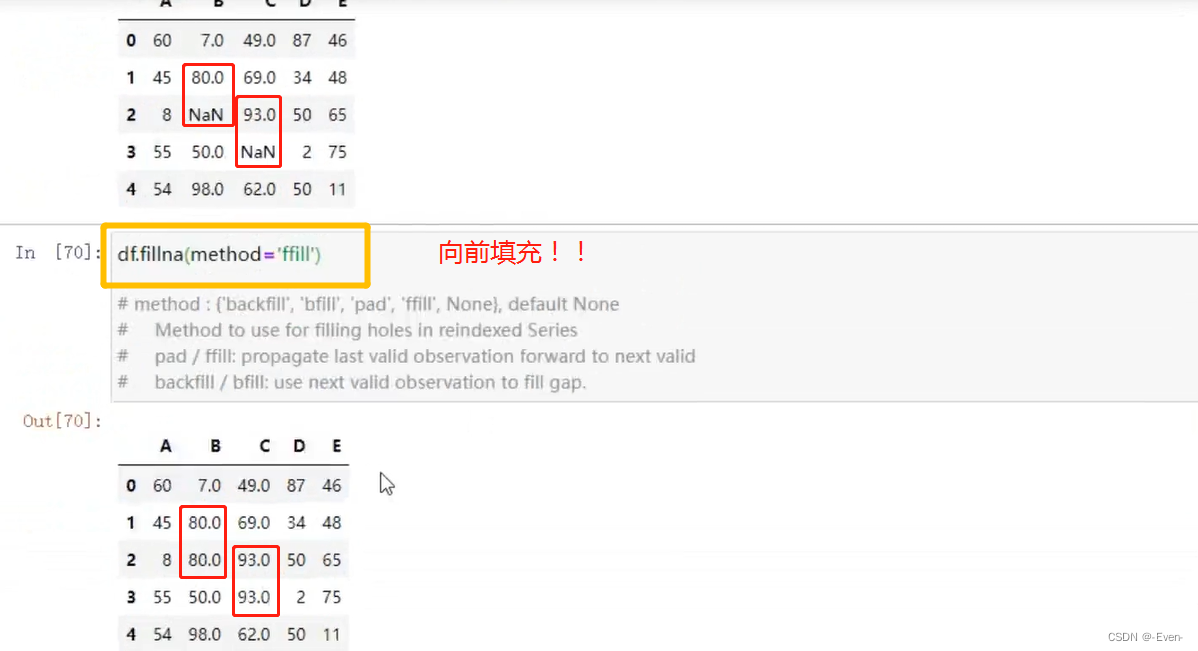
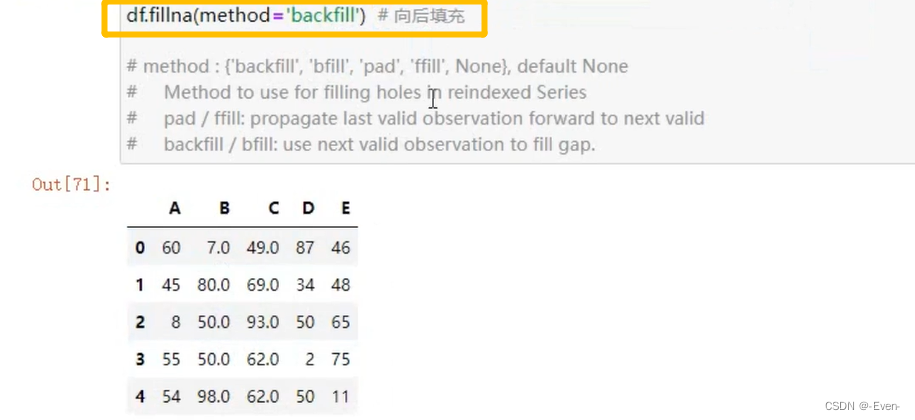
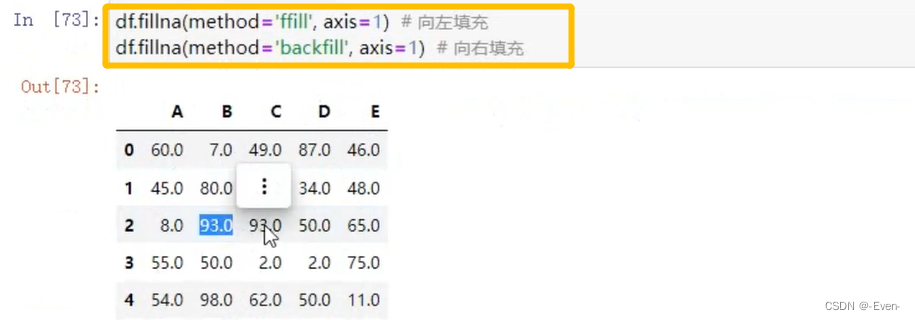
6、Pandas处理重复值和异常值
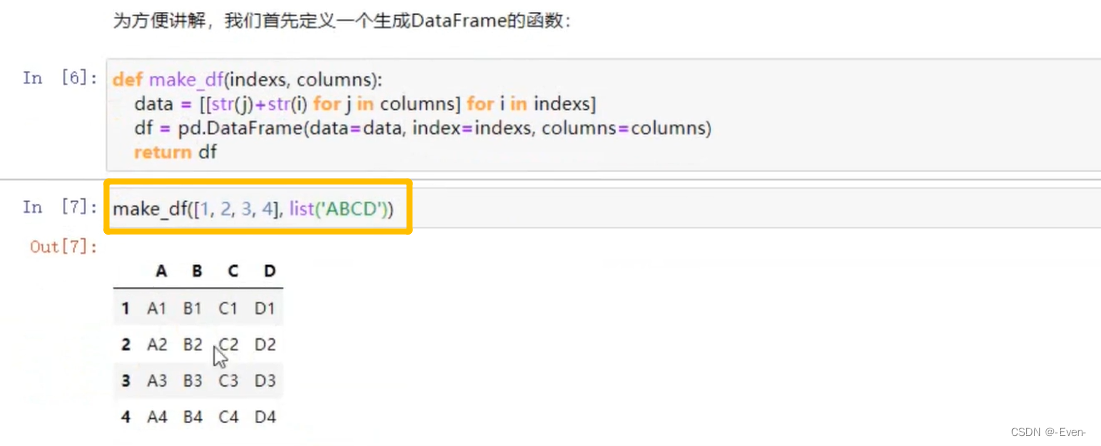
def make_df(indexs, columns):
data = [[str(j)+str(i) for j in columns] for i in indexs]
df = pd.DataFrame(data=data, index=indexs, columns=columns)
return df
# make_df([1, 2, 3, 4], ['A', 'B', 'C', 'D'])

6.1 删除重复行
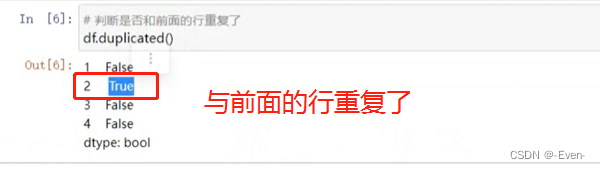
- 使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象
- 每个元素对应一行,如果该行不是第一次出现,则元素为True
# 让第一行和第二行重复
df.loc[1] = df.loc[2]
# 判断是否和前面的行重复了
df.duplicated()
# df.duplicated(keep='first') # 保留第一行,这里就会第二行显示False
# df.duplicated(keep='last') # 保留最后一行,这里就会第一行显示False
# df.duplicated(keep=False) # 标记所有重复行,不保留任何一行
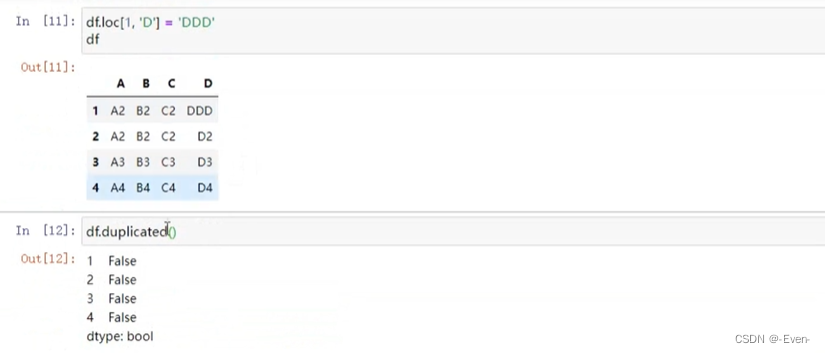
df.loc[1, 'D'] = 'DDD'
# subset: 子集, 只需要子集相同就可以判断重复
df.duplicated(subset=['A', 'B', 'C'])

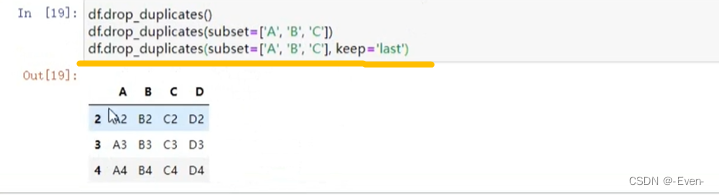
- 使用drop_duplicates()函数==删除重复的行==
df.drop_duplicates(subset=['A', 'B', 'C'])
df.drop_duplicates(subset=['A', 'B', 'C'], keep='last') #表示保留最后一行,前面重复行删除
6.2 映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
包含三种操作:
- replace()函数:替换元素
- map()函数:处理某一单独的列, 最重要
- rename()函数:替换索引
6.2.1 replace()函数:替换元素
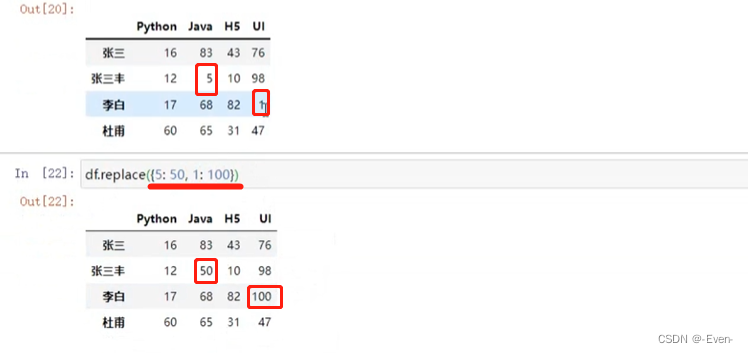
使用replace()函数,对values进行替换操作
index = ['鲁班', '张三丰', '张无忌', '杜甫', '李白']
columns = ['Python', 'Java', 'H5', 'Pandas']
data = np.random.randint(0, 100, size=(5, 4))
df = pd.DataFrame(data=data, index=index, columns=columns)
# replace还经常用来替换NaN元素
df.replace({
1: 100})
6.2.2 map()函数: 适合处理某一单独的列
df2 = df.copy()
df2
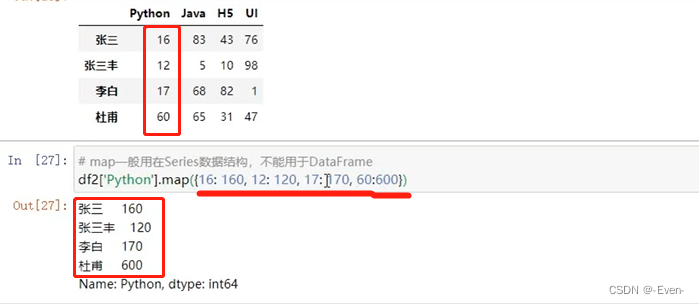
# map是Series调用,不能使用DataFrame调用
df2['Python'].map({
12: 100, 11: 90})
# map()函数中可以使用lambda函数
# 新建一列
df2['NumPy'] = df2['Python'].map(lambda x: x+100) #表示python列所有+100之后,新增到numpy列
df2
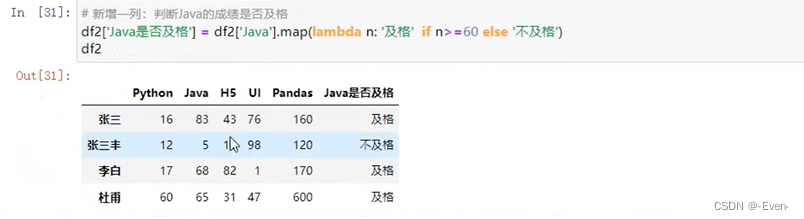
# 新增一列:判断java成绩是否及格
df2['是否及格'] = df2['Java'].map(lambda n: "及格" if n>=60 else "不及格")
df2
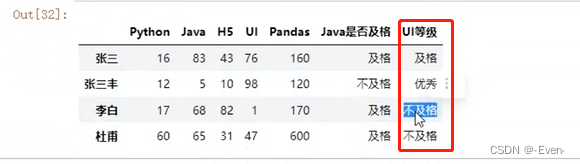
# 新增一列:判断Java成绩的等级(>=80优秀,>=60及格,<60不及格)
def fn(n):
if n >= 80:
return '优秀'
elif n >= 60:
return '及格'
return '不及格'
df2['等级'] = df2['Java'].map(fn)
df2
6.2.3 rename()函数:替换更改索引
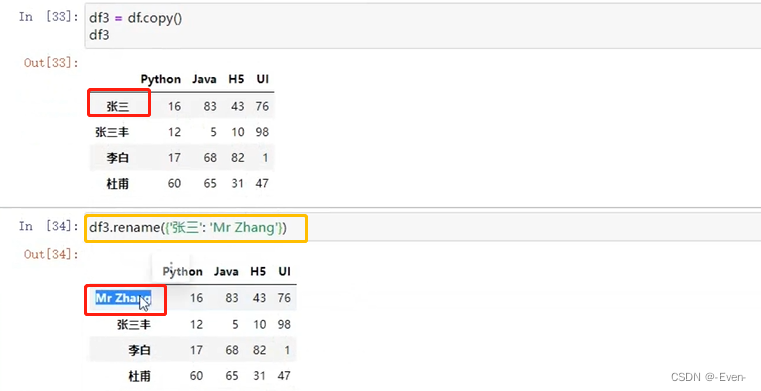
df3 = df.copy()
df3
# 更改索引名称
df3.rename({
'鲁班': "Mr Lu"}) # 默认更改 行索引
df3.rename({
'Python': 'PYTHON'}, axis=1) # 更改 列索引
df3.rename(index={
'鲁班': "Mr Lu"}) # 更改行索引
df3.rename(columns={
'Python': 'PYTHON'}) # 更改列索引
6.2.4 apply()函数:既支持 Series,也支持 DataFrame
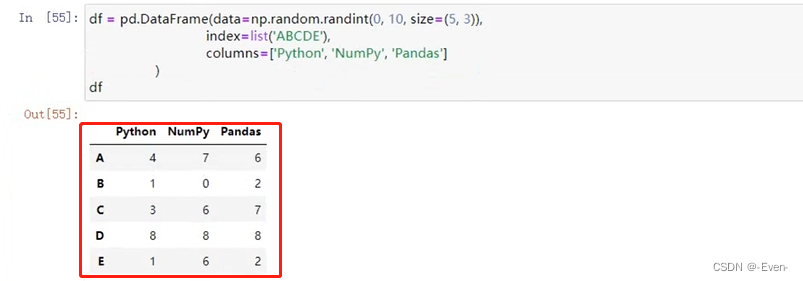
df = pd.DataFrame(data=np.random.randint(0, 10, size=(5,3)),
index=list('ABCDE'),
columns=['Python', 'NumPy', 'Pandas'])
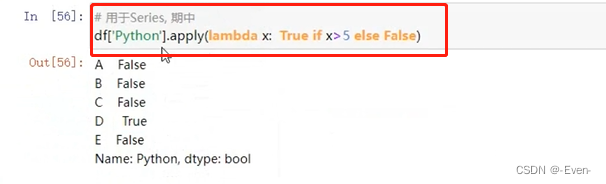
# 用于Series,其中x是Series中元素
df['Python'].apply(lambda x:True if x >5 else False)
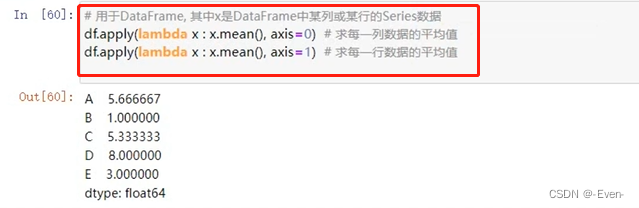
# 用于DataFrame,其中的x是DataFrame中列或者行,是Series
df.apply(lambda x : x.median(), axis=0) # 列的中位数
df.apply(lambda x : x.median(), axis=1) # 行的中位数
# 自定义方法
def convert(x):
return (np.round(x.mean(), 1), x.count())
df.apply(convert, axis=1) # 行平均值,计数
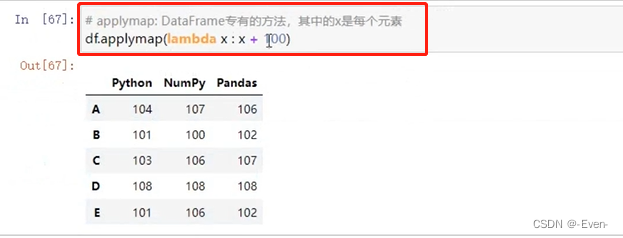
# applymap: DataFrame专有, 其中的x是DataFrame中每个元素
df.applymap(lambda x : x + 100) # 计算DataFrame中每个元素
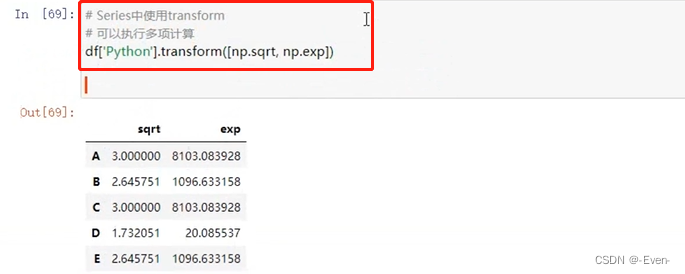
6.2.5 transform()函数:既支持 Series,也支持 DataFrame
df = pd.DataFrame(data=np.random.randint(0, 10, size=(10,3)),
index=list('ABCDEFHIJK'),
columns=['Python', 'NumPy', 'Pandas'])
# 1、一列执行多项计算
# 可以执行多项计算
# np.sqrt 平方根
df['Python'].transform([np.sqrt, np.exp]) # Series处理
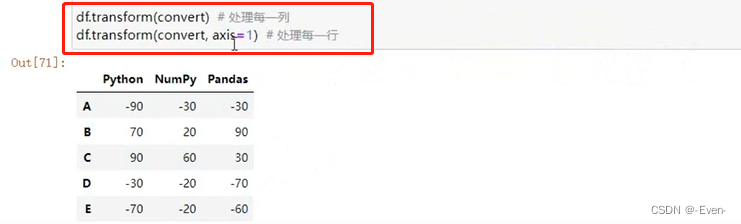
# 2、多列执行不同计算——DataFrame处理
def convert(x):
if x.mean() > 5: # mean()平均值
x *= 10
else:
x *= -10
return x
df.transform({
'Python':convert,'NumPy':np.max,'Pandas':np.min})

6.3 异常值检测和过滤
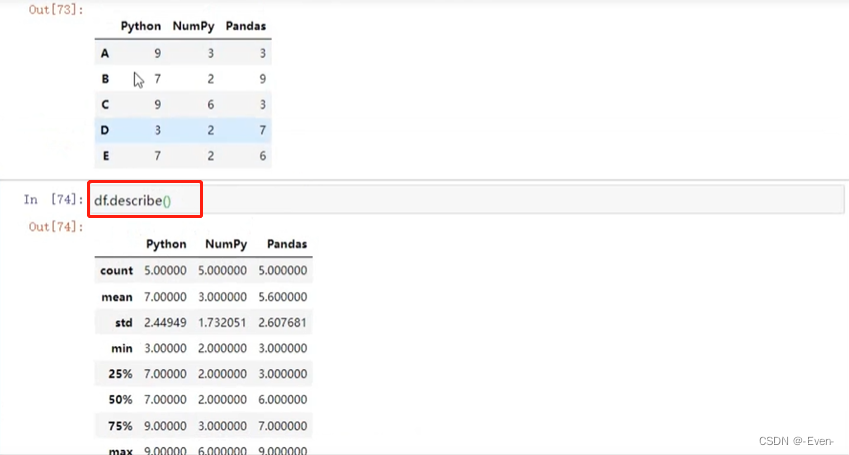
- describe(): 查看每一列的描述性统计量
# 查看每一列的描述性统计 必须是数字,是字符串则不行
df.describe()
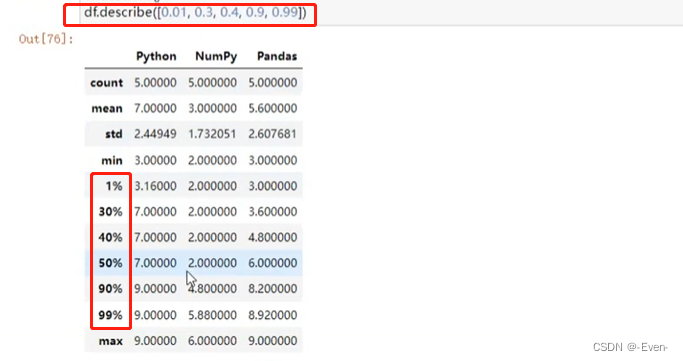
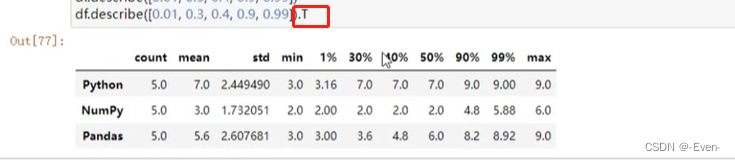
df.describe([0.3, 0.4, 0.5, 0.9, 0.99]) # 指定百分位数
df.describe([0.3, 0.4, 0.5, 0.9, 0.99]).T # 转置,行和列转换,在列比较多的情况下使用
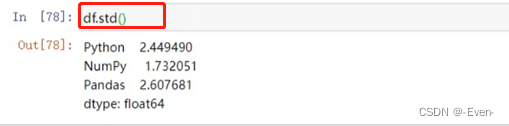
- df.std() : 可以求得DataFrame对象每一列的标准差
df.std()
- ==df.drop(): 删除特定索引 ==
df4 = df.copy()
df4
df4.drop('鲁班') # 默认删除行
df4.drop('Java', axis=1) # 删除列
df4.drop(index='鲁班') # 删除行
df4.drop(columns='H5') # 删除列
df4.drop(columns=['Java', 'Pandas']) # 同时删除多列
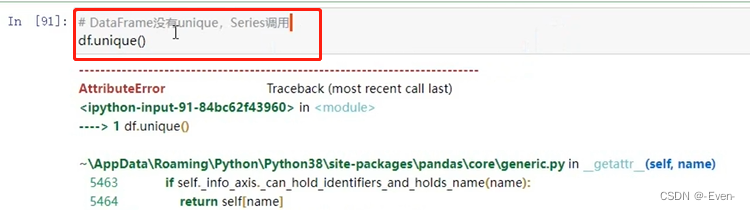
- unique() : 唯一,去重
index = ['鲁班', '张三丰', '张无忌', '杜甫', '李白']
columns = ['Python', 'Java', 'H5', 'Pandas']
data = np.random.randint(0, 10, size=(5, 4))
df = pd.DataFrame(data=data, index=index, columns=columns)
df
# unique() : 要用于Series, 不能用于DataFrame
df['Python'].unique()
- query() : 按条件查询
# ==, >, <,
# in
# and &
# or |
df.query('Python == 9') #找到python列中等于9的所有行
df.query('Python > 5')
df.query('Python==5 and Java==5')
df.query('Python==5 & Java==5')
df.query('Python==5 or Java==6')
df.query('Python==5 | Java==6')
df.query('Python in [3, 4, 5, 6]')
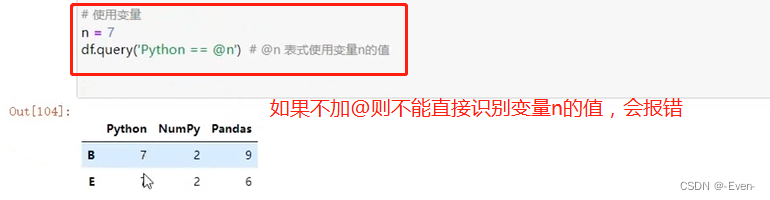
# 使用变量
n = 7
df.query('Python > @n') # @n 表示使用变量n的值
m = [3, 4, 5, 6]
df.query('Python in @m')

-
df.sort_values(): 根据值排序
-
df.sort_index(): 根据索引排序
index = ['A', 'B', 'C', 'D', 'E']
columns = ['Python', 'Java', 'H5', 'Pandas']
data = np.random.randint(0, 100, size=(5, 4))
df = pd.DataFrame(data=data, index=index, columns=columns)
df
df.sort_values('Python') # 默认按照列名排序,默认升序
# ascending是否升序,默认true
df.sort_values('Python', ascending=False) # 降序
# 根据行索引名排序,会把列进行排序
df.sort_values('B', axis=1)
# 按照行索引或列索引排序
# 默认是对行索引进行排序,默认是升序ascending=True
# 加上axis=1,即对列名进行排序
df.sort_index(ascending=False, axis=1)
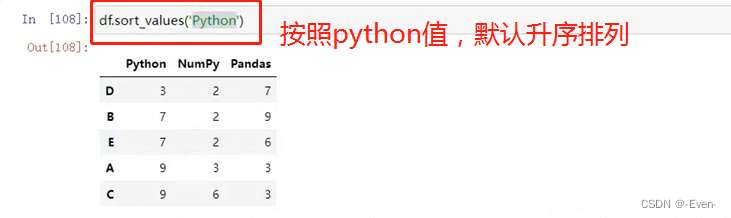
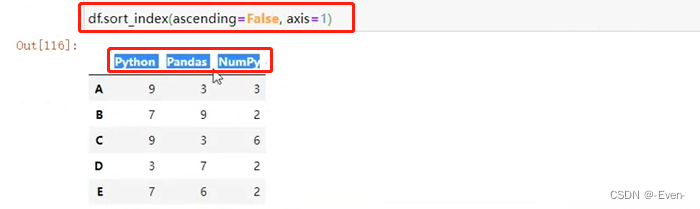
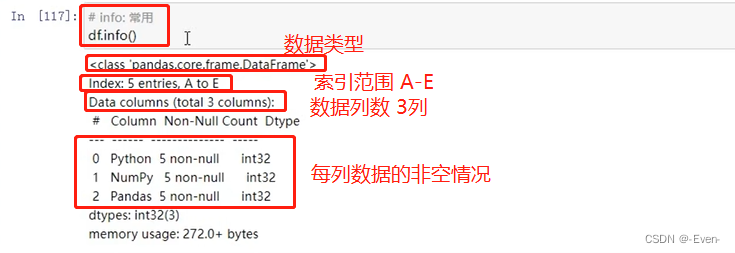
- df.info(): 查看数据信息(常用)
df.info()
练习:
新建一个形状为10000*3的标准正态分布的DataFrame,去除掉所有满足以下情况的行:
- 其中任一元素绝对值大于3倍标准差
df = pd.DataFrame(np.random.randn(10000, 3))
df.head()
# 标准差
df.std()
# 绝对值
df.abs()
# cond: 找到大于3倍标准差的值
cond = df.abs() > df.std() * 3
# cond.sum()
cond
# 找到有True(大于3倍标准差的值)的行
cond2 = cond.any(axis=1)
cond2
# 去除大于3倍标准差的值,取不满足大于3倍标准差的值
df.loc[~cond2]
6.4 抽样
-
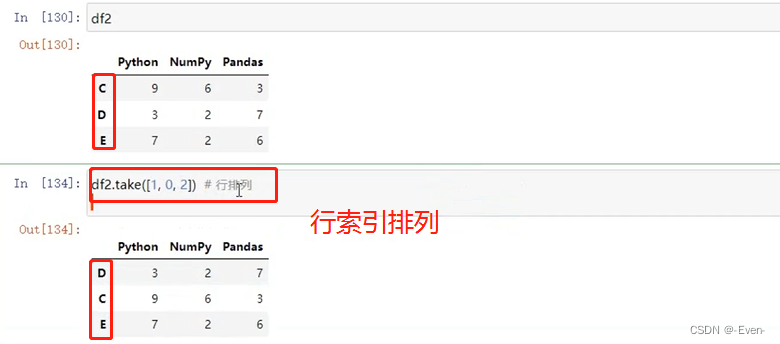
使用.take()函数排序
-
可以借助np.random.permutation()函数随机排序
# 使用前面的df2
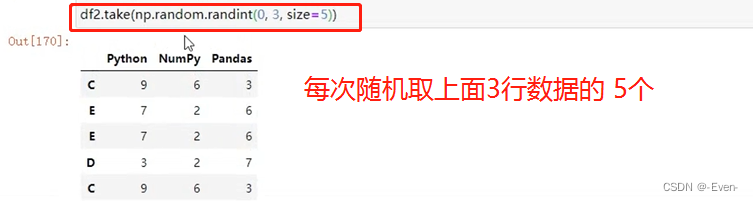
# take()进行函数排序 [0,1,2]指行的索引
df2.take([1, 0, 2]) # 行排列
df2.take([1, 0, 2], axis=1) # 列排列
# 随机排序
np.random.permutation([0, 1, 2])
# 1、无放回抽样:依次随机取出,没有重复值
df2.take(np.random.permutation([0, 1, 2]))
# 2、有放回抽样: 可能出现重复值
# 当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样
np.random.randint(0, 5, size=10)
df2.take(np.random.randint(0, 3, size=5))


7、Pandas数学函数
- 聚合函数
df = pd.DataFrame(data=np.random.randint(0,100,size = (5,3)))
# 下面都是默认求列
df.count() # 非空值的数量
df.max() # 求每一列中不同行之间的最大值,axis=0/1
df.min() # 最小值, axis=0/1
df.median() # 中位数
df.sum() # 求和
df.mean(axis=1) # 每一行的平均值
df[0].value_counts() # 统计元素出现次数
df.cumsum() # 累加
df.cumprod() # 累乘
# 方差: 当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大;当数据分布比较集中时,各个数据与平均数的差的平方和较小。因此方差越大,数据的波动越大;方差越小,数据的波动就越小
df.var() # 方差
# 标准差 = 方差的算术平方根
df.std() # 标准差
- 其他数学函数
- 协方差
- 两组数值中每对变量的偏差乘积的平均值
- 协方差>0 : 表式两组变量正相关
- 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值时另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值;
- 协方差<0 : 表式两组变量负相关
- 如果两个变量的变化趋势相反,即其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
- 协方差=0 : 表式两组变量不相关- 相关系数
- 相关系数r = X与Y的协方差 / (X的标准差 * Y的标准差)
- 相关系数值的范围在-1和+1之间
- r>0为正相关,r<0为负相关。r=0表示不相关
- r 的绝对值越大,相关程度越高
- 两个变量之间的相关程度,一般划分为四级:
- 如两者呈正相关,r呈正值,r=1时为完全正相关;
- 如两者呈负相关则r呈负值,而r=-1时为完全负相关,完全正相关或负相关时,所有图点都在直线回归线上;点分布在直线回归线上下越离散,r的绝对值越小。
- 相关系数的绝对值越接近1,相关越密切;越接近于0,相关越不密切。
- 当r=0时,说明X和Y两个变量之间无直线关系。
- 通常|r|大于0.8时,认为两个变量有很强的线性相关性。
- 相关系数
- 协方差
# 协方差
# 两组数值中每对变量的偏差乘积的平均值
df.cov()
df[0].cov(df[1]) # 第0列 和 第1列的协方差
# 相关系数 = X与Y的协方差 / (X的标准差 * Y的标准差)
df.corr() # 所有属性相关性系数
df.corrwith(df[2]) # 单一属性相关性系数
协方差: C o v ( X , Y ) = ∑ 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) n − 1 Cov(X,Y) = \frac{\sum\limits_1^n(X_i - \overline{X})(Y_i - \overline{Y})}{n-1} Cov(X,Y)=n−11∑n(Xi−X)(Yi−Y)
相关性系数: r ( X , Y ) = C o v ( X , Y ) V a r [ X ] ∗ V a r [ Y ] r(X,Y) = \frac{Cov(X,Y)}{\sqrt{Var[X]*Var[Y]}} r(X,Y)=Var[X]∗Var[Y]Cov(X,Y)
8、 数据分组聚合
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
8.1 分组
数据聚合处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心: groupby()函数
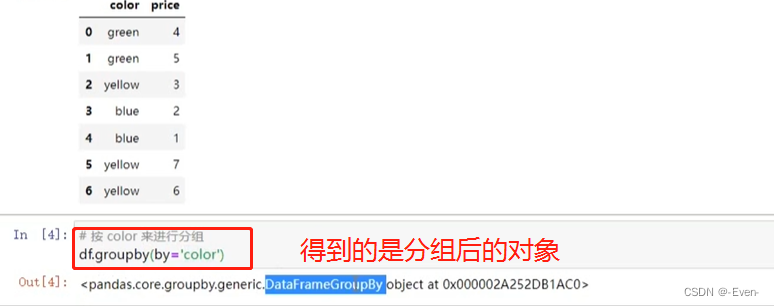
# 创建DataFrame
df = pd.DataFrame(
{
'color': ['green', 'green', 'yellow', 'blue', 'blue', 'yellow', 'yellow'],
'price': [4, 5, 3, 2, 7, 8, 9]
}
)
df
# 使用.groups属性查看各行的分组情况:
# 根据color进行分组
df.groupby(by='color')
# 使用.groups属性查看各行的分组情况
df.groupby(by='color').groups
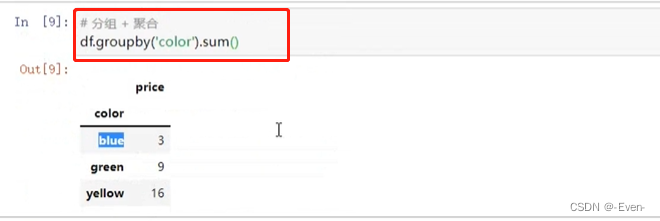
# 分组 + 聚合
df.groupby(by='color').sum()

8.2 分组聚合练习:
假设菜市场张大妈在卖菜,有以下属性:
-
菜品(item):萝卜,白菜,辣椒,冬瓜
-
颜色(color):白,青,红
-
重量(weight)
-
价格(price)
- 要求以属性作为列索引,新建一个ddd
- 对ddd进行聚合操作,求出颜色为白色的价格总和
- 对ddd进行聚合操作,求出萝卜的所有重量以及平均价格
- 使用merge合并总重量及平均价格
ddd = pd.DataFrame(
data={
"item": ["萝卜","白菜","辣椒","冬瓜","萝卜","白菜","辣椒","冬瓜"],
'color':["白","青","红","白","青","红","白","青"],
'weight': [10,20,10,10,30,40,50,60],
'price': [0.99, 1.99, 2.99, 3.99, 4, 5, 6,7]
}
)
ddd
# 2. 对ddd进行聚合操作,求出颜色为白色的价格总和
ddd.groupby('color')['price'].sum() # Series
ddd.groupby('color')[['price']].sum() # DataFrame
ddd.groupby('color')[['price']].sum() .loc[['白']]
# 3. 对ddd进行聚合操作,求出萝卜的所有重量以及平均价格
df1 = ddd.groupby('item')[['weight']].sum()
df2= ddd.groupby('item')[['price']].mean()
# 4.使用merge合并总重量及平均价格
# display(df1, df2)
df1.merge(df2, left_index=True, right_index=True)
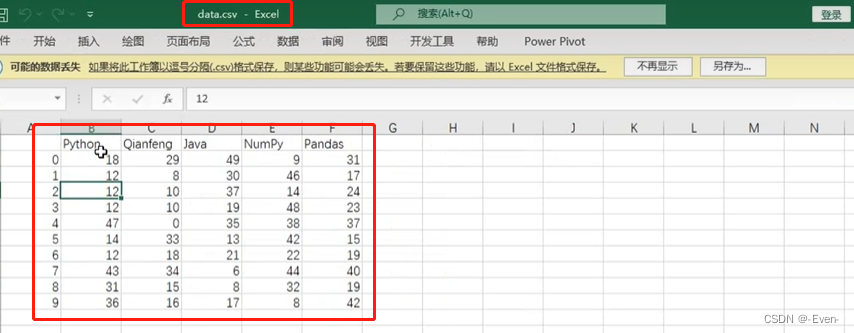
9、Pandas加载数据
9.1 csv数据
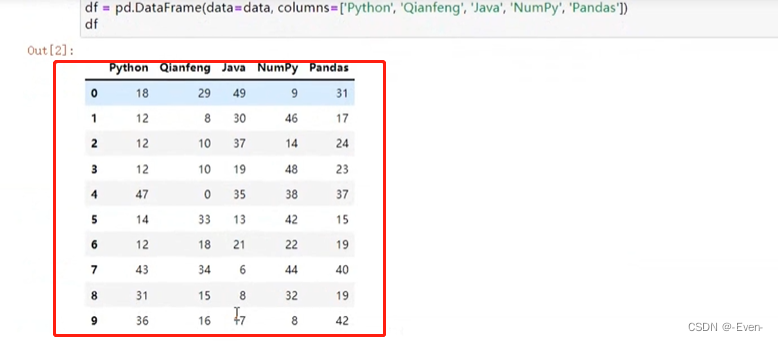
data = np.random.randint(0,50,size=(10,5))
df = pd.DataFrame(data=data, columns=['Python','Qianfeng','Java','NumPy','Pandas'])
# 保存到csv
df.to_csv('data.csv',
sep=',', # 文本分隔符,默认是逗号
header=True, # 是否保存列索引
# 是否保存行索引,保存行索引,文件被加载时,默认行索引会作为一列
index=True)
# 加载csv数据
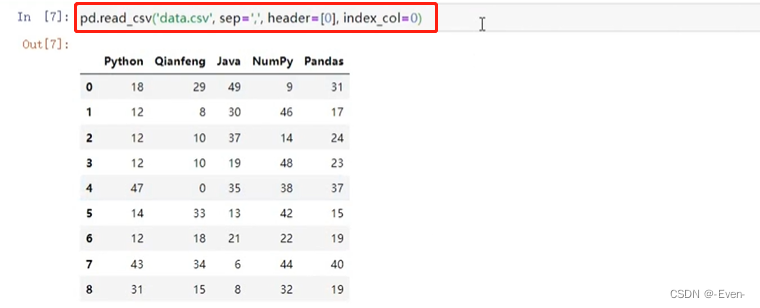
pd.read_csv('data.csv',
sep=',', # 默认是逗号
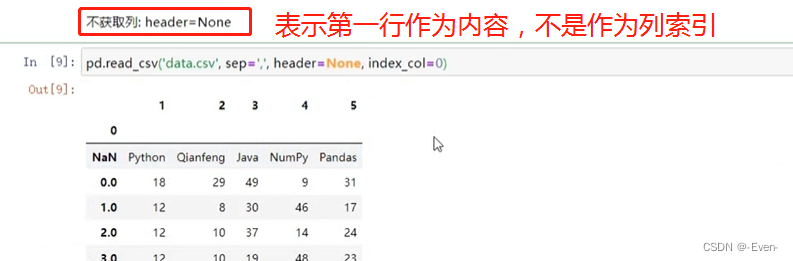
header=[0], # 指定列索引,如果header=None表示第一行不是作为列索引,而是作为列内容
index_col=0) # 指定行索引
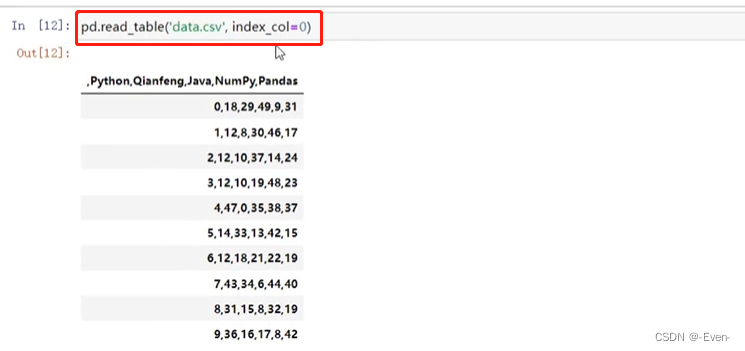
# 与上面的read_csv的区别在于分割符
# read_csv默认分隔符是sep=','
# read_table默认分隔符是sep='\t' 但想要取sep=','也是可以的
pd.read_table('data.csv', # 和read_csv类似,读取限定分隔符的文本文件
sep=',',
header=[0], # 指定列索引
index_col=0 # 指定行索引
)
9.2 excel数据
data = np.random.randint(0, 50, size=(10,5))
df = pd.pDataFrame(data=data, columns=['Python','Java','Go','C','JS'])
# 保存到excel文件
df.to_excel('data.xlsx',
sheet_name='sheet1',# Excel中工作表的名字
header=True, # 是否保存列索引
index=False) # 是否保存行索引
# 读取excel
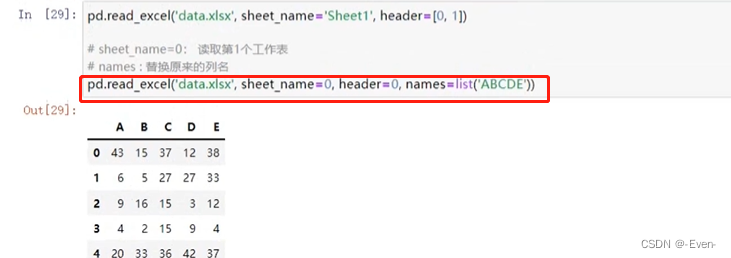
pd.read_excel('data.xlsx',
sheet_name=0, # 读取哪一个Excel中工作表,默认第一个, 也可以写工作表名称
header=0, # 使用第一行数据作为列索引 指定多行列索引也可以header=[0,1]
names=list('ABCDE'), # 替换原来的行索引
index_col=1) # 指定行索引,B作为行索引
9.3 MySQL数据
- 需要安装pymysql
- pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
- 需要安装sqlalchemy:
- pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
- sqlalchemy是Python语言下的数据库引擎库, 在Django/Flask中常用ORM库
from sqlalchemy import create_engine
data = np.random.randint(0,150,size=(150,3))
df = pd.DataFrame(data=data, columns=['Python','Pandas','PyTorch'])
# 数据库连接
# root: MySQL用户名
# 123456: MySQL密码
# localhost: 本机
# db: 数据库名(提前创建)
conn = create_engine('mysql+pymysql://root:123456@localhost/db')
# 保存到MySQL
df.to_sql('score', # 表名(会自动创建表)
con=conn, # 数据库连接
index=False, # 是否保存行索引
if_exists='append') # 如果表名存在,追加数据
# 从MySQL中加载数据
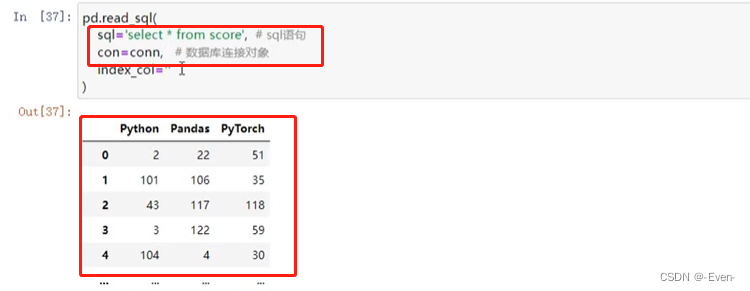
pd.read_sql('select * from score', # sql查询语句
con=conn, # 数据库连接
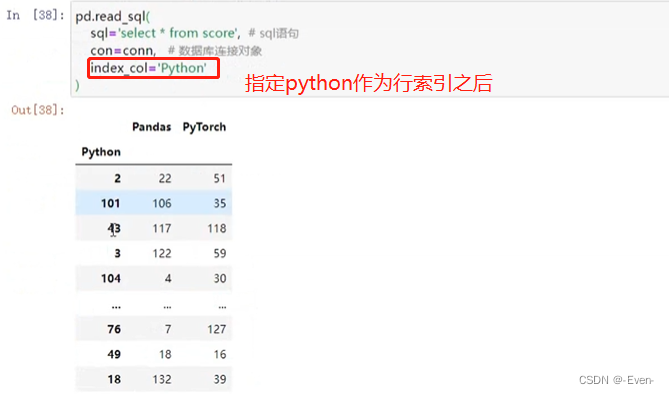
index_col='Python') # 指定行索引名
10、Pandas分箱操作
- 分箱操作就是将连续型数据离散化。
- 分箱操作分为等距分箱和等频分箱。
data = np.random.randint(0,100,size=(5,3))
df = pd.DataFrame(data=data, columns=['Python','Pandas','PyTorch'])
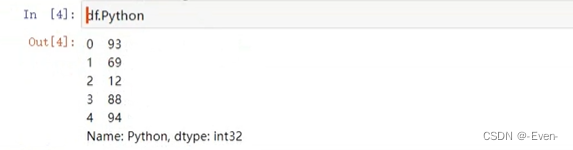
# 对Python列进行分箱
df.Python
# 1、等宽分箱(常用)
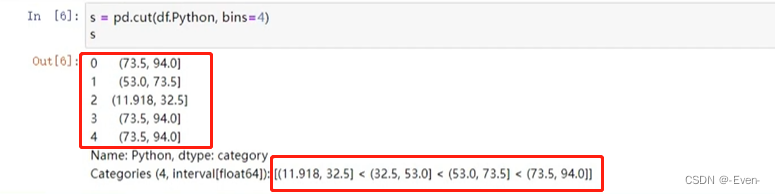
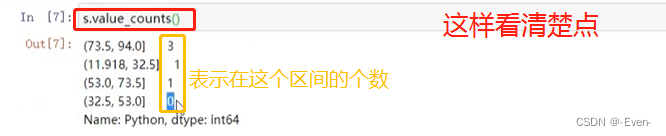
pd.cut(df.Python, bins=4) # 第一个参数:分箱数据 第二个参数:bins分组数量,分成几组
# 指定宽度分箱
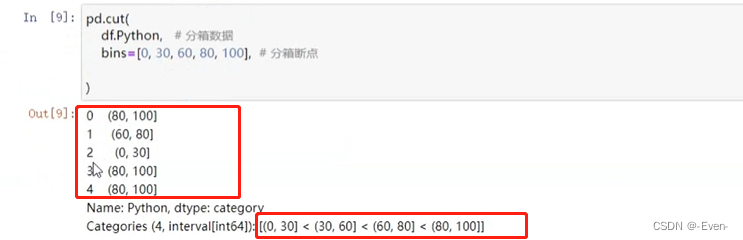
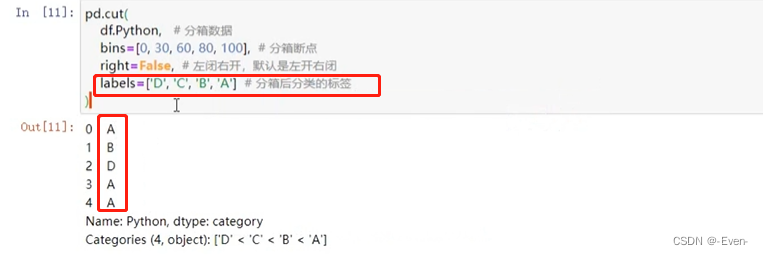
pd.cut(df.Python, # 分箱数据
bins=[0, 30, 60, 80, 100], # 分箱断点
right=False, # 左闭右开 默认是左开右闭
labels=['D','C','B','A']) # 分箱后分类标签
# 2、等频分箱
pd.qcut(df.Python, # 分箱数据
q=4, # 4等份
labels=['差', '中', '良', '优']) # 分箱后分类标签
11、Pandas时间序列
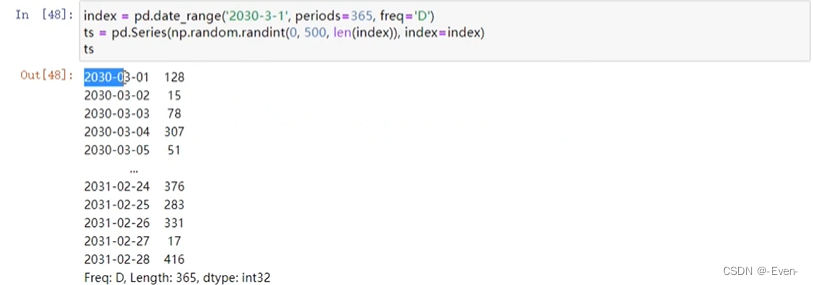
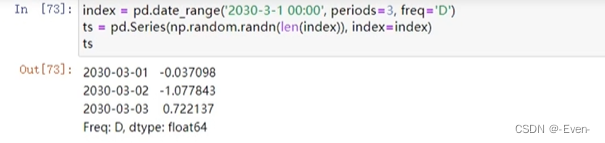
11.1 创建时间




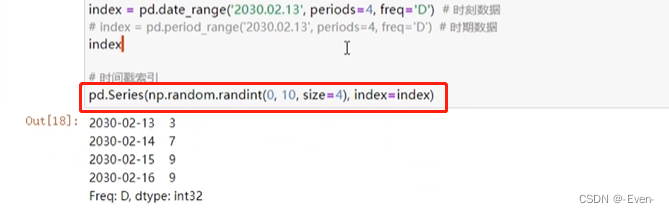
11.2 时间转换&索引&切片和属性
-
转换方法


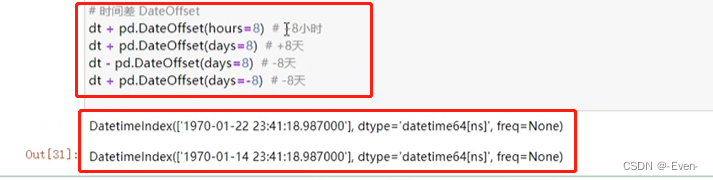
-
索引
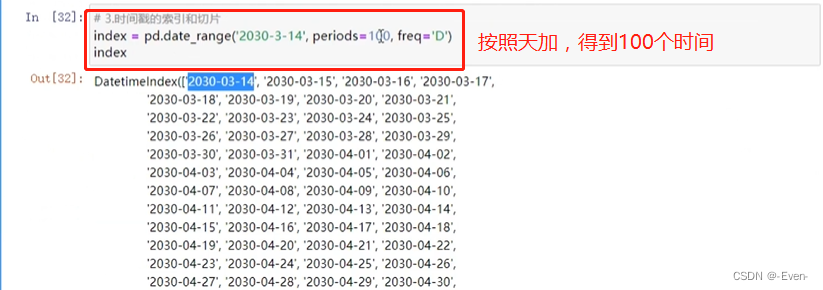
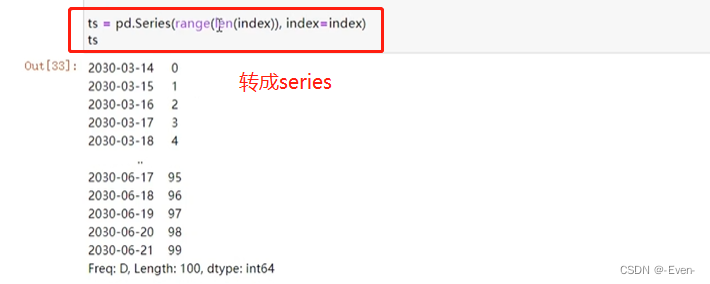
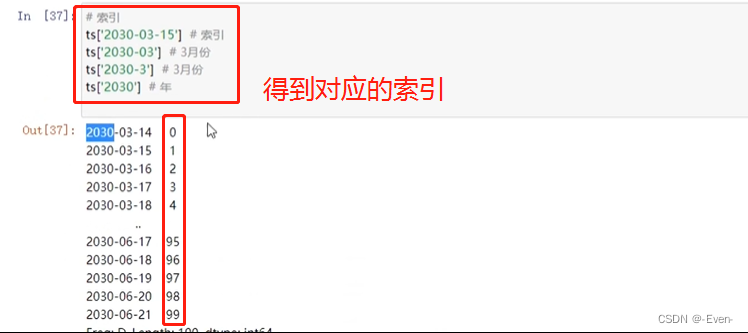
-
切片
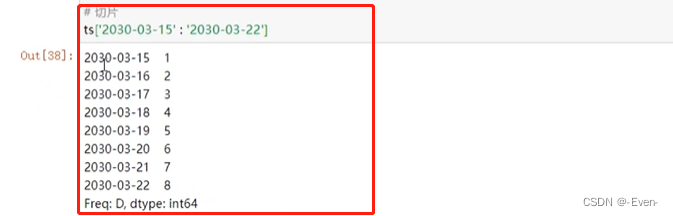
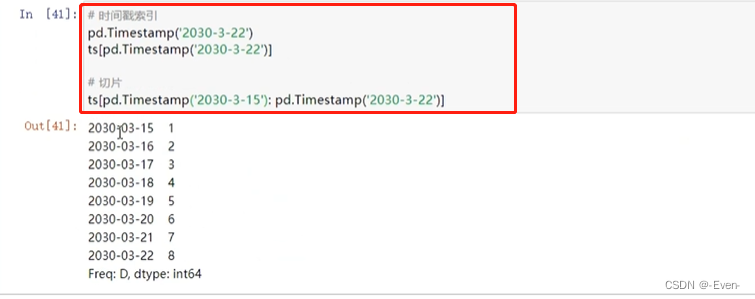
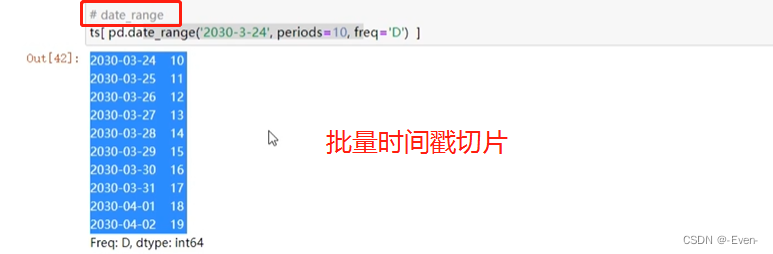
-
属性
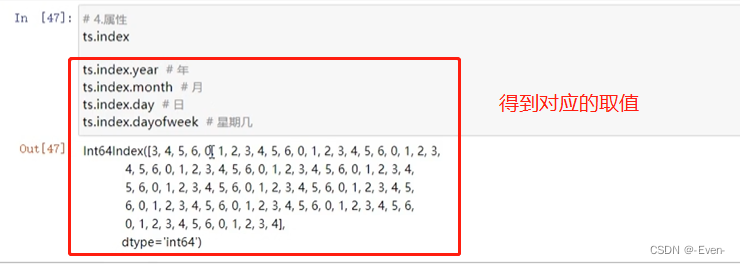
11.3 时间移动和频率
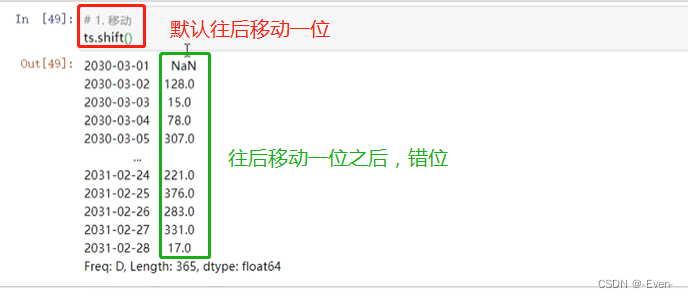
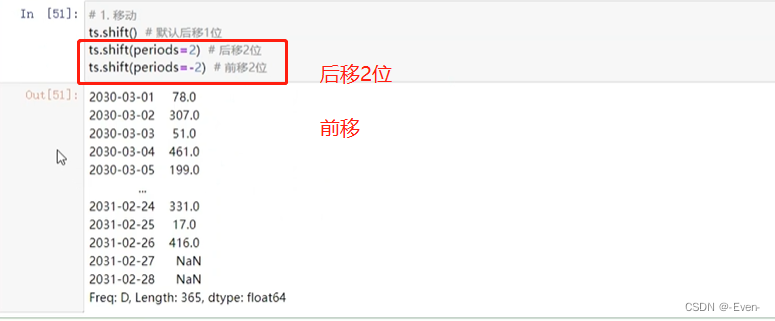
-
移动
-
频率转换
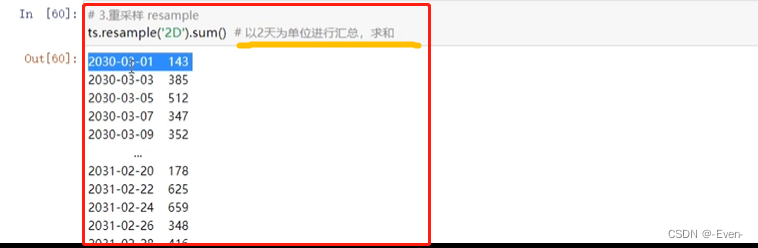
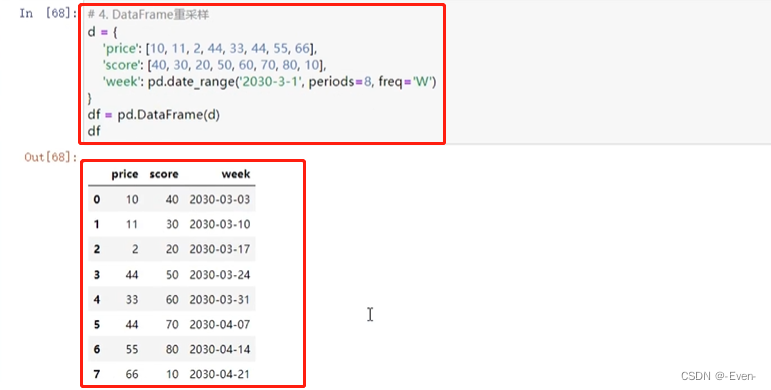
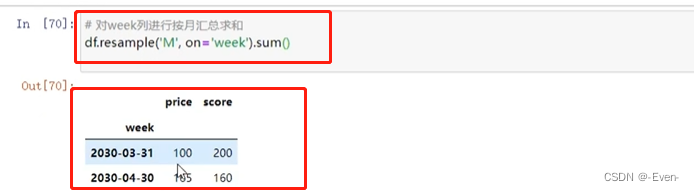
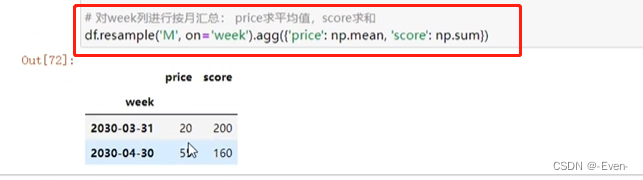
11.4 重采样resample:根据日期维度进行数据集合
- 按照分钟(T)、小时(H)、日(D)、周(W)、月(M)、年(Y)等来作为日期维度
- Series
- DataFrame
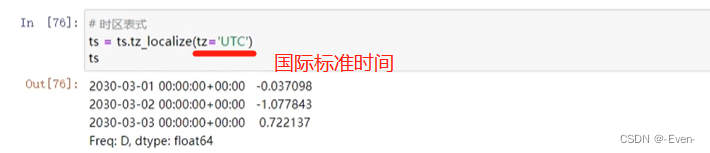
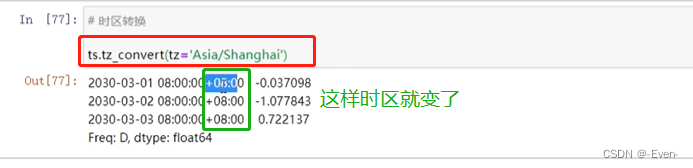
11.5 时区
# tz:timezone 时区
import pytz

12、Pandas绘图
- Series和DataFrame都有一个用于生成各类图表的plot方法
- Pandas的绘图是基于Matplotlib, 可以快速实现基本图形的绘制,复杂的图形还是需要用Matplotlib
常见可视化图形:
- 折线图
- 条形图/柱形图
- 饼图
- 散点图
- 箱型图
- 面积图
- 直方图
import matplotlib.pyplot as plt
12.1 折线图
# 折线图
# Series画图
s = pd.Series([100, 250, 300, 200, 150, 100])
s.plot()
# sin曲线:正弦曲线
# np.pi是π的意思,3.14
x = np.arange(0, 2*np.pi, 0.1) # 中间间隔是0.1
y = np.sin(x)
s = pd.Series(data=y, index=x)
s.plot() # 值(data=y)是y轴,索引(index=x)是x轴
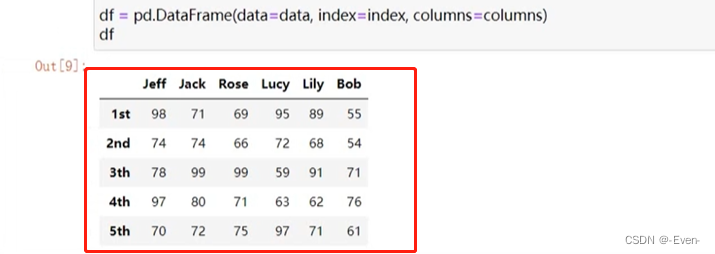
# DataFrame画图
data = np.random.randint(50, 100, size=(5, 6))
index = ['1st', '2nd', '3th', '4th', '5th']
columns = ['Jeff', 'Jack', 'Rose', 'Lucy', 'Lily', 'Bob']
df = pd.DataFrame(data=data, index=index, columns=columns)
df.plot() # 每一列一根线
# df.T.plot() # 每一行一根线

12.2 条形图/柱形图
# 条形图/柱形图
df = pd.DataFrame(data=np.random.rand(10,4))
df.plot.bar(stacked=True) # stacked 是否堆叠
# Series画图
# 可以使用plot中的kind属性来绘制不同图形
s = pd.Series(data=[100, 110, 130, 200])
s.index = ['Jeff', "千锋", 'Python', 'Rose']
s.plot(kind='bar') # 柱状图
# 或
s.plot(kind='barh') # 条形图
# kind:
# - 'line' : line plot (default)
# - 'bar' : vertical bar plot
# - 'barh' : horizontal bar plot
# - 'hist' : histogram
# - 'box' : boxplot
# - 'kde' : Kernel Density Estimation plot
# - 'density' : same as 'kde'
# - 'area' : area plot
# - 'pie' : pie plot
# - 'scatter' : scatter plot
# - 'hexbin' : hexbin plot.
# DataFrame画图
data = np.random.randint(0, 100, size=(4, 3))
index = list('ABCD')
columns = ['Python', 'C', 'Java']
df = pd.DataFrame(data=data, index=index, columns=columns)
df.plot(kind='bar')
# 或
df.plot(kind='barh')
12.3 饼图
# 饼图
df = pd.DataFrame(data=np.random.rand(4,2),
index=list('ABCD'),
columns=['Python','Java'])
# subplots=True 子图:同时画多个图
# autopct='%.1f%%' 显示占比,保留1位小数
df.plot.pie(subplots=True, figsize=(8,8), autopct='%.1f%%')
12.4 散点图
- 散点图是观察两个一维数据数列之间的关系的有效方法,DataFrame对象可用
# 散点图
data = np.random.normal(size=(1000, 2))
df = pd.DataFrame(data=data, columns=list('AB'))
df.head()
# scatter: 散点图
# x='A' :使用A列作为x轴
# y='B' :使用B列作为y轴
df.plot(kind='scatter', x='A', y='B')
# 或
df.plot.scatter(x='A', y='B') # A和B关系绘制
12.5 面积图
# 面积图
df = pd.DataFrame(data=np.random.rand(10, 4), columns=list('ABCD'))
df.plot.area(stacked=True) # stacked 是否堆叠
12.6 箱型图
# 箱型图
df = pd.DataFrame(data=np.random.rand(10, 5), columns=list('ABCDE'))
df.plot.box()
# 或
df.plot(kind='box')
12.7 直方图
# 直方图
df = pd.DataFrame({
'A': np.random.randn(1000) + 1,
'B': np.random.randn(1000),
'C': np.random.randn(1000) - 1})
df.plot.hist(alpha=0.5) # 带透明度直方图
df.plot.hist(stacked=True) # 堆叠图
# 或
df['A'].plot(kind='hist')
df.plot(kind='hist')