chapter1 mooc
Test1
1.判断以下行为是否属于数据挖掘任务:监测患者的心率是否异常
来自 <数据仓库与数据挖掘_北京理工大学_中国大学MOOC(慕课)>
是的,监测患者的心率是否异常可以被认为是数据挖掘任务的一种。
数据挖掘是通过对大量数据进行分析,发现其中的模式、关联和趋势,并从中提取有用的信息和知识。在这种情况下,监测患者的心率是否异常涉及收集和记录患者的心率数据,然后对这些数据进行分析以识别异常模式或趋势。
来自 <https://poe.com/chat/2k540yisp8vwhcldfa3>
2.数据挖掘是从大量数据中挖掘重要、隐含的、以前未知、______的模式或知识。
来自 <https://poe.com/chat/2k540yisp8vwhcldfa3>
潜在有用的
3.数据仓库的角度可以将数据挖掘过程划分为数据清理、数据集成、数据选择与变换、数据挖掘及_______等阶段。
知识评估
4.买啤酒的人很大概率也会购买尿布——关联规则发现
5.
当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离——聚类
6.不属于数据挖掘任务——根据顾客的职业将顾客进行分组;提取声波的频率;预测掷骰子的结果
7.属于DM——根据顾客的购物记录预测顾客感兴趣;监测患者的心率是否异常
chapter2
内容
| 2Data |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||











mooc题目
| 单选 (2分) age 值(以递增序) 为: 13,15,16,16,19,20,20,21,22,22,25.25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70。使用 z-score规范化将 age 值 35 变换到[0.0,1.0]区间,变换后的值为 () |
|
||||||||
| 单选 (2分) 假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为: () |
|
||||||||
| 属性类型 |
标称属性(nominal attribute)、二元属性(binary attribute)、序数属性(ordinal attribute)、 数值属性(numerical attribute)、离散属性与连续属性。 |
||||||||
| 填空(2分) |
中位数 |
||||||||
| 填空(2分) 定用于分析的数据包含属性age。age 值(以递增序)为: 13,15,1616,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,3536,40,45,46,52,70。则数据的第一个四分位数的值为 ,第三个四分位数的值为35 20 |
|
||||||||
| 填空 (2分)考虑值集(1224 3324 55 682,其四分位数极差是: |
|
||||||||
| 数据集的属性可以划分为____和连续型两种。 |
离散型 |
||||||||
| 两个向量d1 = (1,1,2,1,1,1,0,0,0) d2 = (1,1,1,0,1,1,1,1,1)的余弦相似度为() |
|
||||||||
| 4 单选(2分) 下面不属于数据集特征的是 A.稀疏性 B.连续性 C.分辨率 D.维度 |
|
||||||||
| 数据挖掘感念与技术第三版-----------课后习题(部分) - 一杯Java不加糖 - 博客园 (cnblogs.com) |
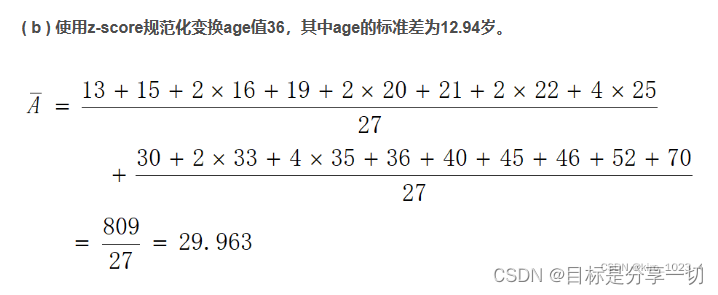




chapter3数据预处理
内容
| 预处理的主要步骤 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 数据清理 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 数据集成 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 数据转换 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 数据约减 |
|











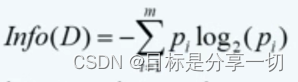



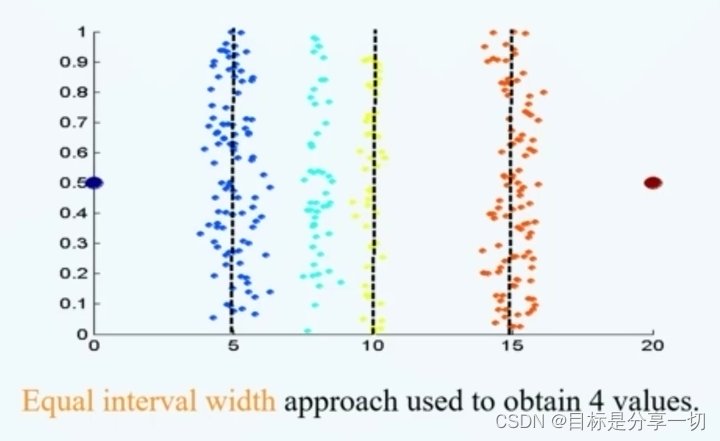
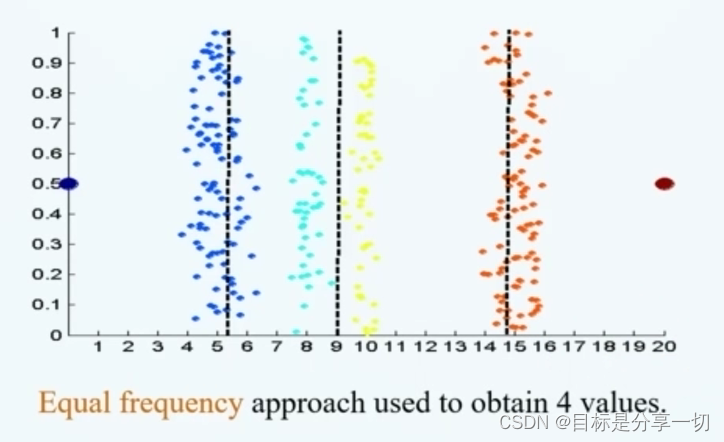
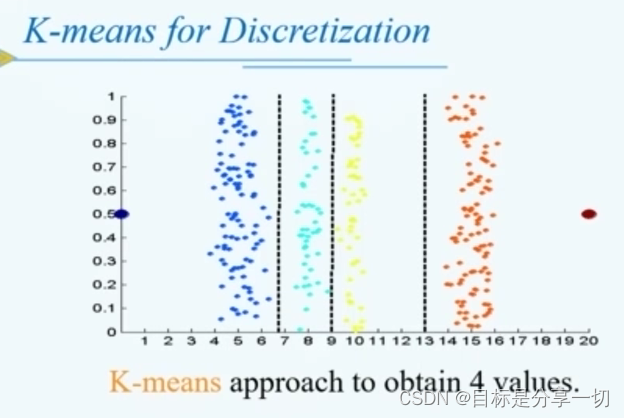

mooc题目
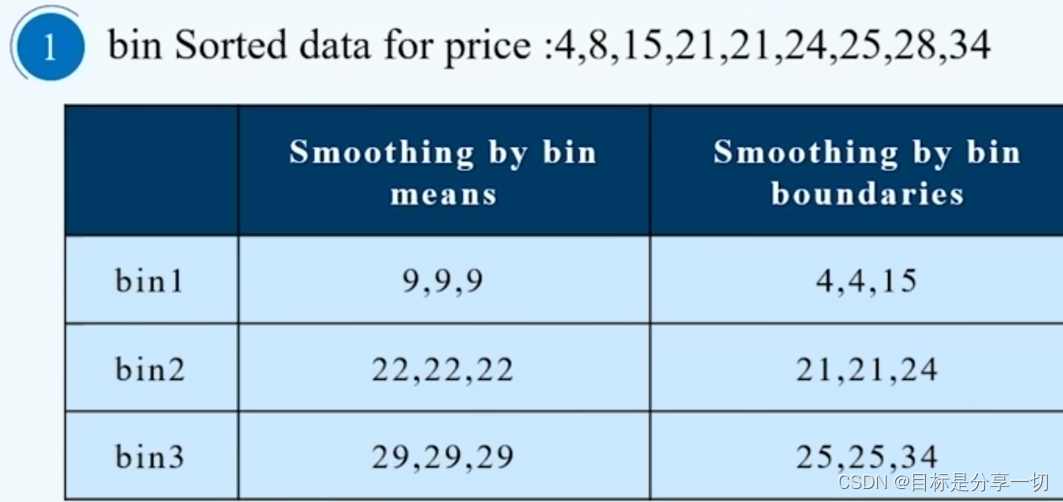
| 单选(2分)假设12个销售价格记录组已经排序如下:5,10,11,13,15,35,50,55,72,92,204,215使用如下每种方法将它们划分成四个箱。等频(等深) 划分时,15在第几个箱子内? (2) |
|
||||||
| 2 单选(2分) 以下哪种方法不是常用的数据约减方法(C) A.聚类 B.抽样 C.关联规则挖掘 D.回归 |
|
||||||
| 单选(2分) 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序): 13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70,问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱子值为: () |
|
||||||
| 4 判断(2分) 主成分分析法是一种有参的数据约减方法【T】 |
|
||||||
| 5 判断(2分)离散属性总是具有有限个值。 A.X B.√ |
错 |
||||||
| 判断(2分) 特征提取技术并不依赖于特定的领域。【×】 A.√ B.X |
|
||||||
| 判断(2分) 可以通过创造新的属性并加入到现有属性集中实现更有效的挖掘 A.√ B.X |
|
||||||
| 判断(2分) 通过离散化操作可以将连续属性转化为序数属性 AX B.√ |
对 |
||||||
| 判断(2分) 通过数据集成可以维护数据源整体上的数据一致性 AX B.√ |
|
||||||
| 判断(2分) 可以将异常视为缺失值,利用缺失值处理的方法处理也可以用前后俩个观测值的平均值修正该异常值 |
|

chapter4Data Warehousing
| Topic |
为什么要学数据仓库+数据仓库与数据库的区别是什么 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 基本概念 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 数据模型与它所做的基本操作olap |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 应用 |
数据的查询分析 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 动态 |
结构化数据库->非结构化数据库->面向查询分析的数据库仓库 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||







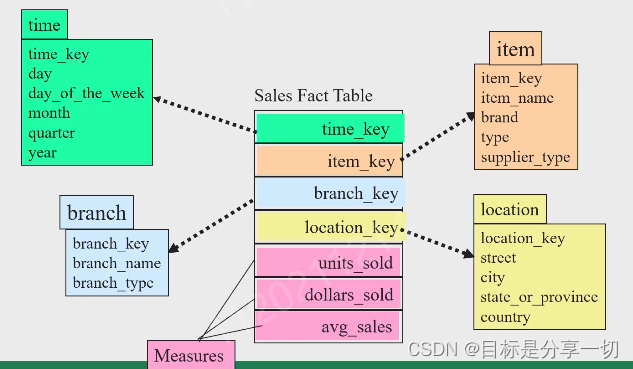
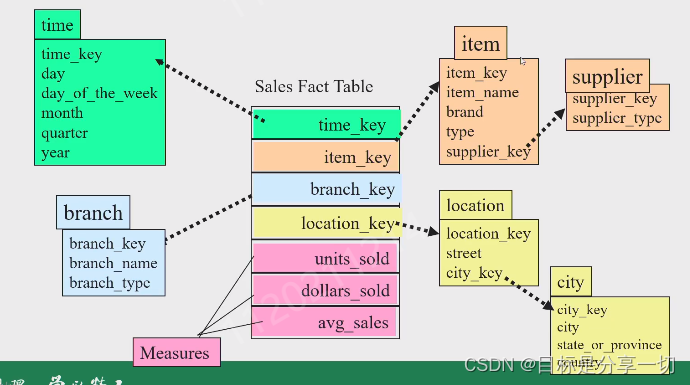
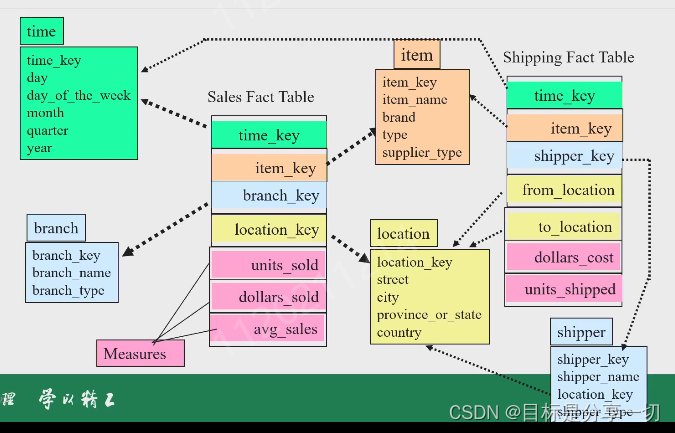



chapter4关联规则挖掘的内容
内容
| 基本概念 |
|
||||||||||||||||||||||||||||||||||||||||||
| 频繁项集的产生 |
|
||||||||||||||||||||||||||||||||||||||||||
| 规则的产生方法 |
|
||||||||||||||||||||||||||||||||||||||||||
| 影响apiori算法计算复杂度的因素 |
|
||||||||||||||||||||||||||||||||||||||||||
| 频繁项集的压缩表示 |
|
||||||||||||||||||||||||||||||||||||||||||
| 关联模式评估 |
|

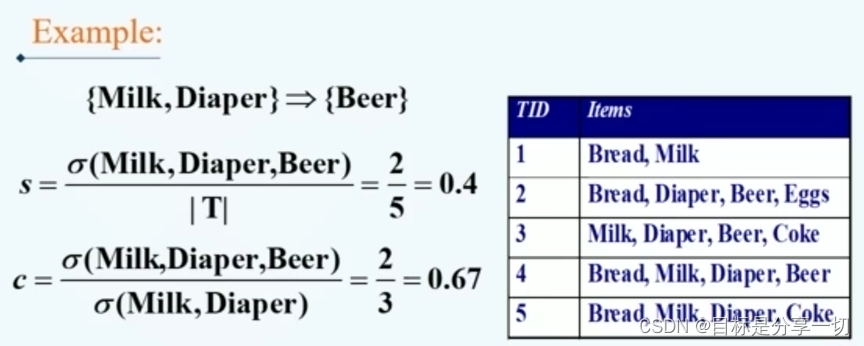




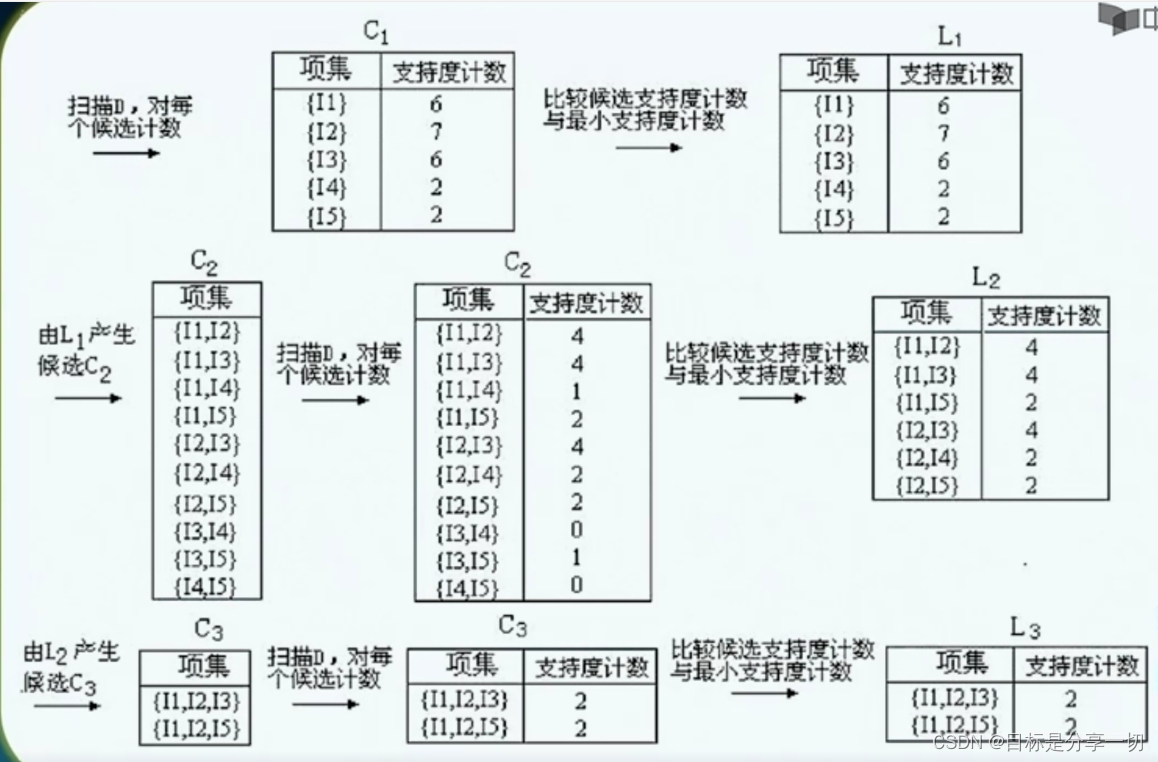
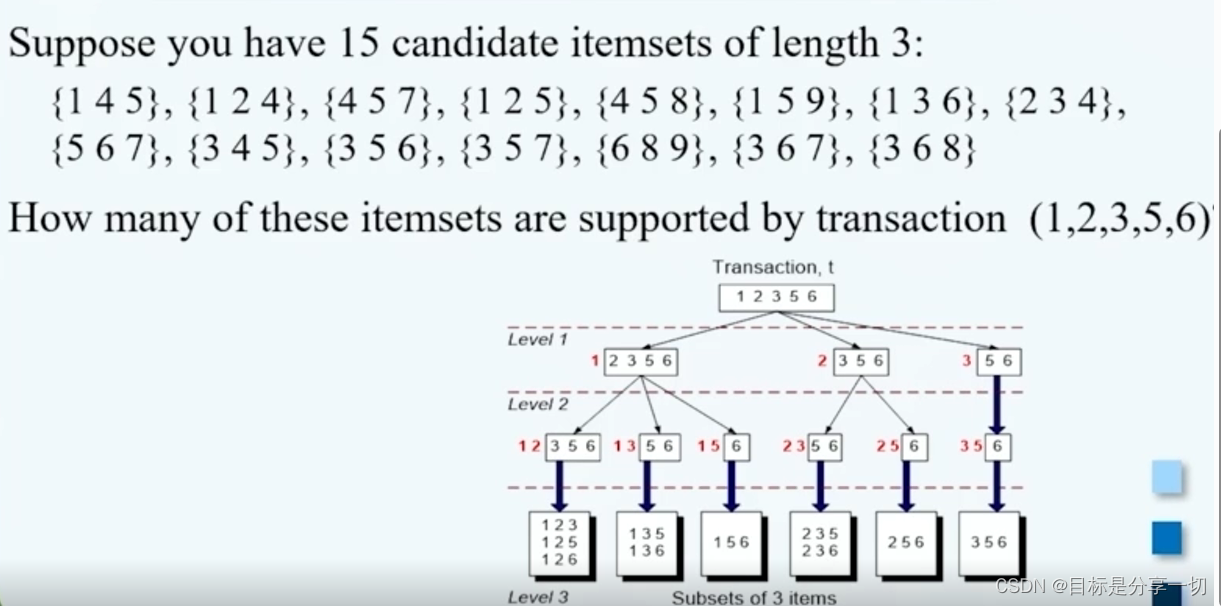



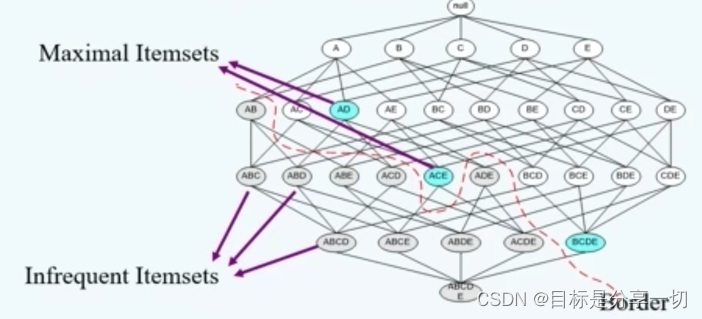
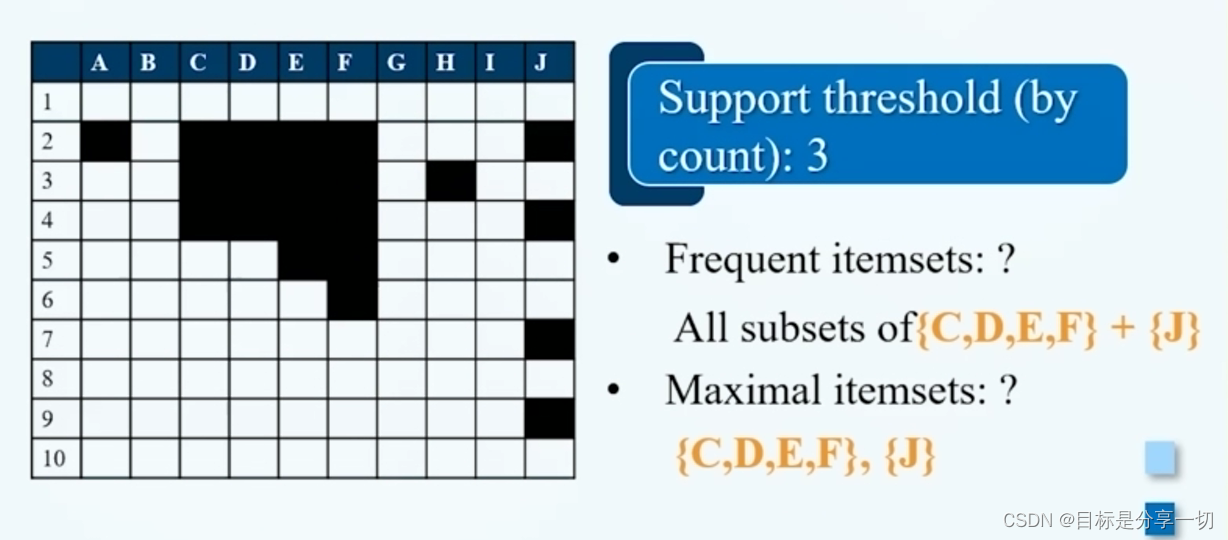
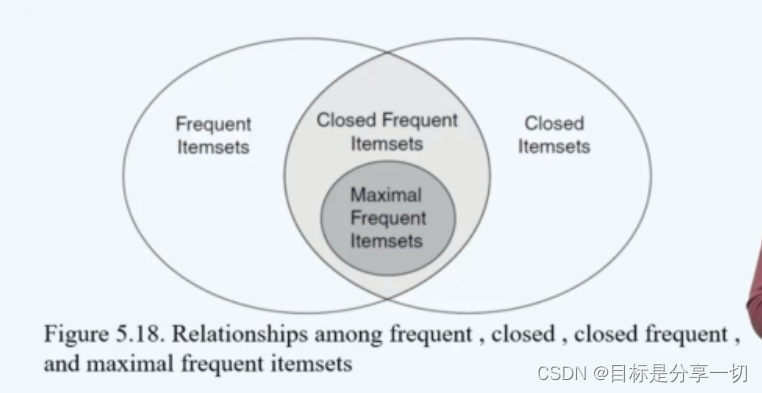



mooc题目
| 单选 (2分) 考虑下面的频繁3-项集的集合:1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}假定数据集中只有5个项,采用合并策略,由候选产生过程得到4-项集不包含 ()【题目有问题】 A.1,2,3,5 B.1,3,4,5 C.1,2,4,5 D.1,2,3,4 |
|
||||||||
| A.5 B.4 C.7 D.6 单选 (2分) 设X={1,2,3]是频繁项集,则可由X产生()个关联规则 |
2^n-2 |
||||||||
| 多选(2分)Apriori算法的计算复杂度受 () 影响 |
A.事务平均宽度 B.项数(维度) C.支持度阈值 D.事务数 |
||||||||
| 非频繁模式() |
非频繁模式是支持度<阈值的项集或规则 对异常数据项敏感 其支持度小于阈值 |
||||||||
|
|
|
||||||||
| |
|
||||||||
| 关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。x |
频繁项集vs关联规则挖掘
|
||||||||
| 具有较高的支持度的项集具有较高的置信度。x |
Support(支持度):表示某个项集出现的频率,也就是包含该项集的交易数与总交易数的比例。例如P(A)=表示项集A的比例,P(A∪B)=P(A∪B)表示项集A和项集B同时出现的比例。 Confidence(置信度):表示当A项出现时B项同时出现的频率,记作{A→B}。换言之,置信度指同时包含A项和B项的交易数与包含A项的交易数之比。公式表达:{A→B}的置信度=P(B∣A)=P(A∩B)/P(A) |
||||||||
| 如果一个项集是频繁的,那包含它的所有项集也是频繁的。x |
|

