一.前言
v-mAP的求法是参考了《Action Tubelet Detector for Spatio-Temporal Action Localization》中的求法,但这篇文章是基于caffe框架的,我熟悉的是pytorch,最终看到了一篇相近动作检测的文章,里面也是用了这篇文章的方法。代码的下载地址放在下边:
先说一下数据的走向。输入模型的数据为[b_s,tb,c,h,w],例如:(8,2,3,300,300)就表示有抽取了8帧图片,2表示(当前帧和下一帧的图像数据),3表示三通道(rgb),剩下两维是宽和高。也就是输入模型的有当前帧数据还有下一帧的数据。
1.模型输出
模型是ACT-VGG16,它的输出为三个部分:
1.预测的bbox坐标信息:例如:[8,8116,2,4]-----8:表示抽取的8帧图像,8116:表示一帧图像预测了8116个bbox,2:表示当前帧和下一帧,4:表示预测的box的坐标。也就是说对于每一帧的图像不仅预测了当前帧的bbox而且还预测了下一帧的bbox。
2.预测的每一个bbox各分类的分数:[8,8116,22]-----22:表示有22类,21类+1类背景
3.对预测的bbox进行的误差修正:[8116,4]
2.如何生成tubes?
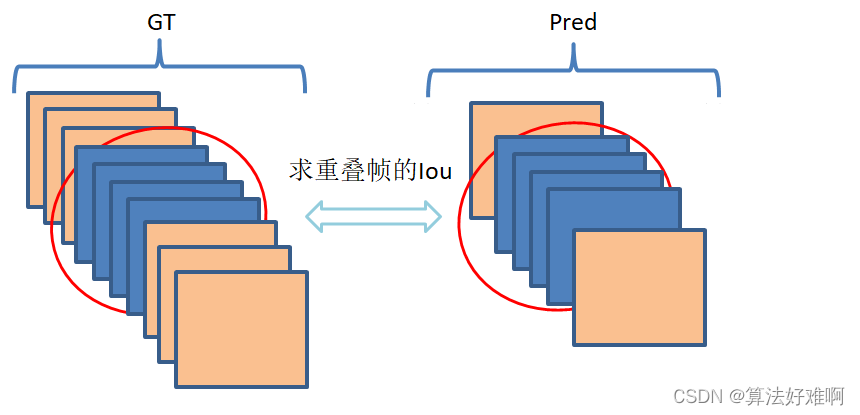
先解释一下什么是tubes,通俗的理解为动作序列。如下图1中:
假设:这是jhmdb数据集中的一个动作所持续的帧数,那么其标注文件是对其每一帧进行了标注,标注了动作的范围(bbox)。如图中的绿色框所示。那么把40帧的同一动作的bbox连起来看就是tubes。
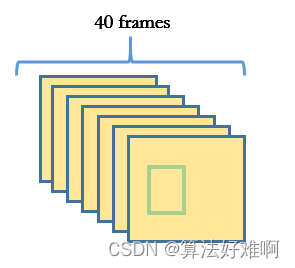
图1
上面介绍了tubes是什么。图1显示的是GT(标注)的tubes,而我们需要预测的tubes让两个tubes越接近越好。那怎么通过预测的bbox来得到tubes呢?简略说一下就是先通过nms滤除一部分的bbox,然后通过首帧找下一帧中iou最大的作为tubes的下一帧,最后知道tubes的生成。详细的生成过程通过下一篇文章讲解中提到《TubeR: Tubelet Transformer for Video Action Detection 》。最后整个tubes的数据情况如下:
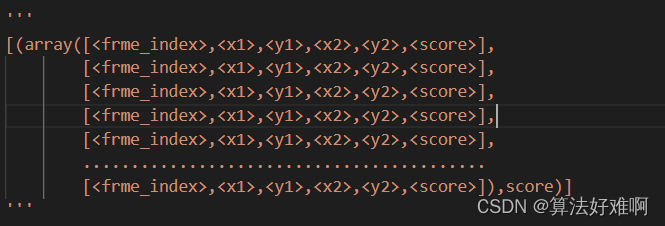
值得注意的是x1,y1,x2,y2后面跟了score,这个代表每一个box的score,而整个tubes后面也跟了一个score,这个表明的是tubes的score,具体是由构成tubes的box的scores求均值得到。
此时可能有小伙伴有疑问,模型输出的一帧预测了当前帧和下一帧的box,也就是除了第一帧和最后一帧,其他的都有两个预测的结果,到底要取哪一个?这里对两个结果的帧的box求均值,作为该帧数的最终的box的坐标,score也是同样的。

最终我们得到了预测的tubes,如图二中红色的box所示。
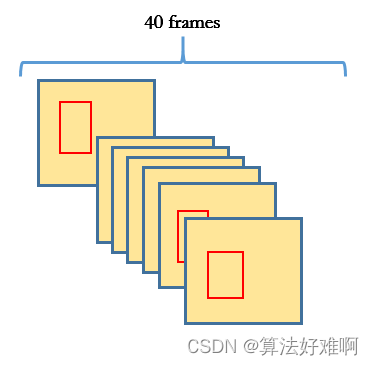
图2
video-mAP的指标实际上也是针对tubes的。在求video-mAP之前也要知道iou3d怎么求。2d的iou我们可能都会求,3d的其实也差不多。
二.Iou3dt的计算方法:
下面就是iou3dt的代码,每一行都注释了,本质也就是:求两个tubes重合部分的iou3d。输入是两个tubes,输出是一个值(表示两个tubes的相似程度)
def iou3dt(b1, b2, spatialonly=False):
"""Compute the spatio-temporal IoU between two tubes"""
#====计算预测的tubes和GT-tubes重合的帧数=========
tmin = max(b1[0, 0], b2[0, 0])
tmax = min(b1[-1, 0], b2[-1, 0])
if tmax < tmin: return 0.0
#====计算两个tubes帧数的交集================
temporal_inter = tmax - tmin + 1
#====计算两个tubes帧数的并集================
temporal_union = max(b1[-1, 0], b2[-1, 0]) - min(b1[0, 0], b2[0, 0]) + 1
#====分别取出两个tubes交集的帧==============
tube1 = b1[int(np.where(b1[:, 0] == tmin)[0]) : int(np.where(b1[:, 0] == tmax)[0]) + 1, :]
tube2 = b2[int(np.where(b2[:, 0] == tmin)[0]) : int(np.where(b2[:, 0] == tmax)[0]) + 1, :]
#=====求重合部分的iou3d,再乘上一个交并系数===========
return iou3d(tube1, tube2) * (1. if spatialonly else temporal_inter / temporal_union)下面是iou3d部分的代码,本质:所有box对应的iou求均值,iou3d的输入是两个tubes,输出是一个值。
def iou3d(b1, b2):
"""Compute the IoU between two tubes with same temporal extent"""
assert b1.shape[0] == b2.shape[0]
assert np.all(b1[:, 0] == b2[:, 0])
#求对应box的交集
ov = overlap2d(b1[:,1:5],b2[:,1:5])
#对所有box的iou取平均值
return np.mean(ov / (area2d(b1[:, 1:5]) + area2d(b2[:, 1:5]) - ov) )三.video-mAP的计算方法:
和f-mAP相似的是,要求mAP,首先要求AP,而AP是针对某一分类而言的。
所以对与某一分类:
我们先把预测的属于这一类的tubes取出来,再把属于这一类的tubes取出来,并且每个视频与视频对应上。其中对于precision和recall声明了一个总的数组pr,第一列存放precision,第二列存放recall。 值得注意的是,这里面多添加了一行,即:首行的precision=1,recall为0,这是为了后面计算曲线与坐标轴围成的面积,而做的准备。上面的文章也讲到了不存在fn和tn的区分。这里的fn其实就是GT的个数,是为了下面求recall。
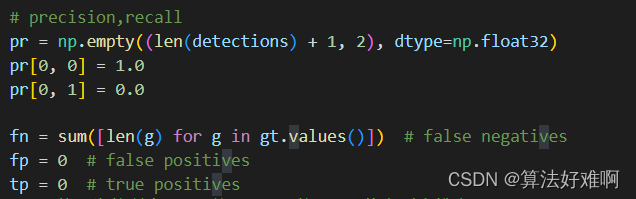
按照从小到大的顺序给预测的tubes排序。并和GT-tubes求Iou3dt大于我们设置的阈值就记为TP.
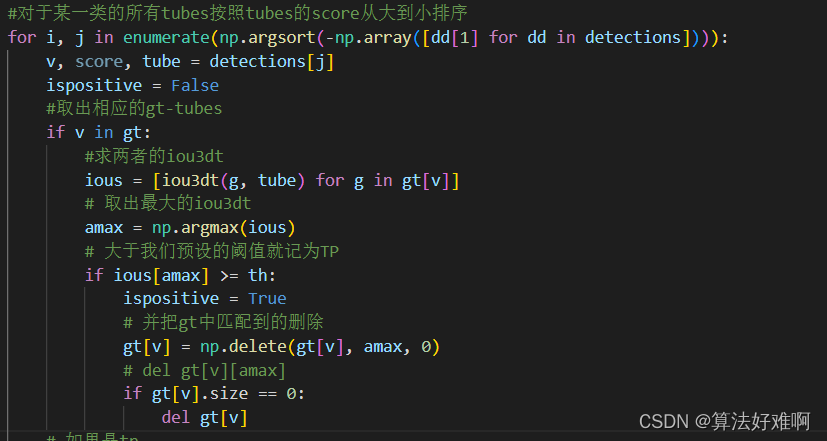
所有的tp和fp加起来其实就是预测的tubes的数目,而tp加fn总和加起来就是sum(gt),也就是gt的数目。这里只是求了一个类别的precision和recall,把所有的class的视频,按照上面的步骤,就能得到所有的类别的precision和recall。
AP的求法就是求precision和recall曲线与坐标轴围成的面积,这里求面积和所有点插值法有些不同,所有点插值法的高是由小区间内最大的precision来确定的,而这里是由区间两端的precision的均值来确定的。本质也是求曲线围成的面积。

把所有类的AP求均值,就是video-mAP,至此video-mAP讲解结束。不难发现和2d的AP求法一模一样,只是求iou时有那么一点的差别。
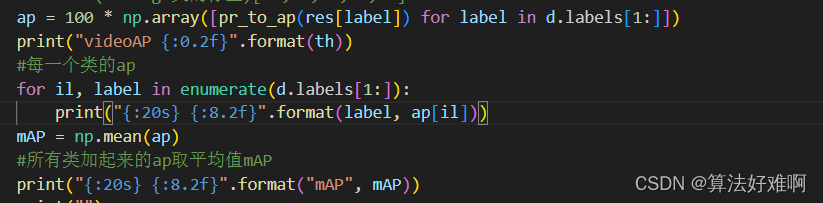
求video-mAP的本质:实际上就是衡量两个video片段中动作范围的相似性。