话在前头:
- 编译软件:python
- 如果与下方数据要求不同,可以联系我有偿修改代码。
- 处理数据:医学dicom文件患者姓名及医院信息匿名化
- 匿名:医院名称统一为“None”,患者姓名统一“序号_rename.nii.gz”
- dicom文件必须在所要批处理的三级目录下
- 含有患者信息的表格必须是xlsx格式的
- 批处理的文件夹名称必须是:123456_刘三,患者姓名前是“_”且后面无其他名称
话在前头(写给计算机学生的编程思路):
- 在含有患者“姓名”列的前面加入“ID”列,将每个“姓名”及其对应的“ID”存为字典
- 以文件夹名中“_”为分割符,将患者姓名分出来,并与上一步的字典匹配,获取对应的“ID”名。
- 遍历三级文件夹,利用pydicom库对其dicom文件进行匿名化,医院名称直接改为“None”,患者姓名改为对应的“ID”
目录
前言
在医学数据处理过程中,尤其是将自己医院的数据给他人进行处理时,大多医生都较为关注患者及医院信息泄露问题。以CT数据为例,一个CT下可能有多个dicom文件,而医生一个个对齐进行重命名显然不现实,但本文可实现对dicom信息的批量匿名化处理。
所需文件
-
批处理的文件夹,如下图

该文件夹下的子文件夹,如下图
ABCDE文件夹下存有dicom文件,如下图
-
名为“样本.xlsx”文件,里面姓名列与批处理的文件夹的患者姓名相对应

匿名化代码
代码名称:dicom文件匿名化.py
from pandas import read_excel
from pandas import notnull
import os
from time import time
from tqdm import tqdm # 导入tqdm库
import argparse
from pydicom import dcmread
def New_ID(xlsx_file_path1, xlsx_file_path_save1):
df = read_excel(xlsx_file_path1)
# 假设姓名列的名称为 "姓名"
name_column = "姓名" # 替换为实际的姓名列名
# 新建ID列并根据顺序填充值
df.insert(0, "ID", "") # 在第一列插入ID列,初始为空字符串
id_counter = -1
for index, row in df.iterrows():
name_value = row[name_column]
if notnull(name_value): # 只填充有姓名信息的行
id_counter += 1
id_value = f"{
id_counter}_rename.nii.gz"
df.at[index, "ID"] = id_value
# 将修改后的DataFrame写回xlsx文件
df.to_excel(xlsx_file_path_save1, index=False)
return df # 返回修改后的DataFrame
def create_dict(file_path):
df = read_excel(file_path)
# 选择ID和姓名列
id_column = "ID"
name_column = "姓名"
# 构建字典
id_name_dict = {
}
for index, row in df.iterrows():
name_value = row[name_column]
id_value = row[id_column]
id_name_dict[name_value] = id_value
return id_name_dict
def folder_rename_name(folder_path, name_mapping):
n_count = 0 # 记录运行到第几个文件夹了
# 使用tqdm来遍历文件夹并显示进度条
for folder_name in tqdm(os.listdir(folder_path), desc="运行进度"):
# 记录开始时间
start_time = time()
old_folder_path = os.path.join(folder_path, folder_name)
if os.path.isdir(old_folder_path):
parts = folder_name.split("_")
if len(parts) >= 2:
name_part = parts[1]
if name_part in name_mapping:
new_name = name_mapping[name_part]
new_name = str(new_name)
# 遍历下一级文件夹 修改患者姓名及医院名称
for subfolder_name in os.listdir(old_folder_path):
subfolder_path = os.path.join(old_folder_path, subfolder_name)
if os.path.isdir(subfolder_path):
# 遍历下一级文件夹内的所有文件
for item in os.listdir(subfolder_path):
item_path = os.path.join(subfolder_path, item)
if os.path.isfile(item_path) and item.endswith(".dcm"):
ds = dcmread(item_path) # 读取dicom文件
ds.PatientName = new_name
ds.InstitutionName = 'None'
ds.save_as(item_path) # 将修改后的文件保存
# 重命名文件夹名称
new_folder_path = os.path.join(folder_path, new_name)
os.rename(old_folder_path, new_folder_path)
else:
print(f"未找到匹配的映射: {
name_part}")
else:
print(f"文件夹名称格式不符合预期: {
folder_name}")
# 记录结束时间
end_time = time()
elapsed_time = end_time - start_time
print(f"总运行时间: {
elapsed_time:.2f} 秒")
def parse_arguments():
parser = argparse.ArgumentParser(description="本程序将dicom中的患者姓名及医院名称匿名化")
parser.add_argument("--XFP", required=True, help="数据的xlsx文件路径:C:\患者信息.xlsx")
parser.add_argument("--XFPS", required=True, help="xlsx文件另存路径(xlsx文件名自定义):C:\患者信息加入ID列.xlsx")
parser.add_argument("--FP", required=True, help="匿名化的文件夹路径(dicom文件必须在第三级目录上)")
return parser.parse_args()
def main():
args = parse_arguments()
xfp_path = args.XFP
xfps_path = args.XFPS
folder_path = args.FP
df = New_ID(xfp_path, xfps_path)
name_mapping = create_dict(xfps_path)
folder_rename_name(folder_path, name_mapping)
if __name__ == "__main__":
main()
为便于封装exe文件,所以使用parser.add_argument进行传参。如果想直接使用pycharm运行,直接将def main()函数下的xfp_path、xfps_path、 folder_path改为自己的文件路径。(路径格式:r"C:\患者信息")。
匿名化代码封装为exe
exe封装文件:链接:https://pan.baidu.com/s/1SizeulyDmefT57MZymM_lQ?pwd=1234 提取码:1234
在pycharm命令行中使用:pyinstaller -F --collect-submodules=pydicom dicom文件匿名化.py 对py文件打包。
打包后将exe程序拖入CMD命令终端中,在后面加入“ -h”,输出帮助信息,如下图
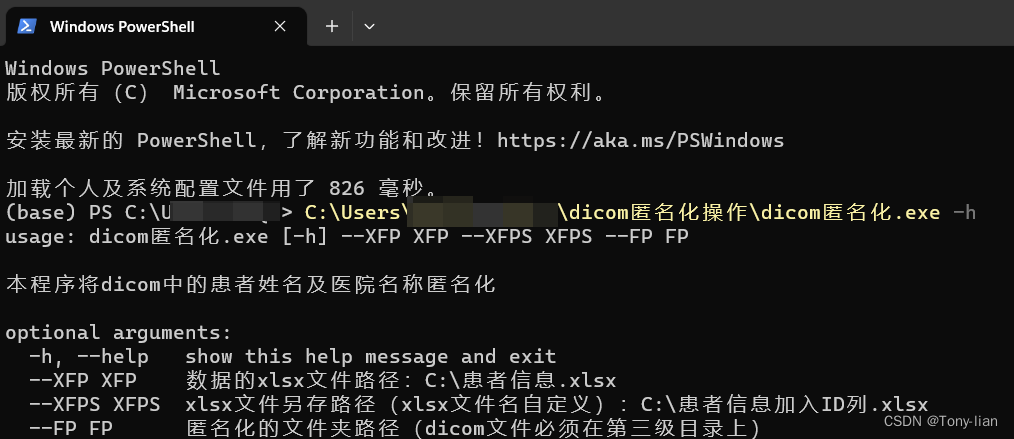
运行exe文件,对dicom文件批量匿名化

话在后头
现在存在的问题:
- 不能个性化的满足每个人的需求,需要有代码经验的人对代码进行更改
- 打包的exe文件有些大(400多MB),希望有能很好压缩exe文件的思路及代码帮助,拜谢。
- 如需要个性化定制自己代码,请在评论区留言。
如有帮助请支持一下博主:
