2023年,人工智能(AI)领域迎来了前所未有的飞速发展。随着技术的不断突破和革新,AI已经成为引领未来潮流的重要驱动力。在这篇文章中,深入研究了来自不同领域的十篇具有变革性的研究论文,涵盖了语言模型、图像处理、图像生成和视频编辑。随着对人工通用智能(AGI)的讨论揭示了AGI似乎比以往更易接近,一些特色论文探讨了通往AGI的各种路径,如扩展语言模型或利用强化学习进行跨领域的掌握。
以下是十篇推荐的研究论文:
2023年十篇具有影响力的人工智能研究论文
以下是十篇推荐的研究论文:
1.Microsoft的AGI火花
摘要
人工智能(AI)研究人员一直在开发和完善大型语言模型(LLMs),这些模型在各种领域和任务中展现出卓越的能力,挑战了人们对学习和认知的理解。最新的模型由OpenAI开发,名为GPT-4 [Ope23],经过前所未有的计算和数据规模的训练。在本文中,报告了对GPT-4早期版本的调查结果,当时它仍在OpenAI积极进行开发。研究人员认为,GPT-4(这个早期版本)是大型语言模型新队列的一部分,与ChatGPT和Google的PaLM等模型一样,表现出比先前的AI模型更为普适的智能。论文中讨论了这些模型不断增强的能力及其引起的影响。研究人员展示了除了GPT-4对语言的精通外,还能够在数学、编码、视觉、医学、法律、心理学等多个领域解决新颖且困难的任务,而无需任何特殊提示。值得注意的是,在所有这些任务中,GPT-4的性能与人类水平非常接近,往往远远超过了先前的模型,如ChatGPT。鉴于GPT-4广泛而深入的能力,研究人员认为它有理由被视为人工通用智能(AGI)系统的早期(尽管仍然不完整)版本。在对GPT-4的探索中,研究人员特别强调了发现其局限性的重要性,并讨论了前进迈向更深入和更全面的AGI版本所面临的挑战,其中可能需要追求超越下一个词预测的新范式。最后,研究人员对最近技术飞跃的社会影响和未来研究方向进行了反思。

了解更多研究内容:
论文标题:Sparks of Artificial General Intelligence: Early experiments with GPT-4
论文地址:https://arxiv.org/abs/2303.12712
论文实验演讲:https://www.youtube.com/watch?v=qbIk7-JPB2c
获取实现代码:
无
2.Google发布的PALM-E
摘要
大型语言模型已经证明能够执行复杂的任务。然而,在实际世界中实现通用推理,例如解决机器人问题,会带来基于实际情况的挑战,即搭建联系的问题。为此,研究人员提出了具有具体体现的语言模型,直接将实际世界中的连续传感器模态纳入语言模型,从而建立单词与感知之间的联系。我们提出的具体体现语言模型的输入是多模态句子,这些句子交织了视觉、连续状态估计和文本输入编码。我们将这些编码与预训练的大型语言模型一起进行端到端的训练,用于多个具体体现任务,包括顺序机器人操作规划、视觉问答和字幕生成。我们的评估表明,PaLM-E,一个单一的大型具体体现多模态模型,能够解决各种具体体现推理任务,涉及多个观测模态,适用于多个具体体现,并且还表现出积极的迁移:该模型受益于跨互联网规模的语言、视觉和视觉语言领域的多样化联合训练。我们的最大模型,PaLM-E-562B,具有562B个参数,除了在机器人任务上进行训练外,还是一种视觉语言通用模型,在OK-VQA上表现出色,并随着规模的增加保留了通用的语言能力。

了解更多研究内容
论文标题:PaLM-E: An Embodied Multimodal Language Model
论文地址:https://arxiv.org/abs/2303.03378
论文演示:https://palm-e.github.io/#demo
博客文章:https://blog.research.google/2023/03/palm-e-embodied-multimodal-language.html
获取实现代码的位置
PaLM-E模型的代码实现目前不可用。
3.Meta AI发布的LLaMA 2
摘要
在这项工作中,研究人员开发并发布了Llama 2,这是一组预训练和微调的大型语言模型(LLMs),其规模从70亿到700亿个参数不等。我们的微调LLMs,称为Llama 2-Chat,经过优化以适用于对话使用场景。我们的模型在我们测试的大多数基准测试中胜过开源对话模型,并根据我们的人工评估,就帮助性和安全性而言,可能是封闭源模型的合适替代品。我们详细描述了我们微调和提升Llama 2-Chat安全性的方法,以便让社区能够在我们的工作基础上进行建设,并为LLMs的负责任发展做出贡献。
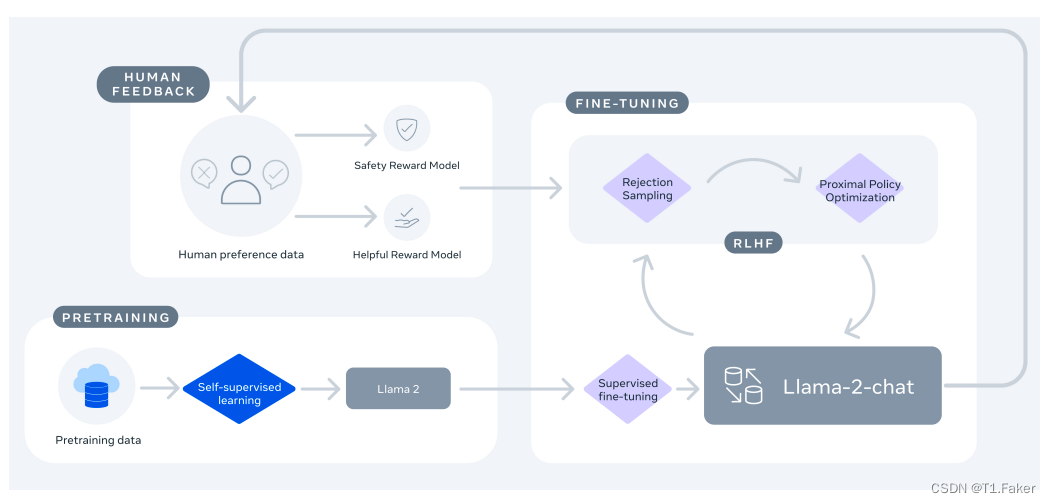
了解更多研究内容
论文标题:Llama 2: Open Foundation and Fine-Tuned Chat Models
论文地址:https://arxiv.org/abs/2307.09288
博客文章:Llama 2: open source, free for research and commercial use
获取实现代码的位置
Meta AI向所有规模的个人、创作者、研究人员和企业发布了LLaMA 2模型,
地址:https://github.com/facebookresearch/llama
4.威斯康辛大学、Microsoft和哥伦比亚大学发布的LLaVA
摘要
在使用机器生成的指令跟随数据对大型语言模型(LLMs)进行指令调整已被证明可以提高对新任务的零炮击能力,但这个想法在多模态领域中探索得较少。作者呈现了首次尝试使用仅依靠语言的GPT-4生成多模态语言-图像指令跟随数据。通过在这种生成的数据上进行指令调整,作者引入了LLaVA:Large Language and Vision Assistant,这是一个端到端训练的大型多模态模型,连接了一个视觉编码器和一个LLM,用于通用的视觉和语言理解。为了促进未来关于视觉指令跟随的研究,作者构建了两个具有多样化和具有挑战性的应用导向任务的评估基准。作者的实验证明,LLaVA展示出令人印象深刻的多模态聊天能力,有时展现出对未见过的图像/指令的多模态GPT-4的行为,并在合成的多模态指令跟随数据集上相对于GPT-4获得了85.1%的相对分数。当在Science QA上进行微调时,LLaVA和GPT-4的协同作用实现了92.53%的新的最高准确度。作者公开了GPT-4生成的视觉指令调整数据、作者的模型和代码。

了解更多研究内容
论文标题:Visual Instruction Tuning
论文地址:https://arxiv.org/abs/2304.08485
博客文章:https://llava-vl.github.io/
获取实现代码的位置
LLaVA的代码实现可在GitHub上获得
地址:https://github.com/haotian-liu/LLaVA
5.斯坦福大学和谷歌发布的Generative Agents
摘要
可信的人类行为代理可以赋予互动应用程序强大的能力,涵盖从沉浸式环境到人际交往排练空间再到原型工具的各个领域。本文介绍了生成型代理:计算软件代理,模拟可信的人类行为。生成型代理会起床,做早餐,上班;艺术家绘画,作家写作;它们形成观点,注意彼此,并开始对话;它们记得和反思过去的日子,同时规划着下一天的生活。为了实现生成型代理,我们描述了一种架构,扩展了大型语言模型,以自然语言存储代理的完整经验记录,随着时间的推移将这些记忆合成为更高层次的反思,并动态检索它们以规划行为。我们通过实例化生成型代理来填充一个受《模拟人生》启发的交互式沙盒环境,最终用户可以使用自然语言与二十五个代理在一个小镇上进行互动。在评估中,这些生成型代理产生可信的个体和新兴社会行为。例如,仅从单一用户指定的一个代理想要举办情人节派对的概念开始,代理们在接下来的两天里自主传播了派对的邀请,结识了新朋友,相约在合适的时间一起出现在派对上。我们通过剔除试验证明我们代理架构的组件——观察、规划和反思——每个都对代理行为的可信度起到至关重要的作用。通过将大型语言模型与计算交互代理融合,这项工作引入了用于实现人类行为可信模拟的架构和交互模式。

了解更多研究内容
论文标题:Generative Agents: Interactive Simulacra of Human Behavior
论文地址:https://arxiv.org/abs/2304.03442
演示视频(由论文第一作者Joon Sung Park演示的研究视频):https://youtu.be/nKCJ3BMUy1s?si=90md6r40oXbdrA8g
获取实现代码的位置
Github:https://github.com/joonspk-research/generative_agents
6.Meta AI发布的Segment Anything
摘要
Segment Anything (SA) 项目介绍了一项新的图像分割任务、模型和数据集。通过在数据收集循环中使用我们高效的模型,我们构建了迄今为止最大的分割数据集(远远超过其他),其中包括超过10,000万张经过许可并尊重隐私的图像上的10亿多个蒙版。该模型经过设计和训练,可以根据提示进行操作,因此可以零样本迁移到新的图像分布和任务。我们在许多任务上评估了其能力,并发现其零样本性能令人印象深刻,往往与先前的完全监督结果相竞争甚至更为优越。我们正在发布Segment Anything Model(SAM)和相应的数据集(SA-1B),其中包括10亿个蒙版和1100万张图像,以促进对计算机视觉基础模型的研究。有关详细信息,请访问 https://segment-anything.com。
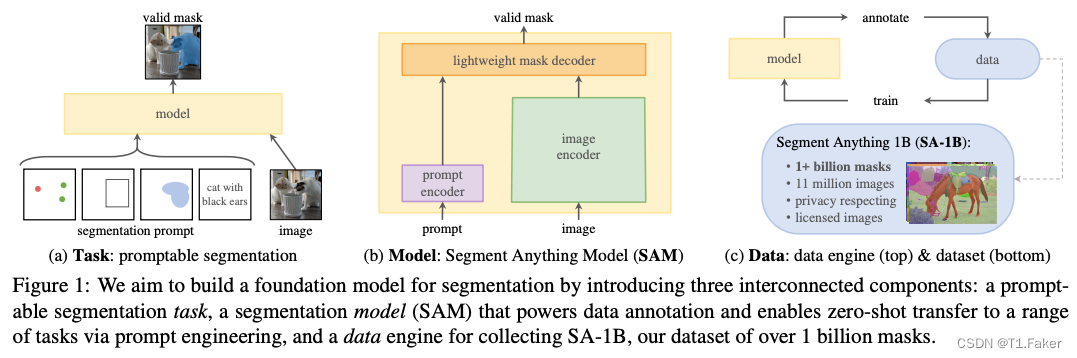
了解更多研究内容
论文标题:Segment Anything
论文地址:https://arxiv.org/abs/2304.02643
演示、数据集:https://segment-anything.com/
获取实现代码的位置
Segment Anything Model(SAM)和相应的数据集(SA-1B),包含10亿个掩码和1100万张图像,已发布
地址:https://github.com/facebookresearch/segment-anything
7.OpenAI发布的DALL-E 3
摘要

了解更多研究内容
论文标题:Improving Image Generation with Better Captions
论文地址:https://cdn.openai.com/papers/dall-e-3.pdf
博客文章:https://openai.com/dall-e-3
获取实现代码的位置
DALL-E 3的代码实现目前不可用,但作者发布了用于评估DALL-E与竞争对手的文本到图像样本集。
地址:https://github.com/openai/dalle3-eval-samples
8.斯坦福大学发布的ControlNet
摘要
ControlNet被提出作为一种神经网络架构,用于向大型、预训练的文本到图像扩散模型添加空间调节控制。ControlNet锁定了生产就绪的大型扩散模型,并重复使用它们经过数十亿图像预训练的深层且强大的编码层作为强有力的支持,以学习多样的条件控制。神经架构与“零卷积”(零初始化卷积层)相连,逐渐从零增长参数,确保不会有有害噪音影响微调过程。我们测试了各种调节控制,例如边缘、深度、分割、人体姿势等,使用Stable Diffusion,单个或多个条件,带有或没有提示。我们展示了ControlNet在小型(<50k)和大型(>1m)数据集上的稳健性培训。广泛的结果表明,ControlNet可能有助于更广泛的应用,以控制图像扩散模型。

了解更多研究内容
论文标题:Adding Conditional Control to Text-to-Image Diffusion Models
论文地址:https://arxiv.org/abs/2302.05543
博客文章:https://github.com/lllyasviel/ControlNet/discussions/188
获取实现代码的位置
Github:https://github.com/lllyasviel/ControlNet
9.Runway发布的Gen-1
摘要
文本引导的生成扩散模型为强大的图像创建和编辑工具打开了新的可能性。虽然这些模型已经扩展到视频生成,但目前的方法在保留结构的同时编辑现有素材的内容需要为每个输入进行昂贵的重新训练,或者依赖于容易出错的在帧间传播图像编辑的方法。
在这项工作中,研究人员提出了一种基于视觉或文本描述编辑视频的结构和内容引导的视频扩散模型。由于两者之间的不足解耦,用户提供的内容编辑与结构表示之间存在冲突。作为解决方案,研究人员表明,使用具有不同详细级别的单眼深度估计进行训练可以实现对结构和内容保真度的控制。我们的模型同时在图像和视频上进行训练,通过一种新颖的引导方法还展现了对时间一致性的显式控制。我们的实验证明了多方面的成功:对输出特征的精细控制,基于少数参考图像的定制,以及用户对我们模型结果的强烈偏好。

了解更多研究内容
论文标题:Structure and Content-Guided Video Synthesis with Diffusion Models
论文地址:https://arxiv.org/abs/2302.03011
博客文章:https://research.runwayml.com/gen1,https://research.runwayml.com/gen2
获取实现代码的位置
Gen-1的代码实现目前不可用。
10.DeepMind 和多伦多大学发布的DreamerV3
摘要
一般智能要求解决许多领域的任务。当前的强化学习算法具有这一潜力,但受到为新任务调整它们所需的资源和知识的限制。研究人员提出了DreamerV3,这是一种基于世界模型的通用且可扩展的算法,相对于先前的方法在固定的超参数下在各种领域中表现更好。这些领域包括连续和离散动作、视觉和低维输入、2D和3D世界、不同的数据预算、奖励频率和奖励规模。我们观察到DreamerV3具有良好的扩展性,更大的模型直接转化为更高的数据效率和最终性能。在实际应用中,DreamerV3是第一个在Minecraft中从零开始收集钻石的算法,而无需使用人类数据或课程,这是人工智能中长期存在的挑战。我们的通用算法使强化学习广泛适用,并允许扩展到复杂的决策问题。

了解更多研究内容
论文标题:Mastering Diverse Domains through World Models
论文地址:https://arxiv.org/abs/2301.04104
项目地址:https://danijar.com/project/dreamerv3/
获取实现代码的位置
Github:https://github.com/danijar/dreamerv3