贝叶斯决策分类算法
一、实验目的
(1)熟悉朴素贝叶斯决策算法。
(2)对 AllElectronics 顾客数据库查询得到先验概率和类条件概率。
(3)在样本集上编写用朴素贝叶斯算法分类的程序,对任务相关数据运行朴素贝叶斯分类算法,调试实验。
(4)写出实验报告。
二、实验原理
1、先验概率和类条件概率
先验概率:先验概率定义为训练样本集中属于 C i C_i Ci类的样本(元组)数与总样本数 N i N_i Ni之比,记为 P ( C i ) = N i N P(C_i)=\frac{N_i}{N} P(Ci)=NNi。
类条件概率:类条件概率定义为训练样本集中属于 C i C_i Ci类中的具有特征 X X X的样本(元组)的个数 n i n_i ni与属于 C i C_i Ci类的样本(元组)数 N i N_i Ni之比,记为 P ( X ∣ C i ) = n i N i P(X|C_i)=\frac{n_i}{N_i} P(X∣Ci)=Nini。
2、贝叶斯决策
贝叶斯决策(分类)法将样本(元组)分到 C i C_i Ci类,当且仅当
P ( X ∣ C i ) P ( C i ) > P ( X ∣ C j ) P ( C j ) , 对 1 ≤ j ≤ m , j ≠ i P(X|C_i)P(C_i)>P(X|C_j)P(C_j), 对1\leq j\leq m, j\neq i P(X∣Ci)P(Ci)>P(X∣Cj)P(Cj),对1≤j≤m,j=i
其中,训练样本集中的样本(元组)可被分为 m m m类。
三、实验内容和步骤
1、实验内容
用贝叶斯分类器对已知的特征向量 X 分类:
- 由 AllElectronics 顾客数据库类标记的训练样本集(元组)编程计算先验
概率 P(Ci)和类条件概率 P(X|Ci),并在实验报告中指出关键代码的功能和实现方法; - 应用贝叶斯分类法编程对特征向量 X 分类,并在实验报告中指出关键程
序片段的功能和实现方法; - 用检验样本估计分类错误率;
- 在实验报告中画出程序或例程的程序框图。
2、实验步骤
由于该分类问题是决定顾客是否倾向于购买计算机,即C1对应于buys_computer=yes,C2对应于 buys_computer=no,是两类的分类问题。实验步骤如下:
- 确定特征属性及划分:浏览所给的数据库,找出划分的特征属性;
- 获取训练样本:即给定的 AllElectronics 顾客数据库类标记的训练样本集
(元组); - 计算训练样本中每个类别的先验概率:P(Ci),i=1,2;
- 计算训练样本中类条件概率:设特征(属性)向量为 X,编程计算类条
件概率 P(X|Ci),i=1,2; - 使用分类器进行分类;
3、程序框图
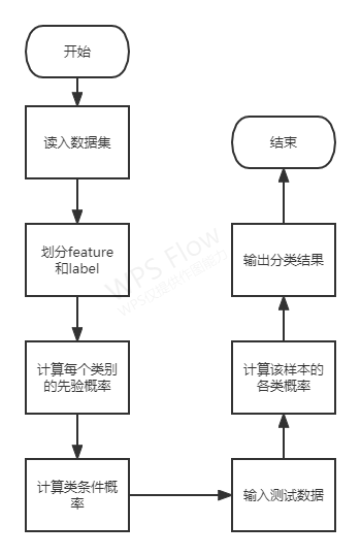
4、实验样本
data.txt

5、实验代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 #
# @Time : 2022/5/30 21:26
# @Author : Yang Haoyuan
# @Email : [email protected]
# @File : Exp4.py
# @Software: PyCharm
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
import argparse
parser = argparse.ArgumentParser(description='Exp4')
parser.add_argument('--mode', type=str, choices=["KFold", "train", "test"])
parser.add_argument('--k', type=int, default=7)
parser.add_argument('--AGE', type=str, choices=["youth", "middle_aged", "senior"])
parser.add_argument('--INCOME', type=str, choices=["high", "medium", "low"])
parser.add_argument('--STUDENT', type=str, choices=["yes", "no"])
parser.add_argument('--CREDIT', type=str, choices=["excellent", "fair"], default="fair")
parser.set_defaults(augment=True)
args = parser.parse_args()
print(args)
# 载入数据集
def loadDataset(filename):
dataSet = []
with open(filename, 'r') as file_to_read:
while True:
lines = file_to_read.readline() # 整行读取数据
if not lines:
break
p_tmp = [str(i) for i in lines.split(sep="\t")]
p_tmp[len(p_tmp) - 1] = p_tmp[len(p_tmp) - 1].strip("\n")
dataSet.append(p_tmp)
return pd.DataFrame(dataSet, columns=["AGE", "INCOME", "STUDENT", "CREDIT", "BUY"])
# 计算总样本数和各类数量
def count_total(data):
count = {
}
group_df = data.groupby(["BUY"])
count["yes"] = group_df.size()["yes"]
count["no"] = group_df.size()["no"]
total = count["yes"] + count["no"]
return count, total
# 计算各类概率
def cal_base_rates(categories, total):
rates = {
}
for label in categories:
priori_prob = categories[label] / total
rates[label] = priori_prob
return rates
# 计算各类条件概率
def f_prob(data, count):
likelihood = {
'yes': {
}, 'no': {
}}
# 根据AGE(youth, middle_aged, senior)和BUY(yes, no)统计概率
df_group = data.groupby(['AGE', 'BUY'])
try:
c = df_group.size()["youth", "yes"]
except:
c = 0
likelihood['yes']['youth'] = c / count['yes']
try:
c = df_group.size()["youth", "no"]
except:
c = 0
likelihood['no']['youth'] = c / count['no']
try:
c = df_group.size()["middle_aged", "yes"]
except:
c = 0
likelihood['yes']['middle_aged'] = c / count['yes']
try:
c = df_group.size()["middle_aged", "no"]
except:
c = 0
likelihood['no']['middle_aged'] = c / count['no']
try:
c = df_group.size()["senior", "yes"]
except:
c = 0
likelihood['yes']['senior'] = c / count['yes']
try:
c = df_group.size()["senior", "no"]
except:
c = 0
likelihood['no']['senior'] = c / count['no']
# 根据INCOME(high, medium, low)和BUY(yes, no)统计概率
df_group = data.groupby(['INCOME', 'BUY'])
try:
c = df_group.size()["high", "yes"]
except:
c = 0
likelihood['yes']['high'] = c / count['yes']
try:
c = df_group.size()["high", "no"]
except:
c = 0
likelihood['no']['high'] = c / count['no']
try:
c = df_group.size()["medium", "yes"]
except:
c = 0
likelihood['yes']['medium'] = c / count['yes']
try:
c = df_group.size()["medium", "no"]
except:
c = 0
likelihood['no']['medium'] = c / count['no']
try:
c = df_group.size()["low", "yes"]
except:
c = 0
likelihood['yes']['low'] = c / count['yes']
try:
c = df_group.size()["low", "no"]
except:
c = 0
likelihood['no']['low'] = c / count['no']
# 根据STUDENT(yes, no)和BUY(yes, no)统计概率
df_group = data.groupby(['STUDENT', 'BUY'])
try:
c = df_group.size()["yes", "yes"]
except:
c = 0
likelihood['yes']['yes'] = c / count['yes']
try:
c = df_group.size()["yes", "no"]
except:
c = 0
likelihood['no']['yes'] = c / count['no']
try:
c = df_group.size()["no", "yes"]
except:
c = 0
likelihood['yes']['no'] = c / count['yes']
try:
c = df_group.size()["no", "no"]
except:
c = 0
likelihood['no']['no'] = c / count['no']
# 根据CREDIT(excellent, fair)和BUY(yes, no)统计概率
df_group = data.groupby(['CREDIT', 'BUY'])
try:
c = df_group.size()["excellent", "yes"]
except:
c = 0
likelihood['yes']['excellent'] = c / count['yes']
try:
c = df_group.size()["excellent", "no"]
except:
c = 0
likelihood['no']['excellent'] = c / count['no']
try:
c = df_group.size()["fair", "yes"]
except:
c = 0
likelihood['yes']['fair'] = c / count['yes']
try:
c = df_group.size()["fair", "no"]
except:
c = 0
likelihood['no']['fair'] = c / count['no']
return likelihood
# 训练
def train(train_data):
# 获取各类数量和训练样本总数
count, total = count_total(train_data)
# 获取先验概率
priori_prob = cal_base_rates(count, total)
# 保存先验概率
np.save("priori_prob.npy", priori_prob)
# 获取各特征的条件概率
feature_prob = f_prob(train_data, count)
# 保存条件概率
np.save("feature_prob.npy", feature_prob)
print("训练完成")
# 分类器
def NaiveBayesClassifier(AGE=None, INCOME=None, STUDENT=None, CREDIT=None):
res = {
}
priori_prob = np.load('priori_prob.npy', allow_pickle=True).item()
feature_prob = np.load('feature_prob.npy', allow_pickle=True).item()
# 根据特征计算各类的概率
for label in ['yes', 'no']:
prob = priori_prob[label]
prob *= feature_prob[label][AGE] * feature_prob[label][INCOME] * feature_prob[label][STUDENT] \
* feature_prob[label][CREDIT]
res[label] = prob
print("预测概率:", res)
# 选择概率最高的类作为分类结果
res = sorted(res.items(), key=lambda kv: kv[1], reverse=True)
return res[0][0]
# 测试
def test(test_data):
correct = 0
for idx, row in test_data.iterrows():
prob = NaiveBayesClassifier(row["AGE"], row["INCOME"], row["STUDENT"], row["CREDIT"])
if prob == row["BUY"]:
correct = correct + 1
return correct / test_data.shape[0]
# 启用k-折交叉验证
def KFoldEnabled():
kf = KFold(n_splits=args.k)
data_set = loadDataset("date.txt")
corr = 0
for train_idx, test_idx in kf.split(data_set):
train_data = data_set.loc[train_idx]
test_data = data_set.loc[test_idx]
train(train_data)
corr = corr + test(test_data)
print("k折交叉验证正确率: ", corr / 7)
if __name__ == '__main__':
if args.mode == "KFold":
KFoldEnabled()
if args.mode == "train":
train_data = loadDataset("date.txt")
train(train_data)
if args.mode == "test":
'''priori_prob = np.load('priori_prob.npy', allow_pickle=True).item()
print("先验概率: ", priori_prob)
feature_prob = np.load('feature_prob.npy', allow_pickle=True).item()
print("类条件概率: ", feature_prob)'''
ret = NaiveBayesClassifier(args.AGE, args.INCOME, args.STUDENT, args.CREDIT)
print("预测结果: ", ret)
四、实验结果

采用k折交叉验证进行训练和测试,k=7

训练模型

模型预测
五、实验分析
本次实验主要实现朴素贝叶斯分类算法。
贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯方法的特点是结合先验概率和后验概率,即避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。
朴素贝叶斯算法(Naive Bayesian algorithm) 在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。
这增强了朴素贝叶斯分类的鲁棒性,但是实际上,其对于属性间互相独立的假设也限制了其分类的性能。
本实验数据中并没有区分训练集和验证集,为了验证朴素贝叶斯分类器在该数据集上的性能,我采用K折交叉验证算法。最后的分类正确率只有50%,我认为这可以归咎于数据集的数量过少,导致朴素贝叶斯分类器在该任务上没有充分训练。
我将训练的数据以.npy的文件保存下来,以便在应用分类的时候直接读取参数,进行分类。