文章目录
1 分组聚合
1.1数据聚合与分组
简单的累计方法可以让我们对数据集有一个笼统的认识,但是我们经常还需要对某些标签或索引的局部进行累计分析,这时就需要用到groupby 了。虽然“分组”(group by)这个名字是借用 SQL 数据库语言的命令,但其理念引用发明 R 语言 frame 的 Hadley Wickham 的观点可能更合适:分割(split)、应用(apply)和组合(combine)。
分割、应用和组合
一个经典分割 - 应用 - 组合操作,其中“apply”的 是一个求和函数。
下图清晰地描述了 GroupBy 的过程。 分割步骤将 DataFrame 按照指定的键分割成若干组。 应用步骤对每个组应用函数,通常是累计、转换或过滤函数。 组合步骤将每一组的结果合并成一个输出数组。
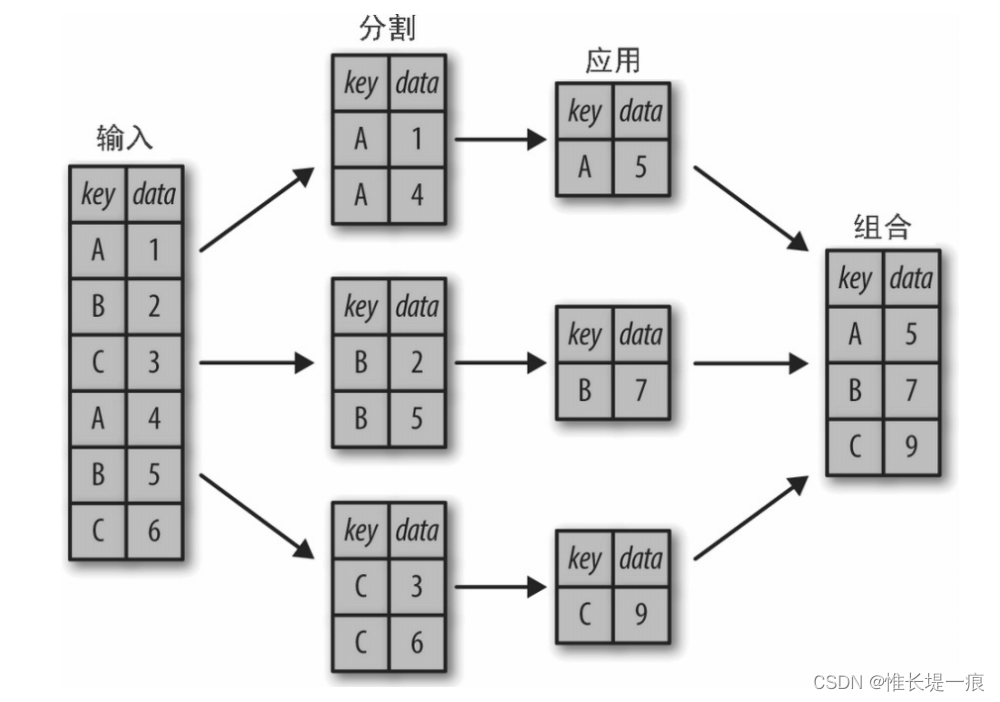
虽然我们也可以通过前面介绍的一系列的掩码、累计与合并操作来实现,但是意识到中间分割过程不需要显式地暴露出来这一点十分重要。而且 GroupBy(经常)只需要一行代码,就可以计算每组的和、均值、计数、最小值以及其他累计值。GroupBy 的用处就是将这些步骤进行抽象:用户不需要知道在底层如何计算,只要把操作看成一个整体就够了。
groupby:(by=None,as_index=True)
by:根据什么进行分组,用于确定groupby的组
as_index:对于聚合输出,返回以组便签为索引的对象,仅对DataFrame
df = pd.DataFrame(
{
'fruit': ['apple', 'banana', 'orange', 'apple', 'banana'], # 名称
'color': ['red', 'yellow', 'yellow', 'cyan', 'cyan'], # 颜色
'price': [8.5, 6.8, 5.6, 7.8, 6.4], # 单价
'count': [3, 4, 6, 5, 2]}) # 购买总量,单位/斤
df['total'] = df['price'] * df['count']
print(df)
输出:
fruit color price count total
0 apple red 8.5 3 25.5
1 banana yellow 6.8 4 27.2
2 orange yellow 5.6 6 33.6
3 apple cyan 7.8 5 39.0
4 banana cyan 6.4 2 12.8
需要注意的是,这里的返回值不是一个 DataFrame 对象,而是一 个 DataFrameGroupBy 对象。这个对象的魔力在于,你可以将它 看成是一种特殊形式的 DataFrame,里面隐藏着若干组数据,但是在没有应用累计函数之前不会计算。这种“延迟计算”(lazy evaluation)的方法使得大多数常见的累计操作可以通过一种对用户而言几乎是透明的(感觉操作仿佛不存在)方式非常高效地实现。
为了得到这个结果,可以对 DataFrameGroupBy 对象应用累计函数,它会完成相应的应用 / 组合步骤并生成结果:
print(df.groupby('fruit').sum())
"""
price
fruit
apple 16.3
banana 13.2
orange 5.6
"""
sum() 只是众多可用方法中的一个。你可以用 Pandas 或 NumPy 的任意一种累计函数,也可以用任意有效的 DataFrame 对象。
GroupBy对象
GroupBy 中最重要的操作可能就是 aggregate、filter、transform 和 apply(累计、过滤、转换、应用)了,后文将详细介绍这些内 容,现在先来介绍一些 GroupBy 的基本操作方法。
(1) 按列取值。GroupBy 对象与 DataFrame 一样,也支持按列取 值,并返回一个修改过的 GroupBy 对象,例如:
import pandas as pd
df = pd.DataFrame({
'fruit': ['apple', 'banana', 'orange', 'apple', 'banana'],
'color': ['red', 'yellow', 'yellow', 'cyan', 'cyan'],
'price': [8.5, 6.8, 5.6, 7.8, 6.4],
'count': [3, 4, 6, 5, 2]})
df['total'] = df['price'] * df['count']
# 查看类型
print(df.groupby('fruit'))
print(df.groupby('fruit').sum())
"""group 对象"""
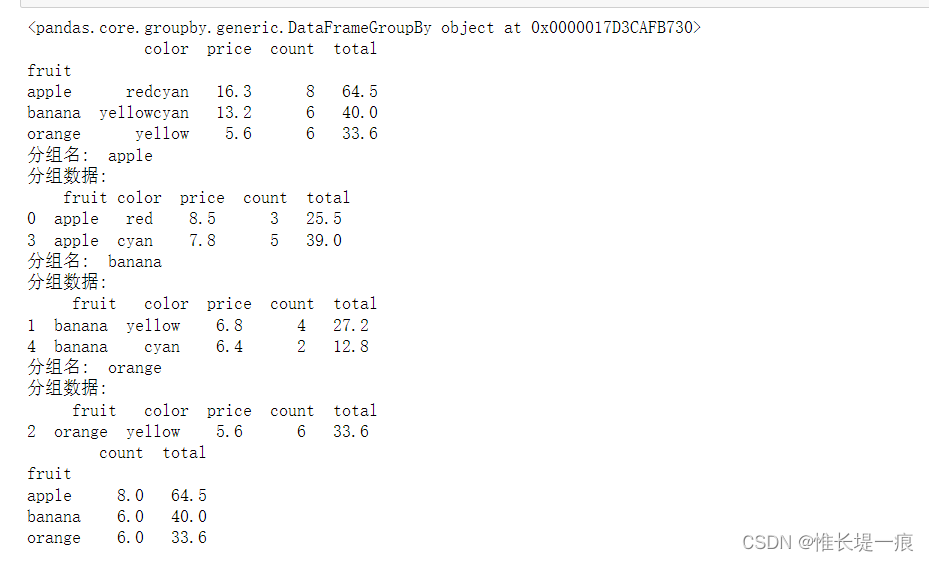
for name, group in df.groupby('fruit'):
print('分组名:\t', name) # 输出组名
print('分组数据:\n', group) # 输出数据块
# 对数量与总价
print(df.groupby('fruit')[['count', 'total']].apply(lambda x: x.sum()))
 聚合(agg)
聚合(agg)
| 函数名 | 描述 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非NA的最小值,最大值 |
| prod | 非NA值的乘积 |
| first, last | 非NA值的第一个,最后一个 |
| 例如: |
import numpy as np
# 多分组数据进行多个运算
print(df.groupby('fruit').aggregate({
'price': 'min', 'count': 'max'}))
"""
如果我现在有个需求,计算每种水果最高价和最低价的差值,
1.上表中的聚合函数不能满足于我们的需求,我们需要使用自定义的聚合函数
2.在分组对象中,使用我们自定义的聚合函数
"""
# 定义一个计算差值的函数
def diff_value(arr):
return arr.max() - arr.min()
print(df.groupby('fruit')['price'].agg(diff_value))
price count
fruit
apple 7.8 5
banana 6.4 4
orange 5.6 6
fruit
apple 0.7
banana 0.4
orange 0.0
Name: price, dtype: float64
过滤(filter)
"""分组后我们也可以对数据进行过滤<自定义规则过滤>"""
def filter_func(x):
print('price:\t', [x['price']])
print('price:\t', type(x['price']))
print('price:\t', x['price'].mean())
return x['price'].mean() > 6 # 过滤平均价格大于6
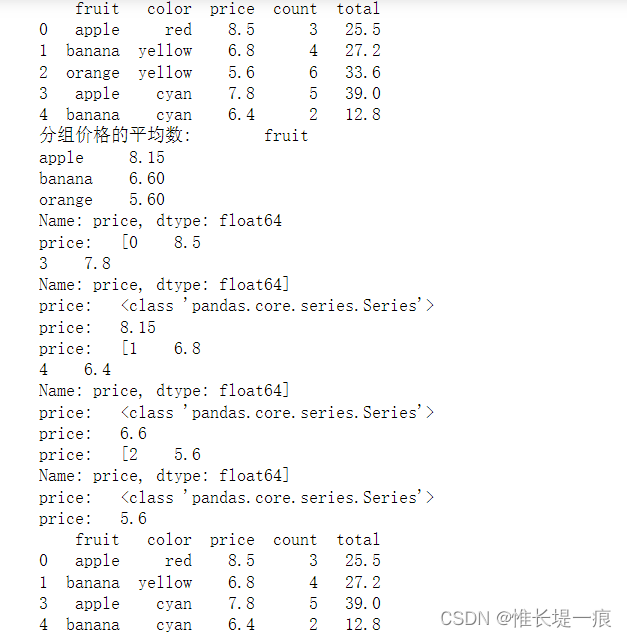
print(df)
print('分组价格的平均数: \t', df.groupby('fruit')['price'].mean())
# 分组之后进行过滤,不影响原本的数据
print(df.groupby('fruit').filter(filter_func))
1.2数据合并
1.2.1 pd.merge数据合并
-
根据单个或多个键将不同DataFrame的行连接起来
-
类似数据库的连接操作
-
pd.merge:(left, right, how=‘inner’,on=None,left_on=None, right_on=None )
left:合并时左边的DataFrame
right:合并时右边的DataFrame
how:合并的方式,默认’inner’, ‘outer’, ‘left’, ‘right’
on:需要合并的列名,必须两边都有的列名,并以 left 和 right 中的列名的交集作为连接键
left_on: left Dataframe中用作连接键的列
right_on: right Dataframe中用作连接键的列
-
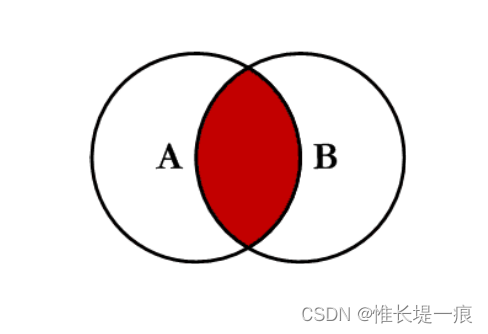
内连接 inner:对两张表都有的键的交集进行联合
-
全连接 outer:对两者表的都有的键的并集进行联合
-
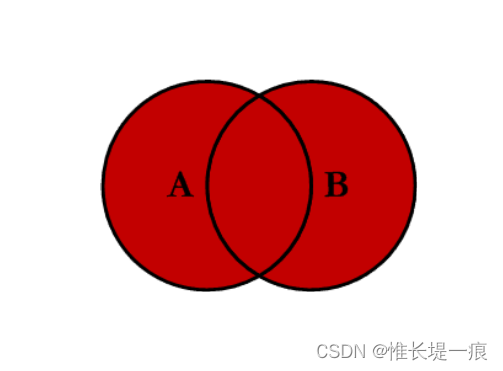
-
左连接 left:对所有左表的键进行联合
-
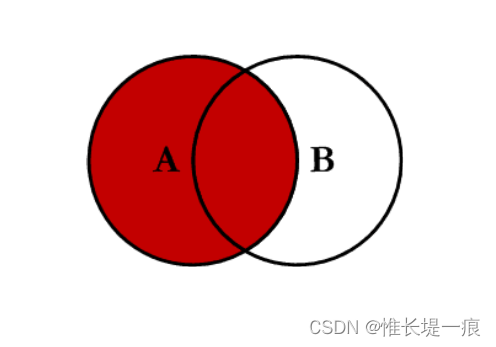
-
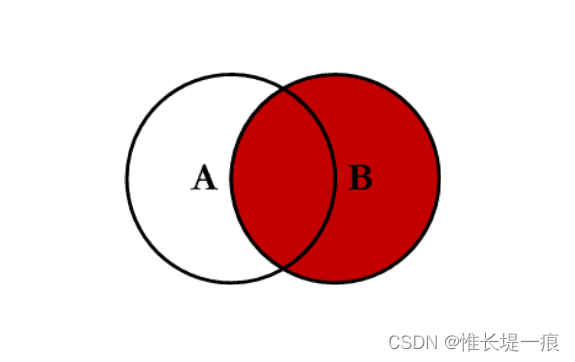
右连接 right:对所有右表的键进行联合
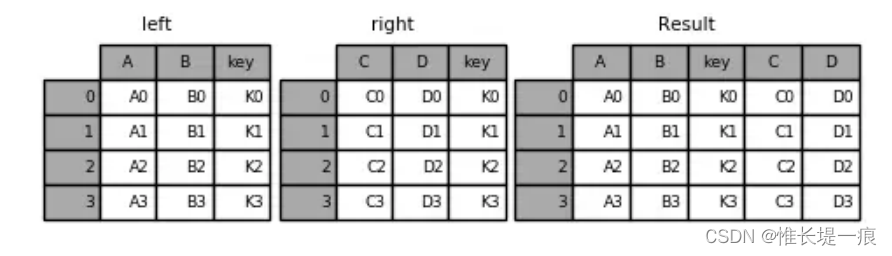
import pandas as pd
import numpy as np
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,on='key') #指定连接键key
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,on=['key1','key2']) #指定多个键,进行合并
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
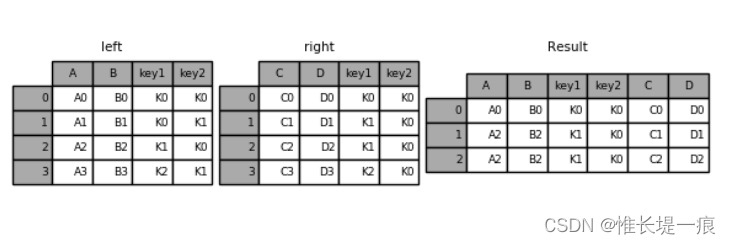
#指定左连接
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how='left', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
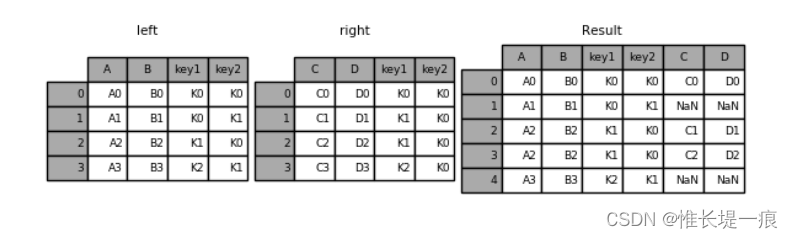
#指定右连接
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how='right', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
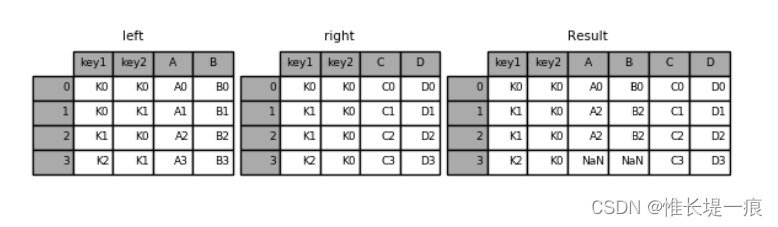
默认是“内连接”(inner),即结果中的键是交集
how指定连接方式
“外连接”(outer),结果中的键是并集
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,how='outer',on=['key1','key2'])
"""
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
"""
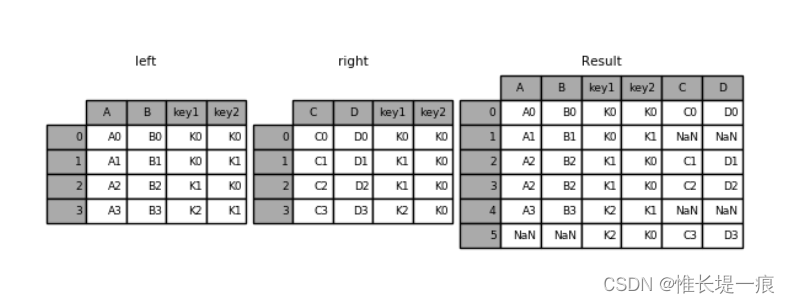
处理重复列名
- 参数suffixes:默认为_x, _y
df_obj1 = pd.DataFrame({
'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({
'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})
print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))
#运行结果
"""
data_left key data_right
0 9 b 1
1 5 b 1
2 1 b 1
3 2 a 8
4 2 a 8
5 5 a 8
"""
按索引连接
- 参数left_index=True或right_index=True
# 按索引连接
df_obj1 = pd.DataFrame({
'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({
'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])
print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))
#运行结果
"""
data1 key data2
0 3 b 6
1 4 b 6
6 8 b 6
2 6 a 0
4 3 a 0
5 0 a 0
"""
1.2.2 pd.concat数据合并
沿轴方向将多个对象合并到一起
NumPy的concat
import numpy as np
import pandas as pd
arr1 = np.random.randint(0, 10, (3, 4))
arr2 = np.random.randint(0, 10, (3, 4))
print(arr1)
print(arr2)
print(np.concatenate([arr1, arr2]))
print(np.concatenate([arr1, arr2], axis=1))
#运行结果
"""
# print(arr1)
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]]
# print(arr2)
[[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2]))
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]
[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2], axis=1))
[[3 3 0 8 6 8 7 3]
[2 0 3 1 1 6 8 7]
[4 8 8 2 1 4 7 1]]
"""
pd.concat
- 注意指定轴方向,默认axis=0
- join指定合并方式,默认为outer
- Series合并时查看行索引有无重复
df1 = pd.DataFrame(np.arange(6).reshape(3,2),index=list('abc'),columns=['one','two'])
df2 = pd.DataFrame(np.arange(4).reshape(2,2)+5,index=list('ac'),columns=['three','four'])
print(pd.concat([df1,df2])) #默认外连接,axis=0
print(pd.concat([df1,df2],axis='columns')) #指定axis=1连接
print(pd.concat([df1,df2],axis=1,join='inner'))
"""
one two three four
a 0.0 1.0 NaN NaN
b 2.0 3.0 NaN NaN
c 4.0 5.0 NaN NaN
a NaN NaN 5.0 6.0
c NaN NaN 7.0 8.0
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
one two three four
a 0 1 5 6
c 4 5 7 8
"""
1.3 重塑
1.3.1 stack
- 将列索引旋转为行索引,完成层级索引
- DataFrame->Series
data = pd.DataFrame(np.arange(6).reshape((2, 3)),
index=pd.Index(['Ohio', 'Colorado'], name='state'),
columns=pd.Index(['one', 'two', 'three'],
name='number'))
print(data)
result = data.stack()
print(result)
#输出:
"""
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
state number
Ohio one 0
two 1
three 2
Colorado one 3
two 4
three 5
dtype: int32
"""
1.3.2 unstack
- 将层级索引展开
- Series->DataFrame
- 默认操作内层索引,即level=1
# 默认操作内层索引
print(stacked.unstack())
# 通过level指定操作索引的级别
print(stacked.unstack(level=0))
"""
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
"""
2 时间序列
时间序列(time series)数据是一种重要的结构化数据形式,。在多个时间点观察或测量到的任何时间都可以形成一段时间序列。很多时间, 时间序列是固定频率的, 也就是说, 数据点是根据某种规律定期出现的(比如每15秒。。。。)。时间序列也可以是不定期的。时间序列数据的意义取决于具体的应用场景。主要由以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
2.1 python内置时间模块
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用得最多的数据类型:
from datetime import datetime
now = datetime.now()
now
"""
datetime.datetime(2023, 11, 1, 21, 25, 38, 531179)
"""
now.year, now.month, now.day
"""
(2023, 11, 1) # 返回元组
"""
datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差:
delta = datetime(2023, 1, 7) - datetime(2022, 6, 24, 8, 15)
delta
"""
datetime.timedelta(days=196, seconds=56700)
"""
delta.days
# 输出:
"""
196
"""
from datetime import timedelta
start = datetime(2022, 1, 7)
start + timedelta(31)
"""
datetime.datetime(2022, 2, 7, 0, 0)
"""

2.1.2 字符串和datetime相互转化
stamp = datetime(2023, 10, 1)
stamp
#输出
datetime.datetime(2023, 10, 1, 0, 0)
"""将datetime对象转换成字符串"""
# 强制转换
str(stamp)
# 格式化
stamp.strftime("%Y-%m-%d %H:%M:%S")
#输出:
'2023-10-01 00:00:00'
"""将字符串转换成datetime对象"""
datetime.strptime('2023/5/20', '%Y/%m/%d')
#输出
datetime.datetime(2023, 5, 20, 0, 0)
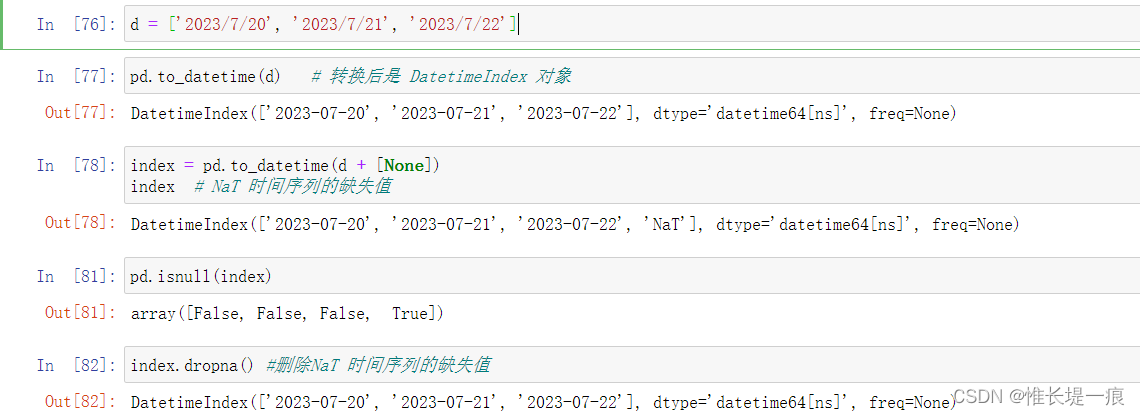
d = ['2023/7/20', '2023/7/21', '2023/7/22']
pd.to_datetime(d) # 转换后是 DatetimeIndex 对象
index = pd.to_datetime(d + [None])
index # NaT 时间序列的缺失值
pd.isnull(index)
index.dropna() #删除NaT 时间序列的缺失值
2.2 时间序列
| 符号 | 含义 | 例 |
|---|---|---|
%a |
缩写的工作日名称 | 'Wed' |
%A |
完整的工作日名称 | 'Wednesday' |
%w |
工作日编号 - 0(星期日)至6(星期六) | '3' |
%d |
每月的一天(零填充) | '13' |
%b |
缩写的月份名称 | 'Jan' |
%B |
全月名称 | 'January' |
%m |
一年中的一个月 | '01' |
%y |
没有世纪的一年 | '16' |
%Y |
与世纪的一年 | '2016' |
%H |
24小时制的小时 | '17' |
%I |
12小时制的小时 | '05' |
%p |
上午下午 | 'PM' |
%M |
分钟 | '00' |
%S |
秒 | '00' |
%f |
微秒 | '000000' |
%z |
时区感知对象的UTC偏移量 | '-0500' |
%Z |
时区名称 | 'EST' |
%j |
一年中的某一天 | '013' |
%W |
一年中的一周 | '02' |
%c |
当前区域设置的日期和时间表示形式 | 'Wed Jan 13 17:00:00 2016' |
%x |
当前区域设置的日期表示形式 | '01/13/16' |
%X |
当前区域设置的时间表示 | '17:00:00' |
%% |
文字%字符 |
'%' |
dates = [datetime(2020, 12, 12), datetime(2020, 12, 13),
datetime(2020, 12, 14), datetime(2020, 12, 15),
datetime(2020, 12, 16)]
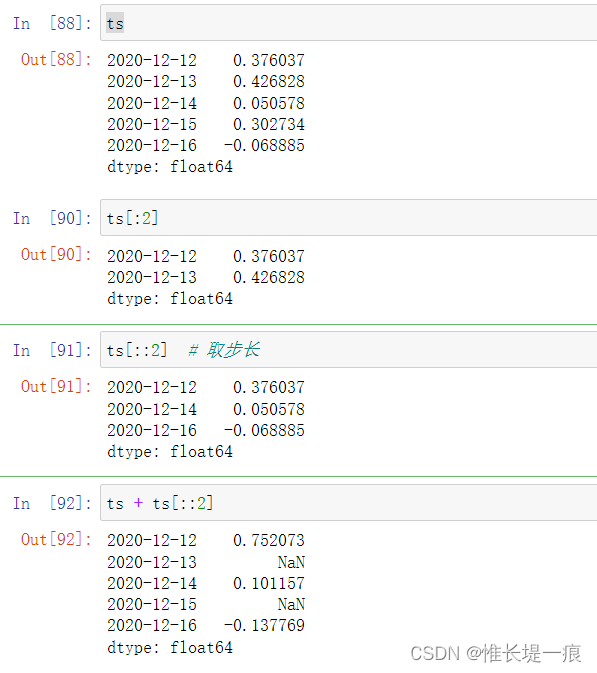
ts = pd.Series(np.random.randn(5), index=dates)
ts # 创建一个 Series 对象, 以时间为行索引
#输出
2020-12-12 0.376037
2020-12-13 0.426828
2020-12-14 0.050578
2020-12-15 0.302734
2020-12-16 -0.068885
dtype: float64
ts.index # 行索引是时间序列索引对象
输出
DatetimeIndex(['2020-12-12', '2020-12-13', '2020-12-14', '2020-12-15',
'2020-12-16'],
dtype='datetime64[ns]', freq=None)
2.2.1取值
ts
2020-12-12 0.376037
2020-12-13 0.426828
2020-12-14 0.050578
2020-12-15 0.302734
2020-12-16 -0.068885
dtype: float64
ts[::2] # 取步长
2020-12-12 0.376037
2020-12-14 0.050578
2020-12-16 -0.068885
dtype: float64
2.2.2推算时间
ts1 = pd.Series(
data=np.random.randn(1000),
index=pd.date_range('2020/01/01', periods=1000)
)
ts1
2020-01-01 -0.700438
2020-01-02 -1.961004
2020-01-03 -0.226558
2020-01-04 -0.594778
2020-01-05 -1.394763
...
2022-09-22 0.025743
2022-09-23 0.784406
2022-09-24 -0.930995
2022-09-25 0.974117
2022-09-26 -1.625869
Freq: D, Length: 1000, dtype: float64
ts1['2021-05-18': '2021-05-27'] # 切片
2021-05-18 -0.487663
2021-05-19 -0.529925
2021-05-20 -0.316952
2021-05-21 0.476325
2021-05-22 -1.006280
2021-05-23 0.438202
2021-05-24 1.505284
2021-05-25 0.523409
2021-05-26 -1.139620
2021-05-27 0.573387
Freq: D, dtype: float64
2.2.3 指定时间范围
pd.date_range('2020-01-01', '2023-08-28')
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10',
...
'2023-08-19', '2023-08-20', '2023-08-21', '2023-08-22',
'2023-08-23', '2023-08-24', '2023-08-25', '2023-08-26',
'2023-08-27', '2023-08-28'],
dtype='datetime64[ns]', length=1336, freq='D')
pd.date_range(start='2020-01-01', periods=100) # 往后推算100天
pd.date_range(end='2023-08-28', periods=100) # 往前推算100天
重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数
resample是一个灵活高效的方法,可用于处理非常大的时间序列。
pd.date_range(start='2023-08-28', periods=10, freq='BH') # freq指定时间频率
输出:
DatetimeIndex(['2023-08-28 09:00:00', '2023-08-28 10:00:00',
'2023-08-28 11:00:00', '2023-08-28 12:00:00',
'2023-08-28 13:00:00', '2023-08-28 14:00:00',
'2023-08-28 15:00:00', '2023-08-28 16:00:00',
'2023-08-29 09:00:00', '2023-08-29 10:00:00'],
dtype='datetime64[ns]', freq='BH')