Keras入门
学习视频: 来自bilibili
gan的一个论文代码集合网站: github
1.环境配置
在annaconda下创建一个新的虚拟环境
配置:
tensorflow需要指定为2.0版本,注意tensorflow和keras的版本一定要对应,对应查看
pip install tensorflow==2.0
pip install keras==2.3.1
2.搭建一个简单的网络
搭建一个网络,去得到公式y=3*x+7,为一元线性回归
除上面的环境配置外,还需要添加
pip install matplotlib
import keras
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,100,30)#在0-100之间任取30个数
y=3*x+7+np.random.randn(30)
model = keras.Sequential()#初始化模型,顺序模型,里面的模块如同火车一样一节一节的
from keras import layers
model.add(layers.Dense(1,input_dim=1))#Dense(输出维度y1,y2...,y3,输入维度x1,x2...xn)全链接层y=ax+b
model.summary()#展示模型参数
#编译模型,确定优化算法,优化目标,确定损失函数,loss是什么,这么优化loss,找loss最小值
model.compile(optimizer='adam',loss='mse')#mse均方差
#训练模型
model.fit(x,y,epochs=30000)
z=model.predict([150])#预测y=150*a+b
print(z)
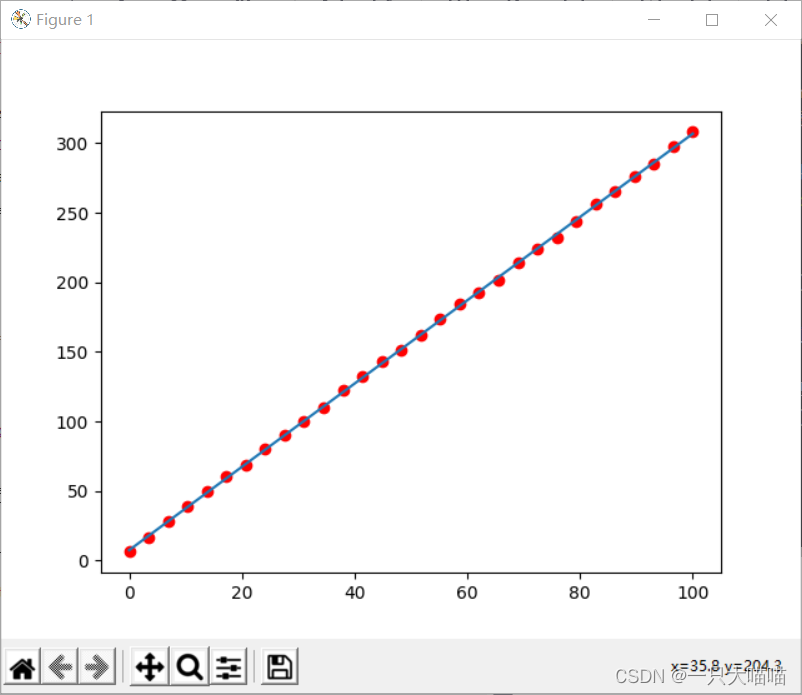
plt.scatter(x,y,c="r")#可视化原有数据集
plt.plot(x,model.predict(x))#可视化函数
plt.show()#可视化展示
3.多元线性回归
多元线性回归公式:Y = W1X1+W2X2+B
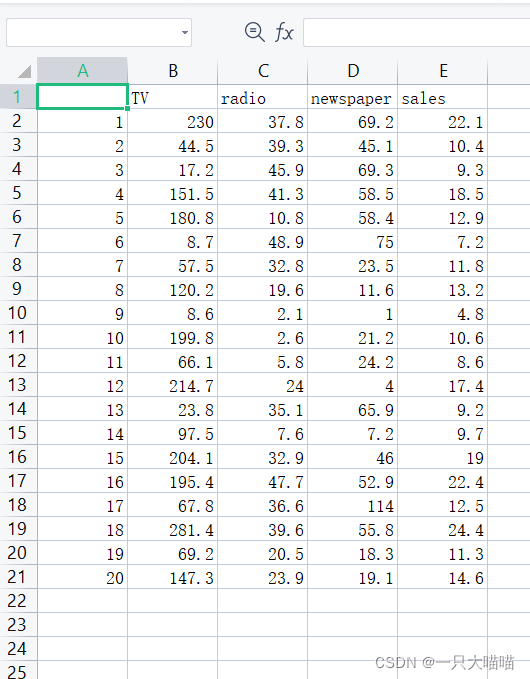
3.1 准备数据集
首先准备数据集,例如下图sales=aTV+bradio+c*newspaper+d
求销售量和各个广告投放的关系[提取码:1024]
3.2 环境配置
在1和2的环境配置基础上添加:
pip install pandas
3.2代码
和一元的代码差不多,不过可以多学习外部数据集如何加载
import keras
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd #pandas是很好用的数据预处理工具
data=pd.read_csv('D:/workspaceForMine/ForGan/ForKeras/data.csv')
#这是excel文件,注意WPS编辑下,可能会导致错误发生,最好使用office,没办法就在WPS保存中选择csv格式,不要直接修改后缀名
z=data.head()
print(z)#打印前几行
x=data[data.columns[1:-1]]#取前三列为x数组
y=data.iloc[:,-1]#取最后一列为y数组
from keras import layers
model= keras.Sequential()
model.add(layers.Dense(1,input_dim=3))#输出1维度,输入维度为3 y_pred=w1*x1+w2*x2+w3*x3+b
model.summary()
model.compile(optimizer='adam',loss='mse')#msejunfangc
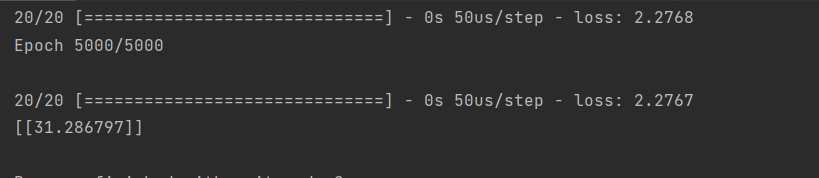
model.fit(x,y,epochs=5000)
w=model.predict(pd.DataFrame([[300,68,60]]))
print(w)
3.4 结果
4.全链接模型之手写数字识别模型
哈哈哈哈哈哈,这个已经是深度学习中类似于Holle World的存在了吧。
这个模型和上面的,可以学习softmax分类以及它常用的sparse_categorical_crossentropy(当label是顺序排列时用这个)和categorical_crossentropy的loss交叉熵

mnist是直接在keras里面的可以不需要先下载
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
print(train_image.shape)#(60000,28,28)由60000张28*28的图片构成
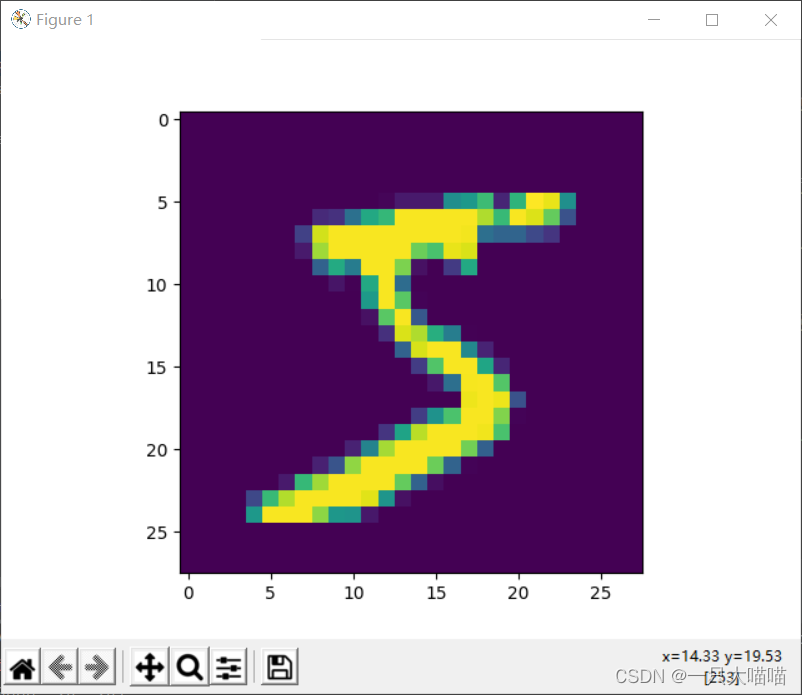
#plt.imshow(train_image[0])#显示第一张图片
plt.show()#plt.imshow()函数负责对图像进行处理,并显示其格式,而plt.show()则是将plt.imshow()处理后的函数显示出来
print(train_label[0])#k看看第一张的标签是啥
model = keras.Sequential()#初始化模型,顺序模型
model.add(layers.Flatten())#展平(60000.28.28)-》(60000,25*25)
model.add(layers.Dense(64,activation='relu'))#28*28链接到64
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc']
)
model.fit(train_image,train_label,epochs=50,batch_size=512)
model.evaluate(test_image,test_label)#输入数据和标签,输出损失和精确度.第一个返回值是损失(loss),第二个返回值是准确率(acc
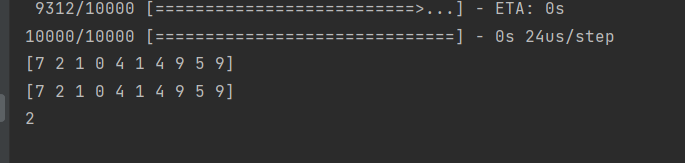
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
print(1+1)
5.优化手写数字识别模型
构建网络的总原则
1.增大网络容量,直到过拟合
2.采取措施抑制过拟合
3.继续增大网络容量,直到过拟合
优化模型常用方法有:多添加全连接层,增大全连接层参数
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
print(train_image.shape)#(60000,28,28)由60000张28*28的图片构成
plt.imshow(train_image[0])#显示第一张图片
#plt.show()#plt.imshow()函数负责对图像进行处理,并显示其格式,而plt.show()则是将plt.imshow()处理后的函数显示出来
print(train_label[0])#k看看第一张的标签是啥
model = keras.Sequential()#初始化模型,顺序模型
model.add(layers.Flatten())#展平(60000.28.28)-》(60000,25*25)
model.add(layers.Dense(64,activation='relu'))#28*28链接到64
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc']
)
model.fit(train_image,train_label,epochs=50,batch_size=512,validation_data=(test_image,test_label
))
print(model.evaluate(test_image,test_label))#输入数据和标签,输出损失和精确度.第一个返回值是损失(loss),第二个返回值是准确率(acc
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
print(1+1)
6.逻辑回归之泰坦尼克判断生死
和上面的区别就是数据预处理挺多的
import keras
import pandas as pd
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
data=pd.read_csv('D:/workspaceForMine/ForGan/ForKeras/Titanic/train.csv')
#print(data.head(5))
#print(data.info)
#y是是否获救
y=data.Survived
#x将有影响因素的类别提出来
x=data[['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']]
#查看Embarked有几类
print(x.Embarked.unique())
#读热编码:把非数值的数据数值化
x.loc[:,'Embarked_S']=(x.Embarked =='S').astype('int')
x.loc[:,'Embarked_C']=(x.Embarked =='C').astype('int')
x.loc[:,'Embarked_Q']=(x.Embarked =='Q').astype('int')
x.loc[:,'Sex']=(x.Sex =='male').astype('int')
x.loc[:,'Pclass1']=(x.Pclass==1).astype('int')
x.loc[:,'Pclass2']=(x.Pclass==2).astype('int')
x.loc[:,'Pclass3']=(x.Pclass==3).astype('int')
del x['Embarked']
del x['Pclass']
#填充数据中的Nan值
x['Age']=x.Age.fillna(x.Age.mean())
print(x)
#准备模型
model = keras.Sequential()
from keras import layers
model.add(layers.Dense(1,input_dim=11,activation='sigmoid'))
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])
history=model.fit(x,y,epochs=300)
plt.plot(range(300),history.history.get('acc'))
plt.show()
history.history.get('loss')
7.加入卷积层之手写数字识别
CNN基础:
cnn工作:将一张图像,让它历经卷积层,非线性层,池化层,池化(下采样层),和全连接层,最终得到输出
卷积是将卷积核应用到某个张良的所有点上,通过将卷积核在输入的张量上滑动而生成经过滤波处理的张量
当一个包含某写特征的图像经过一个卷积核的时候,一些卷积核被激活,输出特定信号。
在训练猫狗图像时,卷积核会被训练,训练的结果就是卷积核会对猫狗不同特征敏感,输出不同的结果,从而达到图像识别的目的
cnn架构:
卷积层:conv2d
非线性变换层:relu/sigmoid/tanh
池化层:pool2d
全连接层:w*x+b
如果没有这些层,模型很难与复杂模式匹配,因为网络将有过多信息填充,这些层的作用就是突出重要信息,降低噪声
conv2d三个参数:
①ksize 核大小
②strides 卷积核移动的跨度
③padding 边缘填充
conv2d:图片输入形状:batch,height,width,channels
池化层 layers.MaxPooling2D()最大池化
增维:
a=np.array([1,2,3]) #a->[1,2,3] a.adim->1
np.expand_dims(a,axis=-1)#增维,在最后一维上增维 a->([1],[2],[3]) a.adim->2
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
train_image=np.expand_dims(train_image,axis=-1)#增加维度将(6000,28,28)—-》(6000,28,28,1 )
test_image=np.expand_dims(test_image,axis=-1)
print(train_image.shape)
model=keras.Sequential()
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.fit(train_image,train_label,epochs=50,batch_size=512,validation_data=(test_image,test_label))
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签

8.练习卷积网络之cifar10数据集多种类识别
和上面的手写数据集识别差不多,就是个人练习
预处理多一个归一化
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
cifar=keras.datasets.cifar10#cifar10是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=cifar.load_data()#加载keras里面的数据集,可能会慢,网上现下\
print(train_image.shape)
#plt.imshow(train_image[100])
#plt.show()
#归一化
train_image=train_image/255
test_image=test_image/255
model=keras.Sequential()
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(32,32,3)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.fit(train_image,train_label,epochs=50,batch_size=512,validation_data=(test_image,test_label))
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
9.cnn卷积网络实例之猫狗数据集分类
9.1图片的读取与预处理
猫狗数据集[验证码:1024]
下面代码的作用是把图片从原本的数据集转移到自建的目录,如果运行过一次,创建了目录,运行第二次的时候会报错已有目录,这时候把创建目录的几行代码注释就行
import keras
import os
import shutil
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
base_dir='./dataset/cat_dog'
train_dir=os.path.join(base_dir,'train')
train_dir_dog=os.path.join(train_dir,'dog')
train_dir_cat=os.path.join(train_dir,'cat')
test_dir=os.path.join(base_dir,'test')
test_dir_dog=os.path.join(test_dir,'dog')
test_dir_cat=os.path.join(test_dir,'cat')
#创建数据集目录
os.mkdir(base_dir)
os.mkdir(train_dir)
os.mkdir(train_dir_dog)
os.mkdir(train_dir_cat)
os.mkdir(test_dir)
os.mkdir(test_dir_dog)
os.mkdir(test_dir_cat)
dc_dir ='D:/workspaceForMine/ForGan/ForKeras/CatDog/dc/train'
#将原本数据集的图片放入准备的数据集
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
s=os.path.join(dc_dir,fname)
d=os.path.join(train_dir_cat,fname)
shutil.copyfile(s,d)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
s=os.path.join(dc_dir,fname)
d=os.path.join(test_dir_cat,fname)
shutil.copyfile(s,d)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
s=os.path.join(dc_dir,fname)
d=os.path.join(train_dir_dog,fname)
shutil.copyfile(s,d)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
s=os.path.join(dc_dir,fname)
d=os.path.join(test_dir_dog,fname)
shutil.copyfile(s,d)
9.2 完整训练代码
import keras
import os
import shutil
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
base_dir='./dataset/cat_dog'
train_dir=os.path.join(base_dir,'train')
train_dir_dog=os.path.join(train_dir,'dog')
train_dir_cat=os.path.join(train_dir,'cat')
test_dir=os.path.join(base_dir,'test')
test_dir_dog=os.path.join(test_dir,'dog')
test_dir_cat=os.path.join(test_dir,'cat')
if not os.path.exists(base_dir):
os.mkdir(base_dir)
os.mkdir(train_dir)
os.mkdir(train_dir_dog)
os.mkdir(train_dir_cat)
os.mkdir(test_dir)
os.mkdir(test_dir_dog)
os.mkdir(test_dir_cat)
dc_dir = 'D:/workspaceForMine/ForGan/ForKeras/CatDog/dc/train'
# 将原本数据集的图片放入准备的数据集
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
s = os.path.join(dc_dir, fname)
d = os.path.join(train_dir_cat, fname)
shutil.copyfile(s, d)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
s = os.path.join(dc_dir, fname)
d = os.path.join(test_dir_cat, fname)
shutil.copyfile(s, d)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
s = os.path.join(dc_dir, fname)
d = os.path.join(train_dir_dog, fname)
shutil.copyfile(s, d)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
s = os.path.join(dc_dir, fname)
d = os.path.join(test_dir_dog, fname)
shutil.copyfile(s, d)
from keras.preprocessing.image import ImageDataGenerator
train_datagen =ImageDataGenerator(rescale=1/255)#rescale=1/255归一化
test_datagen =ImageDataGenerator(rescale=1/255)
train_generator=train_datagen.flow_from_directory(train_dir,target_size=(200,200),batch_size=20,class_mode='binary')
test_generator=train_datagen.flow_from_directory(test_dir,target_size=(200,200),batch_size=20,class_mode='binary')
model=keras.Sequential()
model.add(layers.Conv2D(64,(3*3),activation="relu",input_shape=(200,200,3)))
model.add(layers.Conv2D(64,(3*3),activation="relu"))
model.add(layers.MaxPooling2D())
model.add(layers.Dropout(0.25))#Dropout层防止过拟合
model.add(layers.Conv2D(64,(3*3),activation="relu"))
model.add(layers.Conv2D(64,(3*3),activation="relu"))
model.add(layers.MaxPooling2D())
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(64,(3*3),activation="relu"))
model.add(layers.Conv2D(64,(3*3),activation="relu"))
model.add(layers.MaxPooling2D())
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])
history=model.fit_generator(train_generator,epochs=30,steps_per_epoch=100,validation_data=test_generator,validation_steps=50)#steps_per_epoch训练多少步是一个epoch
9.3 图像增强
如果数据集数据量太少会造成模型过拟合,如果数据集无法增加,可以考虑图像增强操作
在ImageDataGenerator函数中,去使用图像增强参数
train_daragen=ImageDataGenerator(rescale=1/255,rotation_range=40,width_shift_range=0.2)
在实际应用中还是增大真实数据集吧,效果要好很多
10. 模型保存和加载
10.1加载和保存整个模型
整个模型:
①模型的结构,允许重新创建模型
②模型的权重
③模型配置项(损失函数,优化器)
④优化器状态,允许你从上次结束的地方继续训练
以手写模型的cnn网络为例
其实最重要就俩句
import h5py
model.save('mymodel.h5')
1.保存输出模型
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
train_image=np.expand_dims(train_image,axis=-1)#增加维度将(6000,28,28)—-》(6000,28,28,1 )
test_image=np.expand_dims(test_image,axis=-1)
print(train_image.shape)
model=keras.Sequential()
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.fit(train_image,train_label,epochs=20,batch_size=512,validation_data=(test_image,test_label))
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
import h5py
model.save('mymodel.h5')

2.加载模型并推理
遇到了报错:
model_config = json.loads(model_config.decode(‘utf-8’))
AttributeError: ‘str’ object has no attribute ‘decode’
需要在虚拟环境中:pip install tensorflow h5py
import keras
from keras import layers
import matplotlib.pyplot as plt
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
from keras.models import load_model
mymodel = load_model('mymodel.h5')
import numpy as np
test_image=np.expand_dims(test_image,axis=-1)
mymodel.evaluate(test_image,test_label)
y=np.argmax(mymodel.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
10.2只保存和加载模型结构
1.只保存模型结构,而没有权重或者配置项
重要代码如下
my_model_json=model.to_json()
#model.to_json('mymodleJson')
with open('mymodelJson.json','w') as f:
f.write(my_model_json)
完整代码:
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
train_image=np.expand_dims(train_image,axis=-1)#增加维度将(6000,28,28)—-》(6000,28,28,1 )
test_image=np.expand_dims(test_image,axis=-1)
print(train_image.shape)
model=keras.Sequential()
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.fit(train_image,train_label,epochs=10,batch_size=512,validation_data=(test_image,test_label))
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
import h5py
model.save('mymodel.h5')
#之保存模型结构而非其权重或训练配置项
my_model_json=model.to_json()
#model.to_json('mymodleJson')
with open('mymodelJson.json','w') as f:
f.write(my_model_json)
2.加载使用模型结构
import keras
from keras import layers
import matplotlib.pyplot as plt
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
with open('mymodelJson.json') as f:
mymodelJson=f.read()
from keras.models import model_from_json
model=model_from_json(mymodelJson)
import numpy as np
test_image=np.expand_dims(test_image,axis=-1)
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.evaluate(test_image,test_label)
model.summary()
10.3 只保存模型的权重
model.save_weights('my_model_weights.h5')
model.load_weights('my_model_weights.h5')
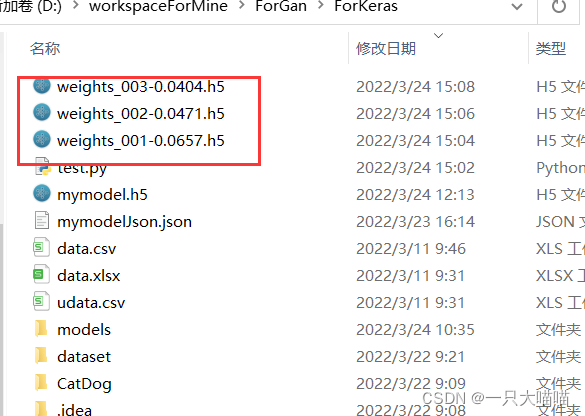
10.4 在训练期间保存检查点
在训练期间或者结束时保存检查点,这样一来,可以使用经过训练的模型,而无需重新训练该模型,或从上次训练赞同的地方继续戌年,以防止训练过程中断。
参考他人博客:[1],[2]
重要代码:回调函数
checkpoint_path='weights_{epoch:03d}-{val_loss:.4f}.h5'
cp_callback=keras.callbacks.ModelCheckpoint(checkpoint_path,period=1,save_weights_only=True)#可以通过参数调整是保存模型还是只是权重
model.fit(train_image,train_label,epochs=20,batch_size=512,validation_data=(test_image,test_label),callbacks=[cp_callback])
完整代码:
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import keras.datasets.mnist as mnist #手写数据集是直接内嵌在keras里面的,要用会直接下载
(train_image,train_label),(test_image,test_label)=mnist.load_data()#加载keras里面的数据集,可能会慢,网上现下
train_image=np.expand_dims(train_image,axis=-1)#增加维度将(6000,28,28)—-》(6000,28,28,1 )
test_image=np.expand_dims(test_image,axis=-1)
print(train_image.shape)
from keras.callbacks import ModelCheckpoint
checkpoint_path='weights_{epoch:03d}-{val_loss:.4f}.h5'
cp_callback=keras.callbacks.ModelCheckpoint(checkpoint_path,period=1,save_weights_only=True)#可以通过参数调整是保存模型还是只是权重
model=keras.Sequential()
model.add(layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
model.fit(train_image,train_label,epochs=20,batch_size=512,validation_data=(test_image,test_label),callbacks=[cp_callback])
y=np.argmax(model.predict(test_image[:10]),axis=1)#测试测试集的前十张,输出1-10,十个数的可能概率
print(y)
print(test_label[:10])#打印测试集的前十个原来的标签
import h5py
model.save('mymodel.h5')