前言
最近在业务中有一个生成一批音频的需求,尝试使用有道开源的 EmotiVoice 项目来实现。然而,在部署 EmotiVoice 的过程中,CUDA 和 PyTorch 环境配置总是有问题。经过一天的斗争,决定寻求其他解决方案。在同事的推荐下,了解到腾讯云还在内测的高性能应用服务 HAI。通过使用 HAI,整个部署过程变得无比丝滑,迅速完成了任务。这里记录一下整个过程。
高性能应用服务 HAI 产品介绍
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 AI 和科学计算的 GPU/NPU 应用服务产品,提供即插即用的强大算力和常见环境。它可以帮助中小企业和开发者快速部署语言模型(LLM)、AI 绘图、数据科学等高性能应用,原生集成配套的开发工具和组件,大大提升应用层的开发生产效率。
HAI 服务优势:
- 简单易用
通过简化计算、网络和存储等基础设施的配置流程,大幅降低了云服务操作和管理的复杂度。 - 应用环境快速部署
支持多种 AI 环境快速部署,如 ChatGLM-6B、StableDiffusion 等,使用户可专注业务及应用场景创新。 - 高灵活性
支持用户登录实例,对 AI 模型及实例环境进行灵活配置。可进行内部开发、业务测试,或对外提供业务服务。 - 多种登录方式
除传统连接方式外,支持通过 jupyterlab、WebUI 等方式一键启动,提供更贴合使用场景的登录方式。 - 算力种类丰富
提供多种算力套餐选择,未来还将加入更多种类供用户选择。
高性能应用服务 HAI 相比传统 GPU 云服务器的主要区别和优势请参考下表:
| 功能类别 | GPU 云服务器 | 高性能应用服务 HAI |
|---|---|---|
| 交付形态 | 基础的虚拟机 | 即插即用的应用 |
| 机型选择 | 需要了解 GPU 型号,自行选择合适机型,有不匹配风险 | 基于 AI 应用,自动匹配合适套餐 |
| 环境部署 | 需要自行部署驱动、CUDA、Python、Notebook 等环境依赖 | 分钟级快速启动,直接交付可用应用环境 |
| 资源配置 | 需要额外购买合适的云硬盘、带宽或流量 | 打包 GPU、云硬盘、带宽及网络,一键启动 |
| 产品入口 | 需要具备一定运维知识,登录命令行界面进行操作 | 提供 WebUI 等可视化连接方式,一键进入服务,可视化配置 |
| 模型甄别 | 各类模型版本繁多,难以自行挑选 | 预置最新版本的主流模型,适配套餐机型 |
| 资源下载 | 部分访问可能遇到网络拥塞问题 | 跨境线路自动择优,支持学术资源平台访问、下载加速 |
HAI 应用场景:
- AI 作画/设计
设计师和开发者可以使用高性能应用服务快速地部署和优化 AI 绘画模型。高性能应用服务预置 Stable Diffusion 等主流 AI 作画模型及常用插件,提供 GUI 图形化界面即开即用,大幅降低上手门槛。 - AI 对话/写作
研究者和开发者可以使用高性能应用服务快速部署和运行大型语言模型,如 LLAMA2、ChatGLM 等,进行自然语言处理任务,如文本生成、情感分析、文本分类等。高性能应用服务提供的算力支持和优化环境确保了语言模型可以在最短的时间内进行部署,同时还能保持高稳定性和可靠性。 - AI 开发测试
高性能应用服务的预配置环境支持大多数流行的 AI 框架和工具,如 TensorFlow、PyTorch 等,使得开发者可以专注于算法设计和模型优化。AI 研究者可以在高性能应用服务上进行模型的开发、训练、测试和优化,无需担心硬件兼容性和软件配置问题。如新算法的原型开发、模型微调与迁移学习、深度学习框架的交叉测试等。 - 数据科学
数据科学家们可使用高性能应用服务,快速进行数据分析和图标处理。高性能应用服务预置了 Notebook、Python 环境,以及主流分析软件。
申请高性能应用服务 HAI
-
点击链接进入 高性能应用服务 HAI 申请体验资格
-
等待审核通过后,进入 高性能应用服务 HAI
-
点击 前往体验 HAI,登录 高性能应用服务 HAI 控制台
-
点击 新建 选择 AI 框架,选择算力方案、输入 实例名称、选择数量 后立即购买
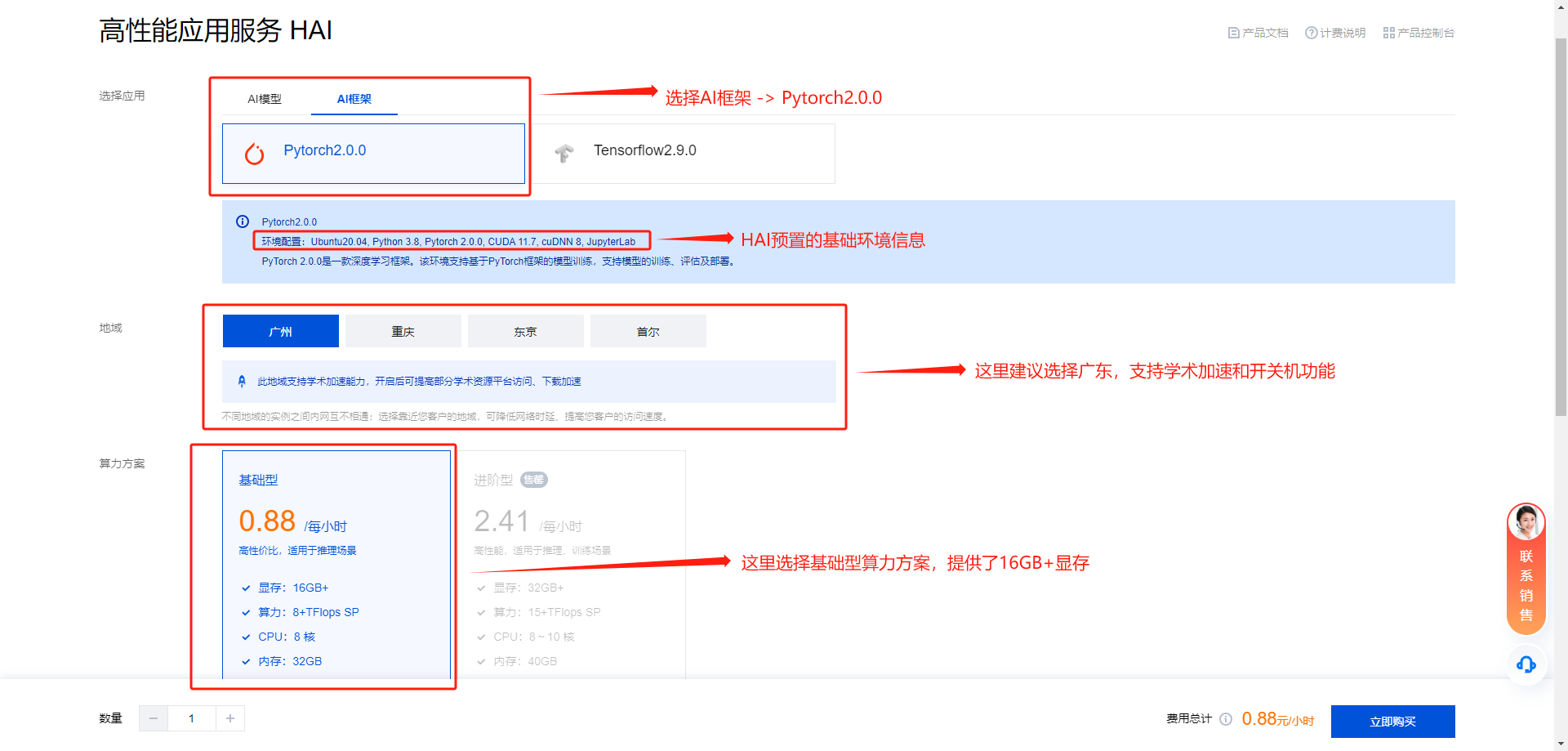
-
查看实例创建状态
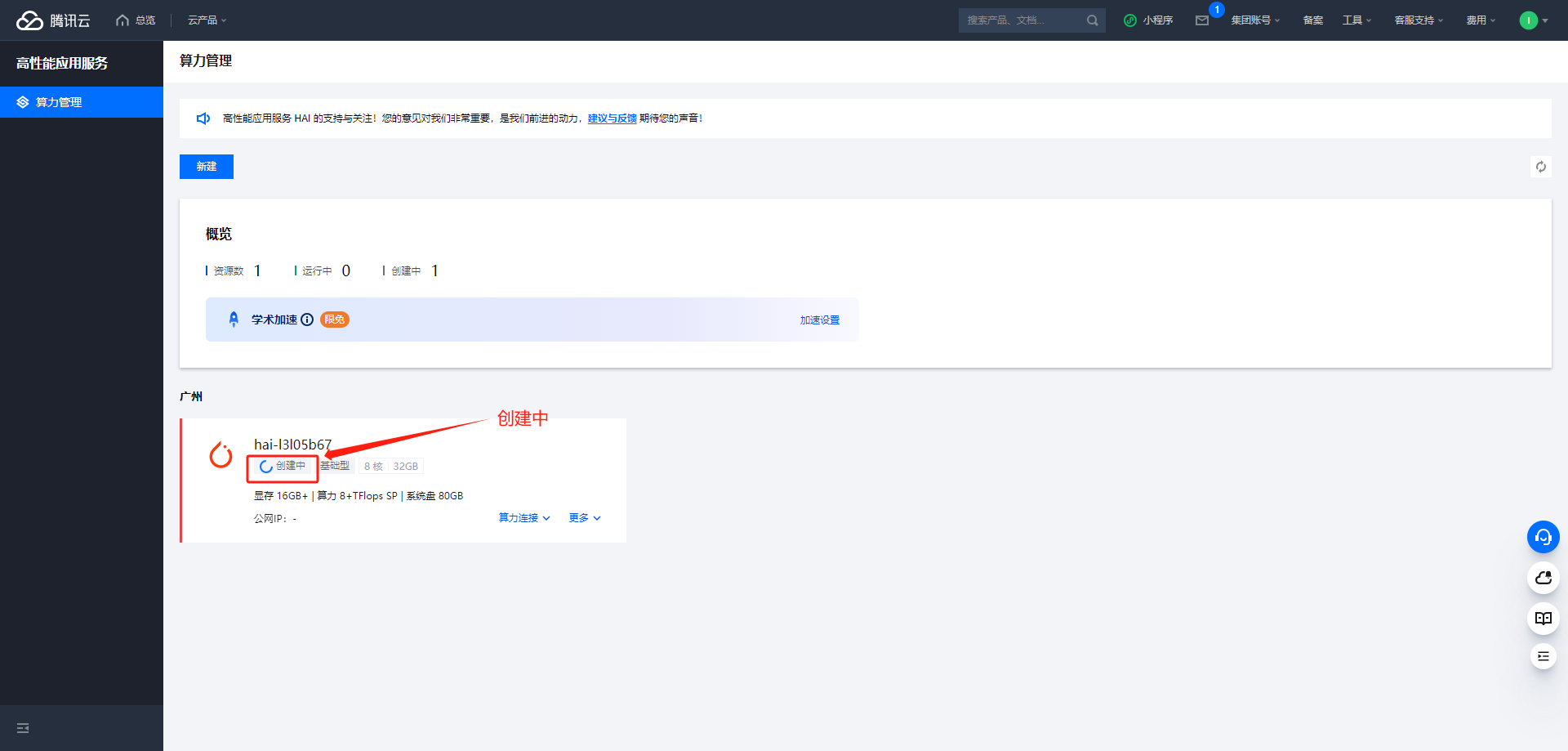
-
开启学术加速功能
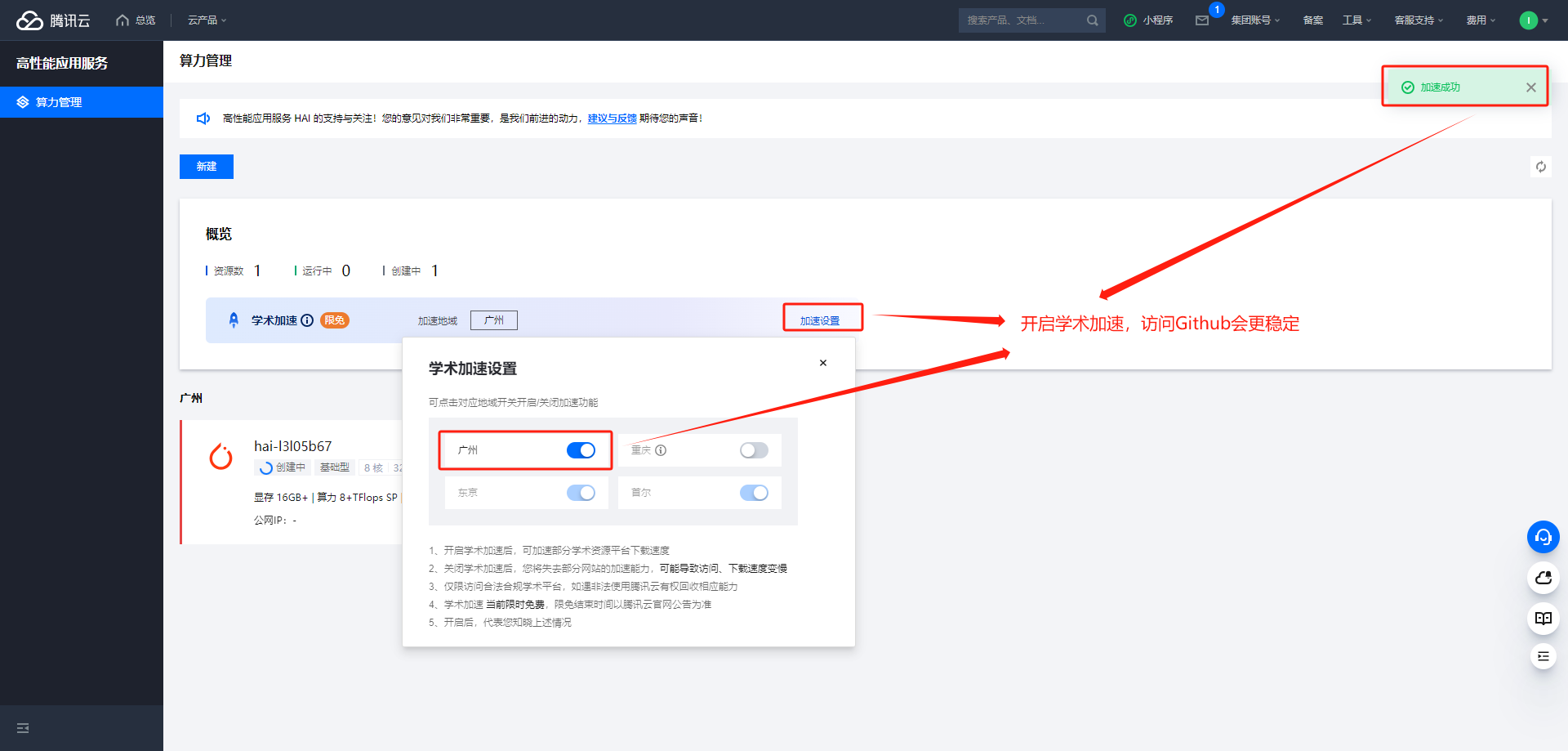
-
完成创建,查看运行状态
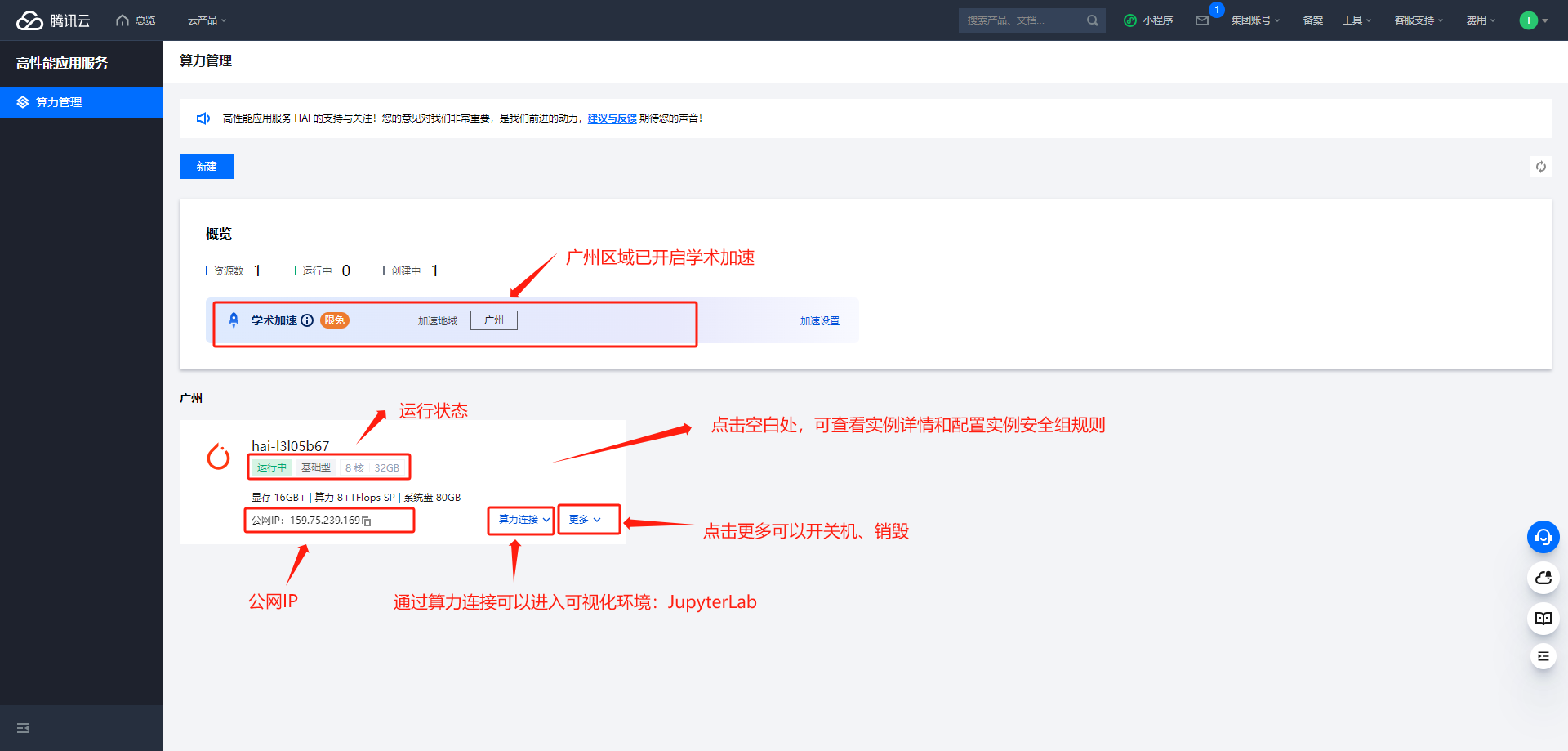
使用 高性能应用服务 HAI PyTorch 2.0 部署 EmotiVoice
-
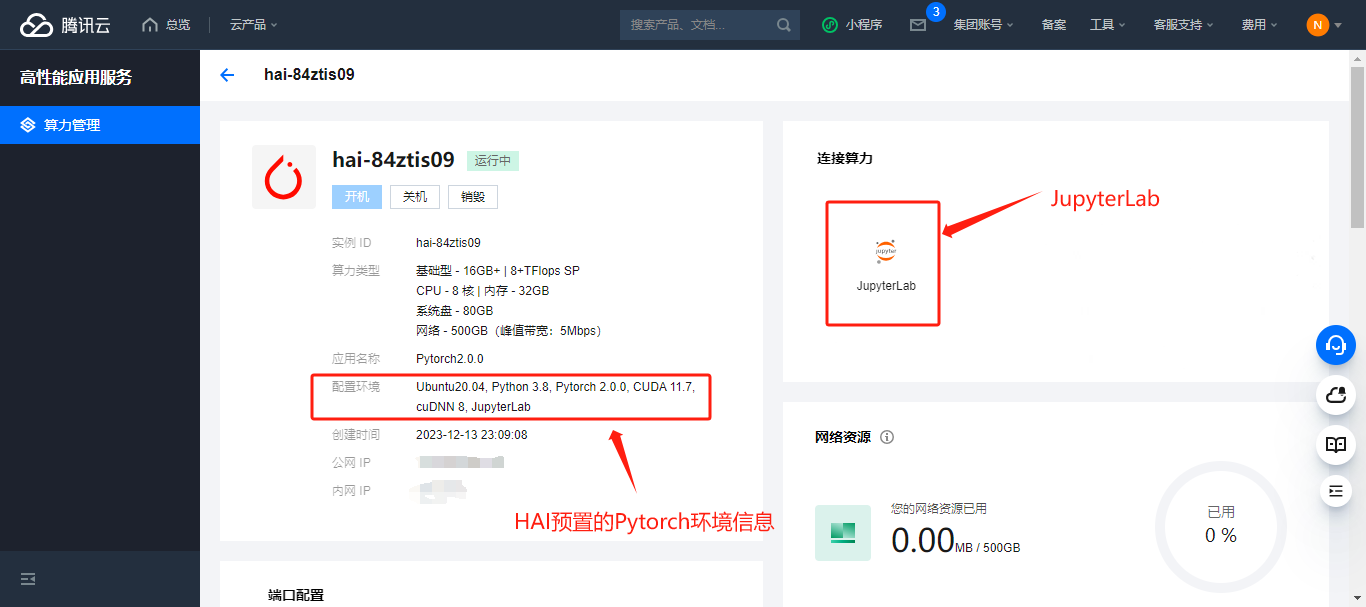
进入 jupyter_lab 环境
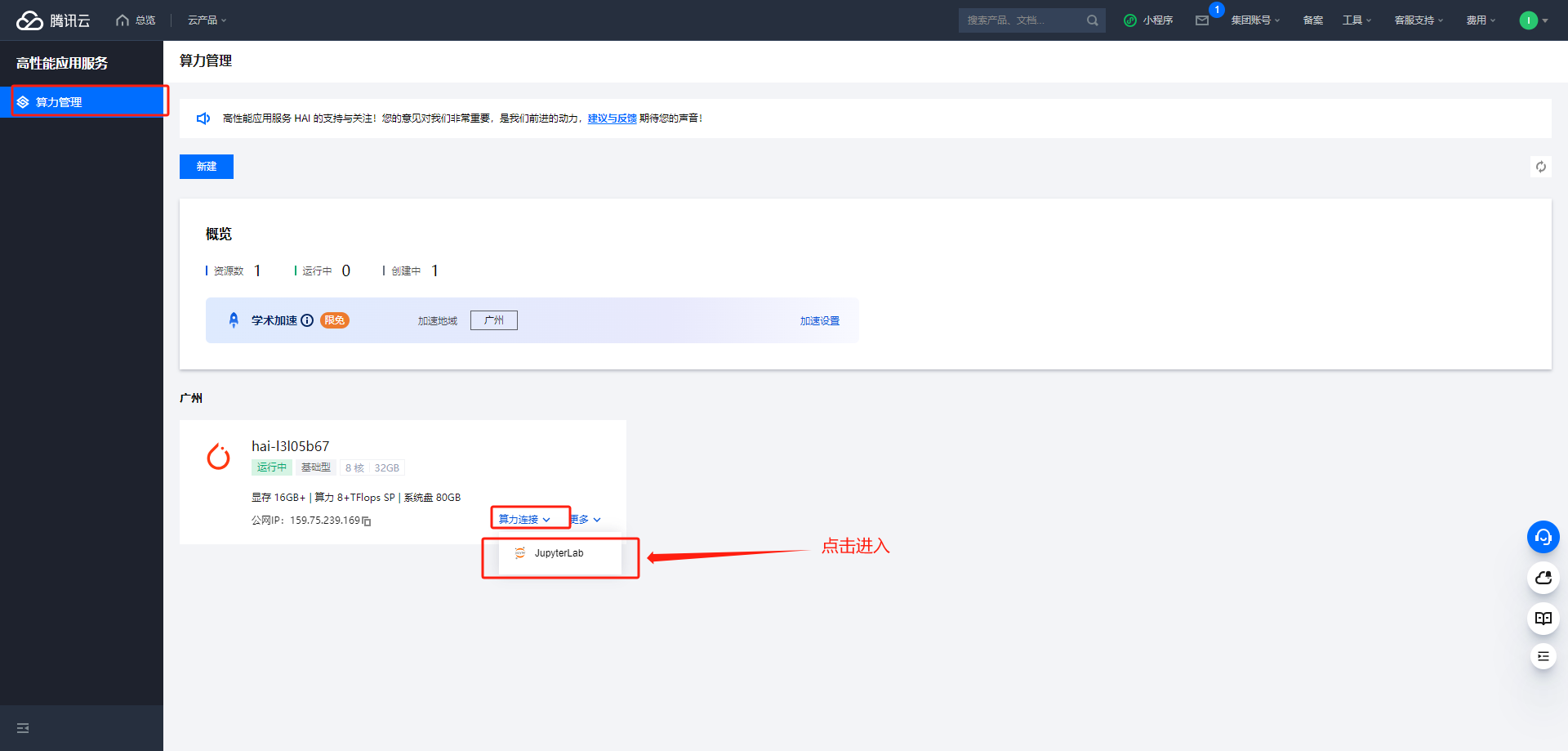
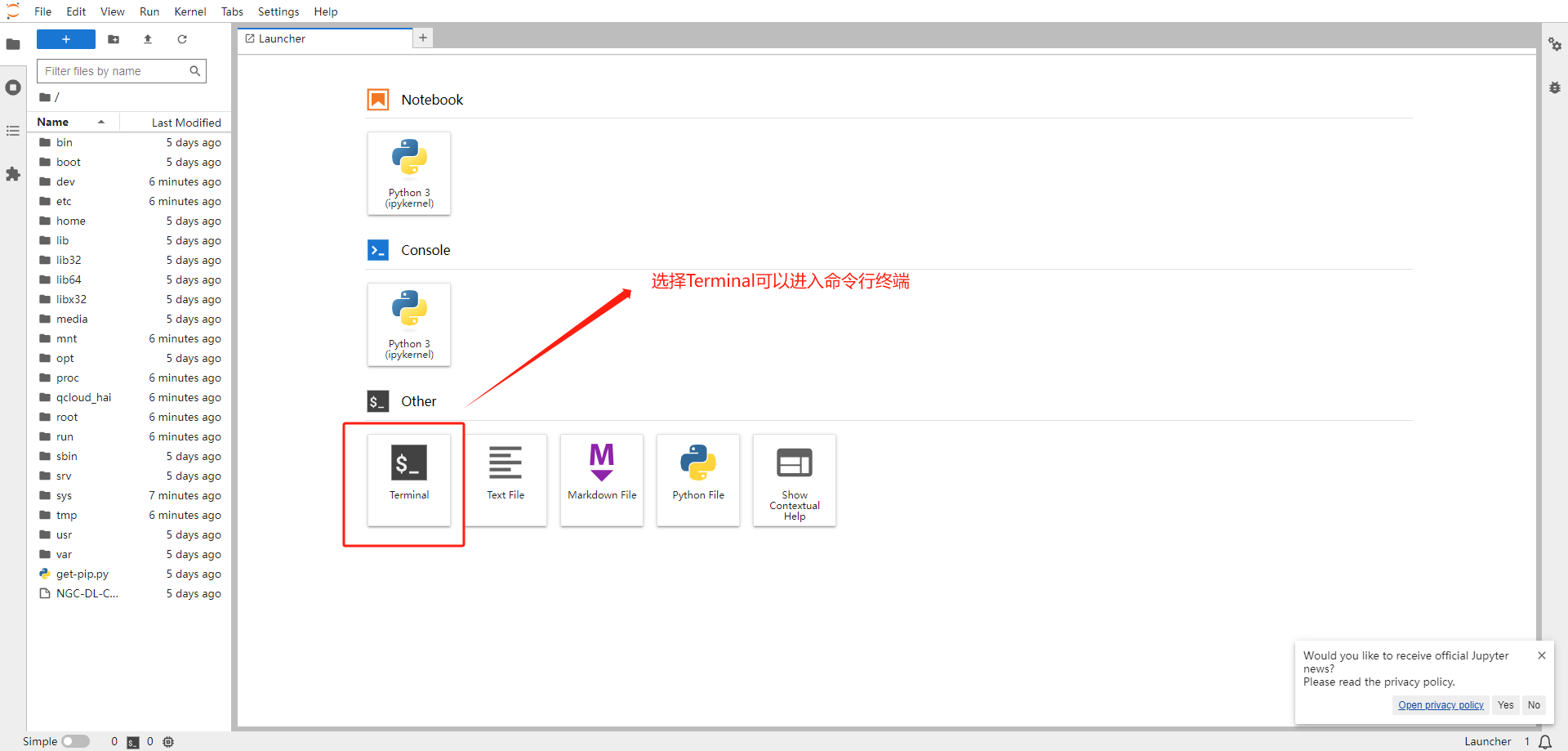
-
安装 CUDA:HAI 已预置,跳过 -
安装 Anaconda:HAI 已预置,跳过 -
创建 Python3.8 环境:HAI 已预置,跳过 -
安装 PyTorch:HAI 环境已预置,跳过 -
安装 git-lfs:
apt-get clean && apt-get update apt-get install git-lfs -
克隆 EmotiVoice 仓库:
cd /root && git clone https://github.com/netease-youdao/EmotiVoice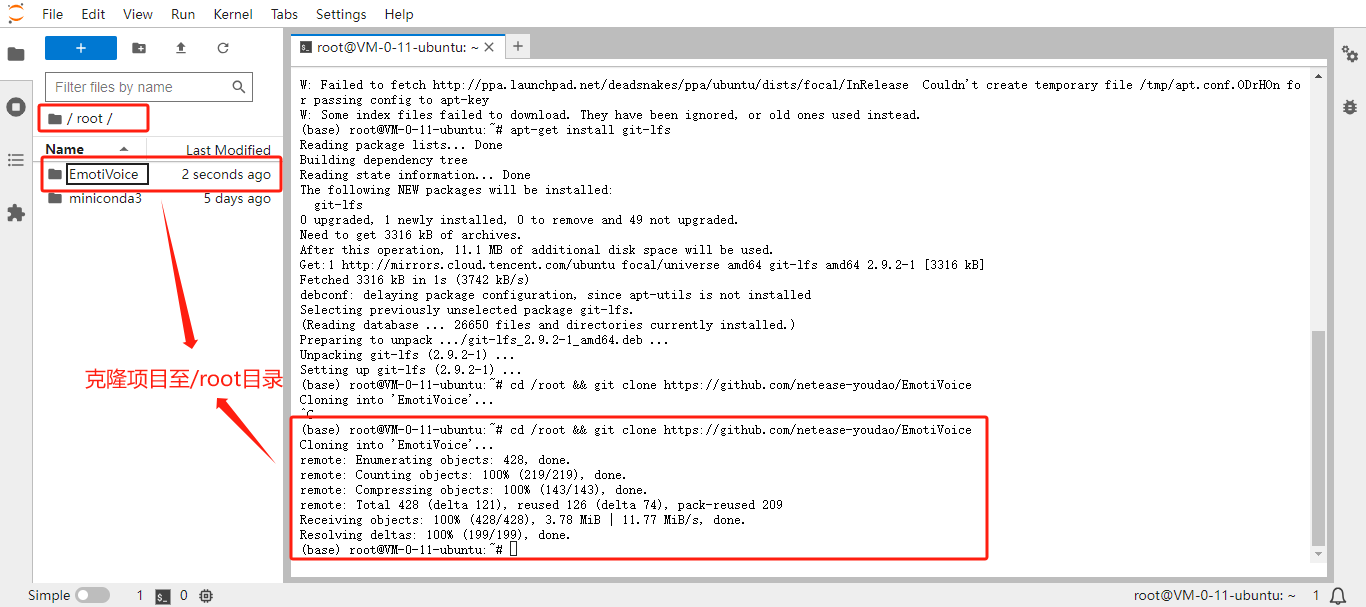
-
下载预训练模型文件:
cd /root/EmotiVoice git lfs install git lfs clone https://www.modelscope.cn/syq163/WangZeJun.git -
下载 ckpt 模型:
cd /root/EmotiVoice git lfs clone https://www.modelscope.cn/syq163/outputs.git这里如果提示
fatal: destination path 'outputs' already exists and is not an empty directory.,手动将/root/EmotiVoice目录下的outputs目录删除,之后再次执行 clone 命令即可 -
上面步骤完成后,项目文件夹内会多
WangZeJun和outputs文件夹,下面是项目文件结构├── Dockerfile ├── EmotiVoice_UserAgreement_易魔声用户协议.pdf ├── demo_page.py ├── frontend.py ├── frontend_cn.py ├── frontend_en.py ├── WangZeJun │ └── simbert-base-chinese │ ├── README.md │ ├── config.json │ ├── pytorch_model.bin │ └── vocab.txt ├── outputs │ ├── README.md │ ├── configuration.json │ ├── prompt_tts_open_source_joint │ │ └── ckpt │ │ ├── do_00140000 │ │ └── g_00140000 │ └── style_encoder │ └── ckpt │ └── checkpoint_163431 -
安装 EmotiVoice 依赖:
pip install numpy numba scipy transformers==4.26.1 soundfile yacs g2p_en jieba pypinyin -
运行 UI 交互界面:
# 安装UI页面所需依赖 pip install streamlit cd /root/EmotiVoice && streamlit run demo_page.py --server.port 6889 --logger.level debug启动命令中的 6889 端口是 HAI 默认开放的端口之一,如果修改了启动命令中的端口,需要手动配置 HAI 的安全组策略,将服务端口放行
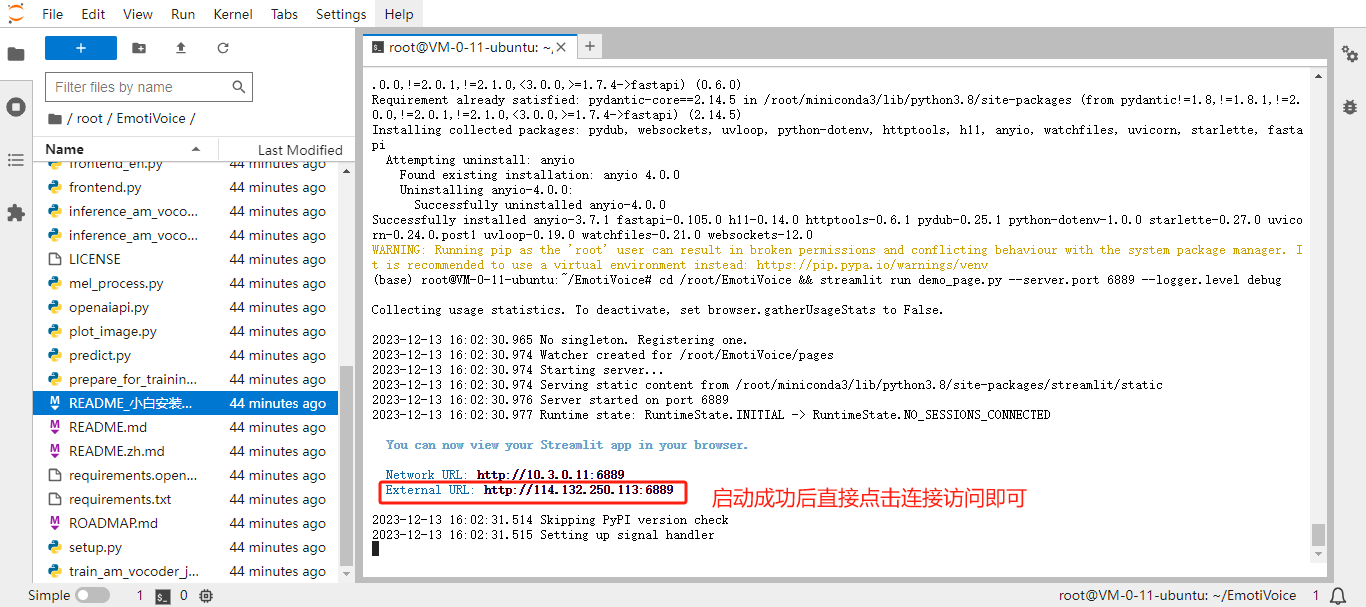

-
运行类 OpenAI TTS 的 API
# 安装ffmpeg apt-get clean && apt-get update apt-get install ffmpeg # 安装API所需的依赖 pip install fastapi pip install pydub pip install uvicorn[standard] # 运行服务 cd /root/EmotiVoice uvicorn openaiapi:app --reload --host 0.0.0.0 --port 6006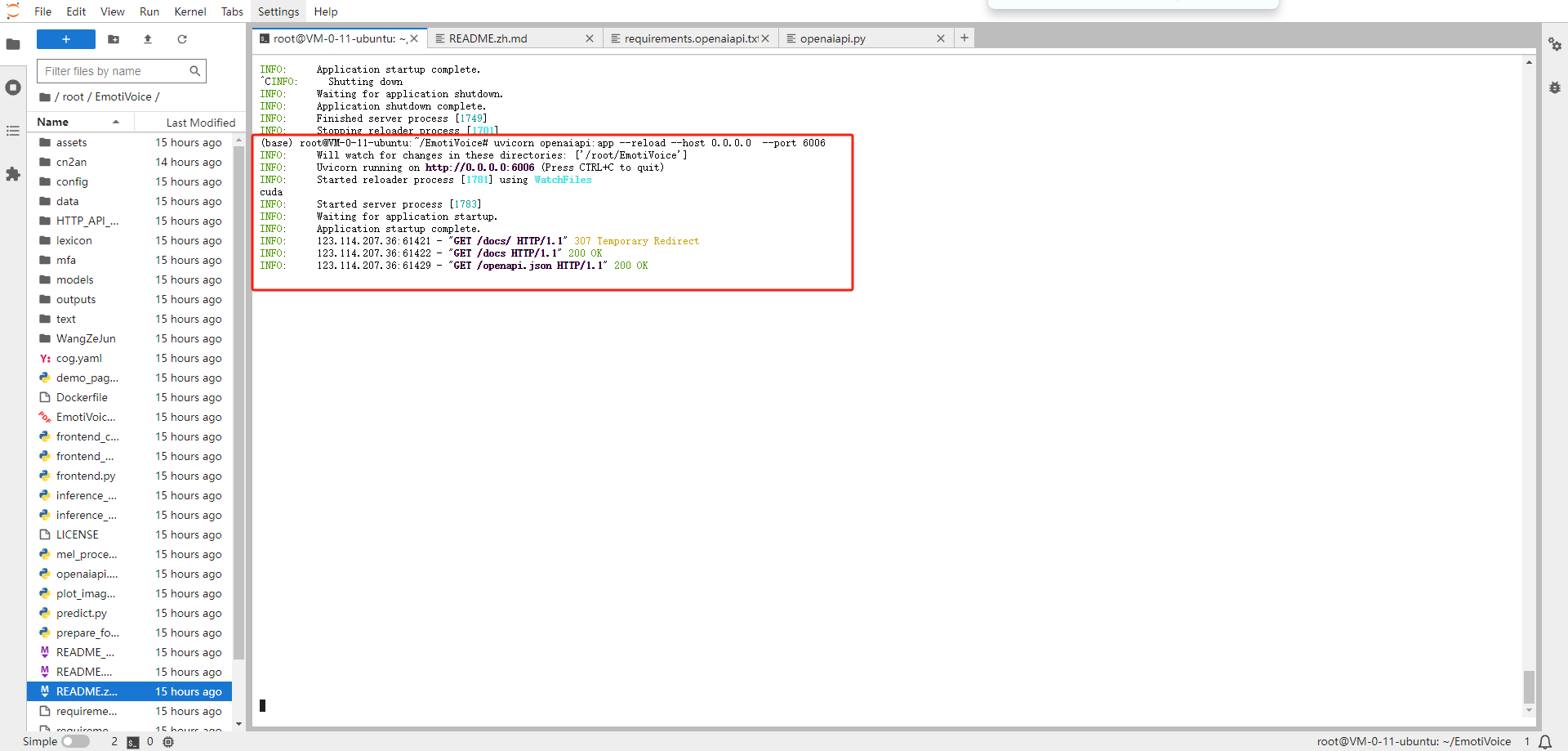
启动后可以通过/docs 查看接口文档
总结
在部署 EmotiVoice 的过程中,我们可以看到,在 HAI 上,得益于 HAI 预置的基础环境和镜像源,部署 EmotiVoice 变得无比简单,十几分钟就可以轻轻松松的将 EmotiVoice 部署完成并运行,大大提高了工作效率。相比之下,B 站上的 EmotiVoice 安装教程视频,花了二十分钟讲解 CUDA、Anaconda、Python、PyTorch,而在 HAI 上,二十分钟的时候已经将应用部署完成了。
同时,使用 HAI 时不需要了解 GPU 型号、机型,不会出现运行环境不匹配的风险,我之前使用 GPU 服务器就是在运行环境配置上被 GPU、CUDA 和 PyTorch 环境问题折磨了一天,HAI 完美帮我避免了这些问题。当然,在使用 HAI 的过程中,也遇到了一些小问题,譬如新建实例可能会失败,开放地域过少等问题。考虑到 HAI 还在内测阶段,这些小问题也无伤大雅,期待 HAI 的后续迭代优化。
HAI 预置了 Juyper NoteBook环境,因此这里也为大家提供一份【基于HAI一键部署EmotiVoice.ipynb】,可以通过文章上方链接进入下载,或者私信我发给大家。