论文信息
代码(官方):https://github.com/ruisun1/Mask-Predict-main
论文地址: https://arxiv.org/pdf/2301.06323.pdf
Abstract
论文方法:Error-Guided Correction Model (EGCM)
- 提出了zero-shot的检错方法
- 提出了新的loss function
1. Introduction
TODO
2. Related Work
略
3. Methodology
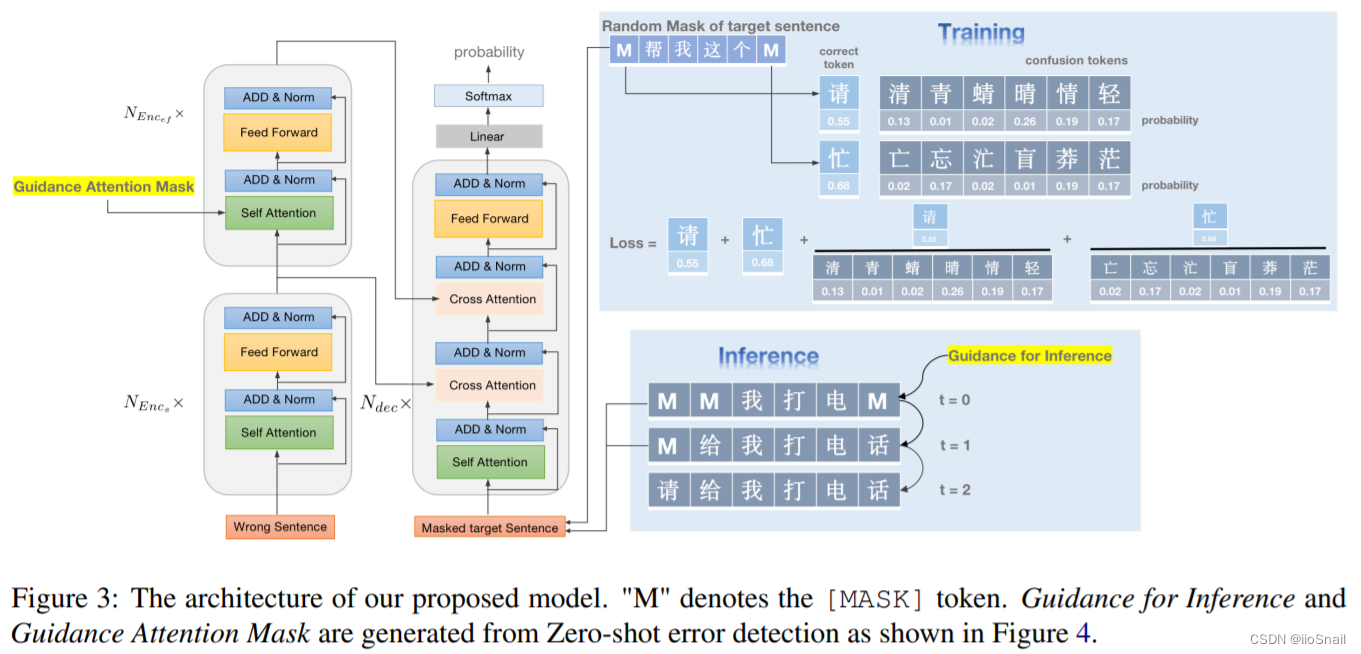
整个方法架构如上图,后面慢慢拆解。
3.1 Zero-shot Detection Method
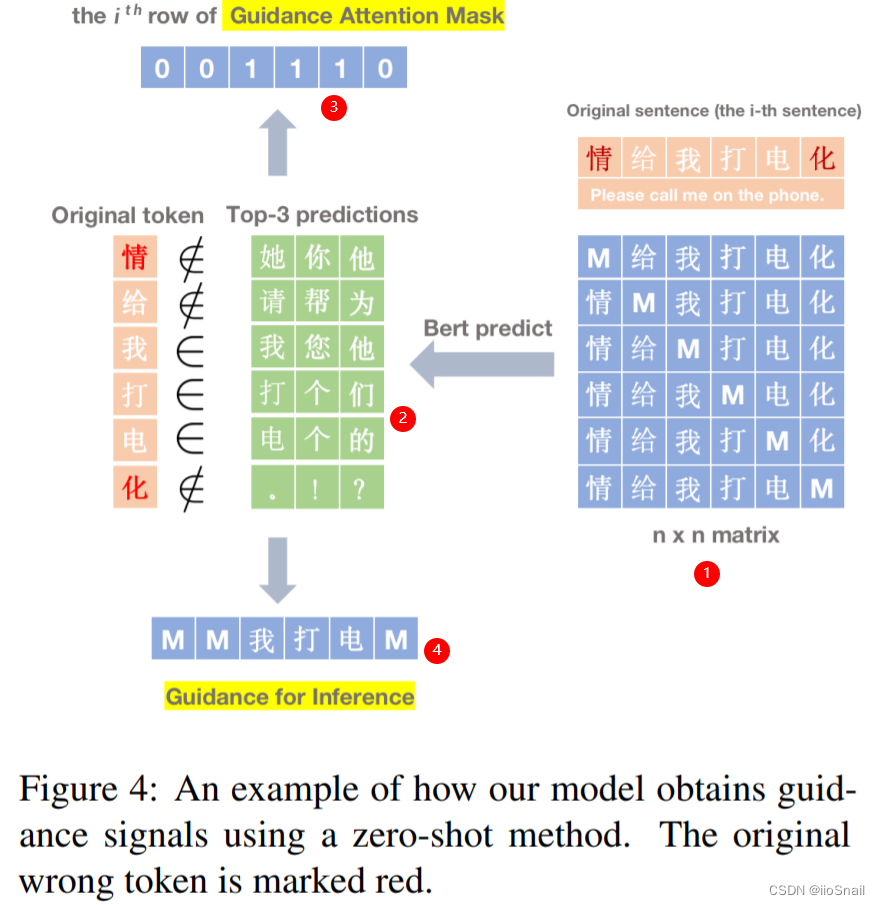
这方法我试了一下, 虽然整体效果不好,但召回率特别高,也就是错字基本都能找出来,但是很多正确的字也会认为是错字
- 将每个字都[MASK]一下, 如果一句话有6个字,最终就会产生6个句子
- 然后将每个句子都送个BERT去预测一下[MASK]位置上的字,然后从输出中选出最大的3个,看下是否包含原token,若包含,则认为该字没错,否则就是错字。
- 生成一个 Guidance Attention Mask(GAM),0 表示该位置是错字,1表示没错。用于后续指导模型纠错(训练和推理阶段均使用)。
- 再生成个 Guidance for Inference(GFI),将错字变成[MASK],正确字原封不动。用于后续指导模型推理(仅推理时使用)。
3.2 Error-aware Encoder
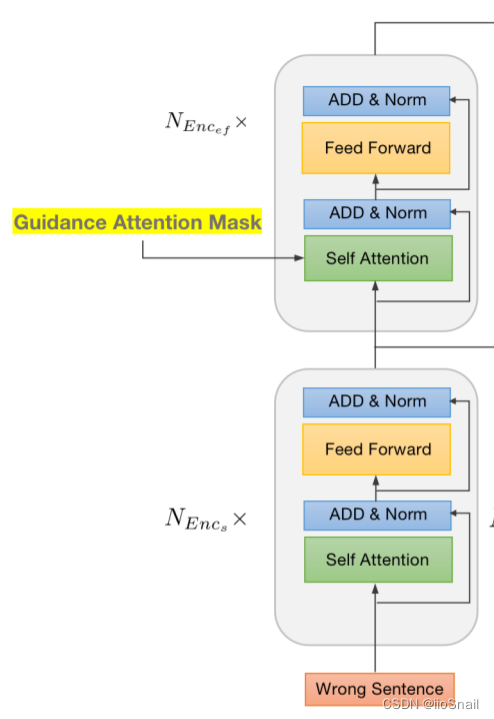
两个n层的Transformer Encoder。
- 下面的 E n c o d e r s Encoder_s Encoders 和普通的没区别
- 上面的 E n c o d e r e f Encoder_{ef} Encoderef (error-focus) 增加了 Guidance Attention Mask(GAM),用于告诉Attention把注意力都放在错字上。
作者好像没说 E n c o d e r e f Encoder_{ef} Encoderef的Self-Attention层怎么把前一层的输出和(GAM)进行融合。直接相乘?
3.3 Integrating Error Confusion Set for Training
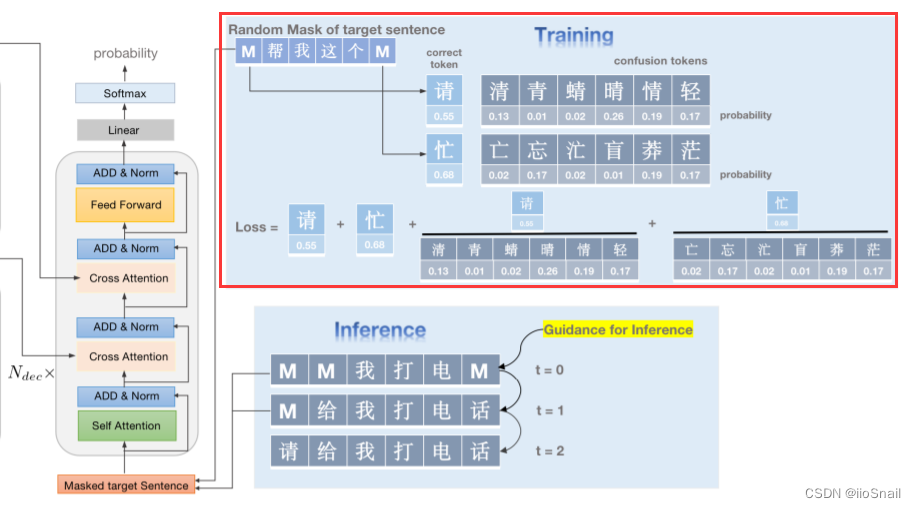
训练阶段会将句子的token进行随机的MASK,包含两种策略:
- mask-separate:就是mask单独的字,例如
[MASK]因你太美 - mask-range: 就是mask连续的字。例如,
[MASK][MASK]你太美。范围是连续的两个字或三个字
不知道为什么作者不使用Guidance Attention Mask,而要使用随机MASK
Decoder比标准Transformer Decoder多了个Cross Attention层,因为前面有两种Encoder( E n c o d e r s Encoder_s Encoders 和 E n c o d e r e f Encoder_{ef} Encoderef)
损失函数上,作者使用了两个损失函数:
- CrossEntropyLoss( L n l l L_{nll} Lnll):不过他只计算
[MASK]token的损失,其他的不计算。 (作者在论文里说的是Negative log-likelihood, NLL,但其实指的就是CrossEntropyLoss) - Confusion Set损失( L c l L_{cl} Lcl):从Softmax结果中取出
[MASK]token对应的混淆字的概率,然后以它们为CrossEntropy的分母,再计算一次CrossEntropy,公式为:
L c s = − ∑ y i ∈ Y m a s k log P ( y i ∣ X , Y o b s ) ∑ y c ∈ Y c o n f log P ( y c ∣ X , Y o b s ) L_{c s}=-\sum_{y_i \in Y_{m a s k}} \frac{\log P\left(y_i \mid X, Y_{o b s}\right)}{\sum_{y_c \in Y_{c o n f}} \log P\left(y_c \mid X, Y_{o b s}\right)} Lcs=−yi∈Ymask∑∑yc∈YconflogP(yc∣X,Yobs)logP(yi∣X,Yobs)
其中 P ( ⋅ ) P(\cdot) P(⋅) 就是某个token的概率, y c y_c yc 为 y i y_i yi对应的混淆字。同样这个只计算[mask]token的概率。
该损失的目的是让token不要被相似的字给干扰。
最终这两个损失加权相加, L = L n l l + γ × L c s L = L_{nll}+\gamma \times L_{cs} L=Lnll+γ×Lcs
3.4 Error-Guided Generation
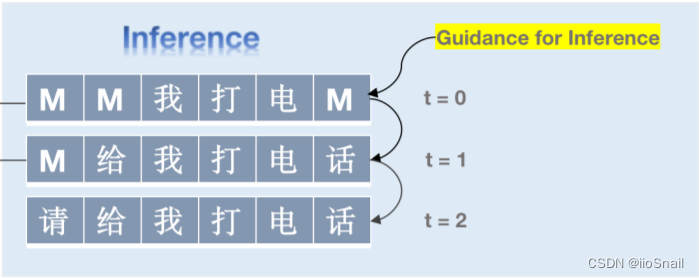
推理阶段,使用Detection模块给出的结果对数据进行MASK,然后送给模型进行预测,预测后将那些置信度比较高的给固定住,置信度低的继续mask进行预测,重复3次。
4. Experimental Setup
4.1 Dataset and Metrics
Wang271K+SIGHAN
4.2 Comparing Methods
略
4.3 Hyperparameter Setting
- Dropout: 0.3
- L2 Weight decay: 0.01
- γ \gamma γ: 2
- Optimizer: Adam( β = ( 0.9 , 0.999 ) , ϵ = 1 e − 6 \beta=(0.9, 0.999), \epsilon=1e^{-6} β=(0.9,0.999),ϵ=1e−6)
- learning rate: 5 e − 5 5e^{-5} 5e−5
- schedule: warmup and linear decay
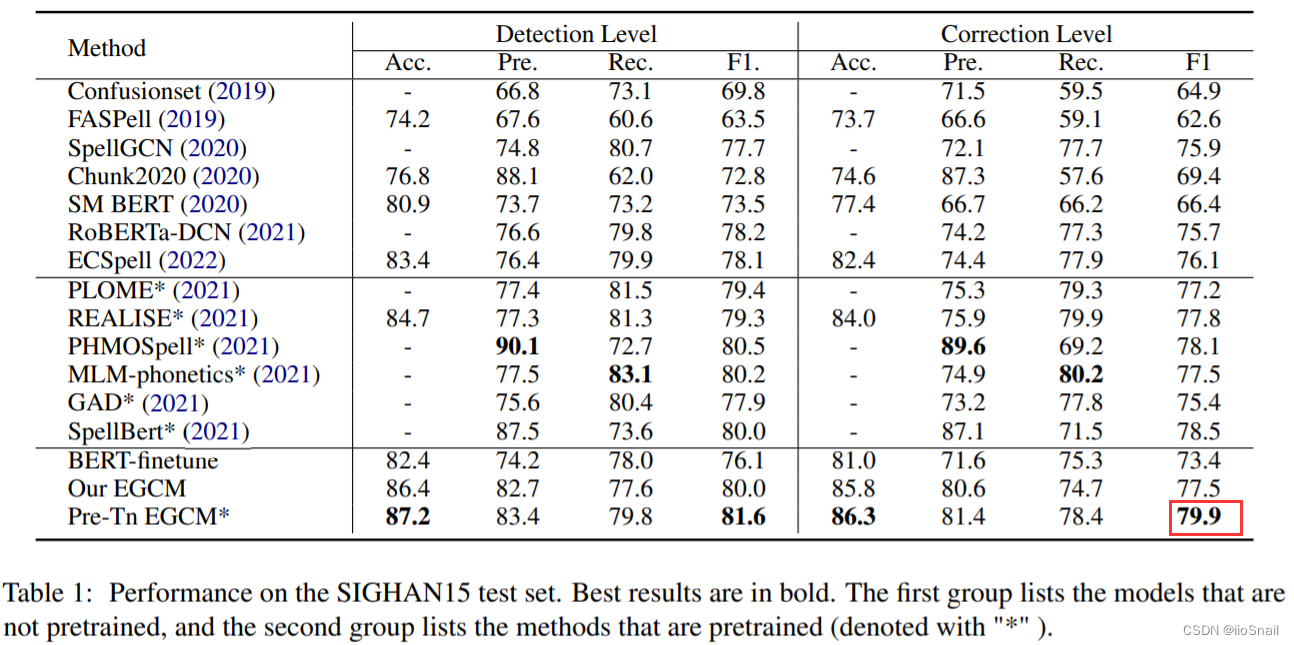
5. Results and Analysis
个人总结
论文缺点
- 没有结合错字信息,这样的话预测结果给一个语义相同的字好像没有应对措施。
值得借鉴的地方
- 论文使用了Detection结果来更新Attention,让模型更关注正确字部分
- 论文使用了多次预测的方式解决了连续错字的问题
- 论文使用了混淆损失函数,让模型可以区分汉字与其混淆字的区别。