

-
使用缓存的逻辑非常通用,基本都是先查缓存,有直接返回,没有查DB,再放入缓存中。这段通用逻辑散落在系统的各个地方,违反了高内聚低耦合的原则。 -
缓存代码和业务逻辑代码深度耦合在一起,不仅降低了代码的可读性,还额外增加了系统复杂度。 -
如果要切换缓存(MDB->LDB)或者API升级时,所有涉及代码都需要改动。 -
如果要解决缓存击穿、缓存穿透、级联缓存等类似通用问题时,都需要通过框架去解决。

先读取缓存数据,如果有数据则直接返回,如果没有读取到数据,则读取DB数据,等数据返回后,再更新缓存。
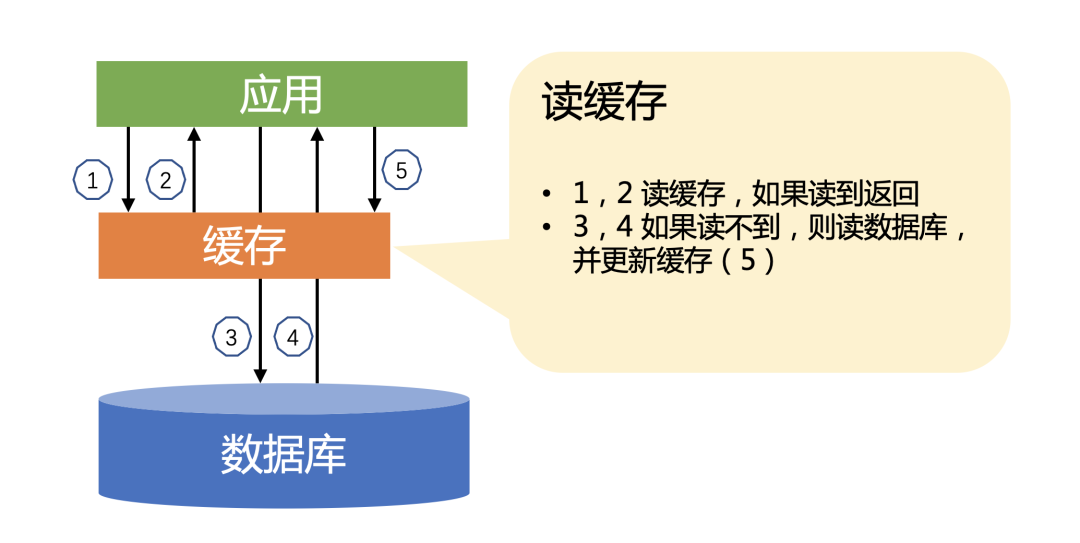
这种场景,在日常编码中,很常见,太简单,但是实际的代码确实很不一样,列举如下几种:
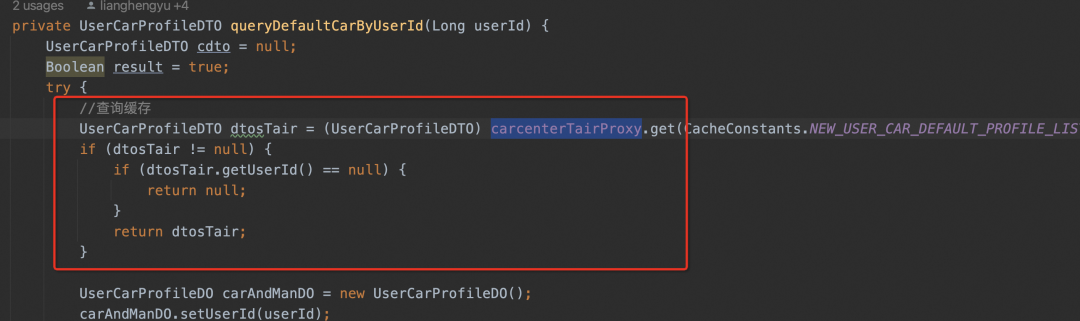
▐ 传统写法
使用什么缓存,就直接使用,嵌入到业务代码中。这种代码不管是code review,还是后人学习业务代码时,都不想看,道理很简单,跟实际的业务功能无关,我不想知道你用什么缓存,你是怎么编码缓存代码的。

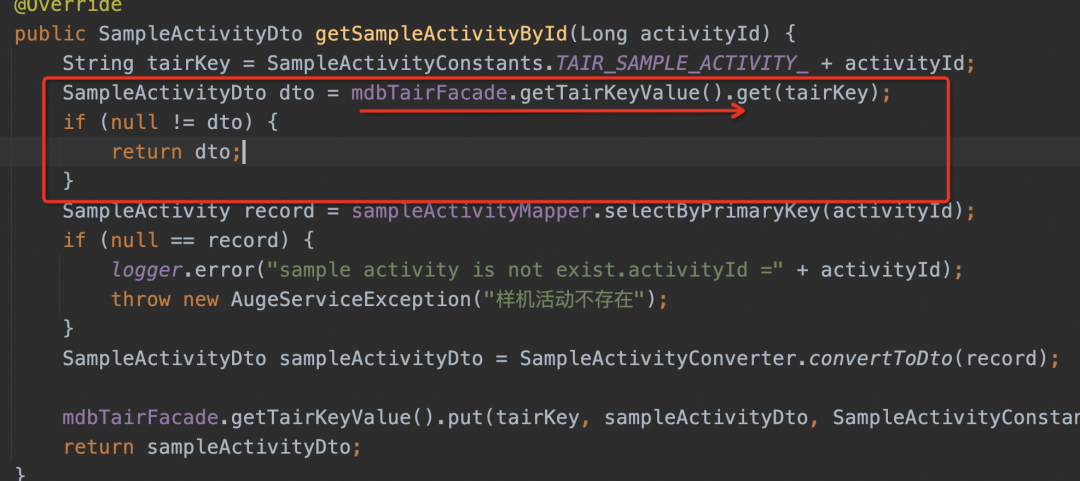
▐ 高级一点的写法
相比传统的写法,为了解决缓存各种数据格式(List、Map等),各种对象序列化问题(java、json),团队内可以针对缓存这块,封装成简单的API,方便大家使用。使用简单了,但代码依然嵌入在业务代码中,没有剥离出来。
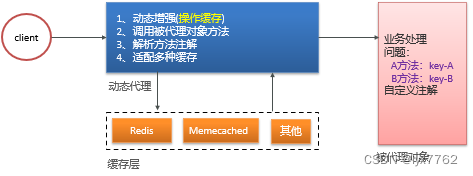
▐ 注解写法


spring cache利用动态代理的方式,在代理类中处理缓存的相关操作,同时调用被代理类中的方法,从而可以使操作缓存的代码和业务代码分离,并且后期需要强化缓存能力时,也只需要修改代理类中的方法即可。
▐ 代码目录
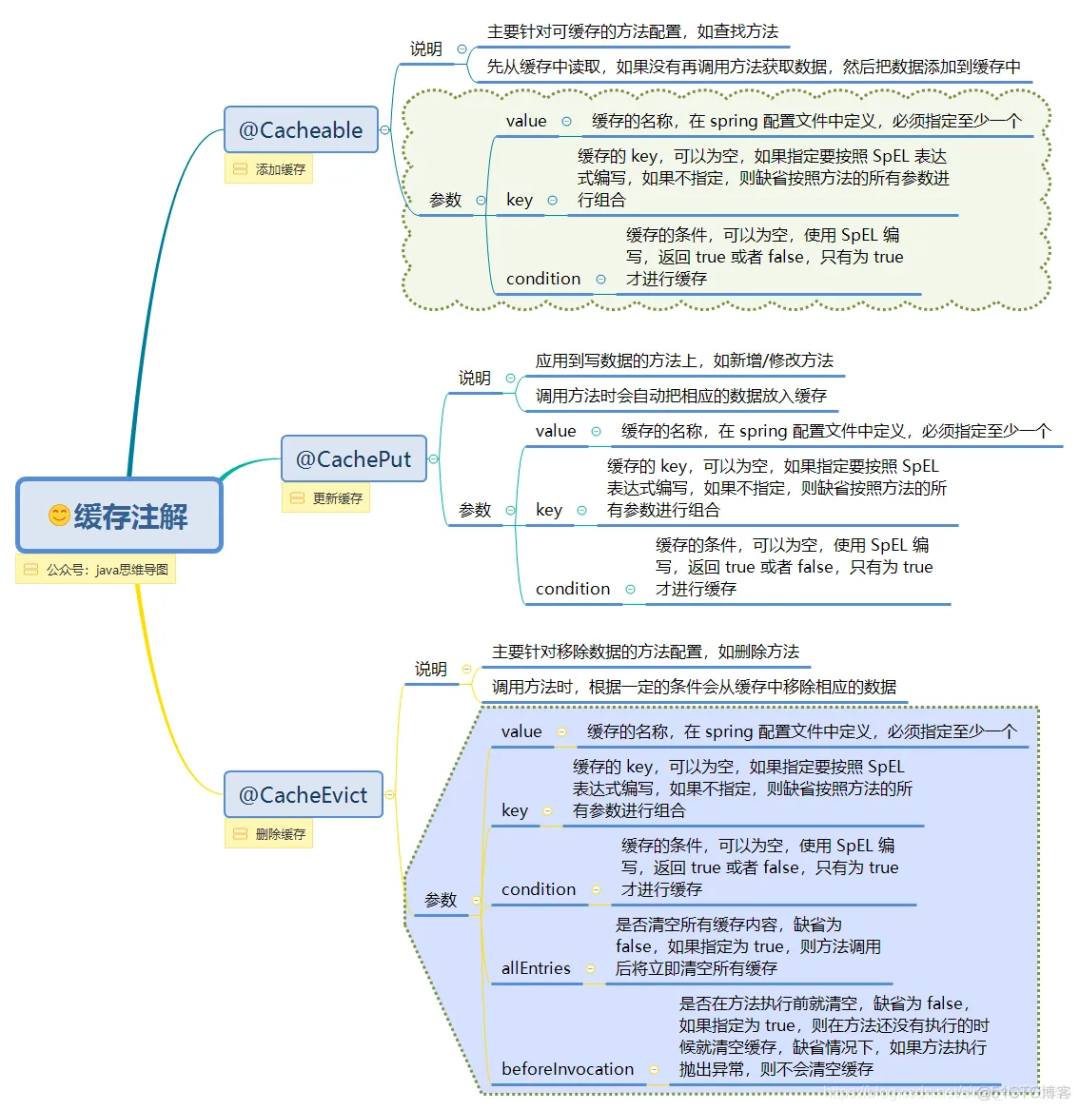
▐ 注解导图
▐ 注解使用示例
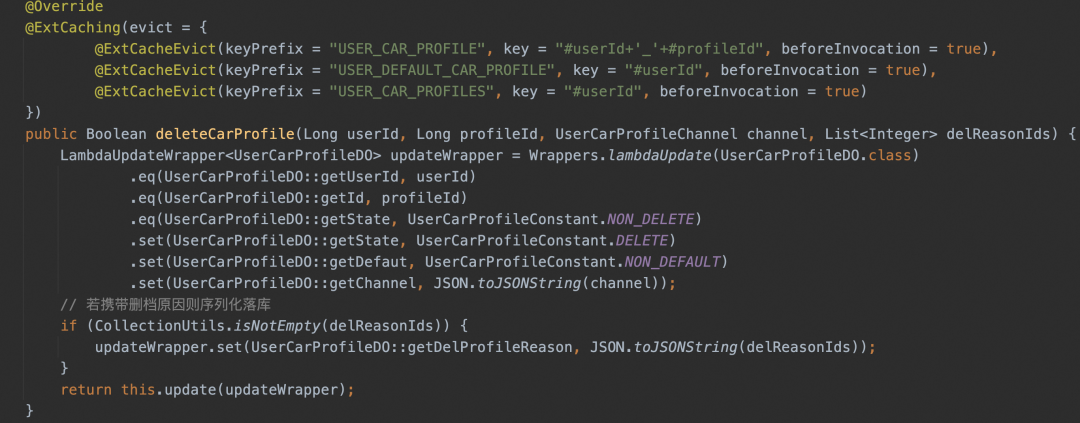
@Cacheable(value = "user_cache", unless = "#result == null")public User getUserById(Long id) {return userMapper.getUserById(id);}@CachePut(value = "user_cache", key = "#user.id", unless = "#result == null")public User updateUser(User user) {userMapper.updateUser(user);return user;}@CacheEvict(value = "user_cache", key = "#id")public void deleteUserById(Long id) {userMapper.deleteUserById(id);}
▐ 方案分析
-
多级缓存; -
缓存定期刷新; -
列表缓存; -
缓存cpp保护机制; -
缓存计数。
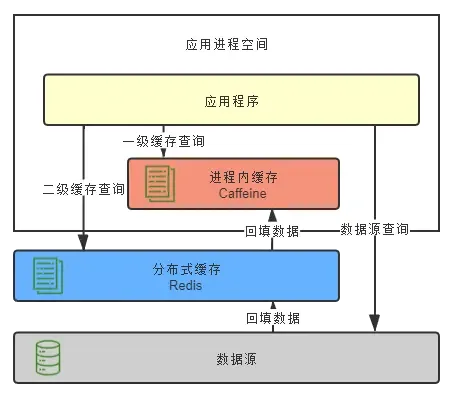

学习spring cache框架方案,实现自定义cache框架,不仅保留spring cache框架的优点,同时实现spring cache很多缺失的能力,例如缓存击穿、缓存穿透保护,多级缓存等。
▐ 注解代码示例

▐ 方案架构
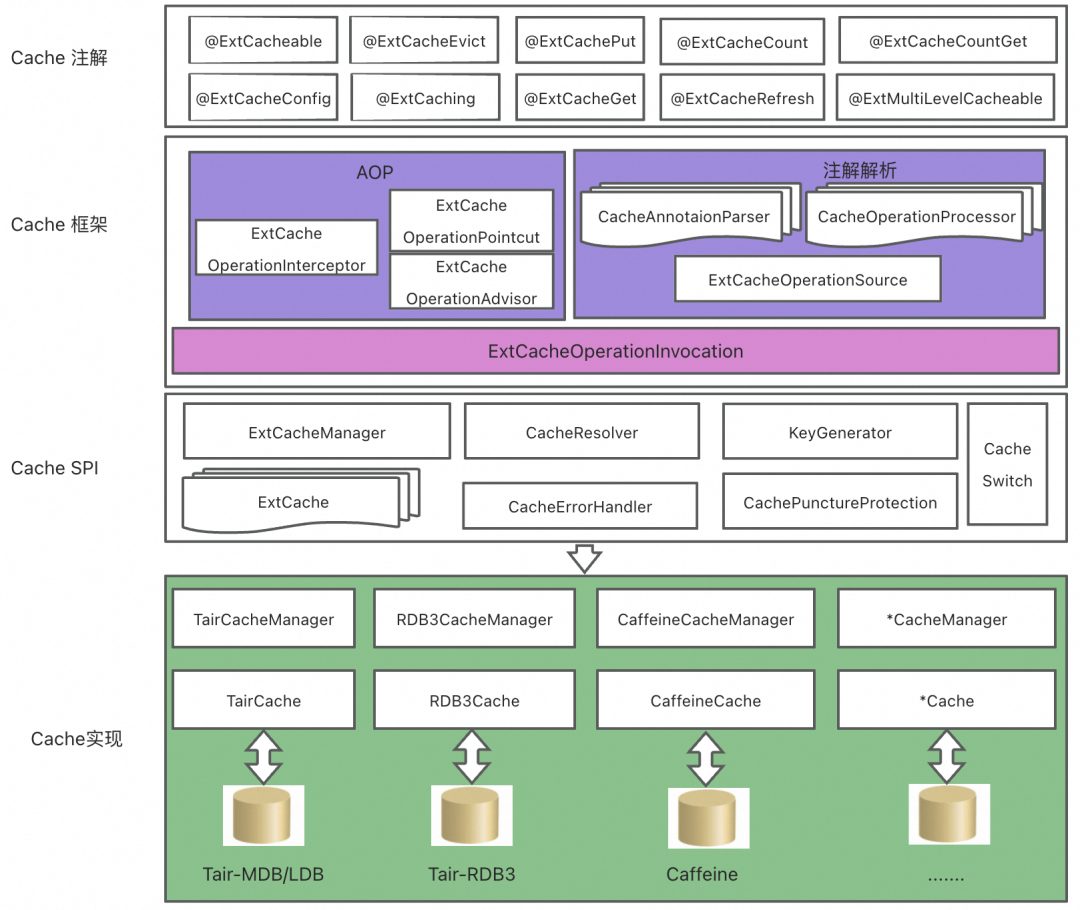

借助spring cache实现方式,构建自定义缓存框架,扩展了很多注解,例如计数、缓存刷新、列表缓存、分布式锁、多级缓存等,不仅实现了缓存代码和业务代码的分离,同时拓展了spring缓存的能力,极大的提升了代码的可读性,降低了缓存代码维护的效率。

天猫汽车技术团队的使命是极致体验的人车生活,重塑汽车行业,做你身边的贴心汽车管家,皆在打造消费者线上看车买车养车心智,数字化并垂直整合汽车行业,通过模式突破撬动品效合一,提升行业效率,创造行业红利。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。